本專欄深入探究從循環神經網絡(RNN)到Transformer等自然語言處理(NLP)模型的架構,以及基于這些模型構建的應用程序。
本系列文章內容:
- NLP自然語言處理基礎
- 詞嵌入(Word Embeddings)(本文)
- 循環神經網絡(RNN)、長短期記憶網絡(LSTM)和門控循環單元(GRU)
3.1 循環神經網絡(RNN)
3.2 長短期記憶網絡(LSTM)
3.3 門控循環單元(GRU) - 編碼器 - 解碼器架構(Encoder - Decoder Architecture)
- 注意力機制(Attention Mechanism)
- Transformer
- 編寫Transformer代碼
- 雙向編碼器表征來自Transformer(BERT)
- 生成式預訓練Transformer(GPT)
- 大語言模型(LLama)
- Mistral
1. 簡介(Introduction)
詞嵌入(Word embeddings)是自然語言處理(Natural Language Processing,NLP)領域的一個基礎概念。它們本質上是一種將單詞轉換為連續向量空間中的數值表示(即向量)的方法。其目標是捕捉單詞的語義含義,使得具有相似含義的單詞具有相似的向量表示。
這篇博客文章涵蓋了詞嵌入從基礎到高級的各個重要方面,確保讀者能夠全面理解這一主題及其在自然語言處理(NLP)和大語言模型(LLMs)背景下的演變。

詞嵌入(Word Embeddings)
定義:詞嵌入是單詞的密集、低維且連續的向量表示,它捕捉了語義和句法信息。
特點:
- 密集:與獨熱編碼(One-Hot Encoding)等稀疏表示不同,詞嵌入是密集的,這意味著它們的大多數元素都不為零。
- 向量空間:單詞被定位在一個向量空間中,從而可以進行數學運算和比較。
- 降維:為了提高計算效率和便于可視化,向量空間通常會被降維到較低的維度。
- 語義相似性:具有相似含義的單詞具有相似的嵌入。

示例
如果“國王(king)”由向量 v k i n g v_{king} vking?表示,“王后(queen)”由向量 v q u e e n v_{queen} vqueen?表示,這些向量之間的關系可以捕捉到性別差異,例如 v k i n g ? v m a n + v w o m a n ≈ v q u e e n v_{king} - v_{man} + v_{woman} \approx v_{queen} vking??vman?+vwoman?≈vqueen?。

詞嵌入的必要性
雖然上述內容確實有一定道理,但為什么我們要有足夠的動力去學習和構建這些詞嵌入呢?
- 對于語音或圖像識別系統而言,所有信息已經以豐富的密集特征向量的形式存在,這些向量嵌入在高維數據集中,比如音頻頻譜圖和圖像像素強度。
- 然而,當涉及到原始文本數據時,尤其是像詞袋模型(Bag of Words)這樣基于計數的模型,我們處理的是單個單詞,這些單詞可能有它們自己的標識符,但無法捕捉單詞之間的語義關系。
- 這會導致文本數據產生巨大的稀疏單詞向量,因此,如果我們沒有足夠的數據,由于維度災難(curse of dimensionality)的影響,我們最終可能得到效果不佳的模型,甚至會出現數據過擬合的情況。

詞嵌入是如何使用的?
- 它們被用作機器學習模型的輸入。
獲取單詞 -> 給出它們的數值表示 -> 用于訓練或推理。 - 用于表示或可視化在用于訓練它們的語料庫中任何潛在的使用模式。
讓我們舉個例子來理解詞向量是如何生成的。我們選取在某些條件下最常使用的情感,將每個表情符號轉換為一個向量,而這些條件將作為我們的特征。

2. 詞嵌入(Word Embeddings)基礎
2.1 理解向量和向量空間
在自然語言處理(Natural Language Processing,NLP)和詞嵌入(Word embeddings)的背景下,理解向量和向量空間是基礎的,因為它們構成了表示單詞及其關系的數學基礎。
什么是向量?
向量是一種既具有大小(長度)又具有方向的數學對象。簡單來說,向量可以被看作是一個有序的數字列表,它表示空間中的一個點。例如,在二維空間中,一個向量可以表示為:

其中 v 1 v_1 v1?和 v 2 v_2 v2?是該向量在兩個維度(例如, x x x軸和 y y y軸)上的分量。
在自然語言處理中,單詞在多維空間中被表示為向量,其中每個維度捕捉單詞含義的不同方面或特征。
什么是向量空間?
向量空間是一種由一組向量組成的數學結構,這些向量可以相加,并且可以與標量(數字)相乘,從而在同一空間內生成另一個向量。向量空間由其維度(例如,二維、三維等)來定義,維度指的是指定該空間內任何一點所需的坐標數量。
在詞嵌入的背景下,我們處理的是高維向量空間,通常具有數百甚至數千個維度。每個單詞都被映射到這個空間中的一個唯一向量。


向量如何表示單詞
當我們在向量空間中把單詞表示為向量時,目標是捕捉單詞的語義含義。具有相似含義或出現在相似上下文中的單詞,在向量空間中應該彼此靠近。訓練詞嵌入的過程是基于單詞在大型文本語料庫中出現的上下文來學習這些向量表示的。
例如,“國王(king)”和“王后(queen)”這兩個單詞可能由在向量空間中彼此靠近的向量來表示,因為它們共享相似的上下文(例如,皇室、領導地位)。
向量空間中的運算
向量空間允許我們執行各種在自然語言處理中很有用的運算:
- 加法和減法:
通過對向量進行加法或減法運算,我們可以探索單詞之間的關系。例如,著名的類比:

這個運算展示了如何通過根據“男人(man)”和“女人(woman)”之間的差異來調整“國王(king)”的向量,從而推導出表示“王后(queen)”的向量。
-
點積:
兩個向量的點積提供了一種衡量它們之間相似度的方法。如果兩個單詞向量的點積很高,這意味著它們是相似的,并且共享上下文。 -
余弦相似度:
余弦相似度是一種常用的衡量兩個向量之間相似度的方法,計算為它們之間夾角的余弦值。在比較單詞向量時,這特別有用,因為它有助于對向量的大小進行歸一化,只關注它們的方向。

向量空間的可視化
雖然自然語言處理中使用的向量空間通常是高維的(遠遠超出我們直接可視化的能力),但通常會使用主成分分析(Principal Component Analysis,PCA)或t分布隨機鄰域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)等技術將維度降低到二維或三維。這種降維使我們能夠可視化單詞彼此之間的位置關系,揭示出語義相關單詞的聚類。

單詞/詞義嵌入的t-SNE投影。綠色標簽顯示了“dogychairman”的兩種詞義嵌入,而黃色和紅色標簽顯示了這兩種詞義的最近鄰居。
2.2 向量嵌入的類型
向量嵌入是一種將單詞、句子和其他數據轉換為數字的方法,這些數字能夠捕捉它們的含義和關系。它們將不同的數據類型表示為多維空間中的點,在這個空間中,相似的數據點會聚集得更近。這些數值表示有助于機器更有效地理解和處理這些數據。
單詞嵌入和句子嵌入是向量嵌入中最常見的兩種子類型,但還有其他類型。一些向量嵌入可以表示整個文檔,以及為匹配視覺內容而設計的圖像向量、用于確定用戶偏好的用戶畫像向量、有助于識別相似產品的產品向量等等。向量嵌入幫助機器學習算法在數據中找到模式,并執行諸如情感分析、語言翻譯、推薦系統等任務。

