自從開始做自然語言處理的業務,TF-IDF就是使用很頻繁的文本特征技術,他的優點很多,比如:容易理解,不需要訓練,提取效果好,可以給予大規模數據使用,總之用的很順手,但是人無千面好,花無百日紅,TF-IDF也有一些局限的地方,這次我們聊聊忽略詞序的問題和解決的思路。
忽略詞序
TF-IDF主要是計算詞頻和逆向詞頻了計算文本特征的(一個詞在文檔中出現的頻率越高(TF),同時在所有文檔中出現的頻率越低(IDF),則該詞對當前文檔的代表性越強。),那么對于詞的位置(就是詞的順序)實際上考慮的不多,但是中文當中,詞的位置可能導致反轉的效果,網上最多的舉例就是:‘人咬狗’和‘狗咬人’。那么這樣就導致了忽略詞序的問題。
解決思路
一、基礎改進方法
1. N-gram特征擴展
思路:將相鄰詞的組合作為新特征
from sklearn.feature_extraction.text import TfidfVectorizer ? # 使用二元語法(bigram) vectorizer = TfidfVectorizer(ngram_range=(1, 2)) ?# 同時包含unigram和bigram
優點:
-
簡單直接,兼容現有TF-IDF流程
-
能捕獲局部詞序關系
缺點:
-
特征空間爆炸(n越大,維度越高)
-
仍無法捕獲長距離依賴
2. 滑動窗口加權
思路:給窗口內的詞對添加位置權重
from collections import defaultdict ? def sliding_window_tfidf(docs, window_size=3):# 先計算普通TF-IDF# 然后為窗口內的詞對添加額外權重co_occur = defaultdict(float)for doc in docs:words = doc.split()for i in range(len(words)-window_size+1):window = words[i:i+window_size]for j in range(len(window)):for k in range(j+1, len(window)):pair = (window[j], window[k])co_occur[pair] += 1# 將共現信息融入TF-IDF權重
二、進階混合方法
3. TF-IDF與詞嵌入結合
思路:用詞向量補充語義信息
import numpy as np from gensim.models import Word2Vec ? # 訓練或加載詞向量模型 w2v_model = Word2Vec(sentences, vector_size=100, window=5, min_count=1) ? def enhanced_tfidf(doc):words = doc.split()tfidf_vec = tfidf_model.transform([doc]) ?# 常規TF-IDFw2v_vec = np.mean([w2v_model.wv[word] for word in words if word in w2v_model.wv], axis=0)return np.concatenate([tfidf_vec.toarray()[0], w2v_vec]) ?# 拼接兩種特征
4. 短語檢測預處理
思路:先識別固定短語再計算TF-IDF
from gensim.models.phrases import Phrases ? # 自動檢測常見短語 phrases = Phrases(sentences) doc_with_phrases = ["_".join(words) for words in phrases[sentences]] ? # 然后在這些處理后的文本上計算TF-IDF
三、最新預訓練模型方法
5. BERT + TF-IDF混合
思路:結合上下文嵌入與傳統特征
from transformers import BertTokenizer, TFBertModel
import tensorflow as tf
?
bert_model = TFBertModel.from_pretrained('bert-base-chinese')
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
?
