論文解讀在這里
File path | Description
```/pretrains
┣ 📂 models
┃ ┗ 📜 config.yaml
┃ ┗ 📜 v1-5-pruned.ckpt┣ 📂 generation
┃ ┗ 📜 checkpoint_best.pth ┣ 📂 eeg_pretain
┃ ┗ 📜 checkpoint.pth (pre-trained EEG encoder)/datasets
┣ 📂 imageNet_images (subset of Imagenet)┗ 📜 block_splits_by_image_all.pth
┗ 📜 block_splits_by_image_single.pth
┗ 📜 eeg_5_95_std.pth /code
┣ 📂 sc_mbm
┃ ┗ 📜 mae_for_eeg.py
┃ ┗ 📜 trainer.py
┃ ┗ 📜 utils.py┣ 📂 dc_ldm
┃ ┗ 📜 ldm_for_eeg.py
┃ ┗ 📜 utils.py
┃ ┣ 📂 models
┃ ┃ ┗ (adopted from LDM)
┃ ┣ 📂 modules
┃ ┃ ┗ (adopted from LDM)┗ 📜 stageA1_eeg_pretrain.py (main script for EEG pre-training)
┗ 📜 eeg_ldm.py (main script for fine-tuning stable diffusion)
┗ 📜 gen_eval_eeg.py (main script for generating images)┗ 📜 dataset.py (functions for loading datasets)
┗ 📜 eval_metrics.py (functions for evaluation metrics)
┗ 📜 config.py (configurations for the main scripts)```目錄
dataset.py
gen_eval_eeg.py
stageA1_eeg_pretrain.py
eeg_ldm.py
gen_eval_eeg.py
dataset.py
一、基礎工具函數模塊

"沿時間軸進行環形填充"是一種信號處理技術,當數據長度不足時,用數據的起始部分循環填充到末尾(類似"循環播放")
對比其他填充方式:
零填充(Zero-pad):
[1,2,3] -> [1,2,3,0,0]環形填充:
[1,2,3] -> [1,2,3,1,2]參數解讀:
((0,0), (0, pad_size)):表示只在第二個維度(時間軸)右側填充
'wrap':指定環形填充模式輸入:
x.shape = (128, 500)(128個EEG通道,500個時間點)
patch_size = 16(每個時間塊包含16個時間點)計算需要填充的長度:
當前時間點:500
需要達到?
N × patch_size?的最小長度
ceil(500 / 16) = 32?塊 →?32×16=512需填充:
512 - 500 = 12?個時間點填充操作:從每個通道的起始位置取前12個時間點,拼接到末尾
為什么選擇環形填充?
填充方式 優點 缺點 適用場景 環形填充 保持信號周期性
避免邊界突變可能引入周期性假象 EEG/ECG等準周期信號 零填充 實現簡單 引入高頻噪聲 通用場景 鏡像填充 平滑邊界 計算復雜 圖像處理 對于EEG信號:
具有準周期性(alpha/beta波等)
避免零填充導致的頻譜泄漏(spectral leakage)
更適合后續的塊處理(patch劃分)

Z-score標準化(又稱標準差標準化)是一種常見的數據標準化方法,其核心是通過線性變換將原始數據轉換為均值為0、標準差為1的分布。
對于一組數據?x,其標準化值?z的計算公式為:z=(x?μ)/σ
μ:數據的均值(平均值)
σ:數據的標準差(反映數據離散程度)
二、時間序列處理模塊
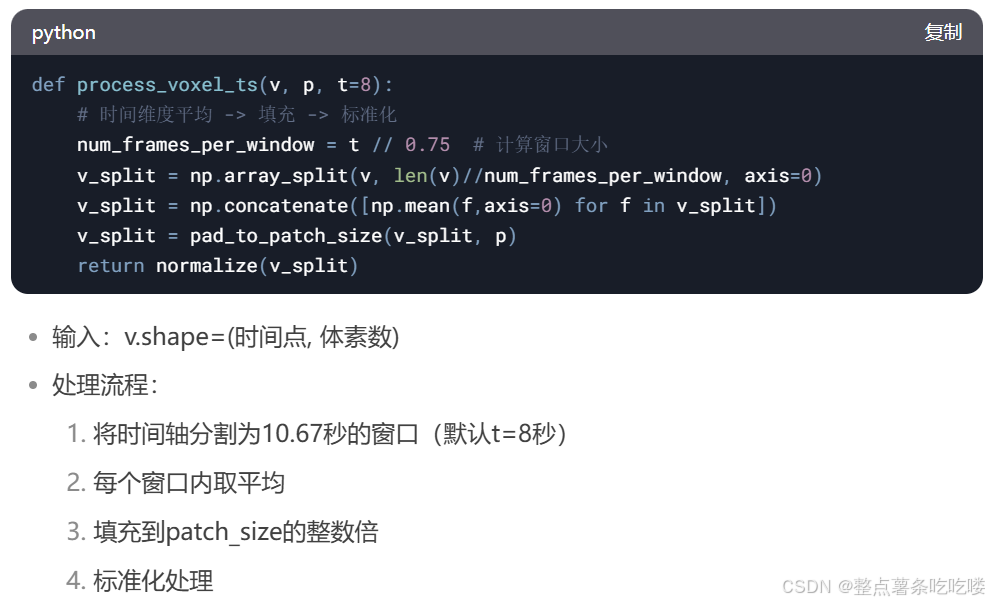
?時間窗口
定義:將連續的EEG信號按固定時長分段處理
目的:
降低計算復雜度
捕捉局部時域特征
匹配后續處理(如傅里葉變換、模型輸入長度)
三、數據增強模塊

四、核心數據集類
1. 預訓練數據集
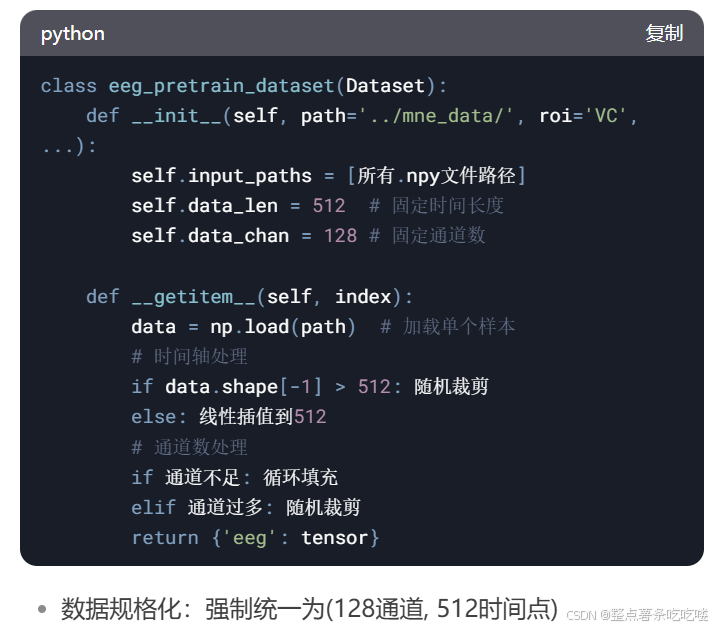
2. 完整EEG-Image數據集
class EEGDataset(Dataset):def __init__(self, eeg_signals_path):loaded = torch.load(eeg_signals_path) # 加載預處理數據self.data = [{'eeg': tensor, # EEG信號 [通道, 時間]'label': int, # 類別標簽 'image': 'n01440764' # ImageNet ID}, ...]def __getitem__(self, i):# EEG處理eeg = data[i]['eeg'].t() # 轉置為[時間, 通道]eeg = eeg[20:460] # 選擇有效時間窗口eeg = interp1d(...) # 插值到512點# 圖像處理image_path = 'n01440764/n01440764_10026.JPEG'image = Image.open(path)image = processor(image) # CLIP預處理五、數據劃分模塊
