@TOC
本文僅為記錄學習軌跡,如有侵權,聯系刪除
一、環境說明
使用前必須檢查以下環境
(1)python編譯環境
(2)python腳本執行所需要的庫,具體看代碼(main.py)import導入的部分庫
(3)確保電腦可以正常連接網絡,可以正常訪問淘寶鏈接
備注:博主測試的python環境是3.8.8,盡量用python3版本
二、代碼說明
代碼請查看main.py,先看需要引入的庫的部分,使用前需要保證這些庫的正確引入,重點需要注意的是DrissionPage庫的引入,該庫用于爬取數據
共分為兩個主要方法,一個是get_data方法,用于爬取數據,另一個是save_to_csv方法,用于保存數據

_main_是主函數入口,這里默認爬取30頁的數據,可以根據實際情況修改要爬取的頁數,不過需要注意的是,淘寶有很嚴格的反爬機制,如果爬取太多頁的數據,可能會觸發淘寶的相關反爬機制,例如限流、返回異常數據、或者彈窗驗證碼等操作。
三、代碼執行
(1)前期準備
先打開谷歌瀏覽器,訪問淘寶頁面,然后先進行登錄,這是為了繞過淘寶的登錄驗證機制,以前好像不用登錄就可以搜索商品數據,現在好像有限制,而且為了避免引起不必要的麻煩,所以干脆先登錄淘寶
(2)執行代碼
博主測試時用的pycharm執行的代碼,不過用python自帶的編譯器也可以,執行的時候代碼會自動打開谷歌瀏覽器,然后自動在輸入框輸入商品名稱,爬取數據后,會自動在頁面點擊下一頁按鈕進行換頁,然后再爬取數據,直到代碼設置的頁數都爬取完成,以下截圖來自博主親測截圖如下
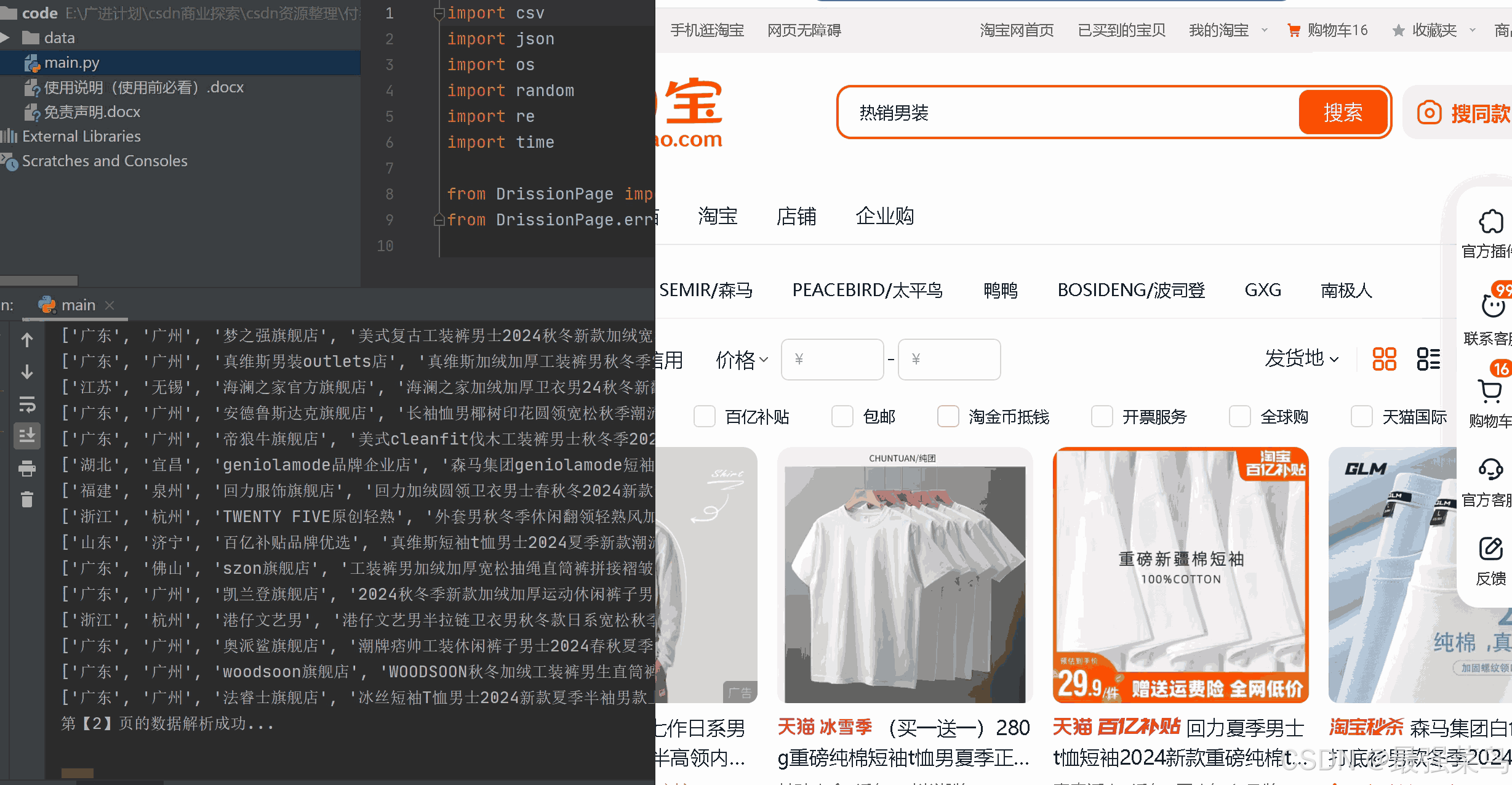
數據爬取完成后,會在main.py同級目錄下生成一個data目錄,里面存放爬取的數據,格式為csv
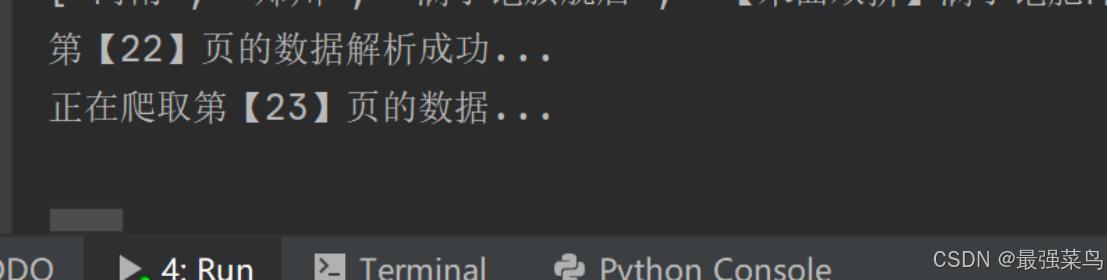
注意,如果出現以下截圖,例如卡在爬取某一頁的日志,請耐心等待,代碼設置了最長兩分鐘的監聽時長,如果超時系統會有日志打印
)









)
與殘差連接(Residual Connection))




)


