
前言:Hello大家好,我是小哥談。YOLOv9還沒捂熱乎,YOLOv10就推出來了,太卷了,太快了,坐等YOLOv9000!自今年2月YOLOv9發布之后, YOLO(You Only Look Once)系列的接力棒傳到了清華大學研究人員的手上。YOLOv10推出的消息引發了AI界的關注,它被認為是計算機視覺領域的突破性框架,以實時的端到端目標檢測能力而聞名,通過提供結合效率和準確性的強大解決方案,延續了YOLO系列的傳統。新版本發布之后,很多人已經進行了部署測試,效果不錯,本節課就帶領大家如何基于YOLOv10訓練模型并推理測試!~🌈
? ? ?目錄
🚀1.算法介紹
🚀2.網絡結構
🚀3.數據標注
🚀4.模型訓練
第1步:準備數據集
第2步:創建yaml文件
第3步:下載預訓練權重
第4步:新建Python文件
第5步:調節參數
第6步:開始訓練
🚀5.模型推理
🚀6.導出模型
🚀7.本節總結

🚀1.算法介紹
在我們深入探討YOLOv10之前,讓我們回顧一下YOLO的發展歷程。YOLO在實時目標檢測領域一直是先驅,兼顧速度和準確性。從YOLOv1到YOLOv9,每個版本在架構、優化和數據增強方面都引入了顯著的改進。然而,隨著模型的發展,某些限制依然存在,特別是對后處理依賴非極大值抑制(NMS),這會減慢推理速度。YOLOv10正面解決了這些挑戰,使其成為實時應用中穩健高效的模型。
YOLOv10是清華大學研究人員所研發的一種新的實時目標檢測方法,解決了YOLO以前版本在后處理和模型架構方面的不足。通過消除非最大抑制(NMS)和優化各種模型組件,YOLOv10在顯著降低計算開銷的同時實現了最先進的性能。并用大量實驗證明,YOLOv10在多個模型尺度上實現了卓越的精度-延遲權衡。
YOLOv10亮點:
無 NMS 設計:利用一致的雙重分配來消除對NMS的需求,從而減少推理延遲。
整體模型設計:從效率和準確性的角度全面優化各種組件,包括輕量級分類頭、空間通道去耦向下采樣和等級引導塊設計。
增強的模型功能:納入大核卷積和部分自注意模塊,在不增加大量計算成本的情況下提高性能。
自從Ultralytics發布YOLOv5以來,我們已經習慣了每次YOLO發布時提供各種模型尺寸:nano、small、medium、large和xlarge。YOLOv10也不例外,清華大學的研究人員也提供了一系列預訓練模型,可以用于各種目標檢測任務。
所有這些模型在延遲和平均精度(AP)方面表現出優于之前YOLO版本的性能,如下圖所示:
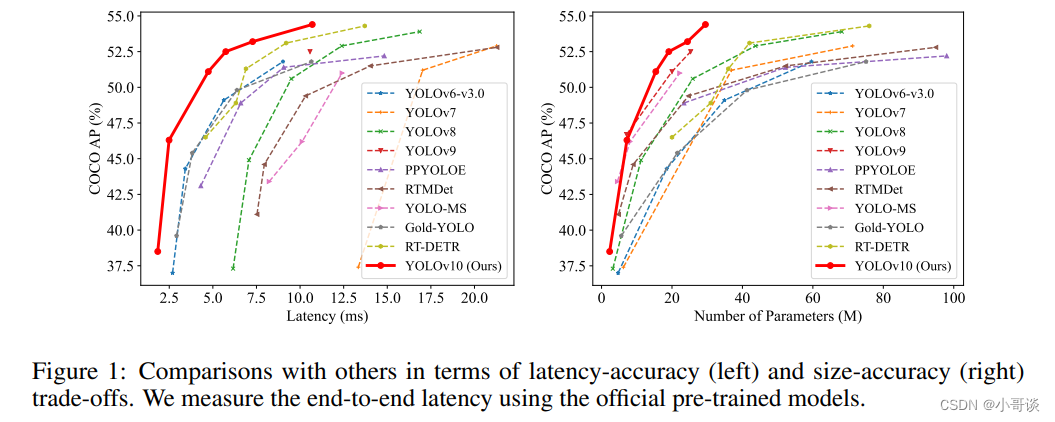
YOLOv10有多種型號,可滿足不同的應用需求:
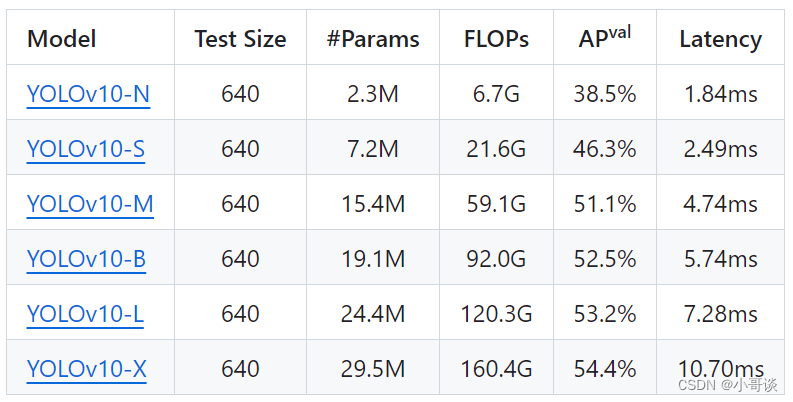
YOLOv10-N:用于資源極其有限環境的納米版本。
YOLOv10-S:兼顧速度和精度的小型版本。
YOLOv10-M:通用中型版本。
YOLOv10-B:平衡型,寬度增加,精度更高。
YOLOv10-L:大型版本,精度更高,但計算資源增加。
YOLOv10-X:超大型版本可實現最高精度和性能。

