目錄
一、紅樓夢數據分析
(1)紅樓夢源文件
(2)數據預處理——分卷實現思路
(3)分卷代碼
二、分卷處理,刪除停用詞,將文章轉換為標準格式
1.實現的思路及細節
2.代碼實現(遍歷所有卷的內容,并添加到內存中)
3、代碼實現“1”中剩余的步驟
(1)數據展示
(2)代碼及方法
三、計算紅樓夢分詞后文件的 TF_IDF的值
一、紅樓夢數據分析
(1)紅樓夢源文件
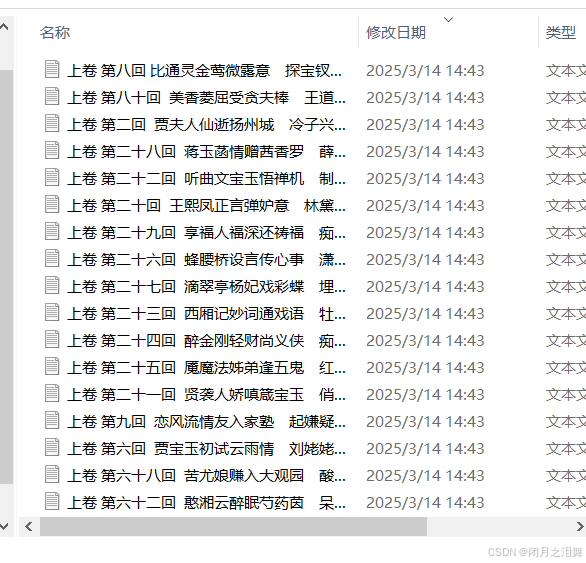
預計要實現的效果:觀察下面的文件截圖,我們希望將紅樓夢每一回的文件內容存在文件中,將文件的“上卷 第一回 甄士隱夢幻識通靈 賈雨村風塵懷閨秀”第幾回,這一整行作為文件的名字,每一回作為一個文件,儲存到指定的路徑下。



最終效果:
(2)數據預處理——分卷實現思路
(1)使用os是python的標準庫,讀取紅樓夢源文件
(2)以寫的格式打開一個以"紅樓夢開頭.txt"為名字的文件,用以存儲文件開頭的內容,如下:

(3)使用for循環,逐行讀取文件內容,通過觀察,每一回的開頭,都會有“卷 第 ”這樣的字,如下

我們可以通過in來判斷是否讀取到這一行,滿足條件則對這行執行strip()方法,去除行前后的空格和換行符。
(4)使用os.path.join方法構建一個完整的路徑,將路徑(根據自己的實際情況來寫)和文件名拼接在一起,這里是把前面寫的路徑,與后面讀取的文件名拼接起來了,分卷最好放置在一個單獨的文件夾中,為了更有條理。
os.path.join 會自動添加成斜杠,會根據系統自動補充路徑中的斜杠,對不同系統有適配性,windows 斜杠\,macos 斜杠/,Linux 斜杠 /。
效果
![]()
(5)關閉先前存儲文件開頭的juan_file這個文件,使用close()方法。
(6)按照上面第(4)步拼接的路徑,打開文件,然后使用continue跳出本次循環,向文件中逐行寫入第一回的內容
(7)發現在每一回的下一行都會有這樣一行內容,我們希望將其剔除,剔除方法如下:
![]()
if '手機電子書·大學生小說網' in line: #過濾掉無用的行 continue
這里表示如果發現讀取的行中存在'手機電子書·大學生小說網'這個內容,就直接跳出循環,即跳過這一行,循環讀取文件下一行的內容。
(8)按照上面的方法不斷地循環,最終我們就能將整個紅樓夢文件按照每一回存儲在一個文件中的格式將紅樓夢分卷處理。
效果:

(3)分卷代碼
import osfile=open("./data/紅樓夢/紅樓原數據/紅樓夢.txt",encoding='utf-8') #讀取紅樓夢原數據集
juan_file=open('./data/紅樓夢/紅樓夢開頭.txt','w',encoding='utf-8') #這里會創建并打開,以紅樓夢開頭.txt為名字的文件
#逐行讀取讀取紅樓夢.txt中的文件內容
for line in file:if '卷 第'in line: #為了將第幾回這一行,每一回的標頭作為文件的名字,這里需要能夠識別到這樣的行,通過文字匹配來匹配,如果滿足這個條件則會執行下面的其他代碼juan_name=line.strip()+'.txt' #去除行前后的空格和換行符,與.txt拼接成文件名path = os.path.join('.\\data\\紅樓夢\\分卷\\',juan_name) #使用os.path.join方法將路徑和文件名拼接在一起print(path)juan_file.close()juan_file=open(path,'w',encoding='utf-8')continueif '手機電子書·大學生小說網' in line: 過濾掉無用的行continuejuan_file.write(line) #將文件的其他內容寫入到juan_file中
juan_file.close()二、分卷處理,刪除停用詞,將文章轉換為標準格式
(詞之間通過空格分隔),即進行分詞處理
1.實現的思路及細節
(1)遍歷所有卷的內容,并添加到內存中
(2)將紅樓夢詞庫添加到jieba庫中(jieba不一定能識別出紅樓夢中所有的詞,需要手動添加詞庫)
(3)讀取停用詞(刪除無用的詞)
(4)對每個卷進行分詞,
(5)將所有分詞后的內容寫入到分詞后匯總.txt
分詞后匯總.txt的效果為:

可以看出,紅樓夢的原文被分成上圖的格式,詞與詞之間以空格分隔,同時每一行就是一個分卷的內容,也就是每一行是一回的內容。
2.代碼實現(遍歷所有卷的內容,并添加到內存中)
(1)os.walk():os.walk是直接對文件夾進行遍歷,總共會有三個返回值第一個是文件的路徑,第二個是路徑下的文件夾,第三個是路徑下的文件。
for root,dirs,files in os.walk(r"./data/紅樓夢/分卷"):
這里我們分別用三個變量去接收,os.walk的返回值。
import pandas as pd
import os
filePaths=[] #用于保存文件的路徑
fileContents=[] #用于保存文件的內容for root,dirs,files in os.walk(r"./data/紅樓夢/分卷"):for name in files: #對files進行遍歷,依次取出文件操作filePath=os.path.join(root,name) #將文件的路徑和名字拼接到一起形成一個完整的路徑,并將路徑存儲在filepath這個變量中print(filePath)filePaths.append(filePath) #將完整路徑存儲到filepathS這個列表中f=open(filePath,'r',encoding='utf-8') #根據上面拼接好的路徑,打開文件fileContent=f.read() #讀取文章內容,一次性讀取全文f.close() #關閉文件減少內存占用fileContents.append(fileContent) #將文章內容添加到filecontents這個列表中
corpos=pd.DataFrame( #使用pandas的DataFrame方法,將filepath和filecontent存儲成dataframe類型{"filePath":filePaths,"fileContent":fileContents}
)
print(corpos)corpos內部存儲的效果:每一行是一個分卷的內容,第一列是文件存儲的路徑,第二列是每個分卷的內容。

3、代碼實現“1”中剩余的步驟
(1)數據展示
紅樓夢詞庫(紅樓夢詞庫.txt):

停用詞(StopwordsCN.txt):

(2)代碼及方法
load_userdict():是jieba庫中加載新詞到jieba的辭海中,針對海量的新詞可以使用這個方法,對文件格式也有要求,文件的每一行是一個停用詞。
iterrows():遍歷pandas數據,逐行讀取,返回值有兩個,行索引和pandas類型數據的全部內容
“if seg not in stopwords.stopword.values and len(seg.strip())>0:”其中stopwords.stopword.values是stopwords變量下stopword列對應的值調用。
import jiebajieba.load_userdict(r".\data\紅樓夢\紅樓原數據\紅樓夢詞庫.txt")
#讀取停用詞
stopwords=pd.read_csv(r"./data/紅樓夢/紅樓原數據/StopwordsCN.txt",encoding='utf-8',engine='python',index_col=False)
file_to_jieba=open(r'./data/紅樓夢/分詞后匯總.txt','w',encoding='utf-8')
for index,row in corpos.iterrows():juan_ci=''filePath=row['filePath'] #獲取文件路徑fileContent=row['fileContent'] #獲取文件內容 segs=jieba.cut(fileContent) #使用cut()方法對第一行的內容進行切分,也可以使用lcut(),并將分詞后的結果存儲在segs中for seg in segs: #利用for循環過濾掉文章中的停用詞if seg not in stopwords.stopword.values and len(seg.strip())>0:#if如果滿足,當前詞不在停用詞中,并且詞不為空的前提下,將這個詞添加到juan_ci+保存juan_ci+=seg+' '#將沒一回的內容寫入到file_to_jieba這個文件中,我們希望每一回在同一行,所以這里在每一回的內容后加上"\n"換行符file_to_jieba.write(juan_ci+'\n')file_to_jieba.close() #等所有分卷的內容全部寫入后關閉file_to_jieba(分詞后匯總.txt)這個文件,減少內存的占用為什么總是把處理完成的文件保存下來呢,預處理結束將文件保存到本地,這樣做的目的是代碼分塊化實現,防止調試代碼時每次都要全部執行,每做一步將處理好的結果保存下來,可以加快調試的效率。
三、計算紅樓夢分詞后文件的 TF_IDF的值
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd#讀取分詞后匯總,并逐行讀取文件內容,存儲在corpos變量中
inFile = open(r"./data/紅樓夢/分詞后匯總.txt","r",encoding='utf-8')
corpos = inFile.readlines()#實例化對象,使用fit_transfrom計算每個詞的TF-IDF的值
vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)
print(tfidf)#使用get_feature_names方法獲取紅樓夢的所有關鍵詞
wordlist=vectorizer.get_feature_names()
print(wordlist)#將tfidf轉化為稀疏矩陣
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)#逐列排序,輸出tfidf排名前十的關鍵詞及TF-IDF值
for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False)print(f"第{i+1}回的關鍵詞是:{feature_rank[:10]}")wordlistte特征值的個數33703個為:
![]()
輸出效果為:我們就能得到每一回的關鍵詞以及對應的TF-IDF值