在各種應用中,通常會使用幾種不同類型的向量嵌入。以下是一些例子:
- 單詞嵌入:將單個單詞表示為向量。像詞向量(Word2Vec)、全局詞向量(GloVE)和快速文本(FastText)等技術,通過從大型文本語料庫中捕捉語義關系和上下文信息來學習單詞嵌入。
- 句子嵌入:將整個句子表示為向量。像通用句子編碼器(Universal Sentence Encoder,USE)和跳過思想向量(SkipThought)等模型,會生成能夠捕捉句子整體含義和上下文的嵌入。
- 文檔嵌入:將文檔(從報紙文章、學術論文到書籍等任何文檔)表示為向量。它們捕捉整個文檔的語義信息和上下文。像文檔向量(Doc2Vec)和段落向量(Paragraph Vectors)等技術就是為了學習文檔嵌入而設計的。
- 圖像嵌入:通過捕捉不同的視覺特征,將圖像表示為向量。像卷積神經網絡(Convolutional Neural Networks,CNNs)和預訓練模型(如殘差網絡(ResNet)和視覺幾何組網絡(VGG))等技術,會為圖像分類、目標檢測和圖像相似度等任務生成圖像嵌入。
- 用戶嵌入:將系統或平臺中的用戶表示為向量。它們捕捉用戶的偏好、行為和特征。用戶嵌入可以用于從推薦系統到個性化營銷以及用戶細分等各個方面。
- 產品嵌入:在電子商務或推薦系統中,將產品表示為向量。它們捕捉產品的屬性、特征以及任何其他可用的語義信息。然后,算法可以使用這些嵌入,根據產品的向量表示來比較、推薦和分析產品。
嵌入和向量是同一回事嗎?
在向量嵌入的背景下,是的,嵌入和向量是同一回事。它們都指的是數據的數值表示,其中每個數據點都由高維空間中的一個向量來表示。
術語“向量”僅僅是指具有特定維度的一組數字。在向量嵌入的情況下,這些向量在連續空間中表示上述任何一種數據點。相反,“嵌入”專門指的是將數據表示為向量的技術,這種表示方式能夠捕捉有意義的信息、語義關系或上下文特征。嵌入旨在捕捉數據的底層結構或屬性,并且通常是通過訓練算法或模型來學習的。
雖然在向量嵌入的背景下,“嵌入”和“向量”可以互換使用,但“嵌入”強調的是以有意義和結構化的方式表示數據的概念,而“向量”則指的是數值表示本身。
在這篇博客文章中,我們主要關注的是詞嵌入(Word Embeddings)。讓我們更詳細地討論一下這個內容。
2.3 詞嵌入如何表示含義
詞嵌入是自然語言處理(Natural Language Processing,NLP)中的一個強大工具,因為它們能夠以一種捕捉單詞語義含義以及單詞與其他單詞之間關系的方式來表示單詞。與獨熱編碼等傳統方法不同,獨熱編碼將單詞視為相互獨立且沒有關聯的實體,而詞嵌入則以緊湊、密集的向量形式對有關單詞上下文和用法的豐富信息進行編碼。
詞嵌入中的含義概念
詞嵌入背后的核心思想是,出現在相似上下文中的單詞往往具有相似的含義。這基于語言學中的分布假設,該假設指出,出現在相同上下文中的單詞往往具有相似的含義。
例如,考慮“貓(cat)”和“狗(dog)”這兩個單詞。這些單詞經常出現在相似的上下文中(例如,“貓/狗正在玩球”)。因此,它們的嵌入在向量空間中應該彼此靠近,這反映了它們相似的含義。
通過上下文捕捉含義
詞嵌入通常是通過分析單詞在大型文本語料庫中出現的上下文來學習得到的。學習過程涉及將每個單詞映射到高維空間中的一個向量,使得這個空間的幾何結構能夠捕捉單詞之間的語義關系。
- 共現統計:
詞嵌入通常源自共現統計,其中每個單詞的向量是基于在文本中頻繁出現在其附近的單詞來學習的。例如,在詞向量(Word2Vec)模型中,嵌入的訓練方式是讓具有相似共現模式的單詞擁有相似的向量表示。 - 上下文相似性:
出現在相似上下文中(即被相同的一組單詞所包圍)的單詞會被賦予相似的向量表示。例如,“國王(king)”和“王后(queen)”可能經常出現在相似的上下文中(例如,“_統治著王國”),這使得它們的嵌入在向量空間中彼此靠近。
2.4 嵌入中的幾何關系
詞嵌入的真正強大之處在于嵌入空間中向量之間的幾何關系。這些關系對不同類型的含義和語義信息進行了編碼。
- 同義性和相似性:
具有相似含義的單詞,其嵌入在向量空間中彼此靠近。例如,“快樂(happy)”和“愉快(joyful)”這兩個單詞可能由彼此靠近的向量來表示,這表明了它們的語義相似性。 - 類比和語義關系:
詞嵌入的一個迷人特性是它們能夠通過向量運算來捕捉類比關系。一個著名的例子是這樣的類比:
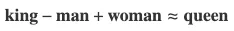
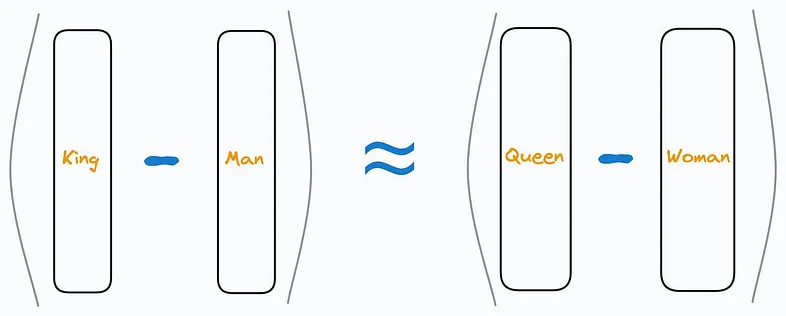
這意味著“國王”和“男人”之間的向量差與“王后”和“女人”之間的向量差相似。這種運算表明,嵌入能夠捕捉諸如性別、皇室,甚至是地理關系(例如,“巴黎 - 法國 + 意大利 ≈ 羅馬”)等復雜的語義關系。
- 層次關系:
一些嵌入還能夠捕捉層次關系。例如,在一個訓練良好的嵌入空間中,“狗(dog)”可能會靠近“動物(animal)”和“貓(cat)”,這反映了“狗”和“貓”都是“動物”的一種這樣的層次結構。 - 一詞多義性和上下文含義:
雖然傳統的詞嵌入在處理一詞多義(具有多種含義的單詞)方面存在困難,但像上下文嵌入(例如,雙向編碼器表征來自變換器(BERT)、基于語境的詞向量表示(ELMo))這樣的較新模型已經推進了這一概念。在這些模型中,一個單詞的嵌入會根據它出現的上下文而發生變化,這使得模型能夠捕捉像“銀行(bank)”(例如,河岸與金融銀行)這樣的單詞的不同含義。
2.5 密集表示
詞嵌入被稱為密集表示,是因為它們將一個單詞的含義濃縮到相對較少的維度中(例如,100 - 300 維),其中每個維度捕捉單詞含義或上下文的不同方面。這與獨熱編碼等稀疏表示形成對比,在獨熱編碼中,每個單詞由一個大多為零的長向量來表示。
例如,考慮在三維空間中“貓(cat)”和“狗(dog)”的以下詞嵌入:

這些向量彼此靠近,反映了“貓”和“狗”的相似含義。
2.6 詞嵌入中含義的應用
詞嵌入捕捉含義的能力在自然語言處理中有廣泛的應用:
- 相似性和相關性:嵌入用于衡量兩個單詞的相似程度,這在信息檢索、聚類和推薦系統等任務中非常有用。
- 語義搜索:詞嵌入使搜索引擎更加智能,能夠理解同義詞和相關術語。
- 機器翻譯:嵌入有助于在不同語言之間對齊單詞,從而實現更準確的翻譯。
- 情感分析:通過理解上下文中單詞的含義,嵌入提高了情感分類的準確性。
2.7 詞嵌入中的上下文概念
詞嵌入通過分析在大型文本語料庫中與目標單詞緊密相鄰出現的單詞,利用上下文來捕捉單詞的含義。其核心思想是,出現在相似上下文中的單詞往往具有相似的含義。
- 上下文窗口:
在訓練詞嵌入時,通常會使用一個上下文窗口來定義圍繞目標單詞的單詞范圍,這些單詞被視為目標單詞的上下文。例如,在“貓坐在墊子上(The cat sat on the mat)”這樣的句子中,如果目標單詞是“貓(cat)”,且上下文窗口大小為 2,那么上下文單詞就是“這(The)”和“坐(sat)”。
上下文窗口的大小會影響嵌入的質量。較小的窗口關注更接近的單詞,能夠捕捉更具體的關系,而較大的窗口可能會捕捉更一般的語義關系。 - 上下文相似性:
訓練過程會調整單詞向量,使得具有相似上下文的單詞最終擁有相似的向量。例如,“貓(cat)”和“狗(dog)”可能具有“寵物(pets)”、“動物(animals)”、“家(home)”等相似的上下文。因此,它們的向量在嵌入空間中會彼此靠近。 - 上下文相關嵌入:
像詞向量(Word2Vec)和全局詞向量(GloVe)這樣的傳統詞嵌入會為每個單詞生成一個單一的向量,而不考慮其上下文。然而,像基于語境的詞向量表示(ELMo)和雙向編碼器表征來自變換器(BERT)這樣的較新模型會生成上下文相關嵌入,其中一個單詞的向量會根據其上下文而發生變化。
例如,在雙向編碼器表征來自變換器(BERT)中,“河岸(river bank)”和“金融銀行(financial bank)”中的“銀行(bank)”這個單詞會有不同的向量,這反映了它們在這些上下文中的不同含義。這使得能夠對單詞及其含義有更細致入微的理解。
為什么上下文很重要
上下文至關重要,因為如果沒有上下文,一個單詞的含義往往是模糊的。同一個單詞根據其周圍的單詞可能會有不同的含義,而理解這一點是自然語言理解的關鍵。
- 消除歧義:
上下文有助于消除具有多種含義(一詞多義)的單詞的歧義。例如,“樹皮(bark)”這個單詞可能意味著狗發出的聲音,也可能意味著樹的外皮。上下文(例如,“狗大聲地叫(The dog barked loudly)”與“樹的樹皮很粗糙(The tree’s bark was rough)”)有助于確定正確的含義。 - 同義詞和相關單詞:
具有相似含義或在相似上下文中使用的單詞將具有相似的嵌入。例如,“快樂(happy)”和“愉快(joyful)”可能會出現在相似的上下文中,如“感覺(feeling)”或“情感(emotion)”,從而導致相似的嵌入。 - 捕捉細微差別:
通過利用上下文,嵌入可以捕捉含義上的細微差別。例如,“大(big)”和“巨大(large)”可能具有相似的嵌入,但上下文可能會揭示它們在使用上的細微差別,比如“大機會(big opportunity)”與“大量(large amount)”。
3. 詞嵌入技術
在自然語言處理(Natural Language Processing,NLP)中,詞嵌入的生成是理解語言語義的核心。這些嵌入,即單詞的密集數值表示,捕捉了語義關系,并使機器能夠有效地處理文本數據。已經開發出了幾種生成詞嵌入的技術,每種技術都為語言的語義結構提供了獨特的見解。

讓我們來探討一些主要的方法:
3.1 基于頻率的方法
3.1.1 計數向量化器(Count Vectorizer)
在收集用于分布式單詞表示的單詞數據時,可以從對一系列文檔中的單詞進行簡單計數開始。每個單詞在每個文檔中出現的次數總和就是一個計數向量。計數向量化器(CountVectorizer)通過計算每個單詞出現的次數,將文本轉換為固定長度的向量。現在,這些token被存儲為一個詞袋模型(Bag-of-Words)。