論文題目:《YOLOv10: Real-Time End-to-End Object Detection》
論文地址:??https://arxiv.org/pdf/2405.14458
代碼實現:??GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
🚀2.網絡結構
關于YOLOv10的網絡結構圖具體如下圖所示:
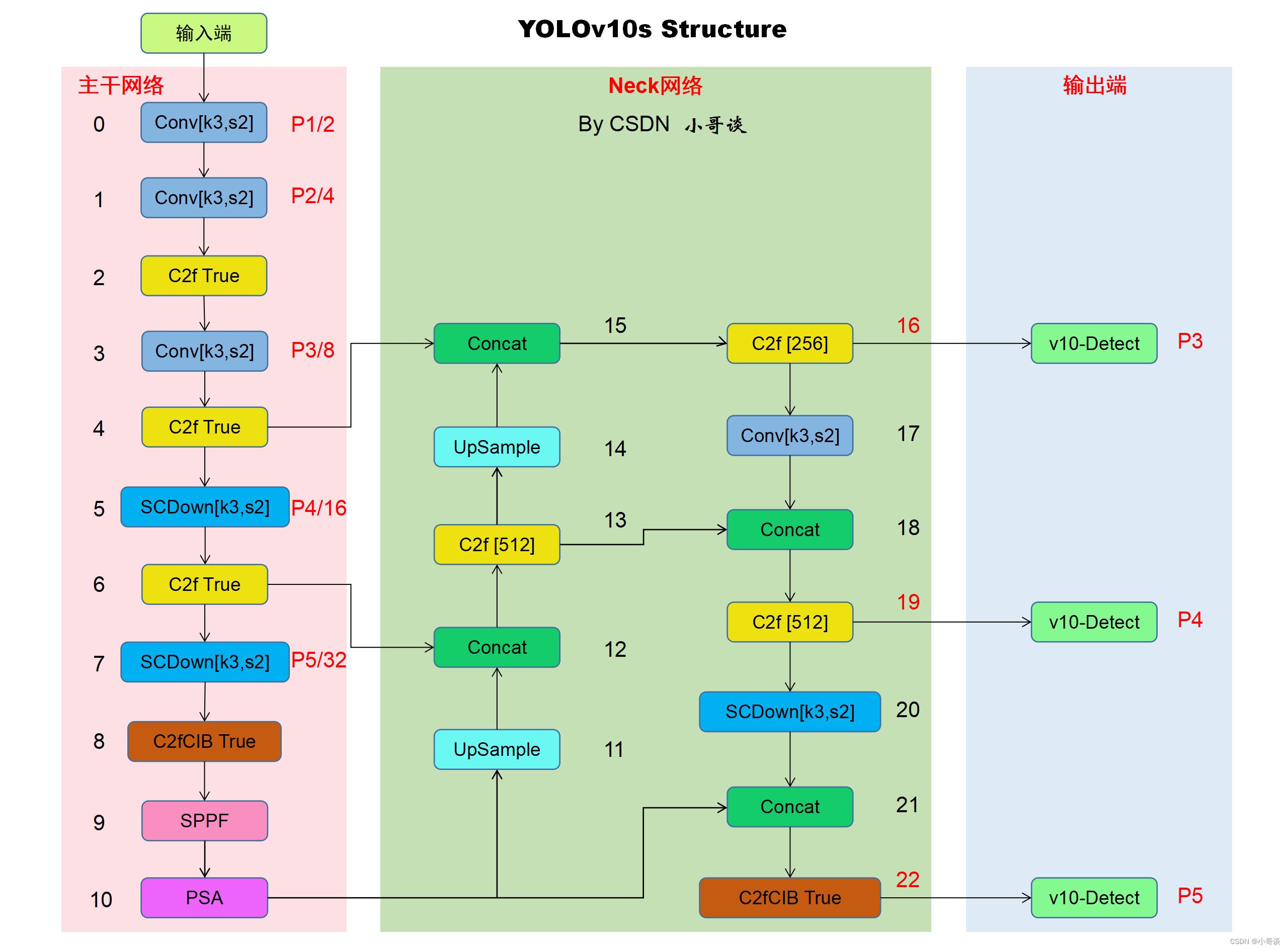
備注:后續關于改進就是基于上述YOLOv10網絡結構圖,請大家提前熟悉其基礎組件。?
🚀3.數據標注
利用labelimg或者make sense軟件來標注數據,關于如何使用labelimg或者make sense軟件來為自己的數據集打上標簽,請參考作者專欄文章:👇
說明:??????
數據標注工具的使用教程:
YOLOv5入門實踐(1)— 手把手教你使用labelimg標注數據集(附安裝包+使用教程)
YOLOv5入門實踐(2)— 手把手教你使用make sense標注數據集(附工具地址+使用教程)
🚀4.模型訓練
第1步:準備數據集
將數據集放在datasets文件夾中。datasets屬于放置數據集的地方,位于PycharmProjects中,C:\Users\Lenovo\PycharmProjects中(這是我的電腦位置,跟你的不一定一樣,反正位于PycharmProjects中,如果沒有,可自行創建),屬于項目的同級文件夾。
具體如下圖所示:
打開datasets文件夾,可以看到本次安全帽訓練所使用的數據集。