代碼匯總:
此處代碼為上面的整合,去除了部分注釋,可以將其放在一個.py文件中,安裝好指定的庫即可運行,需要注意文件的路徑與你自己的文件路徑對應,數據集文件可以到我的數據集中獲取(有單獨的一篇文章注明了數據集)
"""通過os系統標準庫,讀取紅樓夢的原始數據,并將每一回的數據文本存儲到不同的txt文件中。"""import osfile=open("./data/紅樓夢/紅樓原數據/紅樓夢.txt",encoding='utf-8') #讀取紅樓夢原數據集
juan_file=open('./data/紅樓夢/紅樓夢開頭.txt','w',encoding='utf-8') #這里會創建并打開,以紅樓夢開頭.txt為名字的文件
#逐行讀取讀取紅樓夢.txt中的文件內容
for line in file:if '卷 第'in line: #為了將第幾回這一行,每一回的標頭作為文件的名字,這里需要能夠識別到這樣的行,通過文字匹配來匹配,如果滿足這個條件則會執行下面的其他代碼juan_name=line.strip()+'.txt' #去除行前后的空格和換行符,與.txt拼接成文件名path = os.path.join('.\\data\\紅樓夢\\分卷\\',juan_name) #使用os.path.join方法將路徑和文件名拼接在一起print(path)juan_file.close()juan_file=open(path,'w',encoding='utf-8')continueif '手機電子書·大學生小說網' in line: #過濾掉無用的行continuejuan_file.write(line) #將文件的其他內容寫入到juan_file中
juan_file.close()import pandas as pd
import os
filePaths=[]
fileContents=[]for root,dirs,files in os.walk(r"./data/紅樓夢/分卷"):for name in files:filePath=os.path.join(root,name)print(filePath)filePaths.append(filePath)f=open(filePath,'r',encoding='utf-8')fileContent=f.read()f.close()fileContents.append(fileContent)
corpos=pd.DataFrame({"filePath":filePaths,"fileContent":fileContents}
)print(corpos)import jiebajieba.load_userdict(r".\data\紅樓夢\紅樓原數據\紅樓夢詞庫.txt")
stopwords=pd.read_csv(r"./data/紅樓夢/紅樓原數據/StopwordsCN.txt",encoding='utf-8',engine='python',index_col=False)
file_to_jieba=open(r'./data/紅樓夢/分詞后匯總.txt','w',encoding='utf-8')
for index,row in corpos.iterrows():juan_ci=''filePath=row['filePath']fileContent=row['fileContent']segs=jieba.cut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip())>0:juan_ci+=seg+' 'file_to_jieba.write(juan_ci+'\n')
file_to_jieba.close()from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pdinFile = open(r"./data/紅樓夢/分詞后匯總.txt","r",encoding='utf-8')
corpos = inFile.readlines()vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)
print(tfidf)wordlist=vectorizer.get_feature_names()
print(wordlist)df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False)print(f"第{i+1}回的關鍵詞是:{feature_rank[:10]}")


詳解)




)
)



 ─── linux第28課)

數據增強)