代碼示例
from sklearn.feature_extraction.text import CountVectorizer# 示例語料庫
corpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?',
]# 初始化計數向量化器
vectorizer = CountVectorizer()# 擬合并轉換語料庫
X = vectorizer.fit_transform(corpus)# 將結果轉換為密集矩陣并打印
print("Count Vectorized Matrix:\n", X.toarray())# 打印特征名稱
print("Feature Names:\n", vectorizer.get_feature_names_out())
輸出:
Count Vectorized Matrix:[[0 1 1 1 0 0 1 0 1][0 2 0 1 0 1 1 0 1][1 0 0 1 1 0 1 1 1][0 1 1 1 0 0 1 0 1]]
Feature Names:['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
局限性
- 由于詞匯量較大,導致維度較高。
- 忽略單詞的語義含義和上下文。
- 不考慮單詞順序。
- 生成稀疏的特征矩陣。
- 在捕捉長距離單詞關系方面能力有限。
- 無法處理同義詞,將每個單詞視為不同的個體。
- 在處理新文檔中的未登錄詞(OOV)時存在困難。
- 對文檔長度敏感,可能會引入偏差。
- 罕見詞可能會引入噪聲,且沒有有意義的貢獻。
- 除非進行處理,否則頻繁出現的詞可能會主導特征空間。
- 對所有詞賦予同等重要性,缺乏區分能力。
- 對于大型語料庫,資源消耗大,可能存在可擴展性問題。
3.1.2 詞袋模型(Bag-of-Words,BoW)
詞袋模型(BoW)是一種文本表示技術,它將文檔表示為一個無序的單詞集合以及這些單詞各自的頻率。它忽略單詞的順序,捕捉文檔中每個單詞的頻率,從而創建一個向量表示。
這是一種非常靈活、直觀且最簡單的特征提取方法。文本/句子被表示為一個唯一單詞計數的列表,由于這個原因,這種方法也被稱為計數向量化。要對我們的文檔進行向量化,我們所要做的就是計算每個單詞出現的次數。
由于詞袋模型是根據單詞的出現次數來衡量單詞的重要性。在實際應用中,像“is”“the”“and”這樣最常見的詞沒有什么價值。在進行計數向量化之前,會先去除停用詞(在本系列博客中介紹過)。
示例

詞匯表是這些文檔中唯一單詞的總數。
Vocabulary: [‘dog’, ‘a’, ‘live’, ‘in’, ‘home’, ‘hut’, ‘the’, ‘is’]
代碼示例

局限性
- 忽略單詞順序和上下文,丟失語義含義。
- 高維度、稀疏的向量可能導致計算效率低下。
- 無法捕捉單詞之間的語義相似性。
- 在處理一詞多義(多個含義)和同義(相同含義)方面存在困難。
- 對詞匯量大小和選擇敏感。
- 無法捕捉多詞短語或表達。
- 常見詞(停用詞)可能會主導表示。
- 需要大量的預處理(分詞、去除停用詞等)。
- 不適合需要對語言進行細致理解的復雜任務。
3.1.3 詞頻-逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)
詞頻-逆文檔頻率(TF-IDF)是一種數值統計量,用于評估一個單詞在文檔中相對于一組文檔(或語料庫)的重要性。基本思想是,如果一個單詞在某個文檔中頻繁出現,但在其他許多文檔中不常出現,那么它應該被賦予更高的重要性。
在語料庫D中,文檔d中術語t的TF-IDF分數是通過兩個指標的乘積來計算的:詞頻(Term Frequency,TF)和逆文檔頻率(Inverse Document Frequency,IDF)。
-
詞頻(TF)
詞頻(TF)衡量一個術語在文檔中出現的頻率。為了防止偏向較長的文檔,通常會用文檔中術語的總數對其進行歸一化。
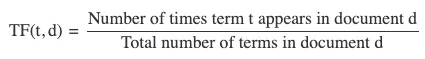
-
逆文檔頻率(IDF)
逆文檔頻率(IDF)衡量一個術語在整個語料庫中的重要性。它會降低在許多文檔中出現的術語的權重,并增加在較少文檔中出現的術語的權重。

在分母中加上“+1”是為了防止在術語未出現在任何文檔中的情況下出現除零錯誤。 -
結合TF和IDF:TF-IDF
對于文檔d中的術語t,TF-IDF分數是通過將TF值與IDF值相乘來計算的:

重要性:有助于識別文檔中的重要單詞,常用于信息檢索和文本挖掘。
代碼示例
from sklearn.feature_extraction.text import TfidfVectorizer# 示例文本數據(文檔)
documents = ["The cat sat on the mat.","The cat sat on the bed.","The dog barked."
]
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 擬合模型并將文檔轉換為TF-IDF表示
tfidf_matrix = vectorizer.fit_transform(documents)
# 獲取特征名稱(語料庫中的唯一單詞)
feature_names = vectorizer.get_feature_names_out()
# 將TF-IDF矩陣轉換為數組
tfidf_array = tfidf_matrix.toarray()
# 顯示TF-IDF矩陣
print("Feature Names (Words):", feature_names)
print("\nTF-IDF Matrix:")
print(tfidf_array)
輸出:
Feature Names (Words): ['barked' 'bed' 'cat' 'dog' 'mat' 'on' 'sat' 'the']TF-IDF Matrix:
[[0. 0. 0.37420726 0. 0.49203758 0.374207260.37420726 0.58121064][0. 0.49203758 0.37420726 0. 0. 0.374207260.37420726 0.58121064][0.65249088 0. 0. 0.65249088 0. 0.0. 0.38537163]]

局限性
- 無法捕捉單詞的上下文或含義。
- 對于大型詞匯表,會生成高維度且稀疏的向量。
- 無法有效地處理同義詞或一詞多義。
- 可能會過度懲罰較長的文檔。
- 僅限于線性關系,無法捕捉復雜的模式。
- 是靜態的,無法適應新的上下文或不斷演變的語言。
- 對于非常短或非常長的文檔效果不佳。
- 對單詞順序不敏感。
3.1.4 N元語法(N - Grams)
N元語法是在文本分析中可作為一個單元共同使用的單詞序列。像 “瑪麗有一只小羊羔(Mary had a little lamb)”“瑪麗有(Mary had)”“有一只(had a)”“一只小(a little)” 和 “小羔羊(little lamb)” 這樣的表述就是二元語法(N = 2)。很多N元語法在數據中出現的頻率可能不夠高,因而用處不大,這會導致表示結果稀疏且缺乏意義。
類型
- 一元語法(Unigram):單個單詞。
- 二元語法(Bigram):一對單詞。
- 三元語法(Trigram):三個單詞的序列。
重要性
能夠捕捉文本中的上下文和單詞依賴關系。
import nltk
from nltk.util import ngrams
from collections import Counter# 示例文本數據
text = "The quick brown fox jumps over the lazy dog"
# 將文本分詞為單詞
tokens = nltk.word_tokenize(text)
# 生成一元語法(1 - gram)
unigrams = list(ngrams(tokens, 1))
print("一元語法:")
print(unigrams)
# 生成二元語法(2 - gram)
bigrams = list(ngrams(tokens, 2))
print("\n二元語法:")
print(bigrams)
# 生成三元語法(3 - gram)
trigrams = list(ngrams(tokens, 3))
print("\n三元語法:")
print(trigrams)
# 統計每個N元語法的頻率(用于演示)
unigram_freq = Counter(unigrams)
bigram_freq = Counter(bigrams)
trigram_freq = Counter(trigrams)
# 打印頻率(可選)
print("\n一元語法頻率:")
print(unigram_freq)
print("\n二元語法頻率:")
print(bigram_freq)
print("\n三元語法頻率:")
print(trigram_freq)
輸出
一元語法:
[('The',), ('quick',), ('brown',), ('fox',), ('jumps',), ('over',), ('the',), ('lazy',), ('dog',)]
二元語法:
[('The', 'quick'), ('quick', 'brown'), ('brown', 'fox'), ('fox', 'jumps'), ('jumps', 'over'), ('over', 'the'), ('the', 'lazy'), ('lazy', 'dog')]
三元語法:
[('The', 'quick', 'brown'), ('quick', 'brown', 'fox'), ('brown', 'fox', 'jumps'), ('fox', 'jumps', 'over'), ('jumps', 'over', 'the'), ('over', 'the', 'lazy'), ('the', 'lazy', 'dog')]
一元語法頻率:
Counter({('The',): 1, ('quick',): 1, ('brown',): 1, ('fox',): 1, ('jumps',): 1, ('over',): 1, ('the',): 1, ('lazy',): 1, ('dog',): 1})
二元語法頻率:
Counter({('The', 'quick'): 1, ('quick', 'brown'): 1, ('brown', 'fox'): 1, ('fox', 'jumps'): 1, ('jumps', 'over'): 1, ('over', 'the'): 1, ('the', 'lazy'): 1, ('lazy', 'dog'): 1})
三元語法頻率:
Counter({('The', 'quick', 'brown'): 1, ('quick', 'brown', 'fox'): 1, ('brown', 'fox', 'jumps'): 1, ('fox', 'jumps', 'over'): 1, ('jumps', 'over', 'the'): 1, ('over', 'the', 'lazy'): 1, ('the', 'lazy', 'dog'): 1})
局限性
- 高維度與稀疏性:維度高,且很多N元語法出現頻率低,導致表示稀疏。
- 缺乏語義理解:只是簡單的單詞序列組合,不理解單詞的語義。
- 忽略上下文:沒有考慮到單詞序列所在的更廣泛上下文。
- 可擴展性問題:隨著語料庫增大,N元語法的數量會急劇增加,計算和存儲成本高。
- 對噪聲和稀有詞敏感:稀有詞或噪聲可能會影響分析結果。
- 難以捕捉一詞多義與同義詞:無法區分同一單詞的不同含義,也難以處理同義詞。
- 跨語言泛化困難:不同語言的N元語法模式差異大,難以泛化。
- 難以捕捉長期依賴關系:對于長距離的單詞依賴關系捕捉能力有限。
3.1.5 共現矩陣(Co - occurrence Matrices)
共現矩陣用于捕捉在給定上下文窗口內單詞共同出現的頻率。這些矩陣量化了單詞之間的統計關系,為生成詞嵌入提供了基礎。
讓我們通過一個簡單的例子來說明共現矩陣的概念。假設我們有一個由以下三篇文檔組成的語料庫:
- 文檔1:“敏捷的棕色狐貍跳過了那只懶狗(The quick brown fox jumps over the lazy dog)。”
- 文檔2:“那只棕色的狗大聲叫著(The brown dog barks loudly)。”
- 文檔3:“那只懶貓安靜地睡著(The lazy cat sleeps peacefully)。”
我們想基于這些文檔中的單詞,在窗口大小為1的情況下構建一個共現矩陣。這意味著我們考慮每個單詞與其緊鄰的相鄰單詞的共現情況。我們將忽略標點符號,并以不區分大小寫的方式處理單詞。
首先,讓我們根據語料庫中的唯一單詞構建一個詞匯表:
詞匯表:[the, quick, brown, fox, jumps, over, lazy, dog, barks, loudly, cat, sleeps, peacefully]
接下來,我們創建一個共現矩陣,其中行和列代表詞匯表中的單詞。矩陣中每個單元格 (i, j) 的值表示單詞 i 與單詞 j 在指定窗口大小內共同出現的次數。
| the | quick | brown | fox | jumps | over | lazy | dog | barks | loudly | cat | sleeps | peacefully | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| the | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| quick | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| brown | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| fox | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| jumps | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| over | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| lazy | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| dog | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| barks | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| loudly | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| cat | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| sleeps | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| peacefully | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
這個共現矩陣捕捉了在窗口大小為1的情況下,每個單詞與其他每個單詞的共現頻率。例如,“the” 行和 “lazy” 列的單元格值為1,表示在指定窗口大小內,“lazy” 與 “the” 在整個語料庫中共同出現了一次。
這個例子展示了如何構建和利用共現矩陣來捕捉文本語料庫中單詞之間的統計關系,為各種自然語言處理任務(如詞嵌入、情感分析和命名實體識別)提供有價值的見解。
共現矩陣在自然語言處理中的主要應用之一是生成詞嵌入。通過分析語料庫中單詞的共現模式,共現矩陣可以捕捉每個單詞周圍的上下文信息。像詞向量(Word2Vec)和全局詞向量(GloVe)這樣的技術利用這些矩陣來創建單詞的密集、低維向量表示,其中向量之間的幾何關系反映了單詞之間的語義相似性。這使得可以進行單詞相似度的度量、類比檢測和語義搜索。

