尼恩:LLM大模型學習圣經PDF的起源
在40歲老架構師 尼恩的讀者交流群(50+)中,經常性的指導小伙伴們改造簡歷。
經過尼恩的改造之后,很多小伙伴拿到了一線互聯網企業如得物、阿里、滴滴、極兔、有贊、希音、百度、網易、美團的面試機會,拿到了大廠機會。
然而,其中一個成功案例,是一個9年經驗 網易的小伙伴,當時拿到了一個年薪近80W的大模型架構offer,逆漲50%,那是在去年2023年的 5月。
- 驚天大逆襲:8年小伙20天時間提75W年薪offer,逆漲50%,秘訣在這
不到1年,小伙伴也在團隊站穩了腳跟,成為了名副其實的大模型架構師。
目前,他管理了10人左右的團隊,包括一個2-3人的python算法小分隊,包括一個3-4人Java應用開發小分隊,包括一個2-3人實施運維小分隊。并且他們的產品也收到了豐厚的經濟回報, 他們的AIGC大模型產品,好像已經實施了不下10家的大中型企業客戶。
當然,尼恩更關注的,主要還是他的個人的職業身價。
小伙伴反饋,不到一年,他現在是人才市場的香饃饃。怎么說呢?
他現在職業機會不知道有多少, 而是大部分都是P8+ (年薪200W+)的頂級機會。
回想一下,去年小伙伴來找尼恩的時候, 可謂是 令人唏噓。
當時,小伙伴被網易裁員, 自己折騰 2個月,沒什么好的offer, 才找尼恩求助。
當時,小伙伴其實并沒有做過的大模型架構, 僅僅具備一些 通用架構( JAVA 架構、K8S云原生架構) 能力,而且這些能力還沒有完全成型。
特別說明,他當時 沒有做過大模型的架構,對大模型架構是一片空白。
本來,尼恩是規劃指導小伙做通用架構師的( JAVA 架構、K8S云原生架構),
毫無疑問,大模型架構師更有錢途,所以, 當時候尼恩也是 壯著膽子, 死馬當作活馬指導他改造為 大模型架構師。
回憶起當時決策的出發點,主要有3個:
(1)架構思想和體系,本身和語言無關,和業務也關系不大,都是通的。
(2)小伙伴本身也熟悉一點點深度學習,懂python,懂點深度學習的框架,至少,demo能跑起來。
(3)大模型架構師稀缺,反正面試官也不是太懂 大模型架構。
基于這個3個原因,尼恩大膽的決策,指導他往大模型架構走,先改造簡歷,然后去面試大模型的工程架構師,特別注意,這個小伙伴面的不是大模型算法架構師。
沒想到,由于尼恩的大膽指導, 小伙伴成了。
沒想到,由于尼恩的大膽指導, 小伙伴成了, 而且是大成,實現了真正的逆天改命。
相當于他不到1年時間, 職業身價翻了1倍多,可以拿到年薪 200W的offer了。
既然有一個這么成功的案例,尼恩能想到的,就是希望能幫助更多的社群小伙伴, 成長為大模型架構師,也去逆天改命。
于是,從2024年的4月份開始,尼恩開始寫 《LLM大模型學習圣經》,幫助大家穿透大模型,走向大模型之路。

尼恩架構團隊的大模型《LLM大模型學習圣經》是一個系列,初步的規劃包括下面的內容:
-
《Python學習圣經:從0到1精通Python,打好AI基礎》
-
《LLM大模型學習圣經:從0到1吃透Transformer技術底座》
-
《LangChain學習圣經:從0到1精通LLM大模型應用開發的基礎框架》
-
《LLM大模型學習圣經:從0到1精通RAG架構,基于LLM+RAG構建生產級企業知識庫》
-
《SpringCloud + Python 混合微服務架構,打造AI分布式業務應用的技術底層》
-
《LLM大模型學習圣經:從0到1吃透大模型的頂級架構》
本文是第1篇,作者是資深架構師 Andy(負責初稿) +43歲老架構師尼恩(負責升華,帶給大家一種俯視技術,技術自由的高度)。
尼恩架構團隊會持續迭代和更新,后面會有實戰篇,架構篇等等出來。 并且錄制配套視頻。
在尼恩的架構師哲學中,開宗明義:架構和語言無關,架構的思想和模式,本就是想通的。
架構思想和體系,本身和語言無關,和業務也關系不大,都是通的。
所以,尼恩用自己的架構內功,以及20年時間積累的架構洪荒之力,通過《LLM大模型學習圣經》,給大家做一下系統化、體系化的LLM梳理,使得大家內力猛增,成為大模型架構師,然后實現”offer直提”, 逆天改命。
尼恩 《LLM大模型學習圣經》PDF 系列文檔,會延續尼恩的一貫風格,會持續迭代,持續升級。
這個文檔將成為大家 學習大模型的殺手锏, 此文當最新PDF版本,可以來《技術自由圈》公號獲取。
本文目錄
第一部分:基礎入門
第一章:Python簡介
歡迎來到Python編程的世界!Python是一門強大而優雅的編程語言,無論你是編程新手還是有經驗的開發者,都能在Python中找到樂趣和挑戰。
Python以其簡潔易懂的語法和豐富的庫而聞名,廣泛應用于數據分析、人工智能、Web開發、自動化腳本等各個領域。
在本章中,我們將介紹Python的歷史與特點、Python的應用領域以及如何安裝和配置Python環境。
通過這部分內容,你將對Python有一個初步的了解,為接下來的學習打下堅實的基礎。
1.1 Python的歷史與特點
1.1.1 Python的歷史
Python是一種由Guido van Rossum于1989年發明的高級編程語言。最初,Guido van Rossum在荷蘭的國家研究所工作,設計Python的初衷是為了創建一種易于閱讀和編寫的編程語言,并且能夠處理當時主流的ABC語言不能勝任的任務。
Python的第一個正式版本0.9.0于1991年發布,這個版本已經包含了“模塊、異常處理、函數以及核心數據類型”等許多現在仍然重要的功能。
1994年,Python 1.0發布,標志著Python正式進入了主流編程語言的行列。隨著社區的發展和需求的變化,Python不斷更新和完善:
- Python 2.0:發布于2000年,引入了垃圾回收機制和更完善的Unicode支持。
- Python 3.0:發布于2008年,對語言進行了大幅度的改進,不完全向后兼容,目的是清理一些歷史遺留問題并提升語言的一致性和可讀性。
目前,Python的最新版本是Python 3.x,已經成為主流的Python版本。
Python 2.x系列已經停止更新,建議新項目和學習都使用Python 3.x。
1.1.2 Python的主要特點
Python因其簡潔、優雅和強大,受到了廣泛的歡迎。以下是Python的主要特點:
- 簡潔明了:Python的語法設計簡潔明了,代碼可讀性強。一個典型的Python程序通常比同樣功能的C/C++/Java代碼更短。
- 易學易用:Python的學習曲線相對平緩,非常適合初學者。它提供了大量的文檔和社區支持,幫助新手快速上手。
- 解釋型語言:Python是一種解釋型語言,代碼在運行時逐行解釋執行,無需編譯。這樣不僅方便調試,還能快速測試和驗證代碼。
- 動態類型:Python是動態類型語言,變量在使用時才確定類型,無需預先聲明。
- 跨平臺:Python是一種跨平臺語言,支持在Windows、macOS、Linux等多個操作系統上運行,只需一次編寫即可在多種環境中使用。
- 豐富的標準庫:Python擁有一個龐大的標準庫,涵蓋了文件I/O、系統調用、網絡編程、Web服務、數據庫接口等各個方面,極大地簡化了開發工作。
- 強大的社區支持:Python擁有一個活躍且龐大的社區,提供了豐富的第三方庫和工具,使開發者可以方便地擴展Python的功能。
我們可以看到Python是一門經過長期發展和完善的語言,具備了許多現代編程語言的優點,并在多個領域得到了廣泛應用。
1.2 Python的應用領域
Python以其簡潔的語法和強大的功能,廣泛應用于各個領域。以下是Python在一些主要應用領域中的典型使用場景和優勢。
1.2.1 Web開發
Python在Web開發領域非常受歡迎,得益于其豐富的框架和庫,這些工具極大地簡化了Web應用的開發過程。
常用框架和工具
- Django:一個功能強大且完備的Web框架,適用于快速開發復雜的大型Web應用。Django提供了諸如ORM(對象關系映射)、身份驗證、模板引擎、URL路由等內置功能,極大地減少了開發工作量。
- Flask:一個輕量級的Web框架,靈活性高,適用于小型項目和原型開發。Flask提供了基本的Web開發功能,并允許開發者根據需要自由選擇和集成第三方庫。
示例代碼
下面是一個使用Flask開發的簡單Web應用示例:
from flask import Flask, render_templateapp = Flask(__name__)@app.route('/')
def home():return "Hello, Flask!"if __name__ == '__main__':app.run(debug=True)
保存以上代碼為app.py,然后在命令行中運行:
python app.py
打開瀏覽器,訪問http://127.0.0.1:5000/,你將看到頁面顯示“Hello, Flask!”。
1.2.2 數據分析
Python在數據分析領域同樣表現出色,擁有大量專門用于數據處理和分析的庫,使得數據分析工作更加高效和便捷。
常用庫和工具
- pandas:一個強大的數據處理和分析庫,提供了高效的數據結構和數據操作功能,尤其適用于結構化數據處理。
- NumPy:一個科學計算庫,提供了支持多維數組和矩陣運算的大量函數。
- Matplotlib:一個繪圖庫,用于創建靜態、動態和交互式可視化圖表。
示例代碼
下面是一個使用pandas和Matplotlib進行數據分析和可視化的示例:
import pandas as pd
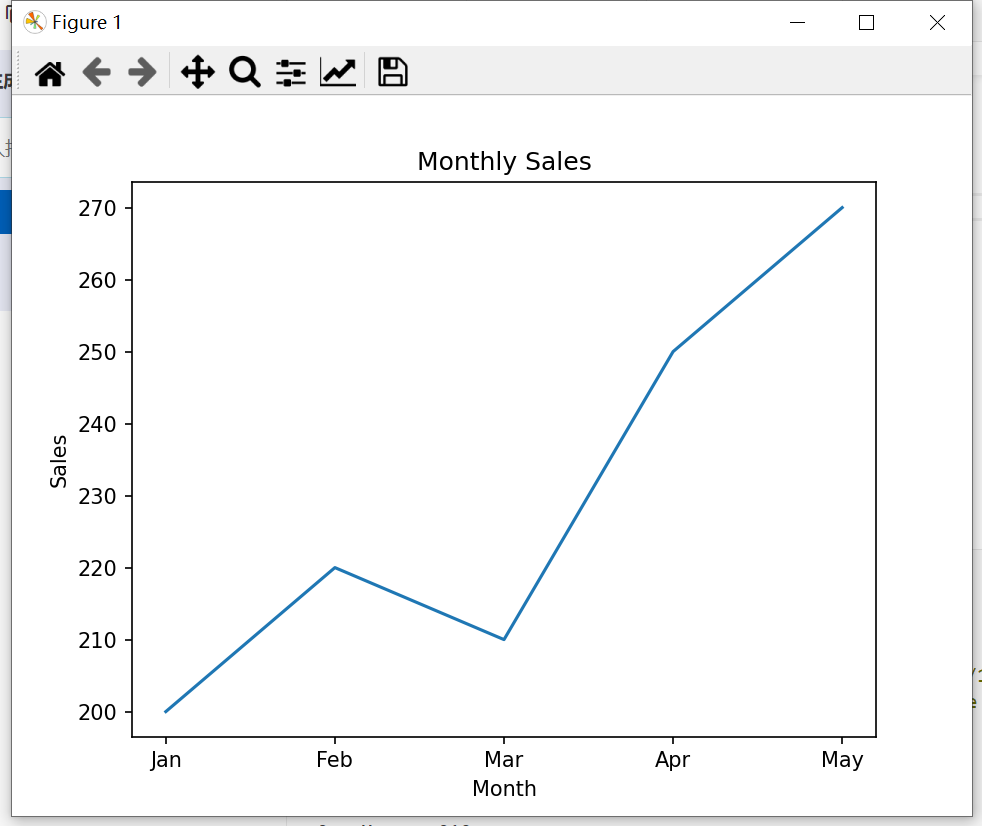
import matplotlib.pyplot as plt# 創建一個簡單的DataFrame
data = {'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May'],'Sales': [200, 220, 210, 250, 270]}
df = pd.DataFrame(data)# 打印數據表
print(df)# 繪制銷售趨勢圖
# 使用月份和銷售數據繪制折線圖
plt.plot(df['Month'], df['Sales'])
# 添加 x 軸標簽
plt.xlabel('Month')
# 添加 y 軸標簽
plt.ylabel('Sales')
# 添加圖表標題
plt.title('Monthly Sales')
# 顯示圖表
plt.show()
運行上述代碼,將生成一個顯示月度銷售趨勢的折線圖。
1.2.3 人工智能與機器學習
Python在人工智能(AI)和機器學習(ML)領域的應用非常廣泛,得益于其豐富的庫和框架,使得開發AI和ML應用變得相對容易。
常用庫和工具
- TensorFlow:一個由Google開發的開源機器學習框架,用于構建和訓練深度學習模型。
- PyTorch:一個由Facebook開發的開源深度學習框架,提供了靈活且易于使用的接口。
- scikit-learn:一個簡單而高效的機器學習庫,包含了大量的分類、回歸、聚類算法,適用于數據挖掘和數據分析。
示例代碼
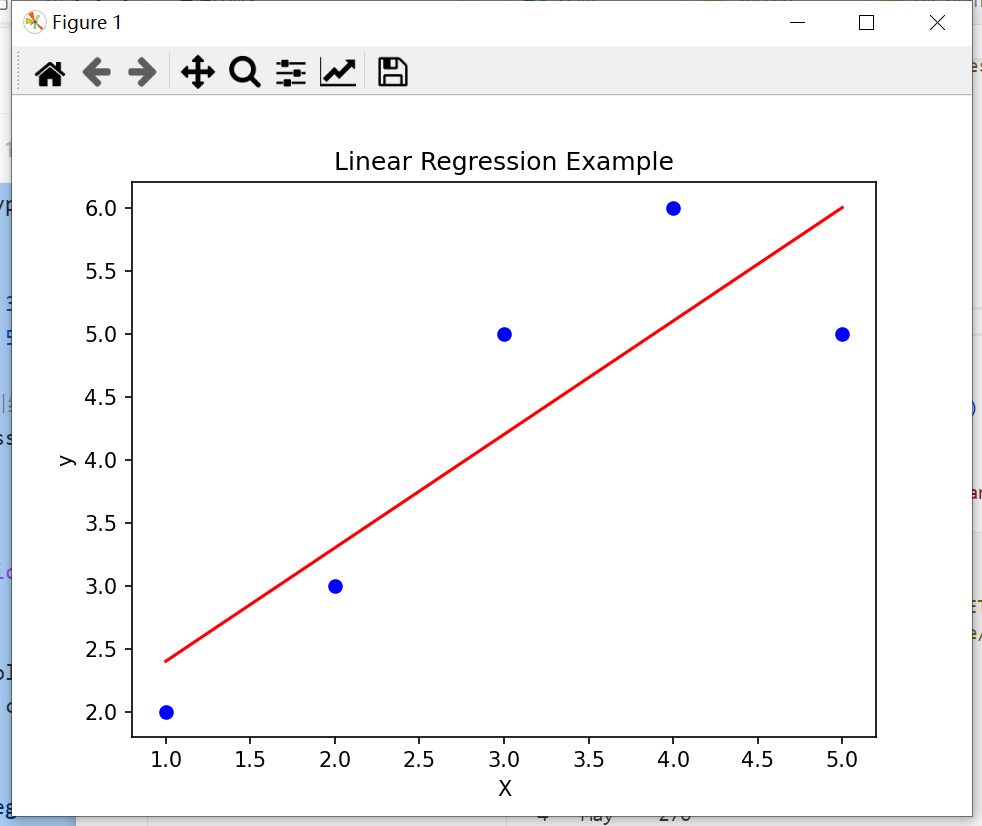
下面是一個使用scikit-learn進行簡單線性回歸的示例:
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt# 生成數據
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # 生成輸入特征X,reshape(-1, 1)將數組轉換成一列
y = np.array([2, 3, 5, 6, 5]) # 生成目標變量y# 創建線性回歸模型并訓練
model = LinearRegression() # 創建線性回歸模型
model.fit(X, y) # 使用輸入特征X和目標變量y訓練模型# 預測
y_pred = model.predict(X) # 使用訓練好的模型預測輸出# 繪制結果
plt.scatter(X, y, color='blue') # 繪制散點圖,用藍色表示
plt.plot(X, y_pred, color='red') # 繪制擬合直線,用紅色表示
plt.xlabel('X') # 設置x軸標簽
plt.ylabel('y') # 設置y軸標簽
plt.title('Linear Regression Example') # 設置圖表標題