class Splitter:def __init__(self, dataset, split_path):loaded = torch.load(split_path)self.split_idx = loaded['splits'][0]['train'] # 取第一個劃分方案# 過濾條件:# 1. EEG長度在450-600之間# 2. 被試匹配(當subject!=0時)六、圖像處理模塊
class random_crop:def __call__(self, img):if 概率p: 執行隨機裁剪else: 返回原圖def normalize2(img):return img * 2.0 - 1.0 # 歸一化到[-1,1]七、重要技術細節
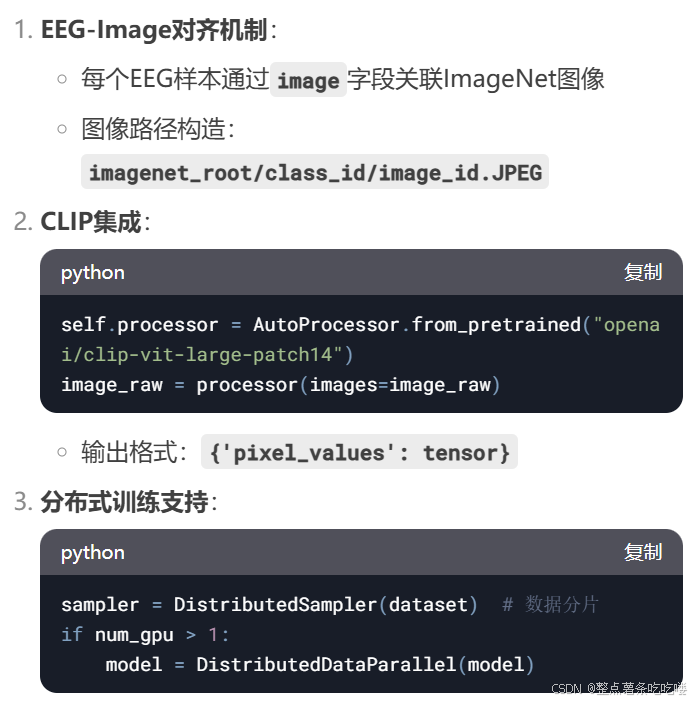
對齊流程:
sequenceDiagramparticipant EEG_Dataparticipant ImageNetEEG_Data->>EEGDataset: 加載樣本iEEGDataset->>EEG_Data: 讀取self.data[i]["image"]字段EEGDataset->>ImageNet: 根據ID構造路徑ImageNet-->>EEGDataset: 返回對應圖像EEGDataset->>Model: 返回{'eeg':eeg, 'image':image}gen_eval_eeg.py
基于MAE (Masked Autoencoder) 的EEG信號預訓練框架,主要包含以下核心模塊:
-
環境配置與工具函數
-
數據加載與預處理
-
模型定義與訓練流程
-
可視化與日志記錄
-
分布式訓練支持
1. 核心模塊解析
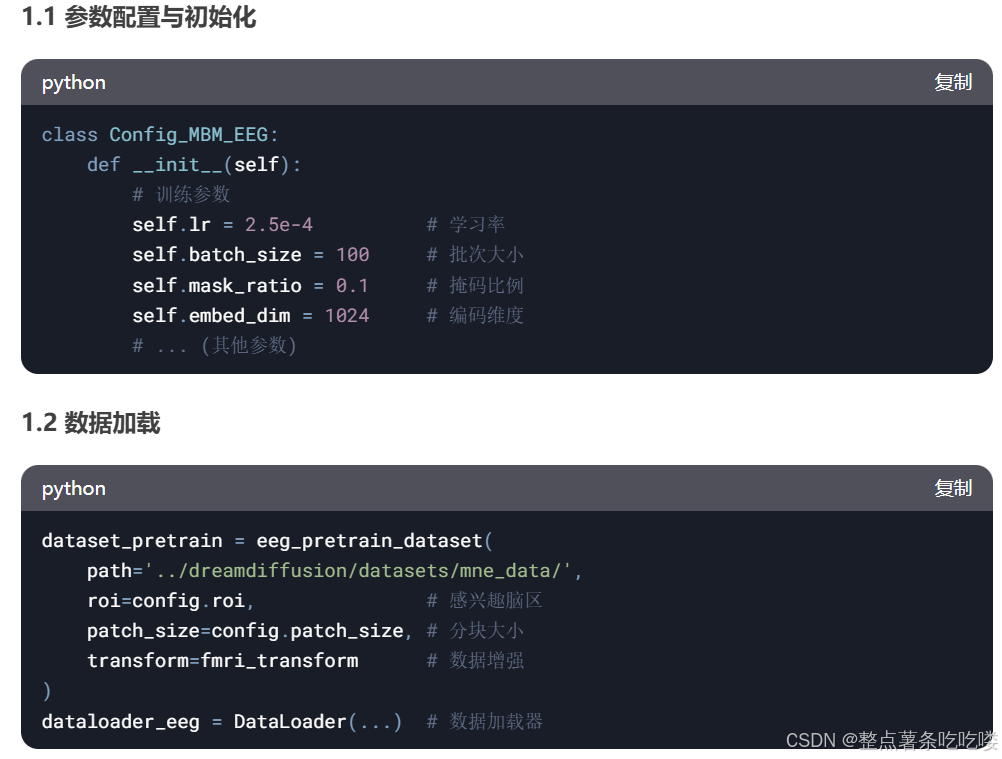

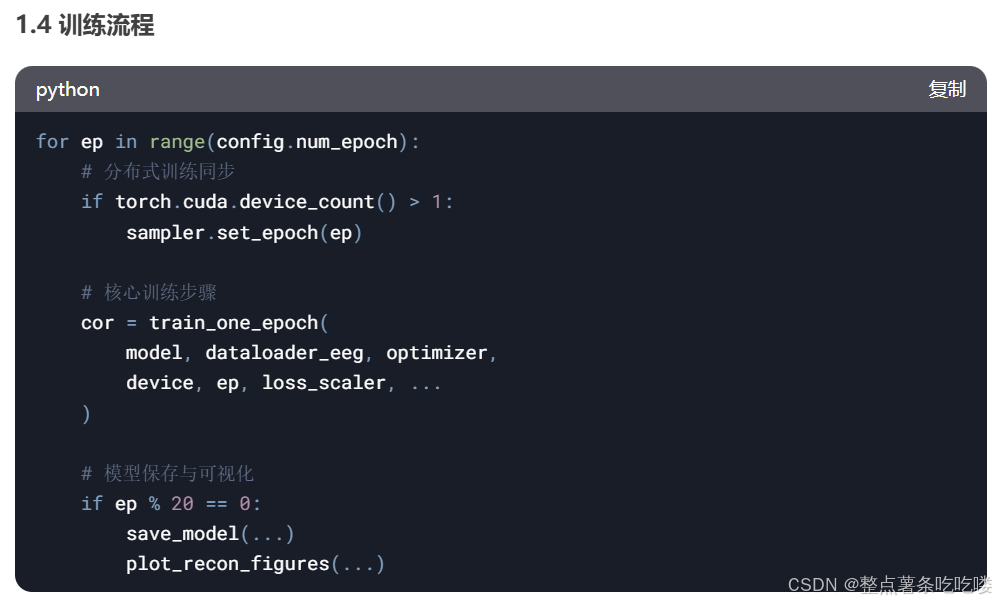
2. 關鍵實現細節

4. 可視化模塊
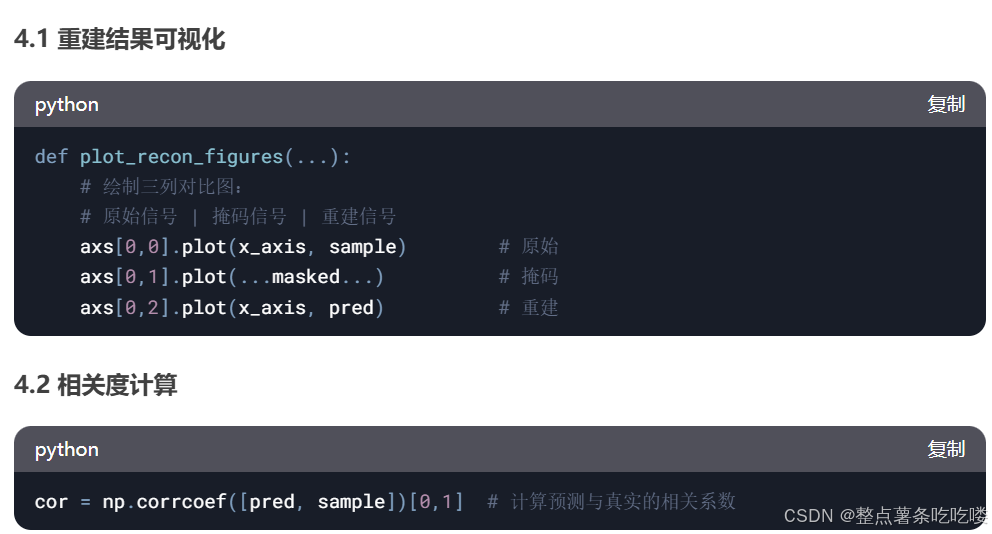
代碼流程圖
graph TDA[初始化配置] --> B[加載數據集]B --> C[構建MAE模型]C --> D[初始化優化器]D --> E[訓練循環]E --> F{達到保存點?}F -- 是 --> G[保存模型+可視化]F -- 否 --> EG --> H[完成訓練]stageA1_eeg_pretrain.py