import numpy as np
import pandas as pd
from collections import Counter
from sklearn.preprocessing import normalize# 示例語料庫
corpus = ["I love machine learning","machine learning is great","I love deep learning","deep learning and machine learning are related"
]# 對句子進行分詞
corpus = [sentence.lower().split() for sentence in corpus]# 將句子列表展平為單個單詞列表
vocab = set([word for sentence in corpus for word in sentence])
vocab = sorted(vocab) # 排序以保證順序一致
vocab_size = len(vocab)# 初始化一個空的共現矩陣
co_occurrence_matrix = np.zeros((vocab_size, vocab_size))# 定義窗口大小
window_size = 2# 創建從單詞到索引的映射
word2idx = {word: i for i, word in enumerate(vocab)}# 填充共現矩陣
for sentence in corpus:for i, word in enumerate(sentence):word_idx = word2idx[word]start = max(0, i - window_size)end = min(len(sentence), i + window_size + 1)for j in range(start, end):if i != j:context_word = sentence[j]context_idx = word2idx[context_word]co_occurrence_matrix[word_idx, context_idx] += 1# 將矩陣轉換為DataFrame以便更好地可視化
co_occurrence_df = pd.DataFrame(co_occurrence_matrix, index=vocab, columns=vocab)# 對共現矩陣進行歸一化
co_occurrence_normalized = normalize(co_occurrence_matrix, norm='l1', axis=1)# 將歸一化后的矩陣轉換為DataFrame以便更好地可視化
co_occurrence_normalized_df = pd.DataFrame(co_occurrence_normalized, index=vocab, columns=vocab)# 顯示共現矩陣
print("共現矩陣:")
print(co_occurrence_df)# 顯示歸一化后的共現矩陣
print("\n歸一化后的共現矩陣:")
print(co_occurrence_normalized_df)
局限性
- 高維度導致效率低下和存儲問題:詞匯表越大,矩陣維度越高,計算和存儲成本增加。
- 極度稀疏:大多數單詞對很少共現,導致矩陣中大部分元素為零。
- 捕捉深度語義關系的能力有限:只能反映單詞的共現頻率,難以捕捉深層次的語義聯系。
- 上下文獨立性:無法區分同一單詞在不同上下文中的不同含義。
- 大規模語料庫的可擴展性挑戰:矩陣大小隨語料庫增大呈二次方增長。
- 偏向高頻詞:高頻詞在矩陣中占主導,對低頻詞或短語的表示不可靠。
- 表達能力有限:難以捕捉復雜的語言結構。
- 數據噪聲:存在停用詞和無意義的單詞對,影響分析結果。
3.1.6 獨熱編碼(One-Hot Encoding)
獨熱編碼是自然語言處理(NLP)中表示單詞的一種基本方法。詞匯表中的每個單詞都被表示為一個唯一的向量,除了對應于該單詞在詞匯表中索引位置的元素為1之外,其余所有元素都設置為0。
示例:給定一個包含10,000個單詞的詞匯表,對每個單詞進行數值表示的最簡單方法是什么?

你可以為每個單詞分配一個整數索引:

我們的10,000個單詞的詞匯表,每個單詞都被分配了一個索引。
那么,舉一些例子:
- 我們詞匯表中的第一個單詞“土豚(aardvark)”的向量表示將是 [1, 0, 0, 0, …, 0],即在第一個位置為1,后面跟著9,999個0。
- 我們詞匯表中的第二個單詞“螞蟻(ant)”的向量表示將是 [0, 1, 0, 0, …, 0],即在第一個位置為0,第二個位置為1,后面跟著9,998個0。
以此類推……
這個過程被稱為獨熱向量編碼。你可能也聽說過這種方法被用于在多分類問題中表示標簽。
現在,假設我們的自然語言處理項目正在構建一個翻譯模型,我們想把英語輸入句子“這只貓是黑色的(the cat is black)”翻譯成另一種語言。我們首先需要用獨熱編碼來表示每個單詞。我們會先查找第一個單詞“the”的索引,然后發現它在我們10,000個單詞的詞匯表中的索引是8676。

然后我們可以用一個長度為10,000的向量來表示單詞“the”,其中除了位置8676處的元素為1之外,其他每個元素都是0。

我們對輸入句子中的每個單詞都進行這種索引查找,并創建一個向量來表示每個輸入單詞。整個過程有點像下面這個動圖展示的這樣:

展示輸入句子“這只貓是黑色的(the cat is black)”中單詞的獨熱編碼的動圖。
請注意,這個過程為每個輸入單詞生成了一個非常稀疏(大部分元素為0)的特征向量(在這里,術語“特征向量”“嵌入”和“單詞表示”可以互換使用)。
這些獨熱向量是一種快速且簡單的將單詞表示為實數值向量的方法。
注意:
如果你想要生成整個句子的表示,而不僅僅是每個單詞的表示,該怎么辦呢?最簡單的方法要么是將句子中各個單詞的嵌入連接起來,要么是對它們求平均值(或者是兩者的某種混合方式)。更先進的方法,比如編碼器-解碼器循環神經網絡(RNN)模型,會按順序讀取每個單詞的嵌入,以便通過多層變換逐步構建出句子含義的密集表示。
代碼:
def one_hot_encode(text):words = text.split()vocabulary = set(words)word_to_index = {word: i for i, word in enumerate(vocabulary)}one_hot_encoded = []for word in words:one_hot_vector = [0] * len(vocabulary)one_hot_vector[word_to_index[word]] = 1one_hot_encoded.append(one_hot_vector)return one_hot_encoded, word_to_index, vocabulary# 示例
example_text = "貓在帽子里 狗在墊子上 鳥在樹上(cat in the hat dog on the mat bird in the tree)"one_hot_encoded, word_to_index, vocabulary = one_hot_encode(example_text)print("詞匯表:", vocabulary)
print("單詞到索引的映射:", word_to_index)
print("獨熱編碼矩陣:")
for word, encoding in zip(example_text.split(), one_hot_encoded):print(f"{word}: {encoding}")
輸出:
詞匯表: {'mat', 'the', 'bird', 'hat', 'on', 'in', 'cat', 'tree', 'dog'}
單詞到索引的映射: {'mat': 0, 'the': 1, 'bird': 2, 'hat': 3, 'on': 4, 'in': 5, 'cat': 6, 'tree': 7, 'dog': 8}
獨熱編碼矩陣:
cat: [0, 0, 0, 0, 0, 0, 1, 0, 0]
in: [0, 0, 0, 0, 0, 1, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
hat: [0, 0, 0, 1, 0, 0, 0, 0, 0]
dog: [0, 0, 0, 0, 0, 0, 0, 0, 1]
on: [0, 0, 0, 0, 1, 0, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
mat: [1, 0, 0, 0, 0, 0, 0, 0, 0]
bird: [0, 0, 1, 0, 0, 0, 0, 0, 0]
in: [0, 0, 0, 0, 0, 1, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
tree: [0, 0, 0, 0, 0, 0, 0, 1, 0]
稀疏獨熱編碼的問題
我們已經完成了獨熱編碼,并成功地將每個單詞表示為一個數字向量。很多自然語言處理項目都采用了這種方法,但最終結果可能并不理想,尤其是在訓練數據集較小的情況下。這是因為獨熱向量并不是一種很好的輸入表示方法。
為什么單詞的獨熱編碼不是最優的呢?
- 缺乏語義相似性:獨熱編碼無法捕捉單詞之間的語義關系。例如,“貓(cat)”和“老虎(tiger)”被表示為完全不同的向量,沒有顯示出它們之間的相似性。這對于基于類比的向量運算等任務來說是個問題,在這些任務中,我們期望像“貓 - 小 + 大”這樣的運算能得到類似于“老虎”或“獅子”的結果。獨熱編碼缺乏完成這類任務所需的豐富性。
- 高維度:獨熱向量的維度與詞匯表的大小成線性關系。隨著詞匯表的增大,特征向量會變得越來越大,加劇了維度災難。這不僅增加了需要估計的參數數量,還需要指數級更多的數據來訓練一個泛化能力好的模型。
- 計算效率低:獨熱編碼的向量是稀疏且高維度的,其中大多數元素為0。許多機器學習模型,尤其是神經網絡,處理這樣的稀疏數據時會遇到困難。較大的特征空間也會帶來內存和存儲方面的挑戰,特別是如果模型不能有效地處理稀疏矩陣的話。
3.2 靜態嵌入
密集向量,或稱為詞嵌入,通過為單詞提供更具信息量和更緊湊的表示,解決了獨熱編碼的局限性。
- 降維:與向量長度等于詞匯表大小不同,嵌入通常使用維度小得多的向量(例如,50、100或300維)。
- 語義接近性:密集向量將語義相似的單詞在向量空間中放置得彼此靠近。例如,“貓(cat)”和“狗(dog)”的向量之間的余弦相似度會高于“貓”和“魚(fish)”的向量之間的余弦相似度。
示例:
- 詞向量(Word2Vec):通過根據上下文預測單詞或反之來學習嵌入。
- 全局詞向量(GloVe):使用矩陣分解來推導嵌入。
- 變換器(例如,雙向編碼器表征來自變換器(BERT)、生成式預訓練變換器(GPT)):生成基于周圍上下文捕捉單詞含義的上下文嵌入。
獨熱向量存在的最重要問題是什么,而密集嵌入又是如何解決它的呢?
嵌入解決的核心問題是泛化能力。
泛化問題。如果我們假設像“貓(cat)”和“老虎(tiger)”這樣的單詞確實是相似的,我們希望有一種方法能將這種信息傳遞給模型。當其中一個單詞很罕見時(例如“獅虎獸(liger)”),這一點就變得尤為重要,因為它可以借助一個相似的、更常見的單詞在模型中所經過的計算路徑。這是因為,在訓練過程中,模型學習以某種方式處理輸入“貓”,即通過由權重和偏差參數定義的多層變換來傳遞它。當網絡最終遇到“獅虎獸”時,如果它的嵌入與“貓”相似,那么它將采取與“貓”相似的路徑,而不是讓網絡完全從頭開始學習如何處理它。對于你從未見過的事物進行預測是非常困難的——但如果它與你見過的事物相關,那就容易多了。
這意味著嵌入使我們能夠構建更具泛化能力的模型——網絡無需匆忙學習許多不同的方式來處理不相關的輸入,而是讓相似的單詞“共享”參數和計算路徑。
邁向密集、具有語義意義的表示
如果我們從詞匯表中選取5個示例單詞(比如說……“土豚(aardvark)”、“黑色(black)”、“貓(cat)”、“羽絨被(duvet)”和“僵尸(zombie)”),并檢查由上述獨熱編碼方法創建的它們的嵌入向量,結果會像這樣:

使用獨熱編碼的單詞向量。每個單詞都由一個大部分為0的向量表示,除了在由該單詞在詞匯表中的索引所決定的位置上有一個“1”。注意:并不是說“黑色”、“貓”和“羽絨被”具有相同的特征向量,只是在這里看起來是這樣。
但是,作為說某種語言的人類,我們知道單詞是具有許多層內涵和意義的豐富實體。讓我們為這5個單詞手工制作一些語義特征。具體來說,讓我們將每個單詞表示為在“動物”、“蓬松度”、“危險性”和“恐怖性”這四種語義屬性上具有介于0和1之間的某種值:

為詞匯表中的5個單詞手工制作的語義特征。
那么,來解釋幾個例子:
- 對于單詞“土豚(aardvark)”,我給它的“動物”特征賦予了較高的值(因為它確實是一種動物),而“蓬松度”(土豚有短鬃毛)、“危險性”(它們是小型的、夜行性的穴居豬)和“恐怖性”(它們很可愛)的值相對較低。
- 對于單詞“貓(cat)”,我給它的“動物”和“蓬松度”特征賦予了較高的值(原因不言而喻),“危險性”特征賦予了中等的值(如果你養過寵物貓,就會明白原因),“恐怖性”特征也賦予了中等的值(試著搜索一下“斯芬克斯貓”的圖片)。
根據語義特征值繪制單詞
我們已經接近重點了:
每個語義特征都可以被看作是更廣泛、更高維度的語義空間中的一個維度。
- 在上述虛構的數據集中,有四個語義特征,我們可以一次繪制其中兩個特征,形成一個二維散點圖(見下文)。每個特征是一個不同的軸/維度。
- 每個單詞在這個空間中的坐標由其在感興趣特征上的特定值給出。例如,單詞“土豚(aardvark)”在“蓬松度與動物”二維圖上的坐標是(x = 0.97,y = 0.03)。

在二維或三維軸上繪制單詞特征值。
- 同樣,我們可以考慮三個特征(“動物”、“蓬松度”和“危險性”),并在這個三維語義空間中繪制單詞的位置。例如,單詞“羽絨被(duvet)”的坐標是(x = 0.01,y = 0.84,z = 0.12),這表明“羽絨被”與蓬松度的概念高度相關,可能有一點危險性,而且不是動物。
這是一個手工制作的簡單示例,但實際的嵌入算法當然會自動為輸入語料庫中的所有單詞生成嵌入向量。如果你愿意,可以將像詞向量(Word2Vec)這樣的詞嵌入算法看作是單詞的無監督特征提取器。
像詞向量(Word2Vec)這樣的詞嵌入算法是單詞的無監督特征提取器。
詞嵌入的維度是什么?
一般來說,詞嵌入的維度是指單詞的向量表示所定義的維度數量。這通常是在創建詞嵌入時確定的一個固定值。詞嵌入的維度表示在向量表示中編碼的特征總數。
不同的生成詞嵌入的方法可能會導致不同的維度。最常見的是,詞嵌入的維度范圍在50到300之間,不過更高或更低的維度也是可能的。
例如,下面的圖展示了“國王(king)”、“王后(queen)”、“男人(man)”和“女人(women)”在三維空間中的詞嵌入:

3.2.1 詞向量(Word2Vec)
由米科洛夫(Mikolov)等人提出的詞向量(Word2Vec),是谷歌推出的一種流行的基于預測的方法,它通過在上下文窗口內預測周圍的單詞來學習詞嵌入。這種方法產生的密集向量表示能夠捕捉單詞之間的語義關系。
本吉奧(Bengio)提出的方法為自然語言處理研究人員提供了新的機會,他們可以修改該技術及其架構本身,以創建一種計算成本更低的方法。為什么呢?
本吉奧等人提出的方法從詞匯表中選取單詞,并將它們輸入到一個具有嵌入層、隱藏層(多個)和一個softmax函數的前饋神經網絡中。
這些嵌入具有相關的可學習向量,它們通過反向傳播進行自我優化。本質上,由于這是一個淺層網絡,該架構的第一層就產生了詞嵌入。
這種架構的問題在于,在隱藏層和投影層之間的計算成本很高。原因比較復雜:
- 投影層產生的值是密集的。
- 隱藏層為詞匯表中的所有單詞計算概率分布。
為了解決這個問題,研究人員(米科洛夫等人在2013年)提出了一個名為“詞向量(Word2Vec)”的模型。
詞向量(Word2Vec)模型從本質上解決了本吉奧的自然語言模型(NLM)的問題。
它完全去除了隱藏層,但與本吉奧的模型一樣,投影層對所有單詞是共享的。缺點是,如果數據較少,這個沒有神經網絡的簡單模型將無法像神經網絡那樣精確地表示數據。
另一方面,在有較大數據集的情況下,它可以在嵌入空間中精確地表示數據。同時,它還降低了復雜度,并且該模型可以在更大的數據集上進行訓練。
詞向量(Word2Vec)有兩種神經嵌入方法:連續詞袋模型(Continuous Bag of Words,CBOW)和跳字模型(Skip-gram)。

連續詞袋模型(CBOW)和跳字模型(Skip-gram)的架構。示例句子——“想法可以改變你的生活(Idea can change your life)”。
3.2.1.1 連續詞袋模型(Continuous Bag of Words,CBOW)
連續詞袋模型(CBOW)在給定周圍單詞的情況下,預測一個單詞出現的概率。我們可以考慮單個單詞或一組單詞。但為了簡單起見,我們將取單個上下文單詞,并嘗試預測單個目標單詞。
英語中大約有120萬個單詞,這使得在我們的示例中不可能包含這么多單詞。所以我將考慮一個小例子,在這個例子中我們只有四個單詞,即“居住(live)”、“家(home)”、“他們(they)”和“在(at)”。為了簡單起見,我們假設語料庫中只有一個句子,即“他們住在家里(They live at home)”。

首先,我們將每個單詞轉換為獨熱編碼形式。此外,我們不會考慮句子中的所有單詞,而只會選取在窗口內的某些單詞。例如,對于窗口大小等于3的情況,我們在一個句子中只考慮三個單詞。中間的單詞是要預測的單詞,周圍的兩個單詞作為上下文輸入到神經網絡中。然后滑動窗口,并重復這個過程。
最后,通過如上述滑動窗口反復訓練網絡后,我們得到權重,我們使用這些權重來得到如下所示的嵌入。

通常,我們取窗口大小約為8到10個單詞,并且向量大小為300。
3.2.1.2 跳字模型(Skip-gram model)
跳字模型(Skip-gram)的架構通常試圖實現與連續詞袋模型(CBOW)相反的操作。它試圖在給定目標單詞(中心單詞)的情況下,預測源上下文單詞(周圍單詞)。
跳字模型(Skip-gram)的工作原理與連續詞袋模型(CBOW)非常相似,但在其神經網絡的架構以及生成權重矩陣的方式上存在差異,如下圖所示:

在獲得權重矩陣后,獲取詞嵌入的步驟與連續詞袋模型相同。
那么,對于實現Word2Vec,我們應該使用這兩種算法中的哪一種呢?事實證明,對于維度較高的大型語料庫,使用跳字模型更好,但訓練速度較慢。而連續詞袋模型更適合小型語料庫,并且訓練速度也更快。

