一、背景
實時數據倉庫是近年來數據技術領域內的一大發展潮流。構建一個能夠實現高吞吐量寫入與更新、端到端全鏈路實時處理以及低延遲、高并發的實時數據倉庫,一直是眾多企業面臨的重大挑戰。隨著B站游戲業務的快速發展,對數據的實時應用需求也日益增加。單點式實時指標計算模式已難以支撐日益復雜的實時業務需求,因此,構建一個穩定、高效的實時數據倉庫變得迫在眉睫。
建設實時數倉的主要原因包括:
-
游戲業務對數據實時性的需求愈發迫切,需要實時數據來輔助決策制定;
-
實時數據建設缺乏統一規范,導致數據可用性不足,難以形成完整的數倉體系,造成資源的極大浪費;
-
離線數倉與實時鏈路相互獨立,難以統一對外服務
如今,Hologre實時數倉體系已建設完成,它全面支持了運營、廣告、算法等多元化業務場景的實時化需求,成為B站游戲數據應用的重要基石。本文將主要介紹我們在架構選型、方案設計、技術細節等方面的探索。
二、架構選型
離線數倉搭建的方法論比較明確,各類數據模型構建方式也比較成熟,數據流轉可通過定時層間調度實現;但對于實時數倉的搭建,目前還沒有一個明確的方法體系,各大廠商也采取了不同的方案架構,尤其是近年來各類優秀的OLAP (Online Analytical Processing) 數據庫如StarRocks、Hologres快速發展,給實時數倉方案提供了更為豐富的選型,從眾多方案中設計出符合B站游戲業務的實時架構,也就成為了我們首先考慮的方面。
1. Lambda還是Kappa?
Lambda架構是一種最經典的數據處理架構,通過Hive構建離線數倉,再利用Kafka、Hbase、Redis、Clickhouse等組件構建實時數倉,既可以滿足跑批的需求,也可以進行流式計算。但是也有一個弊端,就是流和批分為兩套技術棧,運維也要維護兩套系統架構,維護成本非常高。
Kappa架構的出現,給行業帶來了不一樣的思路,即完全通過實時進行數據處理,實現全流程實時化構建,也是對流批一體式架構的一種探索。但只有實時鏈路,難以解決數據質量問題,時常需要離線鏈路對實時鏈路進行修正和豐富,而且依賴消息中間件支撐海量數據的回刷是成本極高且不穩定的架構。
考慮到B站游戲已經有了完善的離線數倉架構,選用Lambda架構是一種可靠且實際的做法,但是如何解決傳統Lambda架構所帶來的離線實時割裂化和高運維成本仍是個亟待解決的問題。