plt.show() # 顯示圖表運行上述代碼,將生成一個展示線性回歸結果的散點圖和回歸線。
1.2.4 自動化腳本
Python在編寫自動化腳本方面也非常有優勢,其簡潔的語法和強大的庫支持,使得開發自動化腳本變得簡單而高效。
常用庫和工具
- os:提供了豐富的操作系統功能,如文件和目錄操作。
- shutil:提供了高級的文件操作功能,如復制和移動文件。
- requests:用于發送HTTP請求,適用于Web抓取和API調用。
示例代碼
下面是一個使用os和shutil庫進行文件整理的自動化腳本示例:
import os
import shutil# 定義源目錄和目標目錄
source_dir = 'C:/Users/Andy/Downloads'
target_dir = 'C:/Users/Andy/Documents/Sorted'# 創建目標目錄
if not os.path.exists(target_dir):os.makedirs(target_dir)# 遍歷源目錄中的文件
for filename in os.listdir(source_dir):file_path = os.path.join(source_dir, filename)# 判斷是否為文件if os.path.isfile(file_path):# 移動文件到目標目錄shutil.move(file_path, target_dir)print(f'Moved: {filename}')
運行該腳本后,下載目錄中的所有文件將被移動到指定的目標目錄中。
1.2.5 其他應用領域
除了上述領域,Python還在許多其他領域有廣泛的應用,包括但不限于:
- 網絡爬蟲:通過編寫爬蟲程序抓取網絡數據,常用庫有BeautifulSoup、Scrapy等。
- 游戲開發:使用Pygame等庫進行簡單的游戲開發。
- 系統管理:編寫腳本實現系統管理和運維任務。
Python的多功能性和廣泛的應用領域,使其成為許多開發者和工程師的首選編程語言。
在接下來的章節中,我們將詳細介紹如何安裝和配置Python環境,幫助你快速入門Python編程。
1.3 如何安裝Python
在開始編寫Python程序之前,我們需要先安裝Python。在本節中,我們將介紹如何在不同操作系統上安裝Python,包括Windows、macOS和Linux。
1.3.1 Windows系統安裝
- 下載Python安裝包:
- 訪問Python官網。
- 點擊“Downloads”菜單,根據你的操作系統選擇“Download for Windows”。
- 下載最新的Python安裝包。
- 運行安裝包:
- 雙擊下載的安裝包以啟動安裝程序。
- 在安裝界面,勾選“Add Python to PATH”選項,這將自動配置環境變量,方便在命令行中使用Python。
- 點擊“Install Now”進行安裝。
- 驗證安裝:
- 安裝完成后,打開命令提示符(按
Win + R,輸入cmd,按回車)。 - 在命令提示符中輸入以下命令,驗證Python是否安裝成功:
python --version
如果顯示Python的版本號,說明安裝成功。
1.3.2 macOS系統安裝
macOS通常預裝了Python,但為了使用最新版本的Python,建議手動安裝。
- 使用Homebrew安裝Python:
- 如果尚未安裝Homebrew,先打開終端(按
Cmd + Space,輸入Terminal,按回車),然后輸入以下命令安裝Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 安裝Homebrew后,使用以下命令安裝Python:
brew install python
- 驗證安裝:
- 在終端中輸入以下命令,驗證Python是否安裝成功:
python3 --version
如果顯示Python的版本號,說明安裝成功。
1.3.3 Linux系統安裝
大多數Linux發行版都預裝了Python,但為了使用最新版本,可以手動安裝。
- 更新包管理器:
- 打開終端,輸入以下命令更新包管理器:
sudo apt update
- 安裝Python:
- 使用以下命令安裝Python:
sudo apt install python3
- 驗證安裝:
- 在終端中輸入以下命令,驗證Python是否安裝成功:
python3 --version
如果顯示Python的版本號,說明安裝成功。
通過以上步驟,你已經成功在Windows、macOS或Linux系統上安裝了Python。接下來,我們將介紹如何配置Python環境,以便更高效地開發Python應用。
1.4 Python環境配置
在安裝了Python之后,我們還需要進行一些配置,以便更高效地進行開發。
這些配置包括Python版本管理、虛擬環境管理以及Anaconda的安裝與配置。
本節將詳細介紹這些概念及其作用,并提供具體的操作步驟。
1.4.1 Python版本管理(pyenv)
1.4.1.1 版本管理的概念和作用
在開發過程中,可能需要使用不同版本的Python來運行不同的項目。例如,一個項目可能需要Python 3.8,而另一個項目可能需要Python 3.9。
這時,管理和切換不同版本的Python就變得非常重要。pyenv是一個用于管理多個Python版本的工具,允許用戶輕松安裝和切換不同版本的Python。
1.4.1.2 安裝和使用pyenv
- 安裝pyenv:
- 打開終端,輸入以下命令安裝
pyenv:
curl https://pyenv.run | bash
- 按照提示將以下內容添加到你的shell配置文件(如
~/.bashrc或~/.zshrc):
export PATH="$HOME/.pyenv/bin:$PATH"
eval "$(pyenv init --path)"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
- 重啟終端:
- 重啟終端或運行以下命令以應用配置:
source ~/.bashrc # 或者 source ~/.zshrc
- 安裝Python版本:
- 使用
pyenv安裝所需的Python版本,例如安裝Python 3.9.7:
pyenv install 3.9.7
- 設置全局或局部Python版本:
- 設置全局默認Python版本:
pyenv global 3.9.7
- 設置局部Python版本(在項目目錄中):
pyenv local 3.8.10
- 驗證安裝:
- 輸入以下命令,驗證當前使用的Python版本:
python --version
1.4.2 虛擬環境管理(virtualenv, venv)
1.4.2.1 虛擬環境的概念和作用
虛擬環境是一種隔離的Python環境,每個虛擬環境都有獨立的Python解釋器和包管理工具。
使用虛擬環境可以避免不同項目之間的包沖突,并確保項目依賴的穩定性。
常用的虛擬環境管理工具有virtualenv和venv。
1.4.2.2 使用venv創建虛擬環境
venv是Python 3內置的虛擬環境管理工具,使用簡單方便。
- 創建虛擬環境:
- 打開終端或命令提示符,輸入以下命令創建一個名為
myenv的虛擬環境:
python3 -m venv myenv
- 激活虛擬環境:
- 激活虛擬環境:
- Windows:
myenv\Scripts\activate
- macOS/Linux:
source myenv/bin/activate
- 激活后,命令行提示符前會顯示虛擬環境的名稱,如
(myenv)。
- 安裝包:
- 在激活的虛擬環境中使用
pip安裝所需的包,例如安裝requests庫:
pip install requests
- 退出虛擬環境:
- 使用以下命令退出虛擬環境:
deactivate
1.4.2.3 使用virtualenv創建虛擬環境
virtualenv是一個獨立于Python標準庫的虛擬環境管理工具,適用于需要更多功能和兼容性的情況。
- 安裝virtualenv:
- 如果沒有安裝
virtualenv,可以使用pip進行安裝:
pip install virtualenv
- 創建虛擬環境:
- 使用
virtualenv創建虛擬環境:
virtualenv myenv
- 激活虛擬環境:
- 激活虛擬環境:
- Windows:
myenv\Scripts\activate
- macOS/Linux:
source myenv/bin/activate
- 退出虛擬環境:
- 使用以下命令退出虛擬環境:
deactivate
1.4.3 Anaconda的安裝與配置
1.4.3.1 Anaconda的概念和作用
Anaconda是一個開源的Python發行版,專為科學計算、數據分析和機器學習而設計。
它包含了許多常用的科學計算庫和數據處理工具,并提供了一個功能強大的包管理和虛擬環境管理工具conda。
Anaconda極大地簡化了科學計算和數據分析的環境配置工作。
1.4.3.2 安裝Anaconda
- 下載Anaconda安裝包:
- 訪問Anaconda官網, 國內用戶推薦訪問清華源下載和安裝。anaconda | 鏡像站使用幫助 | 清華大學開源軟件鏡像站 | Tsinghua Open Source Mirror
- 根據你的操作系統選擇并下載Anaconda安裝包。
- 運行安裝包:
- 雙擊下載的安裝包,按照安裝向導的指示完成安裝。
- 驗證安裝:
- 打開終端或命令提示符,輸入以下命令驗證Anaconda是否安裝成功:
conda --version
1.4.3.3 使用conda管理虛擬環境和包
- 創建虛擬環境:
- 使用
conda創建一個名為myenv的虛擬環境,并指定Python版本:
conda create -n myenv python=3.9
- 激活虛擬環境:
- 激活虛擬環境:
conda activate myenv
- 安裝包:
- 在激活的虛擬環境中使用
conda安裝所需的包,例如安裝numpy庫:
conda install numpy
- 退出虛擬環境:
- 使用以下命令退出虛擬環境:
conda deactivate
- 管理包和環境:
- 列出已安裝的包:
conda list
- 列出所有虛擬環境:
conda env list
通過以上步驟,你已經學會了如何使用Python版本管理工具、虛擬環境和Anaconda來配置和管理你的Python開發環境。
這些工具和技術將幫助你更高效地進行Python開發,并確保項目之間的依賴不互相干擾。
接下來,我們將通過IDE開始編寫第一個Python程序。
1.5 IDE選擇和配置
一個好的集成開發環境(IDE)可以極大地提升開發效率和編程體驗。IDE通常提供代碼編輯、調試、運行和版本控制等功能,使開發者可以更專注于編碼本身。
在本節中,我們將介紹幾種常用的Python IDE,包括PyCharm、VS Code和Jupyter Notebook,并講解它們的安裝與基本配置。
1.5.1 PyCharm安裝與基本配置

PyCharm是由JetBrains開發的一款功能強大的Python IDE,特別適合大型項目和復雜的開發需求。它提供了智能代碼補全、代碼重構、調試工具和版本控制集成等功能。
1.5.1.1 安裝PyCharm
- 下載PyCharm:
- 訪問PyCharm官網。
- 根據你的操作系統下載社區版(Community)或專業版(Professional)。
- 安裝PyCharm:
- 雙擊下載的安裝包,按照安裝向導的指示完成安裝。
1.5.1.2 配置Python解釋器
- 創建新項目:
- 打開PyCharm,選擇“Create New Project”。
- 輸入項目名稱和路徑。
- 選擇Python解釋器:
- 在“New Project”窗口,選擇“Base Interpreter”。
- 選擇系統Python解釋器或虛擬環境。
- 點擊“Create”創建項目。
1.5.1.3 基本配置和使用
- 安裝插件:
- 打開“File -> Settings -> Plugins”。
- 搜索并安裝需要的插件,如Markdown支持插件。
- 創建并運行Python文件:
- 右鍵點擊項目目錄,選擇“New -> Python File”,輸入文件名。
- 編寫Python代碼,例如:
print("Hello, PyCharm!")
