前言
本文隸屬于專欄《機器學習的一百個概念》,該專欄為筆者原創,引用請注明來源,不足和錯誤之處請在評論區幫忙指出,謝謝!
本專欄目錄結構和參考文獻請見[《機器學習的一百個概念》
ima 知識庫
知識庫廣場搜索:
| 知識庫 | 創建人 |
|---|---|
| 機器學習 | @Shockang |
| 機器學習數學基礎 | @Shockang |
| 深度學習 | @Shockang |
正文

基礎概念與原理 🔍
1.1 下采樣的定義
下采樣(Downsampling)是機器學習中一個多義性概念,根據應用場景可分為兩大類:
- 數據層面的下采樣:在類別不平衡問題中,通過減少多數類樣本數量來平衡數據分布的技術
- 特征層面的下采樣:在深度學習中,特別是卷積神經網絡(CNN)中用于降低數據維度或分辨率的操作
1.2 下采樣的工作流程

1.3 理論基礎
下采樣的理論基礎主要涉及以下幾個方面:
-
統計學基礎:
- 樣本代表性
- 隨機性與均勻性
- 概率分布保持
-
信息論基礎:
- 信息熵
- 數據壓縮
- 信息損失評估
-
采樣理論:
- Nyquist采樣定理
- 香農采樣定理
- 混疊效應
應用場景與實現方法 💡
2.1 類別不平衡問題中的下采樣
2.1.1 基本方法