2. StarRocks還是Hologres?
為解決上述問題,我們考慮選取一種OLAP引擎來優化傳統的Lambda架構,StarRocks與Hologres這兩個近年來飛速發展的組件就成為了我們關注的重點。
首先是StarRocks,它采用了全面向量化引擎,并配備全新設計的 CBO優化器,使其查詢速度(尤其是多表關聯查詢)遠超同類產品。用其進行應用層的構建可使效率得到極大的提升,業內也有利用其強大的物化視圖及視圖能力分層構建實時數倉的案例,但對于大數據量的實時構建,通過物化視圖進行驅動會對性能產生巨大的消耗,并不是當前的最優架構。
于是,我們將目光轉向了Hologres,一款阿里自主研發的OLAP引擎,在經過深度調研后,其以下幾個功能點吸引了我們的注意:
a.全鏈路事件驅動
Hologres內部表支持更新事件的Binlog透出能力,可替代kafka等消息中間件實現數倉各層級之間的數據傳遞,從而能夠實現數倉層次間全鏈路實時開發。
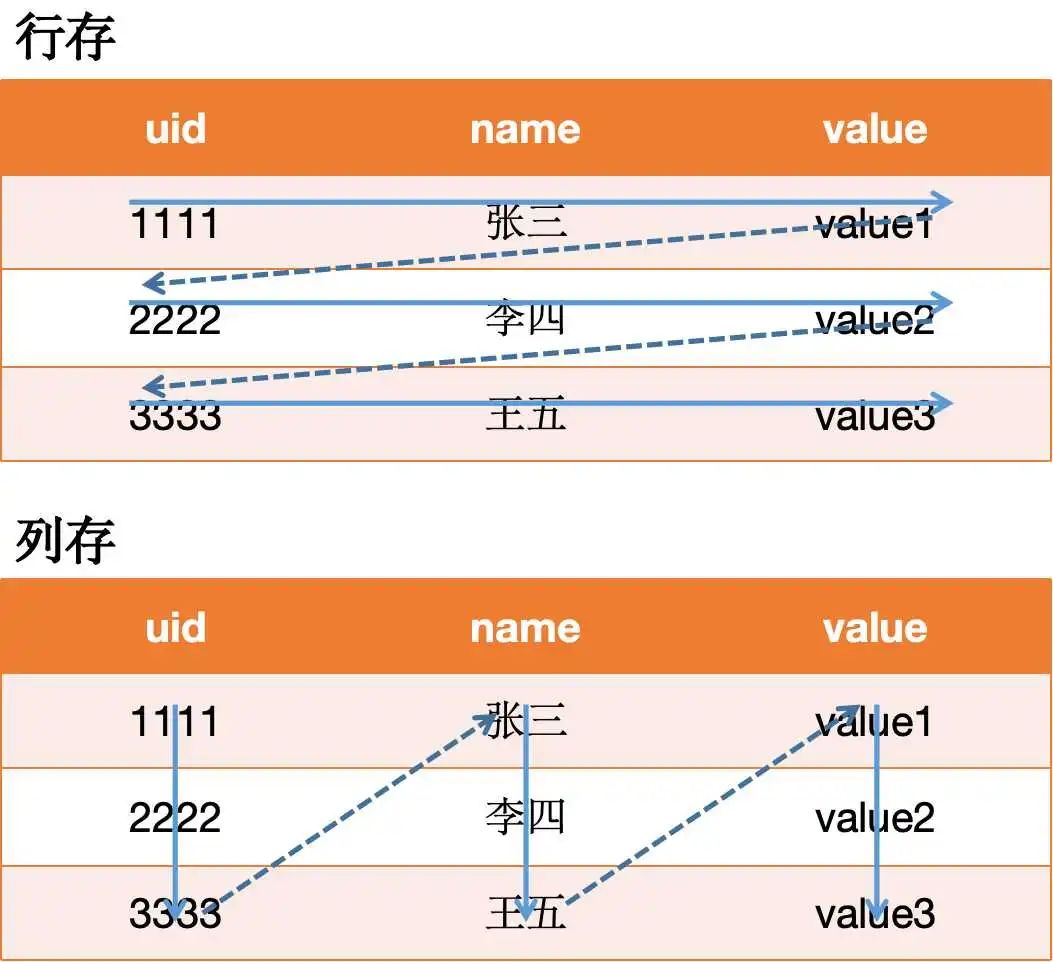
b.行列共存
Hologres同時支持行存格式和列存格式,能支持多樣化的應用場景。
c.局部更新能力
局部更新能力使Flink多表join場景簡化,可通過流式處理分段更新表字段,對于大寬表構建場景提供了強大支持。
d.MaxCompute查詢加速
Hologres與MaxCompute底層數據相互打通,可無縫銜接,且通過Hologres外表可直接加速離線表的查詢,可替代presto等組件的使用。
三、數倉架構
在架構中引入了Hologres后,我們對傳統的Lambda架構進行了優化,將原先所需的消息中間件、緩存、Hbase等組件進行整合,統一使用Hologres+Flink進行實時數據的全鏈路構建,不僅大大降低了運維成本,也實現了存儲層面的流批一體化設計,實現了離線-實時數據間的無縫銜接,全面推進了離線指標的實時化。
下圖是我們現行的實時數倉架構:
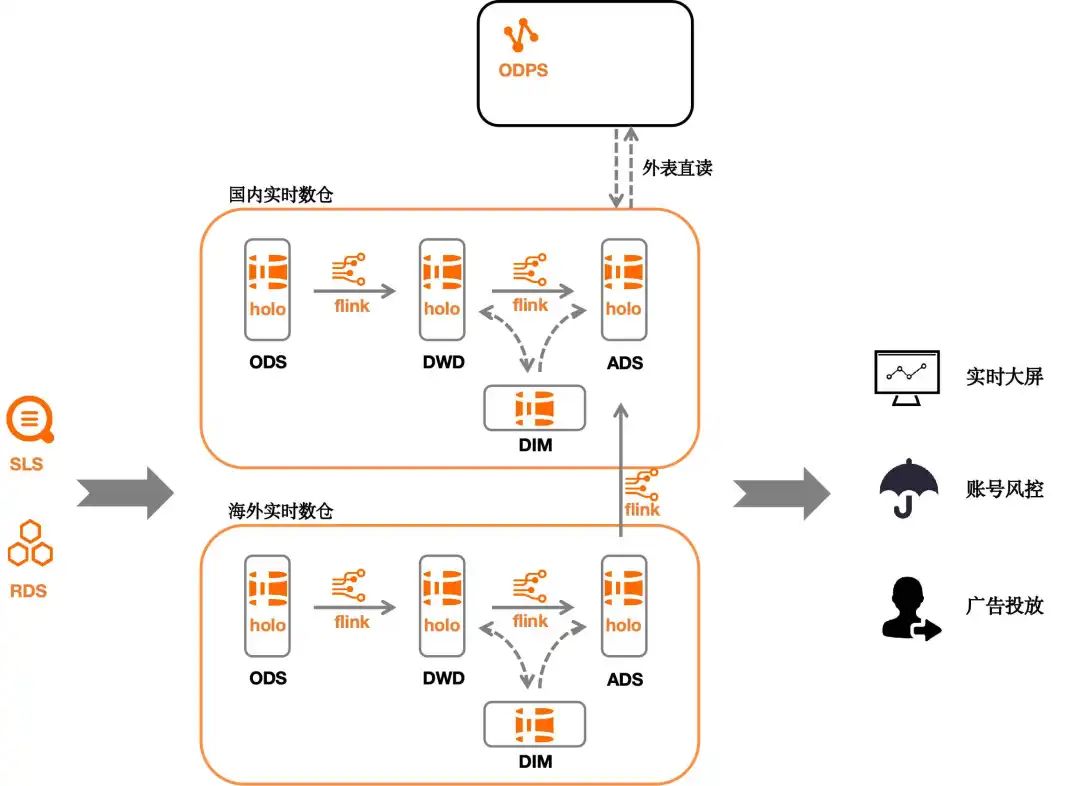
數據從SLS (Log Service)、RDS (Relational Database Service) 等組件流入Hologres,通過Flink讀取holo表的增量binlog進行層間數據模型構建,同時實現實時全量維表的自更新,最終數據流入應用層服務于實時運營、風控、廣告等方向。