Pre-training on EEG data
用于大量訓練的數據集從MOABB上下載,還沒學會,,,,
eeg_ldm.py
Finetune the Stable Diffusion with Pre-trained EEG Encoder
實現了一個基于Latent Diffusion Model (LDM) 的EEG信號到圖像生成的完整流程:
一、代碼整體架構
本代碼是DreamDiffusion項目的第二階段(Stage B),主要包含以下核心模塊:
-
配置管理(Config_Generative_Model)
-
數據加載與預處理(create_EEG_dataset)
-
生成模型定義(eLDM)
-
訓練流程控制(main函數)
-
圖像生成與評估(generate_images)
-
實驗日志記錄(wandb集成)
二、核心組件詳解
1. 配置管理
class Config_Generative_Model:def __init__(self):# 項目參數self.seed = 2022self.root_path = '.'self.eeg_signals_path = 'datasets/eeg_5_95_std.pth'# 模型參數self.pretrain_mbm_path = 'pretrains/generation/checkpoint.pth'self.pretrain_gm_path = 'pretrains/stable-diffusion-v1-5'# 訓練參數self.batch_size = 25self.lr = 5.3e-5self.num_epoch = 5002. 數據加載
-
加載EEG信號和對應的ImageNet圖像路徑
-
應用兩種圖像變換:
-
訓練集:隨機裁剪+歸一化(
img_transform_train) -
測試集:僅歸一化(
img_transform_test)
-
-
返回包含EEG-圖像對的數據集
3. 生成模型(eLDM)
-
雙條件機制:同時接受EEG特征和CLIP文本特征
-
基于Latent Diffusion架構
-
支持從檢查點恢復訓練
5. 圖像生成與評估
