本文所使用數據來自于梯田景區評價數據。
一、數據預處理
數據清洗
去除重復值、空值及無關字符(如表情符號、特殊符號等)。
提取中文文本,過濾非中文字符。
統一文本格式(如全角轉半角、繁體轉簡體)。
中文分詞與去停用詞
使用 jieba 分詞工具進行分詞。
加載自定義詞典(如景點名“多依樹”“老虎嘴”等專有名詞)。
去除通用停用詞(如“的”“了”)和自定義停用詞(如“同程”“門票”)。
情感標簽分類
統計情感分布(好評、中評、差評占比)。
若數據不均衡,采用過采樣(SMOTE)或調整類別權重。
二、可視化分析
詞云生成
全局詞云:所有評論文本的詞頻統計。
分情感詞云:分別生成好評、中評、差評的詞云,對比關鍵詞差異。
工具:WordCloud + matplotlib。


高頻詞條形圖
按詞頻排序,展示Top 20高頻詞。
分情感統計高頻詞(如好評中的“壯觀”“方便”,差評中的“堵車”“貴”)。
情感分布餅圖
可視化好評、中評、差評的比例。
三、特征工程
文本向量化
TF-IDF:提取文本的TF-IDF特征,生成詞-文檔矩陣。
Word2Vec:訓練詞向量模型,獲取語義特征。
BERT(可選):使用預訓練模型提取深度語義特征。
情感標簽編碼
將“好評”“中評”“差評”映射為數值標簽(如0,1,2)。
四、數據建模
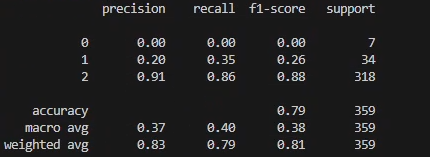
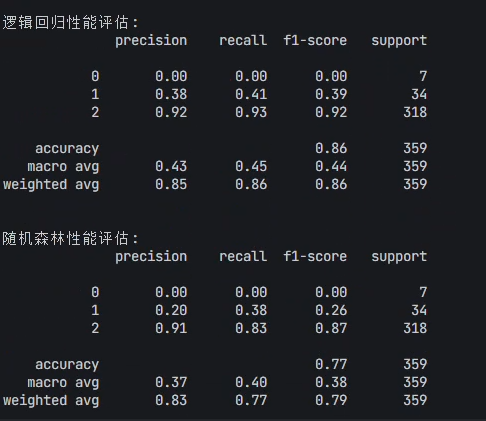
分類模型(情感預測)
模型選擇:邏輯回歸、隨機森林、SVM、LSTM(深度學習)。
輸入:TF-IDF向量 + 情感標簽。
輸出:預測情感類別,評估準確率、F1值。
主題模型(LDA)
提取評論文本中的潛在主題,分析用戶關注點(如“交通”“門票價格”“風景”)。
結合情感標簽,統計不同主題的情感傾向。

情感強度分析
使用情感詞典(如BosonNLP)計算每條評論的情感強度值。
分析不同情感類別的強度分布(如差評是否情緒更強烈)。
五、關鍵分析方向
好評驅動因素
高頻詞:方便、壯觀、震撼、自駕、日出。
潛在主題:取票便捷、風景優美、天氣影響。
差評改進點
高頻詞:堵車、貴、管理差、服務態度。
潛在主題:交通擁堵、門票性價比、配套設施不足。
中評矛盾點
高頻詞:一般、季節、不值。
潛在主題:景色依賴天氣、性價比爭議。
完整代碼如下:
import pandas as pd
import re
import jieba
import jieba.analyse
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 在文件頂部導入matplotlib后添加字體配置
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei' # 設置中文字體
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題
from wordcloud import WordCloud
from collections import Counter# 數據預處理函數
def preprocess_text(text):# 去非中文字符(保留中文標點)text = re.sub(r'[^\u4e00-\u9fa5,。!?;:、]', '', str(text))# 合并重復標點text = re.sub(r'([,。!?;:、])\1+', r'\1', text)return text.strip()# 加載自定義詞典(需要用戶提供路徑)
jieba.load_userdict('custom_dict.txt') # 請替換為實際詞典路徑# 加載停用詞(需要用戶提供路徑)
def load_stopwords(path):with open(path, 'r', encoding='utf-8') as f:return set([line.strip() for line in f])
stopwords = load_stopwords('stopwords.txt') # 請替換為實際停用詞路徑# 中文分詞處理
def chinese_segment(text):# 確保輸入為字符串if not isinstance(text, str):text = str(text)words = jieba.lcut(text)return [w for w in words if w not in stopwords and len(w) > 1]# 生成詞云函數
# 修改生成詞云函數中的字體路徑
def generate_wordcloud(text, title):wordcloud = WordCloud(font_path='C:/Windows/Fonts/simhei.ttf', # 使用絕對路徑確保找到字體background_color='white',width


)
——RAG的retriever模塊作用,原理和目前存在的挑戰)


PyTorch版)


在前端開發中的實踐演進:從 XMLHttpRequest 到 Fetch API)
scan-build與clang-tidy使用)



GEE基礎學習初探及案例詳解【20250330】)



