sortByKey算子:對(K, V)型RDD按key排序,K需實現Ordered接口,可指定升序或降序及分區數。

join算子:連接兩個(K, V)和(K, W)型RDD,返回(K, (V, W))型RDD 。

leftOuterJoin算子:類似SQL左外連接,返回(K, (V, Option[W]))型RDD。

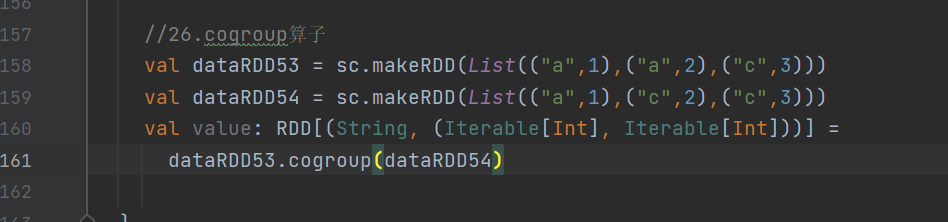
cogroup算子:作用于(K, V)和(K, W)型RDD,返回(K, (Iterable[V], Iterable[W]))型RDD。
RDD行動算子:
RDD行動算子,其能觸發實際的數據計算操作。1.?reduce:用于聚合RDD中的所有元素,先在分區內聚合,再進行分區間聚合。
2.?collect:以數組形式返回數據集的所有元素到驅動程序,函數簽名?def collect(): Array[T]?
3.?foreach:分布式遍歷RDD中的每個元素并應用指定函數。
4.?count:返回RDD中元素的數量,函數簽名?def count(): Long?。
5.?first:返回RDD中的首個元素,函數簽名?def first(): T?。
6.?take:返回由RDD前n個元素組成的數組,函數簽名?def take(num: Int): Array[T]?。
7.?takeOrdered:返回RDD排序后的前n個元素組成的數組,函數簽名?def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]?。
8.?aggregate:先利用初始值聚合分區內數據,再聚合分區間數據。函數簽名?def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U??
9.?fold:是?aggregate?的簡化版本,進行折疊操作。函數簽名?def fold(zeroValue: T)(op: (T, T) => T): T?。
10.?countByKey:統計RDD中每種key出現的次數,返回?Map[K, Long]? ,函數簽名?def countByKey(): Map[K, Long]?。
11.?save相關算子:包括?saveAsTextFile?(保存為文本文件)、?saveAsObjectFile?(保存為序列化對象文件)、?saveAsSequenceFile?(了解即可) ,用于將RDD數據保存為不同格式文件。

 ?
?
 ?
?
 ?
?
?累加器:
實現原理:累加器用于將Executor端變量信息聚合到Driver端。Driver程序定義的變量在Executor端的每個Task都有副本,Task更新副本值后回傳Driver端進行合并。
自定義累加器實現wordcount:創建繼承?AccumulatorV2?的自定義累加器類?WordCountAccumulator?,重寫相關方法實現單詞計數邏輯,在Driver端注冊并使用該累加器統計RDD中的單詞數量。
廣播變量
實現原理:廣播變量用于高效分發較大的只讀對象,向所有工作節點發送該對象,供一個或多個Spark操作使用,避免為每個任務重復發送。
 ?
?
?
?
?
?
?

,getchar(),getline(),cin.get line()異同點)

可視化網站匯總)




)



)






)