目錄
一、你的 SQL 語句為什么變“慢”
二、什么情況會引發數據庫的 flush 過程?
三、分析上面四種場景對性能的影響
四、InnoDB 刷臟頁的控制策略
五、原作者小結:
引言: 一條 SQL 語句,正常執行的時候特別快,但是有時也不知道怎么回事,它就會變得特別慢,并且這樣的場景很難復現,它不只隨機,而且持續時間還很短。 看上去,這就像是數據庫“抖”了一下 。
一、你的 SQL 語句為什么變“慢”
現在你知道了,InnoDB 在處理更新語句的時候,只做了寫日志這一個磁盤操作。這個日志叫作 redo log(重做日志),也就是《孔乙己》里咸亨酒店掌柜用來記賬的粉板,在更新內存寫完 redo log 后,就返回給客戶端,本次更新成功。 (先寫粉板,有空了在更新到賬本)
做下類比的話,掌柜記賬的賬本是數據文件,記賬用的粉板是日志文件(redo log),掌柜的記憶就是內存。
掌柜總要找時間把賬本更新一下,這對應的就是把內存里的數據寫入磁盤的過程,術語就是 flush (flush->清刷,清空) 。 在這個flush 操作執行之前,孔乙己的賒賬總額,其實跟掌柜手中賬本里面的記錄是不一致的。因為孔乙己今天的賒賬金額還只在粉板上,而賬本里的記錄是老的,還沒把今天的賒賬算進去。 (目前這兩個頁面內容是不統一的)
①當內存數據頁跟磁盤數據頁內容不一致的時候,我們稱這個內存頁為“臟頁”。
②內存數據寫入到磁盤后,內存和磁盤上的數據頁的內容就一致了,稱為“干凈頁” 。
不論是臟頁還是干凈頁,都在內存中。在這個例子里,內存對應的就是掌柜的記憶。 (無論是臟頁還是干凈頁,都保存了欠賬的記錄,都可能要經過內存,存入到磁盤里面的)
接下來,用一個示意圖來展示一下“孔乙己賒賬”的整個操作過程。假設原來孔乙己欠賬 10文,這次又要賒 9 文。
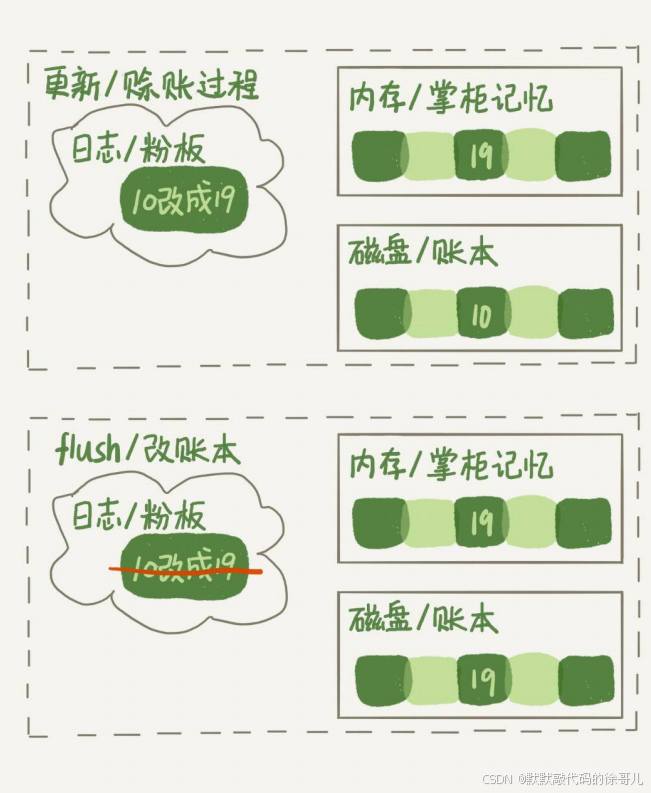
? ? ? ? ? ? ? ? ? ?圖 1 “孔乙己賒賬”更新和 flush 過程
平時執行很快的更新操作,其實就是在寫內存和日志,而 MySQL 偶爾“抖”一下的那個瞬間,可能就是在 刷臟頁(flush) 。
二、什么情況會引發數據庫的 flush 過程?
