簡介
最近在學習I2S音頻相關內容,無可避免會涉及到關于音頻格式的內容,所以剛開始接觸的時候有點一頭霧水,后面了解了下WAV相關內容,大致能夠看懂wav音頻格式是怎么樣的了。本文主要為后面ESP32 I2S音頻系列文章做鋪墊,所以本篇將介紹WAV音頻文件格式,并通過C代碼生成一段1S的正弦波WAV音頻寫入到SD卡里面。
WAV(Waveform Audio File Format) 是一種音頻文件格式,用于存儲音頻數據。它是由 微軟 和 IBM 開發的,通常用于存儲高質量的原始音頻數據。
如果一段單聲道音頻的采樣率為 44100 Hz,一分鐘的音頻數據大約有 5.04MB。這個值是可以大致計算的,后面我們會提到。WAV 文件一般未經過壓縮,因此能夠提供音頻的 高保真度,但相比其他音頻格式,相同時間內的文件會顯得較大。所以一開始我打算用SPIFFS存儲WAV音頻的時候發現好像不太現實,畢竟ESP32 SPIFFS空間太小了,而 WAV文件幾秒的音頻動不動就好幾M了,這樣子的話只能播放短時間的音頻就不符合我的要求了。
WAV文件基于RIFF格式,這是一種用于存儲多媒體數據的通用格式。
也就是說WAV是基于RIFF格式的一種具體應用,RIFF格式還被用于許多其他文件類型。
什么是RIFF格式
RIFF(Resource Interchange File Format,資源交換文件格式)是一種通用的文件格式標準,由微軟和IBM于1991年聯合開發,用于存儲和交換多媒體數據,如音頻、視頻、圖像等。RIFF格式以其靈活性和可擴展性著稱,能夠容納各種類型的數據,并被廣泛應用于多種文件類型,例如:
- WAV(音頻)
- AVI(視頻)
- ANI(動畫光標)
可以簡單理解為它是一種通用的文件容器格式,它通過一個個塊的形式(稱之為chunk)存儲多媒體數據。
以下是基于RIFF格式的不同文件類型及其用途的表格:
| 文件類型 | 擴展名 | 用途 |
|---|---|---|
| WAV | .wav | 存儲音頻數據 |
| AVI | .avi | 存儲音頻和視頻數據 |
| RMI | .rmi | 存儲MIDI音樂數據 |
| ANI | .ani | 存儲動畫光標 |
| WEBP | .webp | 存儲圖像數據(主要用于Web) |
可以看到除了WAV是基于RIFF格式的,還有其他文件類型也是基于RIFF的,這里我們也可以看到很多文件格式會用特定的標識符,比如WAV, AVI,這里就涉及到FOURCC標識符。RIFF 文件的結構通常以標識符 “RIFF” 開頭,緊接著是文件大小(4 字節),再后面跟著的就是一個四字符代碼(FOURCC),用于指明文件的數據類型。
FOURCC標識符
FOURCC(Four-Character Code,四字符代碼)是由 4 個字節組成的標識符,通常使用可打印的 ASCII 字符,它在 RIFF 文件中用來標識數據的具體格式。比如:
WAV 文件:以 “RIFF” 開頭,FOURCC 為 “WAVE”,表示這是一個音頻文件。
AVI 文件:以 “RIFF” 開頭,FOURCC 為 "AVI “”(注意末尾有空格),表示這是一個視頻文件。
FOURCC 的設計要求正好 4 個字符,如果不足則用空格填充,且對大小寫敏感。這種標識方式不僅用于文件類型的最頂層定義,還用于文件內部的各個數據塊,每個數據塊稱作一個chunk,比如 WAV 文件中包含 "fmt "(格式信息)和 “data”(音頻數據)這兩個chunk。
字節序
WAV文件的字節數據還涉及到字節序的問題。字節序(Byte Order)是指多字節數據(如整數、浮點數等)在計算機內存中存儲的順序。不同的計算機體系結構可能采用不同的字節序方式,這可能會導致在不同平臺之間傳輸數據時出現問題。字節序問題主要體現在多字節數據的存儲順序上,尤其是在跨平臺的數據交換和存儲中需要特別注意。根據字節存儲時從低位開始還是從高位開始分為兩種:大端序和小端序。
大端序(Big-Endian)
大端字節序是一種字節順序,其中數據的高字節存儲在內存的低地址處,低字節存儲在高地址處。
例如,對于一個4字節的整數 0x12345678,它的字節序會按以下順序存儲:
| 地址 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 數據 | 0x12 | 0x34 | 0x56 | 0x78 |
這種存儲方式類似于我們閱讀數字的順序,從左到右。
小端序(Little-Endian)
小端字節序是一種字節順序,其中數據的低字節存儲在內存的低地址處,高字節存儲在高地址處。
對于同樣的4字節整數 0x12345678,它的字節序會按以下順序存儲:
| 地址 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 數據 | 0x78 | 0x56 | 0x34 | 0x12 |
這種存儲方式將數字的低位放在前面,更符合計算機內部的處理邏輯。
WAV文件結構
WAV文件基于RIFF格式。RIFF格式的結構是一個個塊構成的,一個塊稱為一個chunk,每個chunk都有一個4字節的ID(FOURCC),緊隨其后的是4字節的塊大小(chunk size),然后是塊數據 (data) 。 最外層的是RIFF chunk,里面在套著"fmt" chunk和"data" chunk。

我們來看一下WAV文件的結構:

這張圖的最左邊是字節序,然后是偏移量,每個數據字段區域的名稱及對應區域的字節大小。
字節序:
前面我們提到WAV的字節序問題,那在WAV中每個chunk里面的字節數據是以什么方式存儲的呢?在RIFF格式中,所有多字節的 數值數據(如塊大小、音頻采樣率等)都以小端序存儲。而ID,即FOURCC標識符,是4個ASCII字符的組合,按照ASCII字符的順序直接存儲, 所以它的字節序是大端序。
偏移量:
偏移量是指當前數據字段相對于文件開始位置的字節數。比如ChunkID的偏移量是0,表示它是文件的開始部分;ChunkSize的偏移量是4,表示它從文件的第4個字節開始,
WAVE音頻文件結構主要分為三個部分:
1. RIFF Chunk Descriptor (偏移量0-12)
這是文件的頭部,提供文件的身份和基本信息:
- ChunkID (偏移量0,4字節) 標識文件為RIFF類型,通常為字符串 "RIFF"。 每個字符在ASCII表中都對應一個十六進制數。比如,R的ASCII碼是0x52,I是0x49,F是0x46,第二個F也是0x46,那連起來的話, "RIFF"這四個字母對應的ASCII碼就是0x52 0x49 0x46 0x46。
- ChunkSize (偏移量4,4字節) 表示整個文件的大小(不包括前8字節,即 ChunkID 和 ChunkSize)。
- 整個文件大小(不包含前8字節)=
36 + SubChunk2Size或4 + (8 + SubChunk1Size) + (8 + SubChunk2Size)或文件總大小-8 - Format (偏移量8,4字節) 指定文件格式為 "WAVE"。對應57 41 56 45。
2. fmt Sub-chunk (偏移量12-36)
這部分描述音頻的格式信息,是播放或處理音頻時必須了解的關鍵數據:
- Subchunk1ID (偏移量12,4字節) 標識這是 "fmt " 子塊。和上面的"RIFF"一樣,使用ASCII字符標識,不足四個字符,末尾用空格補齊。對應66 6D 74 20
- Subchunk1Size (偏移量16,4字節) 表示此子塊的大小(對于PCM通常為16字節)。
- AudioFormat (偏移量20,2字節) 指定音頻格式,例如PCM(未壓縮音頻,值為1)。
- NumChannels (偏移量22,2字節) 聲道數,例如1(單聲道)或2(立體聲)。
- SampleRate (偏移量24,4字節) 采樣率,例如44100 Hz(CD音質)。
- ByteRate (偏移量28,4字節) 每秒字節數,計算公式為:
SampleRate * NumChannels * BitsPerSample / 8 - BlockAlign (偏移量32,2字節) 每個采樣塊的字節數,計算公式為:
NumChannels * BitsPerSample / 8 - BitsPerSample (偏移量34,2字節) 每個樣本采樣的位數,例如8位或16位。
3. data Sub-chunk (偏移量36起)
這部分存儲實際的音頻數據:
- Subchunk2ID (偏移量36,4字節) 標識這是 "data" 子塊。對應64 61 74 61。
- Subchunk2Size (偏移量40,4字節) 表示音頻數據的大小。 datasize =
NumSamples × NumChannels × BitsPerSample / 8,其中NumSamples 是總樣本數 - data (偏移量44起,可變大小) 包含原始的音頻采樣數據。
WAV文件頭
WAV文件的前44字節稱為 WAV的文件頭 ,剩下的data為WAV文件實際的音頻數據。所以整個WAV文件的大小應等于
文件頭44字節 + data字節大小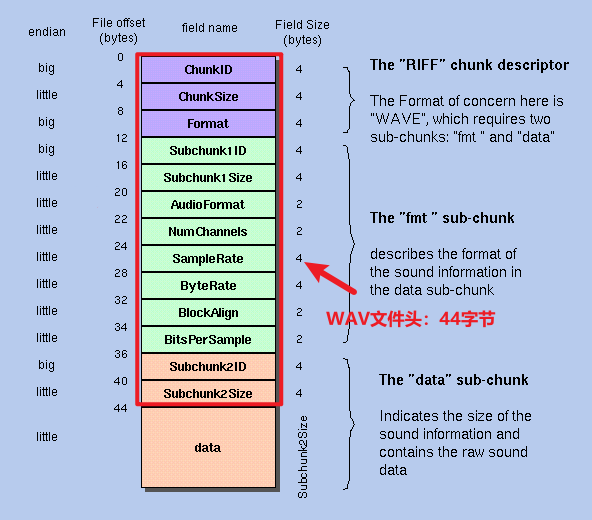
這個文件頭主要注意ChunkSize ,Subchunk2Size,ByteRate ,BlockAlign 這幾個參數,我們重點介紹一下。