傳統的實時數倉往往會面臨離線與實時數據的數據孤島問題,實時數據與離線數據很難做到相互結合,這是不同組件間的底層數據存儲模式不同帶來的痛點。Hologres與MaxCompute底層數據相互打通,數據可以通過直讀模式進行結合,針對這一特性,我們對離線指標所需的所有明細層都進行了實時化構建,使其可以滿足秒級的實時明細查詢,并可通過直讀模式與離線表直接進行join計算,實現了大部分的離線指標實時化。
B站游戲有著全球化部署的策略,我們在國內海外分別部署了Hologres實時數倉,以滿足對全球游戲數據的實時觀測,通過將計算好的指標回傳國內,實現國內-海外數據的一站式查詢。
四、分層構建
為了方便之后與離線數倉對接,我們在層級結構上仿照了離線數據的搭建模式,將實時數據也分為了ODS原始層、DWD明細層、DIM維表層、以及ADS應用層等層級,對數據逐層清洗落盤,使每個實時中間層都可進行數據查詢,并可與離線相關層進行關聯。下文將介紹我們對各個層級的設計思路。
?4.1 數據接入
該層主要是通過Flink清洗SLS中的數據流至ODS原始層,并承擔簡單的解析工作,以減輕下游DWD明細層數據處理壓力。
這里主要面臨的問題是存儲成本方面的,設計初期為實現效率最大化的數據流入,引入了stage接入層,并采用了行存格式。行存格式的數據無法進行高效的數據壓縮,單獨一個Stage層保留三天數據就已超過1.5TB。為了解決該問題,采用了以下方式:
-
行存改列存,在保障滿足吞吐要求的情況下,擁有更高的壓縮比
-
砍掉Stage層,在ODS層保留源數據格式src_message,并進行共有字段的拆解
-
縮減binlog TTL (Time To Live),binlog是無壓縮存儲,會占用大量的空間,每日有六成增量來自binlog存儲。
4.2 DIM層構建
實時維表在實時數倉中扮演著非常重要的角色,它負責了各個事件間的數據交互,用點查維表代替各流間的join操作,能大幅減少數據時延,提升數據準確性。
各維表的數據量很大,其中用戶維表有幾億條數據,設備維表有幾十億條數據,要實現如此大量維表數據的實時更細和高QPS點查,對系統的整體設計帶來了很大的考驗。
