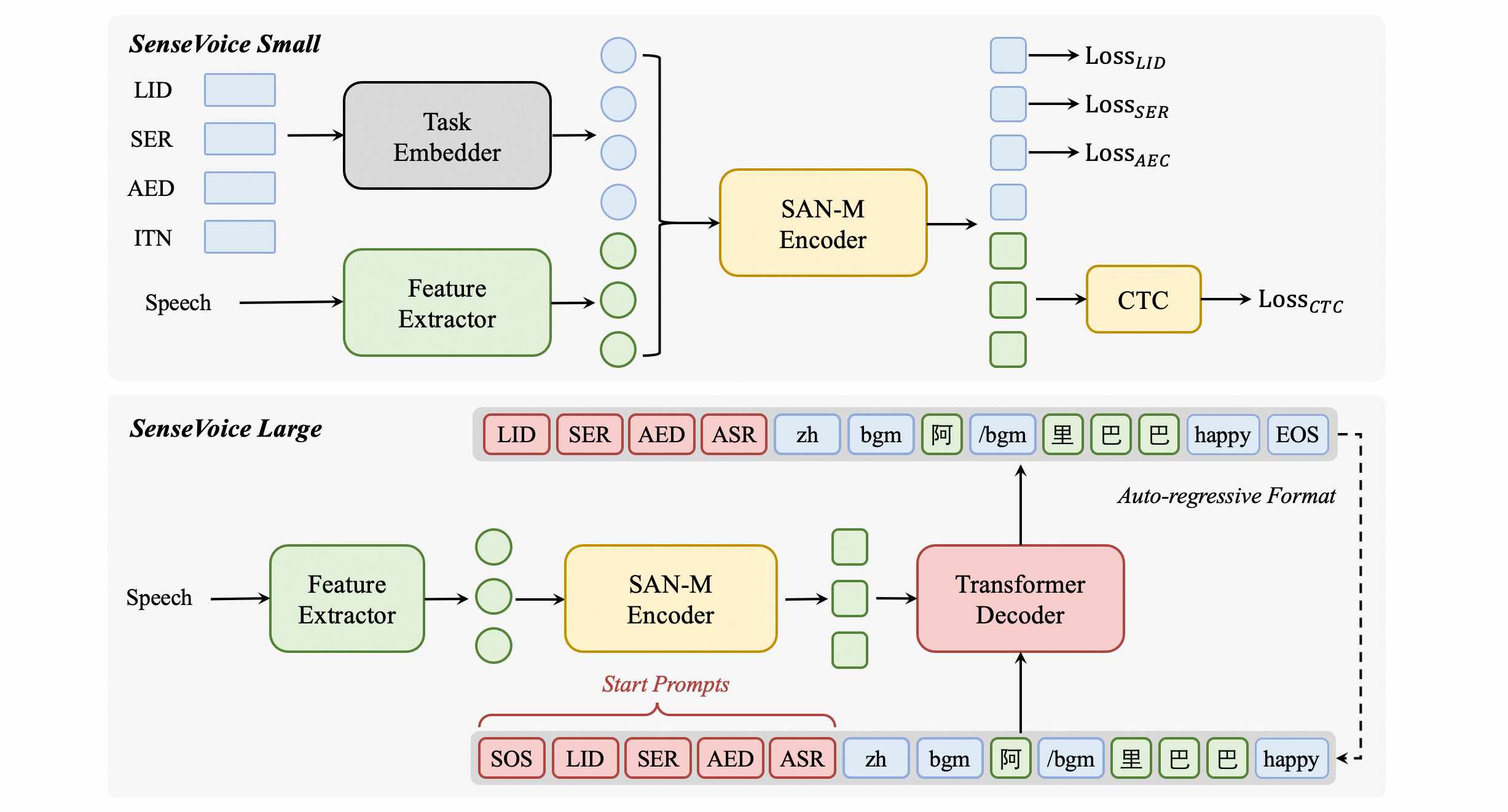
SenseVoiceSmall網絡結構圖
ASR(語音識別)是將音頻信息轉化為文字的技術。在實時語音識別中,一個關鍵問題是:如何決定將采集的音頻數據輸入大模型的最佳時機?固定時間間隔顯然不夠靈活,太短可能導致頻繁調用模型,太長則會延遲文字輸出。有沒有更智能的方式?答案是肯定的。
一種常見的解決方案是使用 webrtcvad 庫中的 Vad(VAD_MODE) 方法。它通過分析音頻波動來判斷是否有人說話,從而決定是否觸發語音識別。然而,我在實際測試中發現,這種方法在某些場景下不夠靈敏,尤其是在白噪音較大或較小的環境中,難以做到真正的自適應。
為了解決這一問題,我嘗試了一種更綜合的驗證方式:結合 聲波能量、VAD 和 頻譜分析,通過多重驗證來判斷音頻中是否包含語音活動。這種方法不僅能更精準地捕捉語音信號,還能有效過濾背景噪音,確保實時輸出的準確性。
在模型選擇上,我推薦使用 SenseVoiceSmall。這款模型在實時語音識別任務中表現優秀,既能保持高準確率,又能兼顧效率。openai推出的IWhisper也可以試試其效果,我主要識別的語言是中文,暫時還沒試過這個模型。此外,值得一提的是,魔搭社區(ModelScope)提供了豐富的模型資源和詳細的調用代碼。如果你對語音識別感興趣,這里是一個值得探索的平臺。雖然它和 Hugging Face有些相似,但作為國產社區,它在本地化支持和模型適配上有著獨特的優勢,值得推薦。
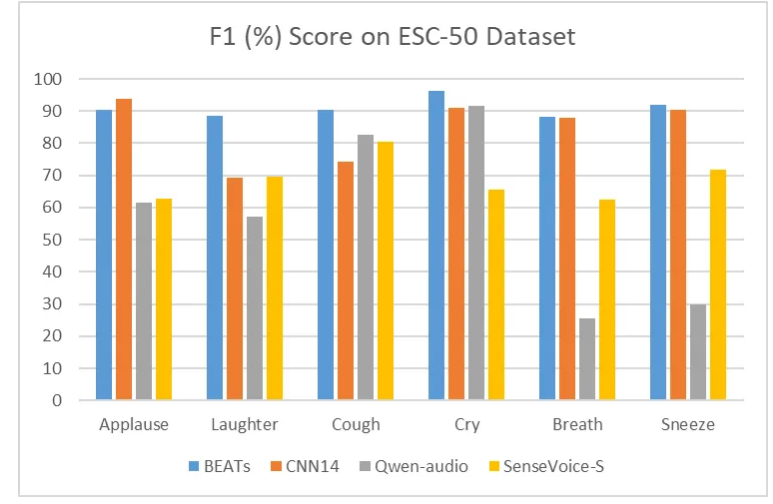
SenseVoiceSmall性能如下:
import pyaudio
import webrtcvad
import numpy as np
from pypinyin import pinyin, Style # 如果后續需要用,可按需使用
import refrom funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
from modelscope.pipelines import pipeline# 參數配置
AUDIO_RATE = 16000 # 采樣率(支持8000, 16000, 32000或48000)
CHUNK_SIZE = 480 # 每塊大小(30ms,保證為10/20/30ms的倍數)
VAD_MODE = 1 # VAD 模式(0-3,數值越小越保守)# 初始化 VAD
vad = webrtcvad.Vad(VAD_MODE)# 初始化 ASR 模型
sound_rec_model = AutoModel(model=r"D:\Downloads\SenseVoiceSmall",trust_remote_code=True,remote_code="./model.py",vad_model="fsmn-vad",vad_kwargs={"max_single_segment_time": 30000},device="cuda:0",use_itn=True,disable_update = True,disable_pbar = True,disable_log = True)# 初始化說話人驗證模型(如果需要后續使用)