ChunkSize
ChunkSize字段里面存儲著 “它之后的數據總大小” 的這個數據 (對于當前chunk的剩余部分)。所以 ChunkSize 指 對于ChunkSize字段后面的數據大小,不包括前8字節,即 4字節的ChunkID 和4字節的ChunkSize,所以ChunkSize大小是
文件總大小-8。 (從ChunkID到data是一個WAV文件,ChunkSize實際就是從下個地址08開始到WAV文件結尾的總字節數)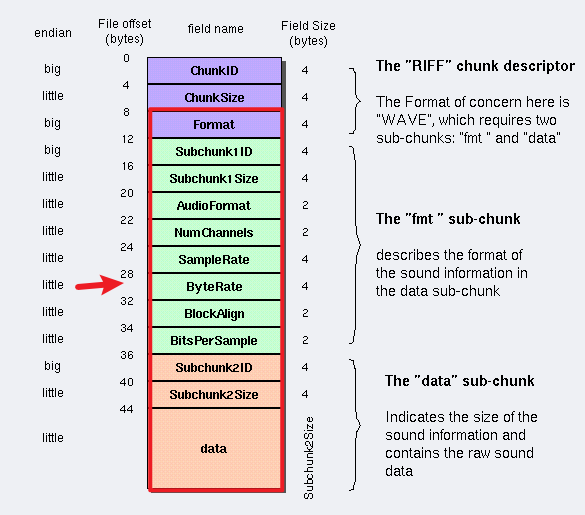
ChunkSize大小還等于
36 + SubChunk2Size。(下圖紅色框+藍色框)。因為同理Subchunk2Size 指 對于Subchunk2Size字段后面的數據大小,而這個數據剛好就是WAV真正的音頻數據,即 datasize,
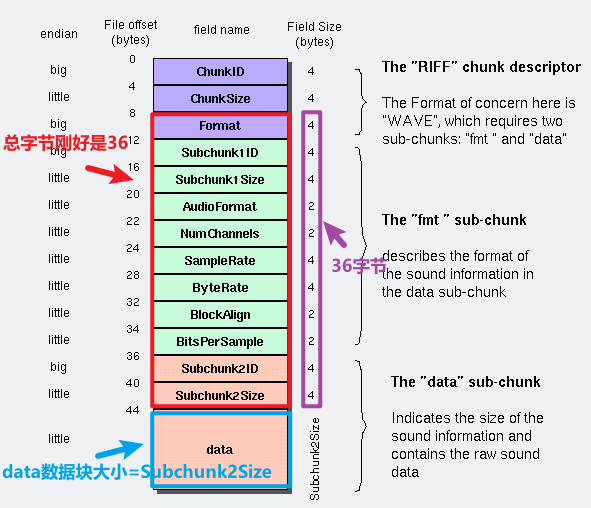
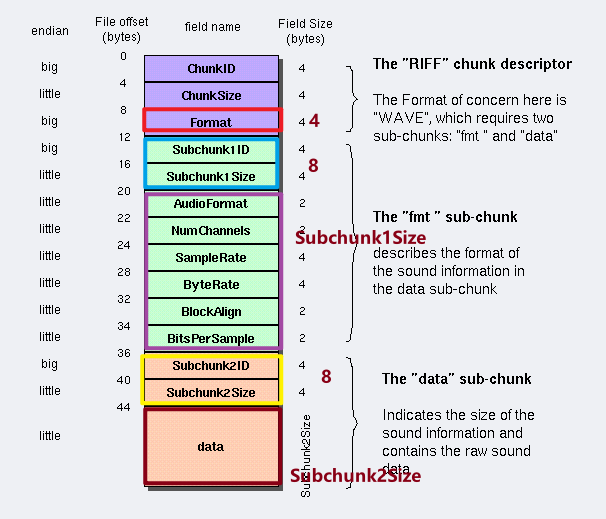
ChunkSize還等于
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size),這個式子比較長,主要是分的比較細,如下圖:
ByteRate
ByteRate表示每秒傳輸的字節數,比如一段采樣率8000hz,采樣深度16bit的音頻,單聲道,則一秒采樣8000個樣本,每個樣本16位,每秒采樣樣本字節大小為
8000 * 16 / 8 * 1聲道 = 16000字節,除以8是為了轉換為字節,所以ByteRate = SampleRate * NumChannels * BitsPerSample / 8BlockAlign
BlockAlign指每個采樣塊的字節數,或者說一幀的樣本,如果是單聲道音頻,一幀樣本就包含一個聲道數據;如果是雙聲道音頻,一幀樣本包含左聲道數據和右聲道數據。比如一段采樣深度16bit的音頻,單聲道,一幀就是
16 / 8 * 1聲道 = 2字節。所以BlockAlign = NumChannels * BitsPerSample / 8。講到采樣幀這里順便提一下之前學習遇到的困惑,之前學習I2S了解到在對音頻樣本采樣時,如果是雙聲道音頻,左聲道和右聲道是一幀樣本,在同一時刻采樣,那為什么WS又區分WS=0和WS=1呢? 在之前學過I2S的通信格式的那個圖里一般左邊是左聲道,右邊是右聲道,這樣子看起來并不是在同一個時刻。這里其實是我混淆了采樣和傳輸的過程,采樣確實是同時采樣的,但是傳輸是先傳輸左聲道,再傳輸右聲道。這里參考了別人畫的圖,很形象借用一下。
假設一個 buffer 包含 4 個周期、而一個周包含 1024 幀、一幀包含兩個樣本(左、右兩個聲道),每個樣本長度為2bytes。

Subchunk2Size
Subchunk2Size表示音頻數據的大小(字節),一般可以預估計算,有了ByteRate ,一般乘以時間,就可以得到音頻總大小。 或者知道樣本數也可以估算出來,比如一段采樣率44100,采樣深度16bit的音頻,單聲道,時間一分鐘60s,字節速率
ByteRate=44100 * 16 / 8 = 88200,即每秒傳輸字節數88200字節,再乘以時間,88200 * 60 = 5292000字節 ≈ 5.04 MB。Subchunk2Size大小因為表示的是WAV音頻實際數據大小,所以也叫datasize,后面編寫程序時我們將使用datasize這個字段名稱。 使用時間去估計音頻數據大小可能會有誤差,但是這個誤差一般不會很大。我們還可以通過樣本數去估計音頻數據大小,即NumSamples × NumChannels × BitsPerSample / 8,其中NumSamples是總樣本數,NumChannels × BitsPerSample / 8 就是每個采樣樣本的字節數(即BlockAlign), 乘以總樣本數,就可以得到總樣本字節大小。以上我們講了ChunkSize ,Subchunk2Size,ByteRate ,BlockAlign 這幾個比較主要的參數,還有一些其他參數在WAV文件中是默認的。為了方便查看,將以上內容整理為表格:
偏移 大小 字段名 內容/說明 0 4 ChunkID "RIFF"(52 49 46 46)4 4 ChunkSize 文件大小 - 8
或
36 + SubChunk2Size
或