在實時體系構建初期,我們使用了MySQL作為維表數據的載體,它帶來了以下痛點:
-
用戶維表分為OB (Open Bata) 前表、OB后表,且由于數據量大,在MySQL中分成了幾十張子表,維護困難
-
實時鏈路復雜,涉及離線表、實時表、實時6h表等各種表間的組合,排查問題時困難
-
計算過程中會將維表存于內存中,需要占用大量的內存資源,曾嘗試過將維表置于redis中,但也會占用大量存儲,成本較高
-
維表字段只有基本的uid、udid等字段,可支持的指標有限
原實時維表架構:
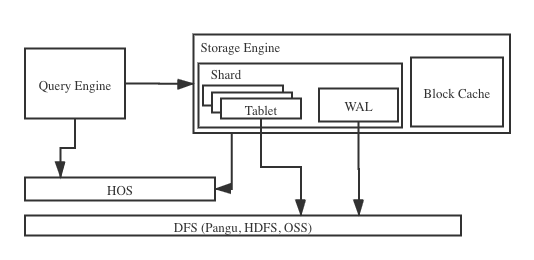
Hologres的行存表底層采用的LSM(Log-Structured Merge)結構,其底層采用了多分片結構,一個分片又由多個tablet組成,這些tablet會共享一個日志(Write-Ahead Log,WAL)。得益與LSM結構,所有新數據都是以append-only的形式寫入,數據先寫到tablet所在的內存表 (MemTable),積累到一定規模后再寫入到文件中。與傳統數據庫的B+-tree數據結構相比,LSM減少了隨機IO,大幅的提高了寫的性能。下圖展示了Hologres的一個分片的基本架構:
我們利用Hologres的行存表構建了全新的實時維表,將全量的用戶、設備、訂單等信息記錄在維表中,通過對明細層的處理實時更新維表字段。原先冗余、繁復的維表架構被取代,實現了維表底層存儲上的統一,同時我們根據日常的使用場景為維表設置了各類分布鍵、聚簇鍵,使其點查效率最大化。它帶來了一系列的好處:
-
LSM結構的行存表帶來了寫入即可查的時效性及高QPS的點查能力,無需再將維表存于內存中,即用即取
-
維表維護鏈路簡化,不需要再維護多個不同ttl的維表,同一維表可實現自更新
-
豐富了維表字段,可支持更多樣化的指標需求
下圖是我們實時維表的更新模式:
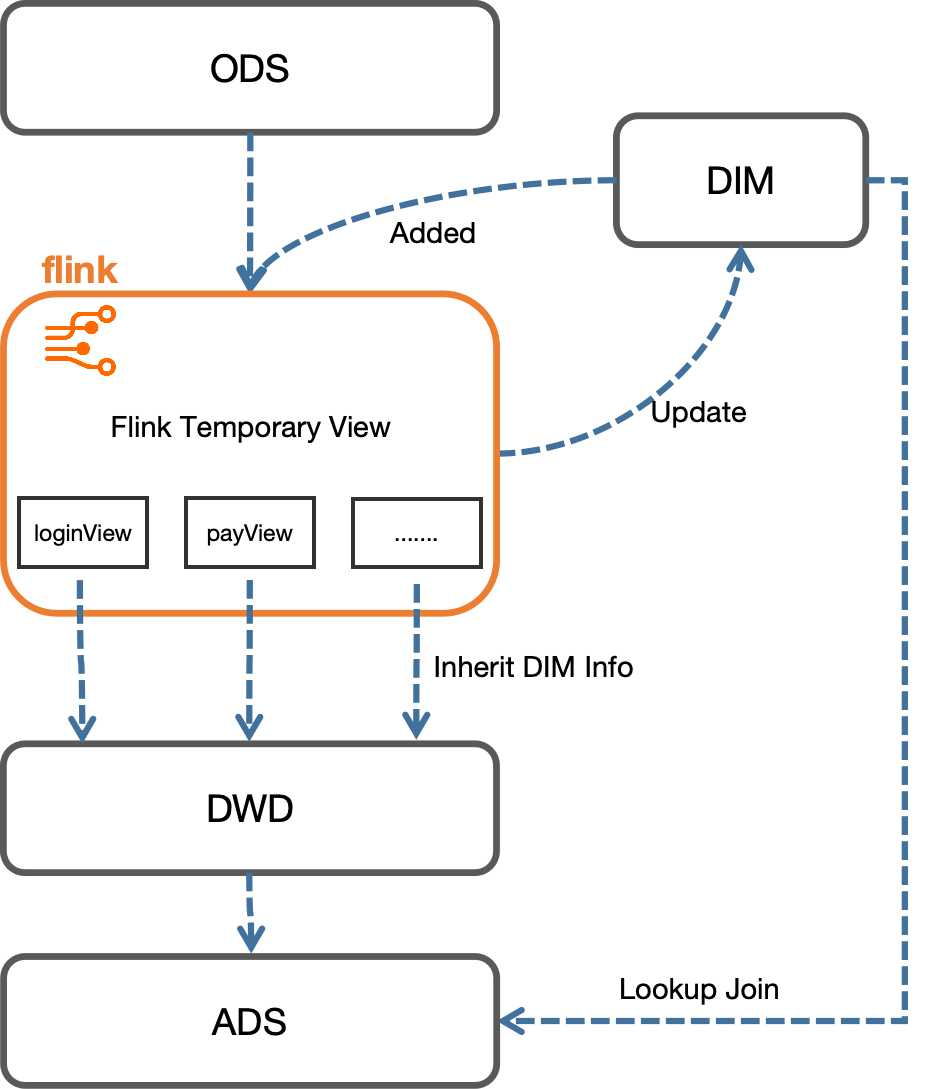
實時維表在初次啟動時,會通過歷史離線數據進行初始化操作,后續會依靠Flink程序進行實時更新。數據從ODS層流入,在Flink程序中進行各事件的拆分,然后與維表進行關聯,將最新的維表信息補充進事件信息中。然后各事件明細層中的維表信息又會反哺給實時維表,使維表始終保持最新狀態。各明細層最終會帶著繼承的最新維表信息進入下游,進行進一步的指標計算。在指標計算過程中,若有其他維表信息的需求,則可直接對維表進行lookup join,取出相應字段進行計算。