3.2.2 全局詞向量(GloVE,Global Vectors for Word Representation)
斯坦福大學的全局詞向量(GloVE)通過利用共現統計信息來訓練詞嵌入,結合了基于計數的方法和基于預測的方法的優點。通過優化全局詞-詞共現矩陣,GloVE生成的嵌入能夠捕捉局部和全局的語義關系。
GloVE是一種無監督學習算法,它通過分析文本語料庫中單詞的共現統計信息來獲得單詞的向量表示。這些單詞向量捕捉了單詞之間的語義含義和關系。
GloVE背后的關鍵思想是通過檢查整個語料庫中單詞共現的概率來學習詞嵌入。它構建一個全局詞-詞共現矩陣,然后對其進行因式分解,以推導出在連續向量空間中表示單詞的單詞向量。
這些單詞向量因其能夠捕捉單詞之間的語義關系,在自然語言處理(NLP)任務中受到了廣泛歡迎。它們被用于各種應用中,如機器翻譯、情感分析、文本分類等,在這些應用中,理解單詞的含義和上下文至關重要。
上下文理解使我們能夠根據周圍的單詞來理解某個單詞。
GloVE嵌入與其他嵌入技術(如Word2Vec和FastText)一起被廣泛使用,顯著提高了自然語言處理模型的性能。
GloVE詞嵌入是如何創建的?
GloVE模型的基本方法是首先創建一個巨大的詞-上下文共現矩陣,該矩陣由(單詞,上下文)對組成,使得這個矩陣中的每個元素都表示一個單詞與上下文(可以是一個單詞序列)一起出現的頻率。然后,其思路是應用矩陣分解來近似這個矩陣,如下圖所示。
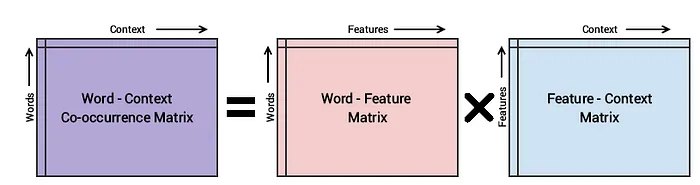
考慮詞-上下文(WC)矩陣、詞-特征(WF)矩陣和特征-上下文(FC)矩陣,我們嘗試對WC = WF × FC進行因式分解,這樣我們的目標就是通過將WF和FC相乘來從它們重構WC。為此,我們通常用一些隨機權重初始化WF和FC,并嘗試將它們相乘得到WC’(WC的近似值),然后衡量它與WC的接近程度。我們使用隨機梯度下降(SGD)多次執行此操作,以最小化誤差。最后,詞-特征矩陣(WF)為我們提供了每個單詞的詞嵌入,其中F可以預設為特定的維度數。需要記住的一個非常重要的點是,Word2Vec和GloVE模型的工作方式非常相似。它們都旨在構建一個向量空間,其中每個單詞的位置都基于其上下文和語義受到相鄰單詞的影響。Word2Vec從單詞共現對的局部單個示例開始,而GloVE從語料庫中所有單詞的全局聚合共現統計信息開始。
3.2.3 FastText
Word2Vec的局限性
雖然Word2Vec在自然語言處理領域是一個具有變革性的方法,但我們會發現它仍然有一些改進的空間:
-
未登錄詞(OOV,Out of Vocabulary)問題:
在Word2Vec中,會為每個單詞創建一個嵌入。因此,它無法處理在訓練過程中未遇到過的任何單詞。
例如,“張量(tensor)”和“流動(flow)”等單詞在Word2Vec的詞匯表中是存在的。但是,如果你嘗試獲取復合詞“TensorFlow”的嵌入,就會得到一個未登錄詞錯誤。

-
詞法問題:
對于像“吃(eat)”和“吃了(eaten)”這樣具有相同詞干的單詞,Word2Vec不會進行任何參數共享。每個單詞都是根據其出現的上下文單獨學習的。因此,存在利用單詞內部結構來提高處理效率的空間。

為了解決上述挑戰,博亞諾夫斯基(Bojanowski)等人提出了一種名為FastText的新嵌入方法。他們的關鍵見解是利用單詞的內部結構來改進從跳字模型中獲得的向量表示。
對跳字模型的修改如下:
- 子詞生成:
對于一個單詞,我們生成其內部長度為3到6的字符n元語法。
-
我們取一個單詞,并添加尖括號來表示單詞的開頭和結尾。

-
然后,我們生成長度為n的字符n元語法。例如,對于單詞“eating”,可以通過從尖括號的開頭滑動一個3字符的窗口直到到達結尾的尖括號來生成長度為3的字符n元語法。在這里,我們每次將窗口移動一步。

-
這樣,我們就得到了一個單詞的字符n元語法列表。

不同長度的字符n元語法的示例如下方所示:

- 由于可能存在大量獨特的n元語法,我們應用哈希來限制內存需求。我們不是為每個獨特的n元語法學習一個嵌入,而是學習總共B個嵌入,其中B表示桶的大小。該論文使用了大小為200萬的桶。

每個字符n元語法被哈希為1到B之間的一個整數。盡管這可能會導致沖突,但它有助于控制詞匯表的大小。該論文使用福勒-諾爾-沃(Fowler-Noll-Vo)哈希函數的FNV-1a變體將字符序列哈希為整數值。

-
帶負采樣的跳字模型:
為了理解預訓練過程,讓我們舉一個簡單的示例。我們有一個句子,中心單詞是“eating”,需要預測上下文單詞“am”和“food”。

-
首先,通過對字符n元語法的向量和整個單詞本身的向量求和來計算中心單詞的嵌入。

-
對于實際的上下文單詞,我們直接從嵌入表中獲取它們的單詞向量,而不添加字符n元語法的向量。

-
現在,我們按照與一元詞頻的平方根成比例的概率隨機收集負樣本。對于一個實際的上下文單詞,采樣5個隨機的負樣本單詞。

-
我們計算中心單詞和實際上下文單詞之間的點積,并應用sigmoid函數以得到0到1之間的匹配分數。
-
根據損失,我們使用隨機梯度下降(SGD)優化器更新嵌入向量,以使實際上下文單詞更接近中心單詞,同時增加與負樣本的距離。

-
3.3 上下文嵌入

上下文嵌入在學習單詞之間的關系方面確實展現出了一些很有前景的成果。
例如,
多虧了它們的自注意力機制,這些嵌入能夠生成具有上下文感知的表示。這使得嵌入模型能夠根據單詞使用的上下文動態地為其生成嵌入。因此,如果一個單詞出現在不同的上下文中,模型將得到不同的表示。
下面的圖片精確地展示了單詞“Bank”在不同用法下的情況。
為了便于可視化,使用t分布隨機鄰域嵌入(t-SNE)將嵌入投影到了二維空間中。

全局詞向量(Glove)與雙向編碼器表征來自變換器(BERT)在理解單詞不同含義方面的對比
像全局詞向量(Glove)和Word2Vec這樣的靜態嵌入模型,對于一個單詞的不同用法會產生相同的嵌入。
然而,上下文相關的嵌入模型則不會。
實際上,上下文相關的嵌入能夠理解單詞“Bank”的不同含義:
- 一家金融機構
- 斜坡地形
- 一道長脊等等。
這里的不同含義取自普林斯頓大學的Wordnet數據庫:WordNet。
因此,它們解決了靜態嵌入模型的主要局限性。
3.3.1 自注意力機制
將靜態嵌入轉化為動態上下文嵌入


該圖展示了單詞“Apple”的含義是如何根據其在句子中的上下文而變化的。這是通過上下文嵌入實現的,在這種方式中,一個單詞的表示會根據周圍的單詞進行調整。我們來剖析一下這個例子。
左側:“我吃了一個蘋果。”
- 句子:“我吃了一個蘋果。(I ate an Apple.)”
- 上下文:在這里,“Apple”顯然指的是水果。

以下分析展示了“Apple”的最終表示是如何受到周圍單詞影響的:
- “I”:表示說話者的代詞。
- “ate”:表示進食動作的動詞。
- “an”:用于修飾單個物品(通常為可數名詞)的冠詞,輔助限定上下文。
- “Apple”:這個單詞本身,其含義受上下文影響。
- 結果:由于“ate”和“an”這兩個單詞,這里“Apple”的向量在很大程度上傾向于水果的含義。
右側:“我買了一個蘋果公司的產品。”
- 句子:“我買了一個蘋果公司的產品。(I bought an Apple.)”
- 上下文:在這個上下文中,“Apple”更有可能指的是蘋果這家科技公司,意味著購買了一部蘋果公司的產品,比如iPhone或MacBook。

以下分析展示了上下文是如何改變單詞含義的:
- “I”:同樣是表示說話者的代詞。
- “bought”:表示購買行為的動詞。
- “an”:和之前一樣的冠詞。
- “Apple”:在這里,這個單詞的含義轉向了產品或品牌的語境。
- 結果:在這個句子中,由于“bought”所提供的上下文,“Apple”的向量轉向了表示蘋果公司或其產品的方向。
上下文很關鍵:單詞“Apple”根據周圍的單詞會有不同的含義。在“我吃了一個蘋果。(I ate an Apple.)”中,它表示水果。在“我買了一個蘋果公司的產品。(I bought an Apple.)”中,它指的是蘋果公司的產品。
上下文嵌入:這些嵌入根據上下文調整“Apple”的向量,從而更準確地理解每個句子中該單詞的含義。這種方法有助于更自然地理解語言,捕捉到靜態嵌入所忽略的細微差別。
現在我們需要像對“Apple”所做的那樣,為每個獨特的單詞都進行這樣的處理。