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size)8 4 Format "WAVE"(57 41 56 45)12 4 Subchunk1ID "fmt "(66 6D 74 20)16 4 Subchunk1Size 16(表示 PCM 格式時) 20 2 AudioFormat 1 表示 PCM;其他為壓縮格式 22 2 NumChannels 聲道數(1=單聲道,2=立體聲) 24 4 SampleRate 采樣率(如 44100) 28 4 ByteRate 每秒傳輸的字節數 = SampleRate * NumChannels * BitsPerSample / 832 2 BlockAlign 每個采樣塊的字節數 = NumChannels × BitsPerSample / 834 2 BitsPerSample 每個樣本的位數(如 16) 36 4 Subchunk2ID "data"(64 61 74 61)40 4 Subchunk2Size 音頻數據的大小(字節) = NumSamples × NumChannels × BitsPerSample / 8WAV音頻文件格式示例
了解了RIFF格式,字節序和WAV文件結構等相關參數后,我們先舉一個WAV音頻文件格式示例,再來看看實際的音頻文件格式是什么樣子的。
假設有一段WAV音頻文件如下(十六進制顯示)52 49 46 46 24 08 00 00 57 41 56 45 66 6d 74 20 10 00 00 00 01 00 02 00
22 56 00 00 88 58 01 00 04 00 10 00 64 61 74 61 00 08 00 00 00 00 00 00
24 17 1e f3 3c 13 3c 14 16 f9 18 f9 34 e7 23 a6 3c f2 24 f2 11 ce 1a 0d對音頻數據按照上面WAV文件結構進行劃分:

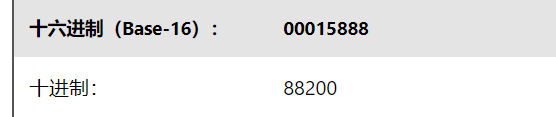
我們可以得到RIFF chunk, ChunkSize, Subchunk1Size,AudioFormat等相關參數,這里要注意除了ASCII字符,其他數據都是以小端序存儲的。 比如ByteRate為 88 58 01 00,小端序應為:0x00015888,對應的十進制為88200。
再比如BlockAlign=4, 根據我們前面舉的例子計算(雙倍),它是一段雙聲道音頻。那對于一段實際音頻,我們如何查看它的十六進制格式呢?我們可以通過 Hex Editor這個軟件,
HxD Hex Editor 是一款功能強大的十六進制編輯器和磁盤編輯器,它可以讓你直接查看和編輯二進制文件的內容。你可以使用HxD Hex
Editor來分析、修改和處理各種數據格式,包括程序文件、磁盤映像、內存轉儲以及其他二進制文件。這里我自己生成了一段30S的WAV音頻。我們用HxD軟件打開它看看。

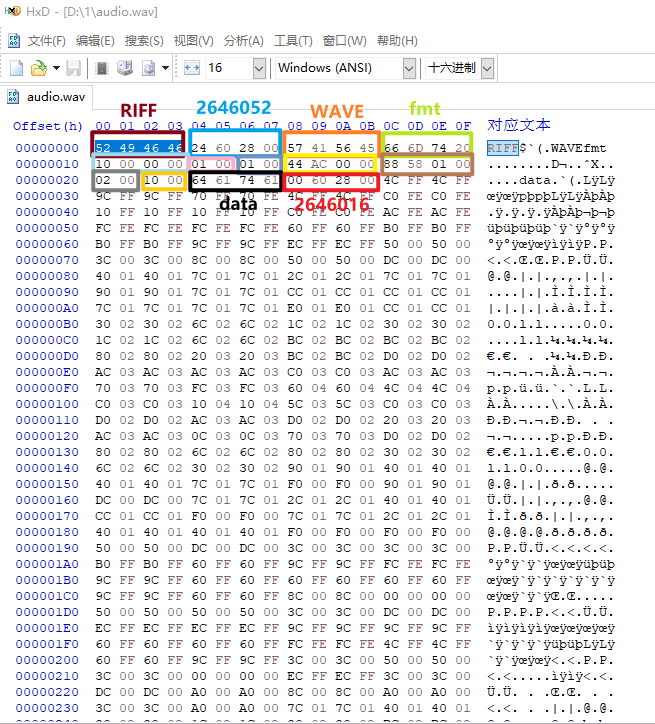
當我們框選頭四個字節時,可以看到右邊也有顯示它的對應文本為:RIFF,表示這是一個基于RIFF格式的文件。我們將每個數據按照上面的結構進行劃分,可以看到這個數據格式和我們介紹的WAV格式相符。除了框選的部位,后面都是真正的WAV音頻數據即data。 框選的所有部分我們稱之為 文件頭,以四個字節為一組,數一下可以發現剛好有11組,11 * 4= 44字節,剛好是WAV文件頭的字節數。 而WAV數據大小就是上面圖片最后紅色框的2646016字節,則整個WAV文件字節數應為
2646016 + 44 = 2646060字節。右鍵查看這個音頻的文件屬性:
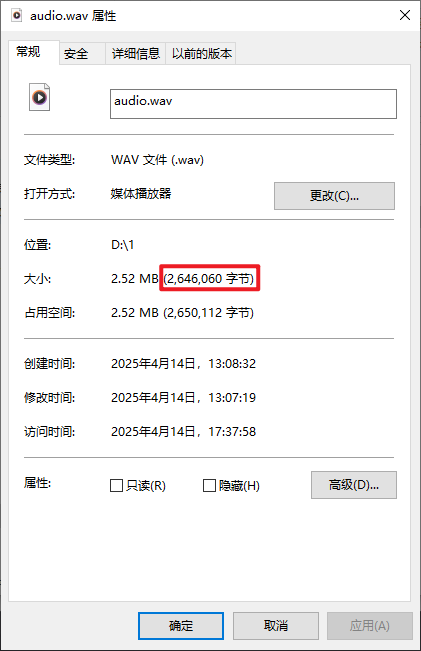
這和我們的計算結果一致。關于這個WAV文件頭的詳細信息如下:
52 49 46 46 RIFF標識
24 60 28 00 ChunkSize = 2646052(除去前8個字節文件大小)
57 41 56 45 WAV標識
66 6D 74 20 fmt標識
10 00 00 00 , Subchunk1Size =16(表示 PCM 格式時固定為16)
01 00 AudioFormat=1 ,音頻格式:PCM(未壓縮)(表示 PCM 格式時固定為1)
01 00 聲道數:1(單聲道)
44 ac 00 00 采樣率:44100 Hz
88 58 01 00 字節率:88200 字節/秒
02 00 塊對齊:2字節(每個采樣點的字節數)
10 00 位深度:16位(每個采樣點2字節)
64 61 74 61 data標識
00 60 28 00 Subchunk2Size = 2646016 (音頻數據大小)WAV文件大小:2646060 字節