1.多流join帶來的數據冗余及數據延遲問題
在探索初期,我們為了讓明細層獲取更多的維表信息,曾用多流join進行補充多種維表字段。這樣做可以使下游在使用數據表時更為方便,但是卻帶來了巨大的維護成本,多流join會導致數據延遲更新,還會使數據在明細層發生冗余。最終我們放棄了這種做法,在每一類明細表中僅保留與其相關的維表信息,如登錄明細表會保留首末次登錄相關的信息。經過優化后,整體的架構顯得簡潔明了,響應延遲也從分鐘級提升至了秒級。
2.QPS峰值問題
QPS (Queries-per-second) 也是我們重點優化的能力之一。這一問題在使用初期并沒有暴露出來,但在重刷數據時,我們發現lookup join算子峰值流量為4000QPS,并隨著多個并行度逐漸空跑,數據傾斜的問題也逐漸顯露,QPS逐漸下降至200~300,這與Hologres的理論性能相去甚遠。經過排查發現,Flink查詢Hologres維表時,默認采用同步方式,這極大的限制了點查性能。通過將點查維表方式從同步改為異步,同時增大批處理size的方式,成功將lookup join算子流量提升至30000+QPS,數據傾斜發生時單一并行度也能達到13000+QPS。
經過多輪優化后,目前實時維表支撐了幾十億級別維表的秒級更新操作,保障了實時指標的準確輸出。
4.3 DWD層構建
DWD明細層是實時數倉重要的中間層,向上承接了ODS層的數據細化與維表更新,向下負責了指標的計算,它直接決定了數據的準確性及計算鏈路的復雜度。
我們在設計dwd層時重點關注了它與離線明細的交互性。我們目標是打通實時、離線間的數據孤島問題,所以在字段設計期間,我們就充分參考了離線數倉的數據模型。
-
在離線明細層拆分邏輯基礎上又額外補充了一些字段信息,保障數據一致性及實時場景的全覆蓋
-
保留了實時維表的關鍵信息,計算指標時可省去很多join操作,降低集群壓力
MaxCompute與Hologres已在底層無縫打通,我們依據其特性構建了多場景明細層應用方式。
1.實時報表展示
我們在實時明細層中增加了大量維表字段,對于各類新增、留存、回流等指標,可不用再join維表直接進行單表聚合統計得出。