- 右鍵點擊文件,選擇“Run ‘filename’”運行代碼。

1.5.2 VS Code安裝與基本配置
VS Code(Visual Studio Code)是由微軟開發的一款輕量級且功能強大的代碼編輯器,支持多種編程語言。它通過擴展可以實現豐富的功能,非常適合Python開發。
1.5.2.1 安裝VS Code
- 下載VS Code:
- 訪問VS Code官網。
- 根據你的操作系統下載安裝包。
- 安裝VS Code:
- 雙擊下載的安裝包,按照安裝向導的指示完成安裝。
1.5.2.2 安裝Python擴展
- 打開VS Code:
- 啟動VS Code。
- 安裝Python擴展:
- 點擊左側活動欄中的“Extensions”圖標。
- 在搜索框中輸入“Python”,找到由Microsoft發布的“Python”擴展并安裝。
1.5.2.3 配置Python解釋器
- 打開命令面板:
- 按
Ctrl+Shift+P(Windows/Linux)或Cmd+Shift+P(macOS),打開命令面板。
- 選擇Python解釋器:
- 在命令面板中輸入“Python: Select Interpreter”,選擇項目使用的Python解釋器。
1.5.2.4 創建并運行Python文件
- 創建新文件:
- 點擊左側活動欄中的“Explorer”圖標,點擊“New File”圖標,創建一個新的Python文件(如
hello.py)。
- 編寫并運行代碼:
- 在新文件中輸入以下代碼:
print("Hello, VS Code!")
- 保存文件,右鍵點擊文件選擇“Run Python File in Terminal”運行代碼。
1.5.3 其他常用IDE介紹
1.5.3.1 Jupyter Notebook
Jupyter Notebook是一款廣泛用于數據分析和科學計算的交互式開發工具。它允許用戶在瀏覽器中編寫和運行代碼,并可以實時查看代碼的輸出結果,非常適合數據探索和可視化。
- 安裝Jupyter Notebook:
- 使用pip安裝:
pip install notebook
- 或者使用conda安裝:
conda install -c conda-forge notebook
- 啟動Jupyter Notebook:
- 在命令行中輸入以下命令啟動Notebook服務器:
jupyter notebook
- 瀏覽器會自動打開Jupyter Notebook的主頁。
- 創建和運行Notebook:
- 在Jupyter主頁,點擊“New -> Python 3”創建一個新的Notebook。
- 在單元格中輸入以下代碼并運行:
print("Hello, Jupyter Notebook!")
- 按
Shift+Enter運行代碼單元格。
1.5.3.2 其他IDE
- Spyder:Anaconda發行版中自帶的IDE,專為數據科學和機器學習設計,集成了許多科學計算庫。
- Sublime Text:一款輕量級代碼編輯器,支持多種編程語言,通過安裝插件可以增強Python支持。
- Atom:由GitHub開發的開源編輯器,通過插件可以支持多種編程語言和功能擴展。
通過上述介紹和配置,你可以選擇和配置適合自己的IDE,提升Python開發的效率和體驗。
在接下來的章節中,我們將開始編寫第一個Python程序,并逐步學習Python的基礎語法和功能。
第2章:Python基礎語法
在本章中,我們將深入學習Python編程語言的基礎語法。這些基礎知識是學習和掌握Python編程的第一步。
通過本章的學習,您將學會編寫簡單的Python程序,理解并使用Python的基本數據類型,掌握變量和常量的定義與使用,了解常見的運算符及其用法,并能編寫包含控制結構的Python程序。
此外,您還將學習如何定義和調用函數,為以后編寫更復雜的Python程序奠定基礎。
2.1 第一個Python程序
編寫和運行第一個Python程序是每個初學者邁向編程世界的第一步。
在這一節中,我們將指導您如何編寫一個稍微復雜的Python程序,該程序將包含變量、數據類型、運算符、控制結構和函數等語法元素。
編寫和運行第一個Python程序
編寫第一個Python程序非常簡單。首先,打開一個文本編輯器(如VS Code、Sublime Text或PyCharm),然后輸入以下代碼:
# 定義一個函數來計算兩個數字的加減乘除并判斷它們的大小關系
def calculate_and_compare(a, b):# 計算和sum_result = a + b# 計算差diff_result = a - b# 計算積prod_result = a * b# 計算商if b != 0:div_result = a / belse:div_result = None# 打印計算結果print(f"{a} + {b} = {sum_result}")print(f"{a} - {b} = {diff_result}")print(f"{a} * {b} = {prod_result}")if div_result is not None:print(f"{a} / {b} = {div_result}")else:print("除數不能為零")# 比較兩個數字的大小if a > b:print(f"{a} 大于 {b}")elif a < b:print(f"{a} 小于 {b}")else:print(f"{a} 等于 {b}")# 從用戶獲取輸入
try:num1 = float(input("請輸入第一個數字: "))num2 = float(input("請輸入第二個數字: "))# 調用函數進行計算和比較calculate_and_compare(num1, num2)
except ValueError:print("請輸入有效的數字")
將文件保存為calculator.py。接下來,打開命令行或終端,導航到保存該文件的目錄,輸入以下命令運行程序:
python calculator.py
如果一切順利,程序將提示您輸入兩個數字,并輸出它們的和、差、積、商,并判斷它們的大小關系。示例如下:
請輸入第一個數字: 8
請輸入第二個數字: 4
8.0 + 4.0 = 12.0
8.0 - 4.0 = 4.0
8.0 * 4.0 = 32.0
8.0 / 4.0 = 2.0
8.0 大于 4.0
通過這個程序,您可以看到Python中如何定義變量和函數,使用不同的數據類型(浮點數),進行各種運算(加、減、乘、除),以及使用控制結構(if-else語句)來進行條件判斷。
這個程序展示了Python編程的基本要素,為后續章節的深入學習打下了基礎。
2.2 數據類型
Python支持多種數據類型,每種類型都有其獨特的特性和用途。
在這一節中,我們將詳細介紹Python中的幾種基本數據類型,包括數字、字符串、列表、元組、字典和集合,并對每種類型的常見操作進行說明。
2.2.1 數字(整數、浮點數、復數)
數字類型是Python中最基本的數據類型之一。Python支持三種不同的數值類型:整數、浮點數和復數。
整數(int)
整數是沒有小數部分的數字,可以是正數、負數或零。
# 整數
a = 10
b = -5
c = 0
print(a, type(a)) # 輸出: 10 <class 'int'>
print(b, type(b)) # 輸出: -5 <class 'int'>
print(c, type(c)) # 輸出: 0 <class 'int'>
常見操作:
# 加法
print(a + b) # 輸出: 5# 減法
print(a - b) # 輸出: 15# 乘法
print(a * b) # 輸出: -50# 除法
print(a / 2) # 輸出: 5.0# 整除
print(a // 3) # 輸出: 3# 取余