繼續用咸亨酒店掌柜的這個例子。
想一想:掌柜在什么情況下會把粉板上的賒賬記錄改到賬本上?
①第一種場景是, 粉板滿了 (redo log滿了) ,記不下了。這時候如果再有人來賒賬,掌柜就只得放下手里的活兒,將粉板上的記錄擦掉一些,留出空位以便繼續記賬。當然在擦掉之前,他必須先將正確的賬目記錄到賬本中才行。 (記賬記滿了,先去清理粉板,才能繼續保證記賬的過程)
這個場景,對應的就是 InnoDB 的 redo log 寫滿了。這時候系統會停止所有更新操作,把 checkpoint 往前推進,redo log 留出空間可以繼續寫。

? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?圖 2 redo log 狀態圖
checkpoint 可不是隨便往前修改一下位置就可以的。比如圖 2 中,把 checkpoint 位置從 CP 推進到 CP’,就需要將兩個點之間的日志(淺綠色部分),對應的所有臟頁都flush 到磁盤上。之后,圖中從 write pos 到 CP’之間就是可以再寫入的 redo log 的區域 (簡單來說,這個推的過程可以理解為協調內存與磁盤數據同步的過程加上清理臟頁)
②第二種場景是,這一天生意太好,要記住的事情太多,掌柜發現自己快記不住了,趕緊找出賬本把孔乙己這筆賬先加進去。
這種場景,對應的就是系統內存不足。當需要新的內存頁,而內存不夠用的時候,就要淘汰一些數據頁,空出內存給別的數據頁使用。如果淘汰的是“臟頁”,就要先將臟頁寫到磁盤。(客房不夠了,必須先清人,再去招待新客人入住)
③第三種場景是,生意不忙的時候,或者打烊之后。這時候柜臺沒事,掌柜閑著也是閑著,不如更新賬本。
這種場景,對應的就是 MySQL 認為系統“空閑”的時候。當然,MySQL“這家酒店”的生意好起來可是會很快就能把粉板記滿的,所以“掌柜”要合理地安排時間,即使是“生意好”的時候,也要見縫插針地找時間,只要有機會就刷一點“臟頁”。 (有空就刷新,沒空也要見縫插針的刷新)
④第四種場景是,年底了咸亨酒店要關門幾天,需要把賬結清一下。這時候掌柜要把所有賬都記到賬本上,這樣過完年重新開張的時候,就能就著賬本明確賬目情況了。 這種場景,對應的就是 MySQL 正常關閉的情況。這時候,MySQL 會把內存的臟頁都flush 到磁盤上,這樣下次 MySQL 啟動的時候,就可以直接從磁盤上讀數據,啟動速度會很快。 (關數據庫后,然后慢慢對賬)
三、分析上面四種場景對性能的影響
其中,第三種情況是屬于 MySQL 空閑時的操作,這時系統沒什么壓力,而第四種場景是數據庫本來就要關閉了。這兩種情況下,你不會太關注“性能”問題。
所以這里,我們主要來分析一下前兩種場景下的性能問題。
第一種是“redo log 寫滿了,要 flush 臟頁”,這種情況是 InnoDB 要盡量避免的。因為出現這種情況的時候,整個系統就不能再接受更新了,所有的更新都必須堵住。如果你從監控上看,這時候更新數會跌為 0。 (前有狼后有虎,進退兩難)
第二種是“內存不夠用了,要先將臟頁寫到磁盤”,這種情況其實是常態。
InnoDB 用緩沖池(buffer pool)管理內存,緩沖池中的內存頁有三種狀態:
第一種是,還沒有使用的;
第二種是,使用了并且是干凈頁;
第三種是,使用了并且是臟頁。
InnoDB 的策略是盡量使用內存,因此對于一個長時間運行的庫來說,未被使用的頁面很少。
而當要讀入的數據頁沒有在內存的時候,就必須到緩沖池中申請一個數據頁。這時候只能把最久不使用的數據頁從內存中淘汰掉:
①如果要淘汰的是一個干凈頁,就直接釋放出來復用; (干凈頁比較少,所以刷臟頁是常態)
②但如果是臟頁呢,就必須將臟頁先刷到磁盤,變成干凈頁后才能復用。 (干凈頁可以直接用,不干凈要沖洗(flush)才能用)
所以,刷臟頁雖然是常態,但是出現以下這兩種情況,都是會明顯影響性能的:
1. 一個查詢要淘汰的臟頁個數太多,會導致查詢的響應時間明顯變長; (臟的太多,刷不過來)
2. 日志寫滿,更新全部堵住,寫性能跌為 0,這種情況對敏感業務來說,是不能接受的。 (刷的能力為0,直接gg)
所以, InnoDB 需要有控制臟頁比例的機制 ,來盡量避免上面的這兩種情況。
四、InnoDB 刷臟頁的控制策略
接下來會介紹InnoDB 臟頁的控制策略,以及和這些策略相關的參數。
首先,你要正確地告訴 InnoDB 所在主機的 IO 能力,這樣 InnoDB 才能知道需要全力刷臟頁的時候,可以刷多快。
1、對于上述這段話比喻一下:這里你可以把數據庫的 IO能力 想象成在倉庫里搬運貨物:
- 磁盤:就像一個大倉庫,數據以文件等形式存放在這里。比如在數據庫中,表數據、索引數據等存放在磁盤文件里。
- 內存:類似倉庫門口的暫存區。數據庫操作數據時,先把磁盤里的數據(貨物 )搬到內存暫存區(加載到內存 ),這樣處理起來速度更快。比如查詢表數據,先把對應表數據從磁盤讀入內存。
- IO 操作
- 讀 IO:從磁盤倉庫往內存暫存區搬運貨物,即數據庫從磁盤讀取數據到內存,像執行查詢語句獲取數據時就會發生讀 IO 。(取)
- 寫 IO:把內存暫存區處理好的貨物(修改后的數據 )放回磁盤倉庫,也就是數據庫將內存中修改后的數據寫回磁盤,像事務提交時會把修改的數據持久化到磁盤 。(存)
- 隨機 IO 與順序 IO
- 隨機 IO:在倉庫里隨機找不同位置的貨物搬運,對應數據庫中數據文件的隨機讀寫,比如索引訪問,要在磁盤不同位置找索引項 。
- 順序 IO:像沿著倉庫通道按順序搬運貨物,如數據庫日志文件的順序寫入,按順序記錄事務操作,提升寫入效率 。
2、如果你來設計策略控制刷臟頁的速度,會參考哪些因素呢?
這個問題可以這么想,如果刷太慢,會出現什么情況?首先是內存臟頁太多,其次是 redo log 寫滿。
所以,InnoDB 的刷盤速度就是要參考這兩個因素:一個是臟頁比例,一個是 redo log 寫盤速度。
InnoDB 會根據這兩個因素先單獨算出兩個數字。
參數 innodb_max_dirty_pages_pct 是臟頁比例上限,默認值是 75%。InnoDB 會根據當前的臟頁比例(假設為 M),算出一個范圍在 0 到 100 之間的數字,計算這個數字的偽代碼類似這樣:
1 F1(M)
2 {
3 if M>=innodb_max_dirty_pages_pct then
4 return 100;
5 return 100*M/innodb_max_dirty_pages_pct;
6 }
InnoDB 每次寫入的日志都有一個序號,當前寫入的序號跟 checkpoint 對應的序號之間的差值,我們假設為 N。InnoDB 會根據這個 N 算出一個范圍在 0 到 100 之間的數字,這個計算公式可以記為 F2(N)。 F2(N) 算法比較復雜,你只要知道 N 越大,算出來的值越 大就好了。
然后, 根據上述算得的 F1(M) 和 F2(N) 兩個值,取其中較大的值記為 R,之后引擎就可以按照 innodb_io_capacity 定義的能力乘以 R% 來控制刷臟頁的速度。