上下文嵌入通過提供基于上下文變化的單詞表示,解決了靜態嵌入的局限性。這些嵌入是由經過訓練以理解單詞出現的上下文的深度學習模型生成的。
- 上下文感知:一個單詞的表示會受到其周圍單詞的影響,從而根據上下文產生不同的含義。
- 動態表示:單詞根據其在不同句子中的用法會有多種表示形式。
- 增強的語義理解:上下文嵌入能夠捕捉更復雜的關系和細微的含義。
這一領域的關鍵進展之一是基于語言模型的嵌入(ELMo,Embeddings from Language Models)的發展。ELMo會考慮整個句子來確定單詞的含義。它在各種自然語言處理任務中顯著提升了性能。
在ELMo之后,雙向編碼器表征來自變換器(BERT,Bidirectional Encoder Representations from Transformers)進一步拓展了這一概念。BERT會分析一個句子中所有單詞之間的關系,而不是孤立地分析單個單詞。這帶來了更加精細的語言模型。
3.3.2 雙向編碼器表征來自變換器(BERT)
像BERT這樣的變換器模型,使用注意力機制來衡量句子中所有單詞的相關性。這在自然語言處理的特征提取方面是一個變革性的突破。它使得預測更加準確,對語言細微差別的理解也更加深入。
BERT是一個基于變換器的模型,它學習單詞的上下文相關嵌入。它通過同時考慮一個單詞的左右上下文來考量其完整的上下文,從而生成能夠捕捉豐富上下文信息的嵌入。
from transformers import BertTokenizer, BertModel
import torch# Load pre-trained BERT model and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
word_pairs = [('learn', 'learning'), ('india', 'indian'), ('fame', 'famous')]# Compute similarity for each pair of words
for pair in word_pairs:tokens = tokenizer(pair, return_tensors='pt')with torch.no_grad():outputs = model(**tokens)# Extract embeddings for the [CLS] tokencls_embedding = outputs.last_hidden_state[:, 0, :]similarity = torch.nn.functional.cosine_similarity(cls_embedding[0], cls_embedding[1], dim=0)print(f"Similarity between '{pair[0]}' and '{pair[1]}' using BERT: {similarity:.3f}")
3.3.3 基于語言模型的詞嵌入(ELMo)
基于語言模型的詞嵌入(ELMo,Embeddings from Language Models)是由艾倫人工智能研究所(Allen Institute for AI)的研究人員開發的。ELMo詞嵌入在問答和情感分析任務中展現出了性能提升。其官方論文地址為:https://arxiv.org/pdf/1802.05365.pdf 。
ELMo在自然語言處理(NLP)的特征提取方面是一項重大進展。這項技術利用深度的、上下文相關的詞嵌入來捕捉句法和語義信息,以及一詞多義(即具有多種含義的單詞)的情況。
與傳統的詞嵌入不同,ELMo會在周圍文本的上下文中分析單詞,從而帶來更豐富的理解。下面是一個用Python編寫的簡化示例:
from allennlp.modules.elmo import Elmo, batch_to_ids# 初始化ELMo
options_file = 'elmo_options.json'
weight_file = 'elmo_weights.hdf5'
elmo = Elmo(options_file, weight_file, num_output_representations=1)# 示例句子
sentences = [['I', 'have', 'a', 'green', 'apple'], ['I', 'have', 'a', 'green', 'thumb']]# 將句子轉換為字符ID
character_ids = batch_to_ids(sentences)# 獲取ELMo嵌入
embeddings = elmo(character_ids)
ELMo的動態詞嵌入是一項具有變革性的技術,它提供了細致入微的詞表示,能夠根據上下文反映單詞的不同含義。這為更復雜的自然語言處理應用鋪平了道路,提升了包括特征提取等在內的各種任務的性能。
在某些應用范圍有限的用例中,訓練一個自定義的嵌入模型可能會被證明是有益的。然而,訓練一個具有良好泛化能力的嵌入模型可能是一項艱巨的任務。收集和預處理文本數據可能很繁瑣,而且訓練過程在計算上也可能非常耗費資源。
對于任何構建人工智能系統的人來說,好消息是一旦創建了嵌入,它們也可以在不同的任務和領域中進行泛化。一些可供使用的著名預訓練嵌入模型如下:
- OpenAI的嵌入模型:
ChatGPT以及GPT系列大語言模型背后的公司OpenAI也提供了三種嵌入模型:text-embedding-ada-002、text-embedding-3-small、text-embedding-3-large。可以使用OpenAI API來訪問OpenAI的模型。 - 谷歌的Gemini嵌入模型:
text-embedding-004(最后更新于2024年4月)是谷歌Gemini提供的模型。可以通過Gemini API來訪問它。 - Voyage AI:
Voyage AI的嵌入模型得到了Claude系列大語言模型的提供商Anthropic的推薦。Voyage提供了幾種嵌入模型,如voyage-large-2-instruct、voyage-law-2、voyage-code-2 。 - Mistral AI嵌入模型:
Mistral是Mistral和Mixtral等大語言模型背后的公司。他們提供了一個名為mistral-embed的1024維嵌入模型。這是一個開源的嵌入模型。 - Cohere嵌入模型:
Cohere是Command、Command R和Command R+等大語言模型的開發者,他們也提供了多種嵌入模型,如embed-english-v3.0、embed-english-light-v3.0、embed-multilingual-v3.0等,可以通過Cohere API來訪問這些模型。
4. Word2Vec訓練
4.1 Word2Vec是如何生成詞嵌入的?
Word2Vec使用了一種你可能在機器學習的其他地方見過的技巧。
Word2Vec是一個帶有單個隱藏層的簡單神經網絡,和所有神經網絡一樣,它有權重,在訓練過程中,其目標是調整這些權重以最小化損失函數。然而,Word2Vec不會被用于它所訓練的任務,相反,我們只會提取它的隱藏層權重,將其用作我們的詞嵌入,然后拋棄模型的其余部分(這聽起來有點“殘忍”)。
你可能在無監督特征學習中也見過這種技巧,在無監督特征學習中,自編碼器被訓練用于在隱藏層中壓縮輸入向量,并在輸出層中將其解壓縮回原始向量。訓練完成后,輸出層(解壓縮步驟)會被去掉,只使用隱藏層,因為它已經學習到了很好的特征,這是一種在沒有標記訓練數據的情況下學習良好圖像特征的技巧。
4.2 架構
其架構類似于自編碼器的架構,你取一個較大的輸入向量,將其壓縮為一個較小的密集向量,然后與自編碼器不同的是,你不是將其解壓縮回原始輸入向量,而是輸出目標單詞的概率。
首先,我們不能將單詞作為字符串輸入到神經網絡中。
相反,我們將單詞作為獨熱向量輸入,獨熱向量本質上是一個長度與詞匯表相同的向量,除了表示我們要表示的單詞的索引位置被賦值為“1”之外,其余位置都填充為“0”。
隱藏層是一個標準的全連接(密集)層,其權重就是詞嵌入。
輸出層輸出詞匯表中目標單詞的概率。

這個網絡的輸入是一個表示輸入單詞的獨熱向量,標簽也是一個表示目標單詞的獨熱向量,然而,網絡的輸出是目標單詞的概率分布,不一定像標簽那樣是獨熱向量。
隱藏層權重矩陣的行,實際上就是我們想要的詞向量(詞嵌入)!

隱藏層就像一個查找表。隱藏層的輸出就是輸入單詞的“詞向量”。
更具體地說,如果你將一個1×10000的獨熱向量與一個10000×300的矩陣相乘,實際上它只會選擇矩陣中與“1”對應的那一行。

所有這些操作的最終目標是學習這個隱藏層權重矩陣,然后在完成后拋棄輸出層!
輸出層只是一個softmax激活函數:

這是該架構的一個高層示意圖:

4.3 語義和句法關系
那么Word2Vec如何幫助回答我們在本文開頭提出的問題呢?
從技術上講,如果不同的單詞在上下文中相似,那么當這些單詞作為輸入傳入時,Word2Vec應該產生相似的輸出,并且為了產生相似的輸出,為這些單詞計算的詞向量(在隱藏層中)必須相似,因此Word2Vec的目的是為處于相似上下文中的單詞學習相似的詞向量。
Word2Vec能夠捕捉單詞之間多種不同程度的相似性,這樣語義和句法模式就可以通過向量運算來重現。像“男人之于女人就如同兄弟之于姐妹”這樣的模式可以通過對這些單詞的向量表示進行代數運算來生成,使得“兄弟”的向量表示 - “男人”的向量表示 + “女人”的向量表示產生的結果在模型中最接近“姐妹”的向量表示。這樣的關系可以針對一系列語義關系(例如國家 - 首都)以及句法關系(例如現在時態 - 過去時態)生成。

4.4 訓練算法
一個Word2Vec模型可以使用層次softmax算法和/或負采樣算法進行訓練,通常情況下,只使用負采樣算法。
傳統上,預測模型是根據最大似然原理進行訓練的,在給定前面單詞的情況下,基于對所有詞匯表單詞的softmax函數來最大化下一個單詞出現的概率。

然而,考慮到一個龐大的詞匯集,這種訓練過程在計算上是相當耗費資源的,因為我們需要在每個訓練步驟中計算并歸一化所有的詞匯表單詞。因此,許多模型提供了不同的減少計算量的方法。
這同樣適用于Word2Vec模型,盡管該網絡是淺層的,只有兩層,但它的寬度極大,因此,它的每一種訓練過程都提供了一種獨特的減少計算量的方法。
4.4.1 層次softmax算法
為了近似估計模型試圖最大化的條件對數似然,層次softmax方法使用哈夫曼樹來減少計算量。
層次softmax算法對于不常見的單詞效果更好。
很自然地,隨著訓練輪數的增加,層次softmax算法就不再那么有效了。
4.4.2 負采樣算法
負采樣算法通過只對N個負樣本實例以及目標單詞進行采樣,而不是對整個詞匯表進行采樣,從而減少計算量。
從技術上講,負采樣算法忽略了獨熱編碼標簽詞向量中的大部分“0”,并且只對目標單詞和一些隨機采樣的負類別進行權重傳播和更新。
更具體地說,負采樣算法在對目標單詞進行采樣的同時,也對負樣本實例(單詞)進行采樣,并在最大化目標單詞的對數似然的同時,最小化采樣得到的負樣本實例的對數似然。