print(a % 3) # 輸出: 1# 冪運算
print(a ** 2) # 輸出: 100
浮點數(float)
浮點數是帶有小數部分的數字。
# 浮點數
d = 3.14
e = -2.71
print(d, type(d)) # 輸出: 3.14 <class 'float'>
print(e, type(e)) # 輸出: -2.71 <class 'float'>
常見操作:
# 加法
print(d + e) # 輸出: 0.43000000000000016# 減法
print(d - e) # 輸出: 5.85# 乘法
print(d * e) # 輸出: -8.5094# 除法
print(d / 2) # 輸出: 1.57
復數(complex)
復數是帶有實部和虛部的數字。
# 復數
f = 1 + 2j
g = 3 - 4j
print(f, type(f)) # 輸出: (1+2j) <class 'complex'>
print(g, type(g)) # 輸出: (3-4j) <class 'complex'>
常見操作:
# 加法
print(f + g) # 輸出: (4-2j)# 減法
print(f - g) # 輸出: (-2+6j)# 乘法
print(f * g) # 輸出: (11+2j)# 除法
print(f / g) # 輸出: (-0.2+0.4j)
2.2.2 字符串
字符串用于表示文本,是一系列字符的集合。可以使用單引號或雙引號定義字符串。字符串是不可變的,這意味著一旦創建就不能更改。
# 使用單引號
str1 = 'Hello, Python'
print(str1, type(str1)) # 輸出: Hello, Python <class 'str'># 使用雙引號
str2 = "Hello, World"
print(str2, type(str2)) # 輸出: Hello, World <class 'str'>
常見操作:
# 拼接字符串
greeting = str1 + " " + str2
print(greeting) # 輸出: Hello, Python Hello, World# 字符串切片
print(greeting[0:5]) # 輸出: Hello# 查找子串
print("Python" in greeting) # 輸出: True# 獲取長度
print(len(greeting)) # 輸出: 26# 轉換大小寫
print(str1.upper()) # 輸出: HELLO, PYTHON
print(str2.lower()) # 輸出: hello, world# 格式化字符串
name = "Alice"
welcome_message = f"Hello, {name}!"
print(welcome_message) # 輸出: Hello, Alice!
2.2.3 列表
列表是一種有序的可變序列,可以包含不同類型的元素。列表使用方括號定義,元素之間用逗號分隔。
# 定義一個列表
my_list = [1, 2, 3, 'Python', 3.14]
print(my_list, type(my_list)) # 輸出: [1, 2, 3, 'Python', 3.14] <class 'list'>
常見操作:
# 訪問列表元素
print(my_list[0]) # 輸出: 1# 修改列表元素
my_list[1] = 'Changed'
print(my_list) # 輸出: [1, 'Changed', 3, 'Python', 3.14]# 添加新元素
my_list.append('New Element')
print(my_list) # 輸出: [1, 'Changed', 3, 'Python', 3.14, 'New Element']# 刪除元素
my_list.remove('Python')
print(my_list) # 輸出: [1, 'Changed', 3, 3.14, 'New Element']# 獲取長度
print(len(my_list)) # 輸出: 5# 列表切片
print(my_list[1:4]) # 輸出: ['Changed', 3, 3.14]
2.2.4 元組
元組與列表類似,但元組是不可變的。一旦定義,元組中的元素不能修改。元組使用圓括號定義,元素之間用逗號分隔。
# 定義一個元組
my_tuple = (1, 2, 3, 'Python', 3.14)
print(my_tuple, type(my_tuple)) # 輸出: (1, 2, 3, 'Python', 3.14) <class 'tuple'>
常見操作:
# 訪問元組元素
print(my_tuple[0]) # 輸出: 1# 元組切片
print(my_tuple[1:4]) # 輸出: (2, 3, 'Python')# 獲取長度
print(len(my_tuple)) # 輸出: 5# 元組解包
a, b, c, d, e = my_tuple
print(a, b, c, d, e) # 輸出: 1 2 3 Python 3.14# 元組的不可變特性
# my_tuple[1] = 'Changed' # 這行代碼會引發錯誤,因為元組不允許修改
2.2.5 字典
字典是一種鍵值對的集合,使用大括號定義。每個鍵值對由鍵和對應的值組成。鍵是唯一的,通常是字符串或數字,而值可以是任何數據類型。
# 定義一個字典
my_dict = {'name': 'Python', 'version': 3.9}
print(my_dict, type(my_dict)) # 輸出: {'name': 'Python', 'version': 3.9} <class 'dict'>
常見操作:
# 訪問字典元素
print(my_dict['name']) # 輸出: Python# 修改字典元素
my_dict['version'] = 3.10
print(my_dict) # 輸出: {'name': 'Python', 'version': 3.10}# 添加新元素
my_dict['creator'] = 'Guido van Rossum'
print(my_dict) # 輸出: {'name': 'Python', 'version': 3.10, 'creator': 'Guido van Rossum'}# 刪除元素
del my_dict['version']
print(my_dict) # 輸出: {'name': 'Python', 'creator': 'Guido van Rossum'}# 獲取所有鍵
print(my_dict.keys()) # 輸出: dict_keys(['name', 'creator'])# 獲取所有值
print(my_dict.values()) # 輸出: dict_values(['Python', 'Guido van Rossum'])# 獲取所有鍵值對
print(my_dict.items()) # 輸出: dict_items([('name', 'Python'), ('creator', 'Guido van Rossum')])
2.2.6 集合
集合是一個無序的不重復元素序列,使用大括號或set()函數創建。集合用于去重和集合運算。
# 定義一個集合
my_set = {1, 2, 3, 4, 5}
print(my_set, type(my_set)) # 輸出: {1, 2, 3, 4, 5} <class 'set'># 使用set()函數定義集合
another_set = set([3, 4, 5, 6, 7])