安全帽佩戴檢測數據集是我手動標注好的,可以在我的博客“資源”中下載。

打開數據集文件,我們會看到數據集文件包括images和labels兩個文件夾,其中,images放的是數據集圖片,包括train和val兩個文件夾,labels放的是經過labelimg標注所生成的標簽,也包括train和val兩個文件夾。
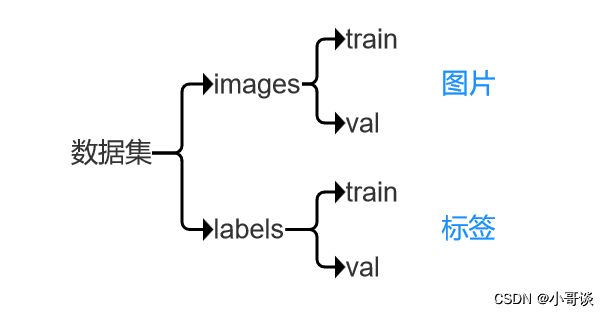
關于此處數據集的邏輯關系,用一張圖總結就是:??????
第2步:創建yaml文件
打開pycharm,選擇yolov10-main項目源碼文件,在datasets下新建一個helmet.yaml,具體位置是ultralytics/cfg/datasets,如下圖所示:👇
打開helmet.yaml,其內容如下:
# Train/val
train: C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\images\train
val: C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\images\val
test: # test images# Classes
nc: 2 # number of classes
names: ['helmet','nohelmet']說明:??????
1.train和val為絕對路徑地址,可根據自己數據集的路徑地址自行設置。
2.nc指的是分類,即模型訓練結果分類,此處為在用labelimg或者make sense為數據集標注時候確定。
3.由于本次進行的是安全帽佩戴檢測模型訓練,所以分兩類,分別是:helmet(佩戴安全帽)和nohelmet(不佩戴安全帽)
打開coco.yaml文件,可以看到里面寫的是相對路徑,和我們的寫法不同,但是都可以使用,據我所知還有很多種數據集讀取方式:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset https://cocodataset.org by Microsoft
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco # dataset root dir
train: train2017.txt # train images (relative to 'path') 118287 images
val: val2017.txt # val images (relative to 'path') 5000 images
test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794# Classes
names:0: person1: bicycle2: car3: motorcycle4: airplane5: bus6: train7: truck8: boat9: traffic light10: fire hydrant11: stop sign12: parking meter13: bench14: bird15: cat16: dog17: horse18: sheep19: cow20: elephant21: bear22: zebra23: giraffe24: backpack25: umbrella26: handbag27: tie28: suitcase29: frisbee30: skis31: snowboard32: sports ball33: kite34: baseball bat35: baseball glove36: skateboard37: surfboard38: tennis racket39: bottle40: wine glass41: cup42: fork43: knife44: spoon45: bowl46: banana47: apple48: sandwich49: orange50: broccoli51: carrot52: hot dog53: pizza54: donut55: cake56: chair57: couch58: potted plant59: bed60: dining table61: toilet62: tv63: laptop64: mouse65: remote66: keyboard67: cell phone68: microwave69: oven70: toaster71: sink72: refrigerator73: book74: clock75: vase76: scissors77: teddy bear78: hair drier79: toothbrush# Download script/URL (optional)
download: |from ultralytics.utils.downloads import downloadfrom pathlib import Path# Download labelssegments = True # segment or box labelsdir = Path(yaml['path']) # dataset root dirurl = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labelsdownload(urls, dir=dir.parent)# Download dataurls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)download(urls, dir=dir / 'images', threads=3)
第3步:下載預訓練權重
打開YOLOv10官方倉庫地址,可以根據需要下載相應的預訓練權重。
預訓練權重下載地址:
GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
下載完畢后,在主目錄下新建weights文件夾(如果已存在,就不需要新建,直接使用即可),然后將下載的權重文件放在weights文件夾下。具體如下圖所示:👇
第4步:新建Python文件
通過查看YOLOv10官方文檔可知,YOLOv10提供CLI和python兩種訓練方式。區別在于:
- 方式1:CLI就是直接在終端運行指令
- 方式2:python需要你新建一個python文件,然后運行代碼
方式1:
訓練模型的話直接用命令行就可以了
yolo detect train data=custom_dataset.yaml model=yolov10s.yaml epochs=300 batch=8 imgsz=640 device=0,1device:設備id,如果只有一張顯卡,則device=0,如果有兩張,則device=0,1,依次類推。
imgsz:圖像放縮大小resize,默認是640,如果資源不夠可以設置為320試試。
方式2:
考慮到部分同學不喜歡使用命令行方式,在YOLOv10源碼目錄下新建Python文件,命名為train.py。具體如下圖所示:
關于train.py文件的完整代碼如下所示:
# coding:utf-8
from ultralytics import YOLOv10
# 模型配置文件
model_yaml_path = "ultralytics/cfg/models/v10/yolov10n.yaml"
# 數據集配置文件
data_yaml_path = 'ultralytics/cfg/datasets/helmet.yaml'
# 預訓練模型
pre_model_name = 'yolov10n.pt'if __name__ == '__main__':# 加載預訓練模型model = YOLOv10("ultralytics/cfg/models/v10/yolov10n.yaml").load('yolov10n.pt')# 訓練模型results = model.train(data=data_yaml_path,epochs=100,batch=8,name='train_v10')第5步:調節參數
YOLOv10關于模型的各種參數都在ultralytics/cfg/default.yaml中(其實是與YOLOv8一致的),通過調節這些參數我們就可以實現各種我們所需的操作。
第6步:開始訓練
點擊運行train.py文件即可進行訓練了,可以看到所打印的網絡結構如下所示。