現在我們是通過WAV文件信息得到這些參數,比如音頻數據大小 2646016 。前面我們說過WAV文件大小可以預估,那我們來計算一下看看有什么差異。以上面我生成的audio.wav文件為例, 假設我們已經知道一些基本參數,一段采樣率44100, 采樣深度16bit, 單聲道WAV音頻,如果我們通過字節速率ByteRate去計算再乘以時間,則
估計總音頻文件大小應為44100 * 16 / 8 * 30 = 2646000字節,但實際大小為2646016字節,我們估計出來的音頻大小比實際小。這是因為采樣音頻時長并不是精確的30 秒, 如果是精確30秒,采樣點數量應該是44100 × 30 = 1323000個,我們通過 Subchunk2Size (實際音頻大小),計算實際樣本數卻為2646016 / 2 = 1323008,比 1323000 多 8 個采樣點,而每個采樣點占 2 字節,所以實際整體多了16字節。 反過來我們可以計算實際采樣時間為1323008 / 44100 ≈ 30.0001814058956秒, 多出8個采樣點的時間剛好為1 / 44100 * 8 = 0.0001814058956秒。所以我們通過時間去預估WAV音頻數據大小的話和實際相比是有差異的,但是我們一般會先預估大小,然后再更新WAV文件頭。使用ESP32將WAV文件寫入SD卡
以上我們介紹了WAV相關內容后,我們將介紹一個例子,將WAV音頻文件寫入SD卡,生成的WAV音頻為一段1S的正弦波音頻。
上面我們知道通過一段WAV文件頭信息,可以得到它的一些參數;反過來我們也可以寫入一些參數到WAV文件頭里,生成WAV文件,所以WAV頭部的定義是不可避免的。【定義WAV文件頭】
假設我們要生成的WAV音頻參數,采樣率8000,采樣深度16bit, 單聲道,那么我們可以預估ChunkSize,Subchunk2Size(即datasize)大小,因為采樣率是8000Hz,我們要生成1秒的音頻,則1秒有8000個樣本,每個樣本大小為2字節(采樣深度16bit),則 datasize = 16000, 根據公式直接計算的話就是
NumSamples × NumChannels × BitsPerSample / 8 = 8000 x 1 x 16 /8 = 16000字節。ChunkSize = 36 + datasize = 16036字節。其他參數可以參考上面的表格,這里就不贅述了。將其轉化為16進制,小端序,定義WAV文件頭:
const uint8_t wavHeader[44] = {0x52, 0x49, 0x46, 0x46, // "RIFF"0xA4, 0x3E, 0x00, 0x00, // chunksize: 160360x57, 0x41, 0x56, 0x45, // "WAVE"0x66, 0x6D, 0x74, 0x20, // "fmt "0x10, 0x00, 0x00, 0x00, // fmt塊大小 (16)0x01, 0x00, // 音頻格式 (1 = PCM)0x01, 0x00, // 聲道數 (1)0x40, 0x1F, 0x00, 0x00, // 采樣率 (8000 Hz)0x80, 0x3E, 0x00, 0x00, // 字節率 (16000)0x02, 0x00, // 塊對齊 (2)0x10, 0x00, // 每樣本位數 (16)0x64, 0x61, 0x74, 0x61, // "data"0x80, 0x3E, 0x00, 0x00 // datasize: 16000 };【創建并打開文件】
為了寫入SD卡,我們還要初始化SD卡。創建一個文件取名為test.wav并打開它:
#define SD_CS_PIN 5// 初始化SD卡 if (!SD.begin(SD_CS_PIN)) { Serial.println("SD卡初始化失敗!"); return; } Serial.println("SD卡初始化成功。");//創建并打開文件 File wavFile = SD.open("/test.wav", FILE_WRITE); if (!wavFile) { Serial.println("無法創建文件!"); return; }【寫入WAV頭部】
File 類是Arduino SD庫的一部分,這里我們創建了一個 File 類對象取名為wavFile,wavFile.write用于向 SD 卡上的文件寫入數據。使用
size_t write(const uint8_t *buf, size_t size)將文件頭寫入前面創建的文件中,這里要注意第一個參數類型是uint8_t *類型的,如果寫入的buffer不是uint8_t *類型,需要進行強制類型轉換。wavFile.write(wavHeader, 44);【 生成440Hz正弦波音頻】