如何選擇負樣本呢?
負樣本是根據一元詞分布來選擇的。
從本質上講,選擇一個單詞作為負樣本的概率與其出現的頻率相關,出現頻率越高的單詞越有可能被選為負樣本。
具體來說,每個單詞被賦予一個與其頻率(詞頻計數)的3/4次方相等的權重。選擇一個單詞的概率就是它的權重除以所有單詞的權重之和。
4.5 實際方法
使用不同的模型參數和不同規模的語料庫會極大地影響Word2Vec模型的質量。
可以通過多種方式提高模型的準確性,包括選擇模型架構(連續詞袋模型(CBOW)或跳字模型(Skip-Gram))、增加訓練數據集、增加向量的維度數量,以及增加算法所考慮的單詞窗口大小。這些改進中的每一項都伴隨著計算復雜度增加的代價,因此也會增加模型生成的時間。
在使用大型語料庫和高維度向量的模型中,跳字模型在總體上能產生最高的準確率,并且在語義關系方面始終能達到最高的準確率,而且在大多數情況下,在句法準確率方面也能達到最高。然而,連續詞袋模型的計算成本較低,并且能產生相似的準確率結果。
總體而言,隨著所使用單詞數量的增加以及維度數量的增加,準確率也會提高。將訓練數據的數量翻倍,與將向量維度的數量翻倍,所導致的計算復雜度增加程度是相當的。
4.5.1 子采樣
一些高頻詞往往提供的信息較少。頻率高于某個閾值的單詞(例如“a”、“an”和“that”)可以進行子采樣,以提高訓練速度和性能。此外,常見的單詞對或短語可以被視為單個“單詞”,以提高訓練速度。
4.5.2 維度
詞嵌入的質量隨著維度的增加而提高。然而,在達到某個閾值之后,邊際收益將會遞減。通常情況下,向量的維度被設置在100到1000之間。
4.5.3 上下文窗口
上下文窗口的大小決定了在給定單詞之前和之后的多少個單詞將被包含為該給定單詞的上下文單詞。根據作者的建議,對于跳字模型,推薦的值是10;對于連續詞袋模型,推薦的值是5。
下面是一個上下文窗口大小為2的跳字模型的示例:

5. 部署詞嵌入模型時的注意事項
- 在部署模型時,你需要使用與為詞嵌入創建訓練數據時相同的流程。如果你使用了不同的分詞器,或者不同的處理空白字符、標點符號等的方法,最終可能會得到不兼容的輸入。
- 在你的輸入中可能存在沒有預訓練向量的單詞。這樣的單詞被稱為未登錄詞(OOV,Out of Vocabulary)。你可以做的是將這些單詞替換為“UNK”,表示未知,然后單獨處理它們。
- 維度不匹配:向量可以有多種長度。如果你訓練的模型使用的向量長度為比如說400,然后在推理階段嘗試使用長度為1000的向量,你將會遇到錯誤。所以要確保在整個過程中使用相同的維度。
6. 如何選擇嵌入模型?
自從ChatGPT發布以及被恰如其分地稱為“大語言模型大戰”的局面出現以來,在開發嵌入模型方面也出現了一股熱潮。評估大語言模型和嵌入模型的標準有很多且在不斷發展。對于“使用哪種嵌入模型?”這個問題,沒有一個絕對正確的答案。然而,你可能會注意到某些嵌入模型在特定的用例(如摘要生成、文本生成、分類等)中效果更好。
OpenAI過去會針對不同的用例推薦不同的嵌入模型。然而,現在他們推薦在所有任務中都使用text-embeddings-3模型。
Hugging Face的多語言文本嵌入基準(MTEB,Multi-Task Evaluation Benchmark)排行榜會根據七個用例來評估幾乎所有可用的嵌入模型,這些用例包括:分類、聚類、成對分類、重排序、檢索、語義文本相似度(STS,Semantic Textual Similarity)和摘要生成。
另一個重要的考慮因素是成本。如果你處理大量的文檔,使用OpenAI的模型可能會產生相當高的成本。開源模型的成本則取決于具體的實現方式。
7. 結論
詞嵌入的發展歷程已經從簡單的獨熱編碼演進到了先進的基于變換器的模型。從像Word2Vec和GloVe這樣提供靜態嵌入的方法開始,這個領域已經發展到了具有上下文嵌入的ELMo、BERT和GPT,從而能夠更細致入微、更復雜地理解和生成人類語言。這種演進反映了在捕捉人類語言的復雜性方面的重大進步,最終成就了當代大語言模型和變換器的強大能力。
8. 檢驗你的知識!
8.1 問題及參考答案
- 你將如何解釋兩個詞向量之間的余弦相似度,以及它對于這兩個詞之間的關系意味著什么?
- 預期答案:余弦相似度衡量的是向量空間中兩個向量之間夾角的余弦值。余弦相似度接近1表明這些向量彼此接近,并且所代表的詞可能具有相似的含義。余弦相似度為0則表明這些向量是正交的,這意味著這些詞是不相關的。負的余弦相似度則表明這些詞具有相反的含義。
- 討論在捕捉一詞多義(polysemy)和同音異義詞(homonymy)方面,向量空間表示法的局限性。現代的嵌入技術是如何解決這些局限性的?
- 預期答案:像Word2Vec這樣的傳統向量空間模型會為每個詞分配一個單一的向量,這無法捕捉一詞多義(一個詞有多種含義)和同音異義詞(發音相同但含義不同的詞)的情況。像上下文嵌入(例如BERT)這樣的現代嵌入技術通過根據詞的上下文為同一個詞生成不同的向量來解決這個問題,從而有效地捕捉了不同的含義。
- 在訓練詞嵌入時,使用大詞匯量和減少詞匯量之間存在哪些權衡?
- 預期答案:大詞匯量能讓模型捕捉到更廣泛的詞以及詞的細微差別,但會增加計算復雜度和內存需求。減少詞匯量可以使訓練速度加快并且降低資源使用量,但可能會遺漏重要的詞或詞的細微差別,導致對低頻詞的嵌入效果變差。
- 在哪些場景中,相較于使用全softmax方法,你更傾向于在訓練詞嵌入時使用基于采樣的方法(如負采樣)?
- 預期答案:當處理大型數據集和大量詞匯時,更傾向于使用負采樣,因為它通過只更新一小部分權重,顯著降低了計算成本。當重點在于捕捉詞之間的相似性,而非對整個詞匯表的分布進行建模(就像在Word2Vec這樣的模型中)時,負采樣尤其有用。
- 在捕捉詞的含義和上下文方面,BERT嵌入與Word2Vec嵌入有何不同?
- 預期答案:BERT嵌入是上下文相關的,這意味著它會根據周圍的上下文為同一個詞生成不同的嵌入。這使得BERT能夠根據詞在句子中的用法捕捉詞的動態含義。相比之下,Word2Vec生成的是靜態嵌入,其中每個詞都有一個單一的向量表示,與上下文無關。
- 解釋FastText是如何通過納入子詞信息來改進Word2Vec的。這對生僻詞的嵌入質量有何影響?
- 預期答案:FastText通過將詞表示為字符n元語法的集合來改進Word2Vec,這使得它能夠通過組合子詞的嵌入來生成詞的嵌入。這種方法有助于為罕見詞或未登錄詞生成更好的嵌入,因為即使在完整的詞數據稀疏的情況下,它也可以利用子詞信息來創建有意義的表示。
- 討論層次softmax的使用及其對大型數據集訓練效率的影響。
- 預期答案:層次softmax是一種在大詞匯量情況下用于近似softmax函數的技術。它將詞匯表構建成一棵二叉樹,使得模型能夠以對數時間而非線性時間來計算概率。通過減少所需的計算量,這極大地提高了訓練效率,尤其是在處理非常大的數據集和大量詞匯時。
- 解釋為特定領域應用優化嵌入所面臨的挑戰,以及你將如何應對這些挑戰。
- 預期答案:特定領域的應用可能需要能夠捕捉該領域獨特細微差別的嵌入,而通用的嵌入可能會遺漏這些。挑戰包括特定領域的數據有限、詞匯不匹配以及需要進行微調。為了應對這些問題,可以使用遷移學習,即對一個通用模型在特定領域的數據上進行微調,或者使用特定領域的語料庫從頭開始訓練嵌入。
- 對于像情感分析這樣的特定任務,你將如何評估詞嵌入的質量?你會使用哪些指標?
- 預期答案:對于情感分析任務的詞嵌入質量,可以使用內在指標和外在指標來評估。內在評估包括諸如詞相似度或類比任務等。外在評估則涉及在下游任務(如情感分析)中使用這些嵌入,并使用諸如準確率、F1值或AUC等指標來衡量性能。在特定任務的上下文中,這些嵌入區分積極和消極情感詞的能力至關重要。
- 討論在評估詞嵌入質量時,僅僅依賴諸如類比任務這樣的內在評估指標可能存在的陷阱。
- 預期答案:像類比任務這樣的內在指標通常測試的是嵌入的幾何屬性,但可能與下游任務的性能沒有很好的相關性。它們可能會給人一種關于嵌入質量的錯誤印象,因為它們沒有考慮到特定應用的具體要求。例如,在類比任務中表現良好的嵌入,在捕捉情感分析或命名實體識別所需的細微差別方面可能仍然會失敗。因此,外在評估為特定任務的嵌入質量提供了更實際的衡量標準。
- 在低延遲環境中部署像BERT這樣的上下文嵌入模型可能會面臨哪些潛在挑戰,以及你將如何緩解這些挑戰?
- 預期答案:在低延遲環境中部署BERT存在挑戰,因為它的規模大且計算復雜,這可能導致推理時間緩慢。緩解策略包括模型蒸餾(在保持性能的同時減小模型的規模)、量化(降低模型權重的精度),或者使用更高效的變體,如DistilBERT或ALBERT。此外,諸如緩存常見短語的嵌入,或者使用兩階段方法(即先由一個更簡單的模型對輸入進行過濾,然后再將其傳遞給BERT)等技術,有助于減少延遲。
- 在生產環境中部署詞嵌入模型時,你將如何處理未登錄詞(OOV)的問題?
- 預期答案:處理未登錄詞的問題,可以使用納入子詞信息的模型,如FastText,它可以通過將未見過的詞分解為已知的子詞來生成其嵌入。另一種方法是使用像BERT這樣的上下文模型,它可以根據上下文推斷未登錄詞的含義。在某些情況下,你還可以設置一個備用機制,將未登錄詞映射到一個表示未知詞的通用向量,或者通過字符級嵌入或哈希等技術來處理它們。
8.2 自主探究
- 應該選擇哪種嵌入模型以及原因是什么。你將如何選擇嵌入模型的規模?
- 什么是“維度災難”,以及它與自然語言處理(NLP)有何關系?
參考文獻
- https://medium.com/@vipra_singh/llm-architectures-explained-word-embeddings-part-2-ff6b9cf1d82d









)


![[python] 正則表達式](http://pic.xiahunao.cn/[python] 正則表達式)





)
:總結篇——問題定位思路與工具選擇策略)