🚀5.模型推理
模型推理測試(默認讀取yolov10/ultralytics/assets文件夾下的所有圖像)
yolo predict model=yolov10s.pt如果測試別的路徑下的文件可以在上面命令后面加上source='xxx/bus.jpg',如果想測試視頻,可以使用source='xxx/bus.mp4'。
也可以在YOLOv10根目錄下創建predict.py文件,該文件源代碼如下所示:
from ultralytics import YOLOv10# Load a pretrained YOLOv10n model
model = YOLOv10("runs/detect/train_v10/weights/best.pt")# Perform object detection on an image
# results = model("test1.jpg")
results = model.predict("ultralytics/assets/bus.jpg")# Display the results
results[0].show()備注:上面的相對路徑地址為訓練后的權重文件和所檢測的圖片地址,根據實際絕對地址填寫。
點擊運行,模型推理結果如下所示:

🚀6.導出模型
本節課提供兩種導出模型的方法:
方法1:CLI命令方式
yolo export model=yolov10x.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model方式2:Python文件方式
from ultralytics import YOLOv10
# Load a model
model = YOLOv10('yolov10x.pt') # load an official model
model = YOLOv10('path/to/best.pt') # load a custom trained model# Export the model
model.export(format='onnx')🚀7.本節總結
清華大學研究人員推出的YOLOv10,作為首個無NMS目標檢測模型,代表了計算機視覺領域的重大進步。與YOLOv8相比,YOLOv10顯著減少了推理延遲,使其更適合高速實時應用,如自動駕駛、視頻監控和交互式AI系統。這種推理過程中計算步驟的減少突顯了YOLOv10的效率和響應能力。
此外,YOLOv10采用了新的無NMS訓練方法,對其各部分進行了微調以提高性能,并在速度和準確性之間達到了很好的平衡。這些升級使得模型的部署更容易,性能更強,速度更快,響應更迅速。無論你是研究人員、開發人員還是技術愛好者,YOLOv10都是值得關注的模型。







分析)