正弦波公式為:
y = A * sin(ωt+φ)其中,
A:振幅,那么y的取值范圍就是
[-A, A];
ω:角頻率,ω = 2 * π * f,其中f為頻率,周期T = 1 / f;
φ:初相位;以下是生成一段1秒440Hz正弦波音頻的示例:
// 生成并寫入440Hz正弦波音頻數據 const int sampleRate = 8000; // 采樣率 const int frequency = 440; // 正弦波頻率 const int numSamples = sampleRate * 1; // 1秒的樣本數 for (int i = 0; i < numSamples; i++) { float time = (float)i / sampleRate; int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time)); }【寫入WAV音頻文件并關閉文件】
使用
size_t write(const uint8_t *buf, size_t size)將前面生成的正弦波音頻數據寫入前面創建的文件中并進行強制類型轉換。wavFile.write((uint8_t*)&sample, 2); // 寫入16位樣本 wavFile.close(); Serial.println("WAV文件寫入完成。");整合后的代碼如下:
#include <SD.h> #include <SPI.h>// SD卡片選引腳 #define SD_CS_PIN 5// WAV文件頭部(44字節) const uint8_t wavHeader[44] = {0x52, 0x49, 0x46, 0x46, // "RIFF"0xA4, 0x3E, 0x00, 0x00, // chunksize: 160360x57, 0x41, 0x56, 0x45, // "WAVE"0x66, 0x6D, 0x74, 0x20, // "fmt "0x10, 0x00, 0x00, 0x00, // fmt塊大小 (16)0x01, 0x00, // 音頻格式 (1 = PCM)0x01, 0x00, // 聲道數 (1)0x40, 0x1F, 0x00, 0x00, // 采樣率 (8000 Hz)0x80, 0x3E, 0x00, 0x00, // 字節率 (16000)0x02, 0x00, // 塊對齊 (2)0x10, 0x00, // 每樣本位數 (16)0x64, 0x61, 0x74, 0x61, // "data"0x80, 0x3E, 0x00, 0x00 // datasize: 16000 };void setup() { Serial.begin(115200);// 初始化SD卡 if (!SD.begin(SD_CS_PIN)) { Serial.println("SD卡初始化失敗!"); return; } Serial.println("SD卡初始化成功。");// 創建并打開文件 File wavFile = SD.open("/test.wav", FILE_WRITE); if (!wavFile) { Serial.println("無法創建文件!"); return; }// 寫入WAV頭部 wavFile.write(wavHeader, 44);// 生成并寫入440Hz正弦波音頻數據 const int sampleRate = 8000; // 采樣率 const int frequency = 440; // 正弦波頻率 const int numSamples = sampleRate * 1; // 1秒的樣本數 for (int i = 0; i < numSamples; i++) { float time = (float)i / sampleRate; int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time)); wavFile.write((uint8_t*)&sample, 2); // 寫入16位樣本 }// 關閉文件 wavFile.close(); Serial.println("WAV文件寫入完成。"); }void loop() { }這里我們觀察到如果使用數組定義WAV文件頭的話需要計算它的十六進制比較麻煩,我們可以定義一個WAV頭部結構體,寫入ASCII字符和公式,這樣可以更方便地計算 WAV 文件頭的信息,而不用手動去處理十六進制數據。
使用結構體定義WAV文件頭:
// 定義 WAV 頭部結構體 struct WavHeader {char riff[4] = {'R', 'I', 'F', 'F'}; // "RIFF"uint32_t chunkSize; // 文件大小 - 8char wave[4] = {'W', 'A', 'V', 'E'}; // "WAVE"char fmt[4] = {'f', 'm', 't', ' '}; // "fmt "uint32_t fmtChunkSize = 16; // fmt 塊大小 (16 for PCM)uint16_t audioFormat = 1; // 音頻格式 (1 = PCM)uint16_t numChannels = 1; // 聲道數 (1 = 單聲道)uint32_t sampleRate = SAMPLE_RATE; // 采樣率 (8000 Hz)uint32_t byteRate = SAMPLE_RATE * 2; // 字節率 (sampleRate * numChannels * bitsPerSample / 8)uint16_t blockAlign = 2; // 塊對齊 (numChannels * bitsPerSample / 8)uint16_t bitsPerSample = 16; // 每樣本位數 (16 bits)char data[4] = {'d', 'a', 't', 'a'}; // "data"uint32_t dataSize; // 數據塊大小 };使用結構體定義WAV文件頭的話我們只是定義了一個類型,所以我們需要定義一個結構體變量,因為我們沒有直接給出 chunkSize 和 datasize ,所以我們需要計算音頻數據大小,創建并初始化WAV文件頭。這里由于樣本比較簡單,所以我們直接可以確定樣本數去計算音頻數據大小,后面就不需要再更新WAV文件頭了。
// 計算音頻數據大小const int numSamples = SAMPLE_RATE * 1; // 1 秒的樣本數const int bytesPerSample = 2; // 16 位,每個樣本 2 字節uint32_t dataSize = numSamples * bytesPerSample; // 數據大小:16000 字節uint32_t chunkSize = 36 + dataSize; // 文件總大小 - 8:16036 字節// 創建并初始化 WAV 頭部WavHeader header;header.chunkSize = chunkSize; // 設置 chunkSizeheader.dataSize = dataSize; // 設置 dataSize完整代碼
修改后的完整代碼如下:
#include <SD.h> #include <SPI.h>// 定義常量 #define SD_CS_PIN 5 // SD卡片選引腳 #define SAMPLE_RATE 8000 // 采樣率(8000 Hz) #define PI 3.1415926535 // π 值// 定義 WAV 頭部結構體 struct WavHeader {char riff[4] = {'R', 'I', 'F', 'F'}; // "RIFF"uint32_t chunkSize; // 文件大小 - 8char wave[4] = {'W', 'A', 'V', 'E'}; // "WAVE"char fmt[4] = {'f', 'm', 't', ' '}; // "fmt "uint32_t fmtChunkSize = 16; // fmt 塊大小 (16 for PCM)uint16_t audioFormat = 1; // 音頻格式 (1 = PCM)uint16_t numChannels = 1; // 聲道數 (1 = 單聲道)uint32_t sampleRate = SAMPLE_RATE; // 采樣率 (8000 Hz)uint32_t byteRate = SAMPLE_RATE * 2; // 字節率 (sampleRate * numChannels * bitsPerSample / 8)uint16_t blockAlign = 2; // 塊對齊 (numChannels * bitsPerSample / 8)uint16_t bitsPerSample = 16; // 每樣本位數 (16 bits)char data[4] = {'d', 'a', 't', 'a'}; // "data"uint32_t dataSize; // 數據塊大小 };void setup() {Serial.begin(115200);// 