-
隨機下采樣
- 優點:實現簡單,計算效率高
- 缺點:可能丟失重要信息
- 適用場景:數據量大,多數類樣本具有較高冗余度
-
啟發式下采樣
- NearMiss算法
- Tomek Links
- 編輯最近鄰(ENN)
- One-Sided Selection(OSS)
-
集成下采樣
- EasyEnsemble
- BalanceCascade
- UnderBagging
2.2 深度學習中的下采樣
2.2.1 池化操作
- 最大池化(Max Pooling)
import torch.nn as nn# 定義2x2的最大池化層
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
- 平均池化(Average Pooling)
# 定義2x2的平均池化層
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
- 步幅卷積(Strided Convolution)
# 使用步幅為2的卷積進行下采樣
conv_downsample = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=2, padding=1)
2.3 下采樣的數學表達
對于圖像處理中的下采樣,其數學表達式為:
Y [ n ] = X [ M n ] Y[n] = X[Mn] Y[n]=X[Mn]
其中:
- X [ n ] X[n] X[n] 是輸入信號
- M M M 是下采樣因子
- Y [ n ] Y[n] Y[n] 是下采樣后的信號
高級技巧與最佳實踐 🚀
3.1 自適應下采樣策略
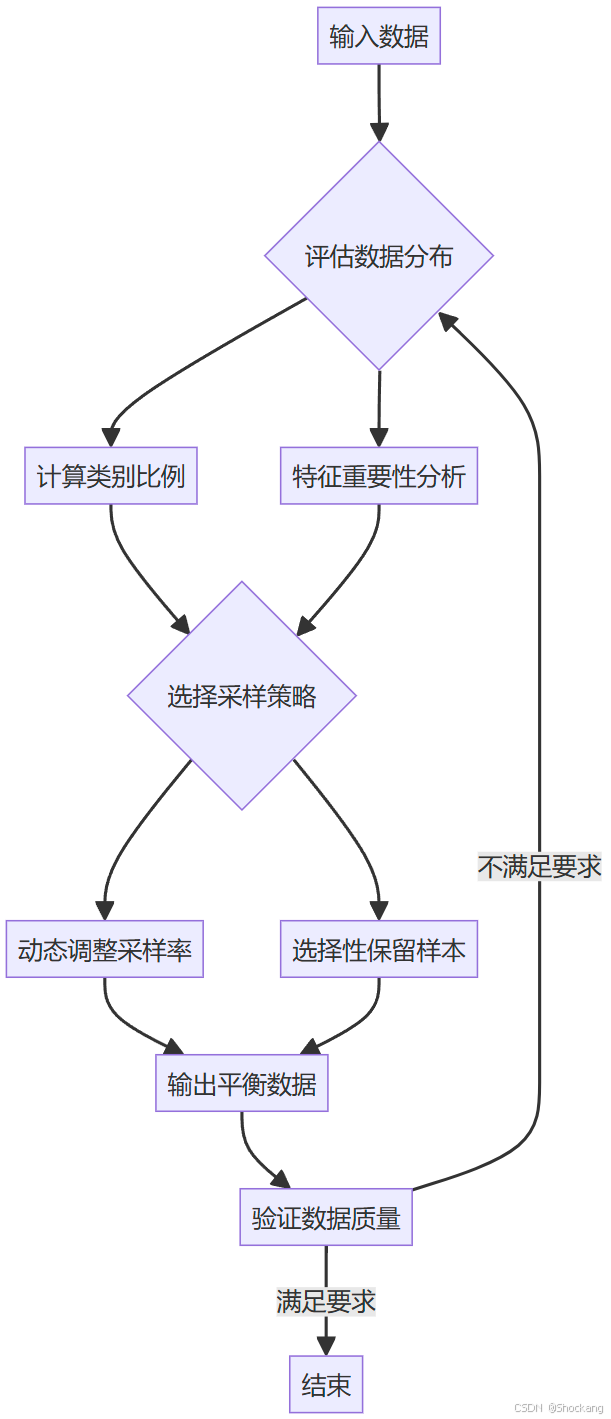
3.2 高級采樣技術
- 基于密度的下采樣
from sklearn.neighbors import KernelDensitydef density_based_undersampling(X, y, threshold):kde = KernelDensity(bandwidth=0.5)kde.fit(X[y==1]) # 針對多數類densities = kde.score_samples(X[y==1])return X[densities > threshold]
- 基于聚類的下采樣
from sklearn.cluster import KMeansdef cluster_based_undersampling(X, y, n_clusters):majority_class = X[y==1]kmeans = KMeans(n_clusters=n_clusters)clusters = kmeans.fit_predict(majority_class)return majority_class[::len(majority_class)//n_clusters]
常見陷阱與解決方案 ??
4.1 信息丟失問題
-
問題描述
- 隨機下采樣可能丟失關鍵樣本
- 特征空間覆蓋不完整
- 決策邊界變形
-
解決方案
- 使用啟發式采樣方法
- 實施分層采樣
- 采用集成學習策略
4.2 采樣偏差
-
現象
- 樣本分布失真
- 模型性能不穩定
- 過擬合風險增加
-
緩解措施
- 交叉驗證
- 多重采樣
- 數據增強
實戰案例分析 💻
5.1 信用卡欺詐檢測
import pandas as pd
from sklearn.utils import resample
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report# 加載數據
df = pd.read_csv('credit_card_fraud.csv')
majority = df[df.Class==0]
minority = df[df.Class==1]# 下采樣多數類
majority_downsampled = resample(majority, replace=False,n_samples=len(minority),random_state=42)# 合并數據
balanced_df = pd.concat([majority_downsampled, minority])# 訓練模型
X = balanced_df.drop('Class', axis=1)
y = balanced_df['Class']
clf = RandomForestClassifier(random_state=42)
clf.fit(X, y)
5.2 圖像分類中的下采樣
import torch.nn as nnclass ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(3, 16, 3, padding=1)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(16, 32, 3, padding=1)self.fc = nn.Linear(32 * 8 * 8, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # 下采樣x = self.pool(F.relu(self.conv2(x))) # 下采樣x = x.view(-1, 32 * 8 * 8)x = self.fc(x)return x
未來發展趨勢 🔮
-
智能采樣
- 基于強化學習的采樣策略
- 自適應采樣率調整
- 多目標優化采樣
-
混合策略
- 下采樣與過采樣結合
- 多種采樣方法集成
- 遷移學習融合
-
新興應用
- 聯邦學習中的采樣策略
- 邊緣計算場景下的輕量級采樣
- 自監督學習中的采樣技術
總結與建議 📝
下采樣是機器學習中一個重要的數據處理技術,其成功應用需要:
-
深入理解問題場景
- 數據分布特點
- 業務需求約束
- 計算資源限制
-
合理選擇策略
- 根據數據規模選擇合適的采樣方法
- 考慮采樣帶來的影響
- 權衡效率與效果
-
注重實踐驗證
- 充分的實驗對比
- 嚴格的效果評估
- 持續的優化改進
本文詳細介紹了下采樣的各個方面,從理論到實踐,希望能夠幫助讀者更好地理解和應用這一技術。在實際應用中,建議讀者根據具體場景選擇合適的下采樣策略,并注意避免常見陷阱。





)


)

)




)
——RAG的retriever模塊作用,原理和目前存在的挑戰)


PyTorch版)