# sv_pipeline = pipeline(
# task='speaker-verification',
# model=r'D:\Downloads\speech_campplus_sv_zh-cn_3dspeaker_16k'
# )def calibrate(stream, calibration_seconds=2, chunk_duration_ms=30):"""校準背景噪音:錄制指定時長的音頻,計算平均幅值與標準差,從而設置自適應閾值參數:calibration_seconds: 校準時間(秒)chunk_duration_ms: 每塊時長(毫秒)返回:amplitude_threshold: 設定的音頻幅值閾值"""print("開始校準背景噪音,請保持安靜...")amplitudes = []num_frames = int(calibration_seconds * (1000 / chunk_duration_ms))for _ in range(num_frames):audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitudes.append(np.abs(audio_data).mean())mean_noise = np.mean(amplitudes)std_noise = np.std(amplitudes)amplitude_threshold = mean_noise + 2 * std_noiseprint(f"校準完成:噪音均值={mean_noise:.2f},標準差={std_noise:.2f},設置閾值={amplitude_threshold:.2f}")return amplitude_thresholdclass SpeechDetector:"""SpeechDetector 負責處理音頻塊,結合能量預處理、VAD 和頻譜分析進行語音檢測,并在檢測到語音結束后調用 ASR 模型進行轉寫,返回識別結果文本。"""def __init__(self, amplitude_threshold):self.amplitude_threshold = amplitude_threshold# 音頻緩沖區,用于存儲當前語音段的音頻數據self.speech_buffer = bytearray()# 連續幀狀態,用于平滑判斷語音是否開始/結束self.speech_state = False # True:正在錄入語音;False:非語音狀態self.consecutive_speech = 0 # 連續語音幀計數self.consecutive_silence = 0 # 連續靜音幀計數self.required_speech_frames = 2 # 連續語音幀達到此值后確認進入語音狀態(例如 2 幀大約 60ms)self.required_silence_frames = 15 # 連續靜音幀達到此值后確認語音結束(例如 15 幀大約 450ms)self.long_silence_frames = 67 # 連續靜音幀達到此值后確認語音結束(例如 34 幀大約 1s)def analyze_spectrum(self, audio_chunk):"""通過頻譜分析檢測語音特性:1. 