def generate_images(generative_model, dataset, num_samples, ddim_steps):grid, samples = generative_model.generate(dataset, num_samples, ddim_steps)# 保存圖像網格Image.fromarray(grid).save('samples.png')# 計算評估指標metrics = get_eval_metric(samples)return metrics評估指標:
-
像素級:MSE, PCC, SSIM
-
語義級:Top-1分類準確率
三、關鍵技術細節
1. 條件擴散模型
graph LRA[EEG信號] --> B[EEG編碼器]C[CLIP文本編碼] --> D[LDM UNet]B --> DD --> E[圖像生成]2. 雙階段訓練策略
-
階段A:預訓練EEG編碼器(MAE架構)
-
階段B:微調擴散模型(本代碼)
3. 圖像變換流水線
img_transform_train = transforms.Compose([normalize, # 歸一化到[-1,1]transforms.Resize(512), # 調整大小random_crop(448, p=0.5), # 隨機裁剪(數據增強)transforms.Resize(512), # 再次調整channel_last # 通道順序轉換
])gen_eval_eeg.py
Generating Images with Trained Checkpoints
實現了EEG信號到圖像生成的評估流程:
一、代碼整體架構
這段代碼是DreamDiffusion項目的評估部分,主要功能是加載預訓練好的生成模型,對EEG信號進行圖像生成并保存結果。核心模塊包括:
-
配置加載:從檢查點恢復實驗配置
-
數據準備:加載EEG測試數據集
-
模型初始化:構建條件擴散模型(eLDM)
-
圖像生成:使用訓練好的模型生成圖像
-
結果保存:存儲生成的圖像網格
二、核心組件詳解
圖像變換流程:
img_transform_test = transforms.Compose([normalize, # 歸一化到[-1,1]transforms.Resize((512,512)), # 調整尺寸channel_last # 通道順序轉換 (C,H,W)->(H,W,C)
])-
數據規格:
-
輸入EEG形狀:
(num_samples, 128通道, 512時間點) -
輸出圖像尺寸:512×512
-
3. 模型初始化
generative_model = eLDM(pretrain_mbm_metafile, # EEG編碼器配置num_voxels, # 輸入維度=EEG特征長度device=device, # 計算設備pretrain_root=config.pretrain_gm_path, # SD權重路徑ddim_steps=config.ddim_steps # 擴散步數(默認250)