上述的計算流程比較抽象,不容易理解,畫了一個簡單的流程圖。圖中的 F1、F2就是上面我們通過臟頁比例和 redo log 寫入速度算出來的兩個值。
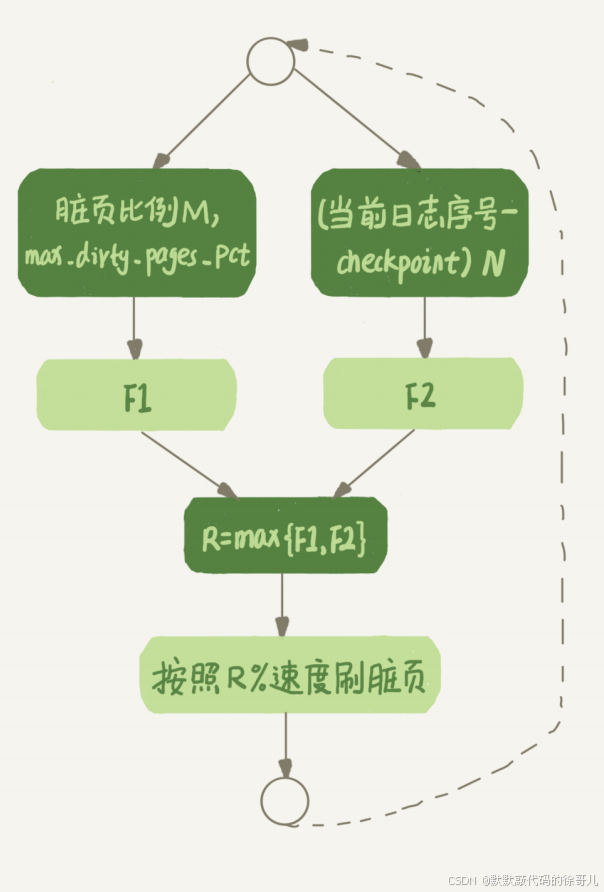
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?圖 3 InnoDB 刷臟頁速度策略
現在你知道了,InnoDB 會在后臺刷臟頁,而刷臟頁的過程是要將內存頁寫入磁盤。所以,無論是你的查詢語句在需要內存的時候可能要求淘汰一個臟頁,還是由于刷臟頁的邏輯會占用 IO 資源并可能影響到了你的更新語句,都可能是造成你從業務端感知到mysql“抖”了一下的原因。
要盡量避免這種情況,你就要合理地設置 innodb_io_capacity 的值,并且 平時要多關注臟頁比例,不要讓它經常接近 75% 。
其中,臟頁比例是通過Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total 得到的,具體的命令參考下面的代碼:
1 mysql> select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_bu
2 select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_po
3 select @a/@b;
接下來,看一個有趣的策略:
一旦一個查詢請求需要在執行過程中先 flush 掉一個臟頁時,這個查詢就可能要比平時慢了。
而 MySQL 中的一個機制,可能讓你的查詢會更慢:在準備刷一個臟頁的時候,如果這個數據頁旁邊的數據頁剛好是臟頁,就會把這個“鄰居”也帶著一起刷掉;而且這個把“鄰居”拖下水的邏輯還可以繼續蔓延,也就是對于每個鄰居數據頁,如果跟它相鄰的數據頁也還是臟頁的話,也會被放到一起刷。 (連帶效應,跟連連看一樣)
在 InnoDB 中,innodb_flush_neighbors 參數就是用來控制這個行為的,值為 1 的時候會有上述的“連坐”機制,值為 0 時表示不找鄰居,自己刷自己的。找“鄰居”這個優化在機械硬盤時代是很有意義的,可以減少很多隨機 IO。機械硬盤的隨機 IOPS 一般只有幾百,相同的邏輯操作減少隨機 IO 就意味著系統性能的大幅度提升。而如果使用的是 SSD 這類 IOPS 比較高的設備的話,建議你把
innodb_flush_neighbors 的值設置成 0。因為這時候 IOPS 往往不是瓶頸,而“只刷自己”,就能更快地執行完必要的刷臟頁操作,減少 SQL 語句響應時間。
在 MySQL 8.0 中 ,innodb_flush_neighbors 參數的默認值已經是 0 了。
五、原作者小結:
今天這篇文章,我延續第 2 篇中介紹的 WAL 的概念,和你解釋了這個機制后續需要的刷臟頁操作和執行時機。利用 WAL 技術 (也就是先寫粉板,等不忙的時候再寫賬本) ,數據庫將隨機寫轉換成了順序寫,大大提升了數據庫的性能。
但是,由此也帶來了內存臟頁的問題。臟頁會被后臺線程自動 flush,也會由于數據頁淘汰而觸發 flush,而刷臟頁的過程由于會占用資源,可能會讓你的更新和查詢語句的響應時間長一些。在文章里,我也給你介紹了控制刷臟頁的方法和對應的監控方式。
,getchar(),getline(),cin.get line()異同點)

可視化網站匯總)




)



)






)