對音頻塊應用漢寧窗后計算 FFT2. 統計局部峰值數量(峰值必須超過均值的1.5倍)3. 當峰值數量大于等于3時,認為該塊具有語音特征"""audio_data = np.frombuffer(audio_chunk, dtype=np.int16)if len(audio_data) == 0:return False# 應用漢寧窗減少 FFT 泄露window = np.hanning(len(audio_data))windowed_data = audio_data * window# 計算 FFT 并取正頻率部分spectrum = np.abs(np.fft.rfft(windowed_data))spectral_mean = np.mean(spectrum)peak_count = 0for i in range(1, len(spectrum) - 1):if (spectrum[i] > spectrum[i - 1] and spectrum[i] > spectrum[i + 1] and spectrum[i] > spectral_mean * 1.5):peak_count += 1return peak_count >= 3def is_speech(self, audio_chunk):"""判斷當前音頻塊是否包含語音:1. 先通過能量閾值預過濾低幅值數據2. 再結合 VAD 檢測與頻譜分析判斷"""threshold = self.amplitude_threshold if self.amplitude_threshold is not None else 11540.82audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitude = np.abs(audio_data).mean()if amplitude < threshold:return Falsevad_result = vad.is_speech(audio_chunk, AUDIO_RATE)spectral_result = self.analyze_spectrum(audio_chunk)return vad_result and spectral_resultdef process_chunk(self, audio_chunk):"""處理每個音頻塊,并在識別到語音結束后返回文本結果。工作流程:- 若檢測到語音:* 增加連續語音幀計數(consecutive_speech),清零靜音幀計數* 若達到語音起始幀閾值,則進入語音狀態* 處于語音狀態時,將當前音頻塊追加到緩沖區- 若檢測為靜音:* 累計靜音幀數,同時清零語音計數* 若處于語音狀態且靜音幀達到設定閾值,認為當前語音段結束,則調用 ASR 模型進行識別,并返




)


![LeetCode[541]反轉字符串Ⅱ](http://pic.xiahunao.cn/LeetCode[541]反轉字符串Ⅱ)





程編程——(4)進程間的傳音術(命名管道))
)