初始化 SD 卡if (!SD.begin(SD_CS_PIN)) {Serial.println("SD卡初始化失敗!");return;}Serial.println("SD卡初始化成功。");// 創建并打開文件File wavFile = SD.open("/test.wav", FILE_WRITE);if (!wavFile) {Serial.println("無法創建文件!");return;}// 計算音頻數據大小const int numSamples = SAMPLE_RATE * 1; // 1 秒的樣本數const int bytesPerSample = 2; // 16 位,每個樣本 2 字節uint32_t dataSize = numSamples * bytesPerSample; // 數據大小:16000 字節uint32_t chunkSize = 36 + dataSize; // 文件總大小 - 8:16036 字節// 創建并初始化 WAV 頭部WavHeader header;header.chunkSize = chunkSize; // 設置 chunkSizeheader.dataSize = dataSize; // 設置 dataSize// 寫入 WAV 頭部wavFile.write((uint8_t*)&header, sizeof(header));// 生成并寫入音頻數據(440 Hz 正弦波)const int frequency = 440;for (int i = 0; i < numSamples; i++) {float time = (float)i / SAMPLE_RATE;int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time));wavFile.write((uint8_t*)&sample, 2);}// 關閉文件wavFile.close();Serial.println("WAV文件寫入完成。"); }void loop() { }以上通過ESP32生成的一段1S的正弦波音頻寫入SD卡模塊,硬件上只需ESP32和SD模塊。下面我們介紹如何將ESP32和SD模塊進行接線。
ESP32

SD卡模塊

ESP32和SD模塊接線
ESP32 SD模塊 D5 CS D18 SCK D23 MOSI D19 MISO 5V VCC GND GND 按照以上步驟,編譯上傳代碼后,應能在SD卡找到生成的名為test.wav的音頻文件,播放會聽到1秒的正弦波聲音。
同樣我們用HxD軟件打開我們生成的test.wav文件
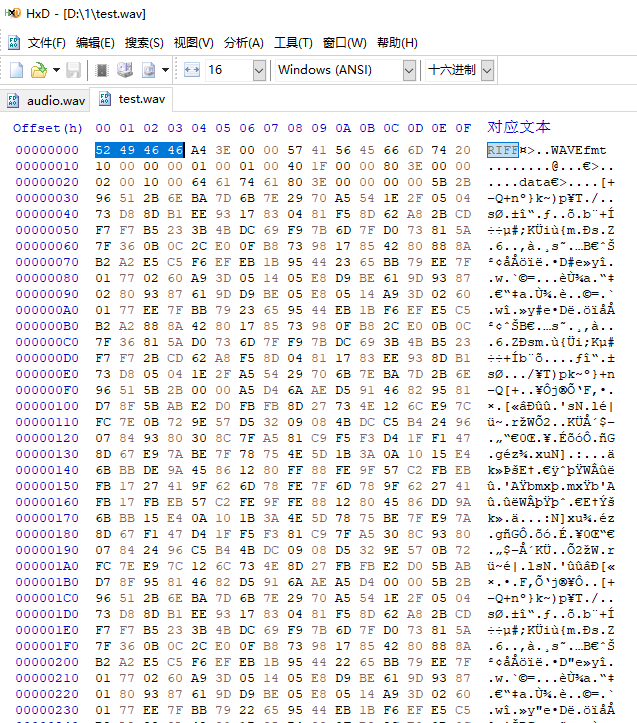
對比我們代碼里的WAV文件頭數據,可以發現數據是一樣的,這說明WAV文件頭確實是按照我們的要求寫入了WAV文件了,而且使用數組或者結構體表示 WAV 頭部這兩種方法都可以實現,建議采用第二個代碼的方式,使用結構體和動態計算 chunkSize等數據,確保 WAV 文件頭部的正確性、靈活性和兼容性。
總結
以上我們介紹了什么是WAV音頻文件,還有一些音頻格式的相關概念、參數,并實際觀察了WAV文件的數據內容,對WAV文件結構有了更深入的了解,然后我們通過ESP32生成了一段1S的正弦波音頻,并將其寫入SD模塊,方法是通過將音頻參數寫入WAV文件頭,并通過SD和文件系統相關函數將文件頭寫入我們創建的文件里,這樣我們就可以在SD卡里通過讀卡器讀取里面的正弦波音頻數據了。
關于WAV文件頭的每個參數是如何計算和填寫的,在我們介紹WAV文件頭的時候,已經舉例并且說明了,我們也可以直接參考一開始總結的表格,里面有詳細說明和相關公式,這些公式并不需要死記硬背,理解了每個參數的含義還是比較容易理解的。在介紹WAV文件頭的時候,還有一些參數沒有詳細說明,比如AudioFormat, 1表示PCM,至于其他值表示的壓縮格式應該是什么樣子這里沒有提到,還有LIST 塊相關本文也沒有提到,因為我們主要針對WAV文件進行介紹,所以這里不作提及,感興趣的小伙伴可以自行去了解下~
本文是為后面ESP I2S音頻學習內容作為鋪墊,因為WAV文件格式的內容還是比較多的,所以單獨寫一篇介紹。后面大家關于WAV文件有疑惑的地方,可以參考這篇文章。因為本人也是初學,以上是個人理解加上搜索資料學習到的,如果有什么問題,可以提出交流討論,歡迎指正!需要HxD軟件和想聽一下源代碼工程生成的WAV音頻文件是什么聲音的可以評論區留言!已經整理好所有文件 ~ 創作不易,多多點贊收藏哦! ~










)
:用數據驅動企業發展的深度解析)





 函數)

)