對于一些累計指標,我們在Hologres中構建了ODPS外表以獲取其保存的離線數據,再與當日實時數據結合,將T+1產出的指標變為實時產出,極大的提高了運營效率。
2.實時信息拉取
對于一些特殊的離線場景,我們需要進行大數據量的離線計算,同時又希望獲取到最新的實時用戶信息,而不是T-1的數據。
針對這種情況,我們在ODPS中構建了Hologres實時外表,利用其實時直讀能力,用離線引擎讀取實時信息進行大數據量的復雜計算。使其可以充分利用MaxCompute的多級分區過濾和算子下推來優化查詢速度。
明細層的實時化構建,打破了傳統數倉中離線、實時數據孤島化的壁壘,使指標計算可在實時-離線中任意切換,全面推進了離線指標實時化的進程。
4.4 ADS層構建與重寫策略
ADS層是實時指標的重要輸出窗口,其易用性、準確性、及其響應速度是我們優先考慮的方面,為了平衡各方面的性能,我們采用了大寬表+行列共存的模式進行構建。
1.指標碎片化問題
實時數倉的指標層,往往會面臨指標碎片化的問題,即單獨的一兩個指標就占用一張實時表,隨著指標數的增多,實時表的數量會越來越多,給下游取數帶來很大的不便。
因此,在應用層的構建上,我們充分利用Hologres的局部更新能力,構建指標大寬表,將大多數實時指標計算維度規范化,統一寫入一張實時指標寬表中,解決業務增長帶來的指標碎片化問題。
-
支持多聚合維度、多統計維度指標擴展
-
國內、海外指標層合表,統一對外提供服務
-
寬表構建,降低下游取數難度
2.指標復雜聚合問題
在實時數倉應用之前,我們采用MySQL作為應用層的載體,MySQL可以賦予指標較高的點查性能,但是對于復雜的指標關聯聚合就顯的比較吃力,往往會帶來使用體驗上的下降。
通過將Hologres底表設置成行列共存,數據查詢時,優化器會根據SQL,解析出對應的執行計劃,執行引擎會根據執行計劃判斷走行存還是列存,大大提升了應用層的查詢效率。
行列共存的數據在底層存儲時會存儲兩份,一份按照行存格式存儲,一份按照列存格式存儲,因此會帶來更多的存儲開銷。但對于使用方來說,行列共存意味著更靈活的使用方式,使一張表同時擁有行列和列存的能力,既支持高性能的基于PK點查,又支持OLAP分析。
3.高亂序數據重寫策略