def get_bert_tfidf_features(text):# BERT特征inputs = tokenizer(text, return_tensors="tf", truncation=True, padding=True)outputs = bert_model(**inputs)bert_features = tf.reduce_mean(outputs.last_hidden_state, axis=1)# TF-IDF特征tfidf_features = tfidf_vectorizer.transform([text])# 合并特征return tf.concat([bert_features, tfidf_features.toarray()], axis=1)
四、設想
-
評估指標選擇:
-
對于分類任務:準確率/F1值
-
對于檢索任務:MAP/MRR/NDCG
-
計算開銷:特征維度/推理時間
-
-
實施路線圖:
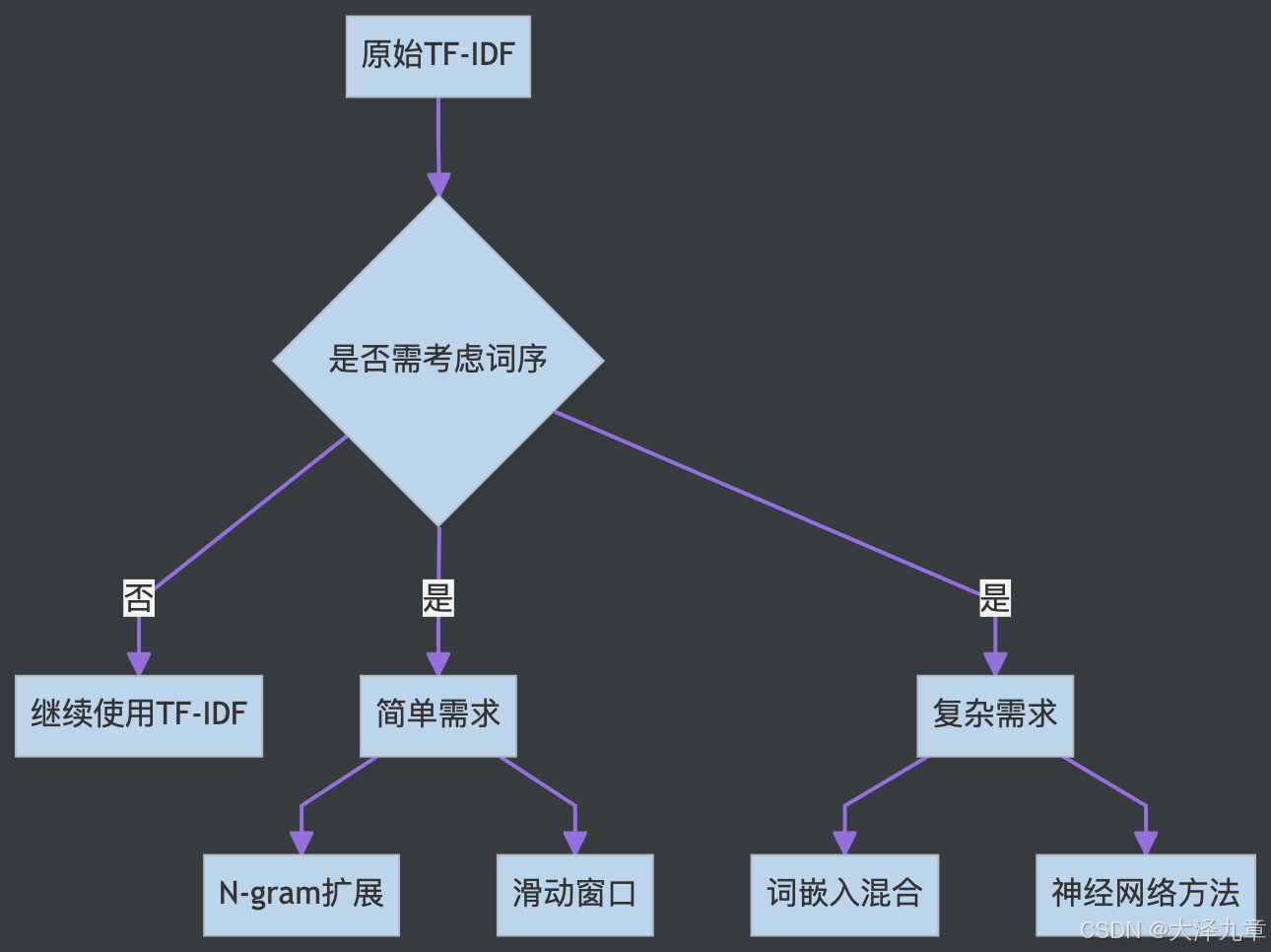
-
資源權衡:
-
低資源環境:N-gram + 短語檢測
-
中等資源:TF-IDF + 詞嵌入
-
充足資源:BERT/Transformer混合模型
-
當然還有很多方法,比如基于RNN也可以解決,由于篇幅就不在列舉了,歡迎各位給出跟多的方法大家一起交流。上面的這些方法可以根據具體場景組合使用,例如先進行短語檢測,再使用N-gram擴展,最后與詞向量特征拼接,能在多個層面上改善原始TF-IDF忽略詞序的問題。





)











![[WUSTCTF2020]CV Maker1](http://pic.xiahunao.cn/[WUSTCTF2020]CV Maker1)