)
generative_model.model.load_state_dict(sd['model_state_dict']) # 加載訓練權重模型架構特點:
-
雙條件機制:EEG特征 + CLIP文本特征
-
基于Latent Diffusion架構
-
使用DDIM采樣方法
4. 圖像生成
# 生成訓練集樣本(10個實例)
grid, _ = generative_model.generate(dataset_train, num_samples=config.num_samples,ddim_steps=config.ddim_steps,HW=config.HW, # 圖像尺寸limit=10
)# 生成測試集樣本
grid, samples = generative_model.generate(dataset_test,num_samples=config.num_samples,ddim_steps=config.ddim_steps,state=sd['state'] # 隨機狀態恢復
)生成參數:
| 參數 | 含義 | 典型值 |
|---|---|---|
num_samples | 每樣本生成數量 | 5 |
ddim_steps | 擴散采樣步數 | 250 |
HW | 圖像高寬 | [512,512] |
limit | 最大生成樣本數 | 10 |
三、關鍵技術細節
1.?條件生成流程
sequenceDiagramparticipant EEGparticipant Modelparticipant ImageEEG->>Model: 輸入EEG信號(128ch×512t)Model->>Model: 通過EEG編碼器提取特征Model->>Model: 擴散模型條件生成Model->>Image: 輸出512×512圖像這個生成代碼很有問題啊,一直報錯,類似這樣,很多人都出現了,但目前無法解決,,,,


教程)




![[250403] HuggingFace 新增檢查模型與電腦兼容性的功能 | Firefox 發布137.0 支持標簽組](http://pic.xiahunao.cn/[250403] HuggingFace 新增檢查模型與電腦兼容性的功能 | Firefox 發布137.0 支持標簽組)

 和 ZSet(例如排行榜) 的詳細對比,涵蓋定義、特性、命令、適用場景及總結表格)



)




)