在Flink流式語義中,當數據正常流入時,watermark會正常推進,少量低亂序數據也可通過各類延遲策略進行解決,保障指標的正常輸出。但是當多并行度數據重刷時,數據會處于高亂序狀態,此時watermark的推進就會異常,導致中間狀態數據缺失。常見的有在使用CUMULATE窗口按分鐘計算累加指標時,若進行數據重刷,則會因數據亂序導致中間狀態缺失,只會更新最新時間點的數據,中間時間點的數據出現計算異常。同時,常用的延遲策略,table.exec.emit.allow-lateness參數在CUMULATE窗口中也還未被支持,給這類數據的修復帶來了很大的麻煩。
針對以上情況,我們開發了與CUMULATE窗口配套的保障程序,其利用實時明細層進行數據補全計算,再刷寫入指標層,可在2~5分鐘內修復中間缺失狀態。在刷寫過程中,我們先將指標寫入臨時表中作為中轉,再刷寫入結果表,用于防止長時間的寫入操作引起的鎖表問題,導致寫入ads報表的Flink程序失敗。
五、現狀與展望
通過將Hologres引入架構,我們對經典Lambda架構進行了全面的優化升級,避免了Lambda架構中眾多組件帶來的高運維成本,同時實現了存儲層面的流批一體,使離線與實時數據可以無縫交互。目前,Hologres實時數倉已全面應用于B站游戲的各類數據應用場景,涉及報表展示、運營分析、算法風控、廣告投放等各個領域,服務于數百款游戲的實時取數需求,全面推進了數據分析的實時化。
下一步我們將針對以下方面進行建設:
1.完善實時指標建設
原來點到點式的實時指標計算方式面臨著開發周期冗長的問題,而實時數倉的指標開發方式,可從任意數據切面進行接入,能大大提高數據的復用性,使我們可以完成更加復雜多樣的指標建設,逐步實現離線指標的全面實時化。
2.擴展實時明細層應用
通過與MaxCompute的存儲直連,我們已實現了DWD明細層的秒級入庫更新,這相比傳統離線數倉明細層的T+1更新有了質的飛躍,在應用層方面也將賦予業務更大實時化空間,推進對實時明細層的應用將是我們下一步的重點工作。
3.研發數據實時解析
實時數倉目前主要針對的是運營數據,針對研發數據的相關解析還主要是通過離線方式。可依托已有經驗,對重點游戲建立研發數據實時倉庫,推進研發數據分析的實時化進程。
-End-
作者丨指尖



-- 第六部分:JS集合與映射在 WPS 的應用)
)
)



)



)



)