print(another_set, type(another_set)) # 輸出: {3, 4, 5, 6, 7} <class 'set'>
常見操作:
# 添加新元素
my_set.add(6)
print(my_set) # 輸出: {1, 2, 3, 4, 5, 6}# 集合的去重特性
my_set.add(3)
print(my_set) # 輸出: {1, 2, 3, 4, 5, 6}# 刪除元素
my_set.remove(4)
print(my_set) # 輸出: {1, 2, 3, 5, 6}# 集合運算
print(my_set & another_set) # 交集: {3, 5, 6}
print(my_set | another_set) # 并集: {1, 2, 3, 5, 6, 7}
print(my_set - another_set) # 差集: {1, 2}
print(my_set ^ another_set) # 對稱差集: {1, 2, 7}
通過學習這些基本數據類型及其常見操作,您將能夠處理各種不同類型的數據,并為后續的編程打下堅實的基礎。
2.3 變量與常量
在編程中,變量和常量是兩個重要的概念。
變量用于存儲可以改變的數據,而常量用于存儲在程序運行期間不改變的數據。
在這一節中,我們將介紹變量和常量的定義與使用。
2.3.1 變量的定義與使用
變量是一個用于存儲數據的容器。在Python中,變量不需要顯式聲明,直接賦值即可創建變量。
定義變量
定義變量時,只需要將變量名賦值給一個數據即可:
# 定義變量
x = 10
y = 3.14
name = "Alice"
is_active = True# 輸出變量的值和類型
print(x, type(x)) # 輸出: 10 <class 'int'>
print(y, type(y)) # 輸出: 3.14 <class 'float'>
print(name, type(name)) # 輸出: Alice <class 'str'>
print(is_active, type(is_active)) # 輸出: True <class 'bool'>
使用變量
定義變量后,可以在程序的不同部分使用這些變量。變量可以參與運算、傳遞給函數、用于條件判斷等。
# 變量參與運算
result = x + y
print(result) # 輸出: 13.14# 變量傳遞給函數
def greet(person):return f"Hello, {person}!"message = greet(name)
print(message) # 輸出: Hello, Alice!# 變量用于條件判斷
if is_active:print("The user is active.") # 輸出: The user is active.
else:print("The user is not active.")
變量命名規則
在命名變量時,需要遵守以下規則:
- 變量名必須以字母或下劃線開頭。
- 變量名只能包含字母、數字和下劃線。
- 變量名區分大小寫(例如,
myVar和myvar是不同的變量)。 - 變量名不要使用Python的保留字(如
and、if、while等)。
# 合法的變量名
my_var = 10
_my_var = 20
myVar2 = 30# 非法的變量名(會引發語法錯誤)
# 2myVar = 40
# my-var = 50
# my var = 60
2.3.2 常量的定義與約定
常量用于存儲在程序運行期間不改變的數據。在Python中,沒有專門的語法定義常量,通常使用全大寫字母的變量名表示常量,以便區分它們和普通變量。
定義常量
在Python中,常量通常在模塊的頂部定義,并使用全大寫字母命名:
# 定義常量
PI = 3.14159
GRAVITY = 9.81
MAX_CONNECTIONS = 100# 輸出常量的值
print(PI) # 輸出: 3.14159
print(GRAVITY) # 輸出: 9.81
print(MAX_CONNECTIONS) # 輸出: 100
使用常量
常量的使用方式與變量相同,但在程序中不應修改常量的值。
# 使用常量計算圓的面積
radius = 5
area = PI * (radius ** 2)
print(f"The area of the circle is: {area}") # 輸出: The area of the circle is: 78.53975# 使用常量進行條件判斷
if MAX_CONNECTIONS > 50:print("The server can handle many connections.") # 輸出: The server can handle many connections.
else:print("The server can handle only a few connections.")
常量命名約定
雖然Python沒有嚴格要求,但使用全大寫字母命名常量是一個廣泛接受的約定。這種約定有助于提高代碼的可讀性,讓其他開發者能夠一目了然地識別出哪些值是常量。
# 合理的常量命名
SPEED_OF_LIGHT = 299792458 # 米每秒
PLANCK_CONSTANT = 6.62607015e-34 # 焦耳秒# 不推薦的常量命名(不遵循約定)
# speed_of_light = 299792458
# planckConstant = 6.62607015e-34
通過學習變量和常量的定義與使用,您將能夠更有效地管理程序中的數據,編寫更清晰、更易維護的代碼。
2.4 運算符
運算符是編程語言中用于執行各種操作的符號。
Python支持多種類型的運算符,包括算術運算符、比較運算符、邏輯運算符、賦值運算符和位運算符。
在這一節中,我們將詳細介紹這些運算符的用法及其示例。
2.4.1 算術運算符
算術運算符用于執行基本的數學運算,如加法、減法、乘法、除法等。Python中的算術運算符如下:
| 運算符 | 描述 | 示例 |
|---|---|---|
+ | 加法 | a + b |
- | 減法 | a - b |
* | 乘法 | a * b |
/ | 除法 | a / b |
// | 整除 | a // b |
% | 取余 | a % b |
** | 冪運算 | a ** b |
示例:
a = 10
b = 3print(a + b) # 輸出: 13
print(a - b) # 輸出: 7
print(a * b) # 輸出: 30
print(a / b) # 輸出: 3.3333333333333335
print(a // b) # 輸出: 3
print(a % b) # 輸出: 1
print(a ** b) # 輸出: 1000
2.4.2 比較運算符
比較運算符用于比較兩個值,并返回布爾值(True 或 False)。Python中的比較運算符如下:
| 運算符 | 描述 | 示例 |
|---|---|---|
== | 等于 | a == b |
!= | 不等于 | a != b |
> | 大于 | a > b |
< | 小于 | a < b |
>= | 大于或等于 | a >= b |
<= | 小于或等于 | a <= b |
示例:
a = 10
b = 3print(a == b) # 輸出: False
print(a != b) # 輸出: True
print(a > b) # 輸出: True
print(a < b) # 輸出: False
print(a >= b) # 輸出: True
print(a <= b) # 輸出: False
2.4.3 邏輯運算符
邏輯運算符用于組合布爾值,并返回布爾值。Python中的邏輯運算符如下:
| 運算符 | 描述 | 示例 |
|---|---|---|
and | 邏輯與 | a and b |
or | 邏輯或 | a or b |
not | 邏輯非 | not a |
示例:
a = True
b = Falseprint(a and b) # 輸出: False
print(a or b) # 輸出: True
print(not a) # 輸出: False
2.4.4 賦值運算符
賦值運算符用于將右邊的值賦給左邊的變量。Python中的賦值運算符如下:
| 運算符 | 描述 | 示例 |
|---|---|---|
= | 簡單賦值 | a = b |
+= | 加法賦值 | a += b |
-= | 減法賦值 | a -= b |
*= | 乘法賦值 | a *= b |
/= | 除法賦值 | a /= b |
//= | 整除賦值 | a //= b |
%= | 取余賦值 | a %= b |
**= | 冪賦值 | a **= b |
示例:
a = 10
b = 3a += b # 等價于 a = a + b
print(a) # 輸出: 13a -= b # 等價于 a = a - b
print(a) # 輸出: 10a *= b # 等價于 a = a * b
print(a) # 輸出: 30a /= b # 等價于 a = a / b
print(a) # 輸出: 10.0a //= b # 等價于 a = a // b
print(a) # 輸出: 3.0a %= b # 等價于 a = a % b
print(a) # 輸出: 0.0a **= b # 等價于 a = a ** b
print(a) # 輸出: 0.0
2.4.5 位運算符
位運算符用于對整數的二進制位進行操作。Python中的位運算符如下:
| 運算符 | 描述 | 示例 |
|---|---|---|
& | 按位與 | a & b |
| | 按位或 | a | b |
^ | 按位異或 | a ^ b |
~ | 按位取反 | ~a |
<< | 左移 | a << b |
>> | 右移 | a >> b |
示例:
a = 10 # 二進制: 1010
b = 4 # 二進制: 0100print(a & b) # 輸出: 0 (二進制: 0000)
print(a | b) # 輸出: 14 (二進制: 1110)
print(a ^ b) # 輸出: 14 (二進制: 1110)
print(~a) # 輸出: -11 (二進制: -1011)print(a << 2) # 輸出: 40 (二進制: 101000)
print(a >> 2) # 輸出: 2 (二進制: 0010)
2.4.6 運算符優先級
當一個表達式中出現多個操作符時,求值的順序依賴于優先級規則。Python遵守數學操作符的傳統規則。
| 運算符 | 描述 |
|---|---|
| ** | 指數(最高優先級) |
| ~、+、- | 按位翻轉,一元加號和減號(最后兩個的方法名為+@和-@) |
| *、/、%、// | 乘、除、取模和取整除 |
| +、- | 加法、減法 |
| >>、<< | 右移、左移運算符 |
| & | 位與 |
| ^、| | 位運算符 |
| <=、<、>、>= | 比較運算符 |
| <> == != | 等于運算符 |
| = %= /= //= -= += *= **= | 賦值運算符 |
| is is not | 身份運算符 |
| in in not | 成員運算符 |
| not or and | 邏輯運算符 |
以上常用的運算符優先級從上到下依次降低,運算優先級高的先計算,低的后計算。有括號時會優先運算括號中的內容,所以我們可以利用括號來打破運算優先級的限制。
通過學習這些運算符及其用法,您將能夠執行各種基本和復雜的操作,編寫功能更強大、更靈活的Python程序。
2.5 控制結構
控制結構用于控制程序的執行流程。Python中最常用的控制結構包括條件語句和循環語句。在本節中,我們將詳細介紹條件語句的用法。
2.5.1 條件語句(if, elif, else)
條件語句用于根據一個或多個條件的真假,來執行不同的代碼塊。Python中的條件語句包括if、elif(else if的縮寫)和else。
if 語句
if語句用于判斷一個條件是否為真,如果為真,則執行相應的代碼塊。
# if 語句示例
x = 10if x > 5:print("x is greater than 5") # 輸出: x is greater than 5
if…else 語句
if...else語句用于在條件為假時執行另一個代碼塊。
# if...else 語句示例
x = 3if x > 5:print("x is greater than 5")
else:print("x is less than or equal to 5") # 輸出: x is less than or equal to 5
if…elif…else 語句
if...elif...else語句用于檢查多個條件,并根據第一個為真的條件執行相應的代碼塊。如果所有條件都為假,則執行else代碼塊。
# if...elif...else 語句示例
x = 7if x > 10:print("x is greater than 10")
elif x > 5:print("x is greater than 5 but less than or equal to 10") # 輸出: x is greater than 5 but less than or equal to 10
else:print("x is 5 or less")
嵌套條件語句
條件語句可以嵌套使用,即在一個條件語句內部再包含另一個條件語句。
# 嵌套條件語句示例
x = 15if x > 10:print("x is greater than 10") # 輸出: x is greater than 10if x > 20:print("x is also greater than 20")else:print("x is not greater than 20") # 輸出: x is not greater than 20
else:print("x is 10 or less")
條件表達式(三元運算符)
Python還支持使用條件表達式(又稱三元運算符)來簡化條件語句。條件表達式允許在一行中編寫簡潔的條件判斷。
# 條件表達式示例
x = 8
result = "greater than 5" if x > 5 else "less than or equal to 5"
print(result) # 輸出: greater than 5
通過條件語句,程序可以根據不同的條件執行不同的代碼塊,從而實現復雜的邏輯控制。
2.5.2 循環語句(for, while)
循環語句用于重復執行某段代碼,直到滿足某個條件為止。Python中主要有兩種循環語句:for循環和while循環。
for 循環
for循環用于遍歷序列(如列表、元組、字符串)或其他可迭代對象。每次循環時,for語句會將序列中的下一個元素賦值給循環變量,并執行循環體中的代碼。
# for 循環遍歷列表
numbers = [1, 2, 3, 4, 5]for num in numbers:print(num)
# 輸出:
# 1
# 2
# 3
# 4
# 5
使用range()函數生成一系列數字,并使用for循環進行遍歷:
# 使用 range() 生成數字序列
for i in range(5):print(i)
# 輸出:
# 0
# 1
# 2
# 3
# 4# 指定起始和結束點
for i in range(2, 7):print(i)
# 輸出:
# 2
# 3
# 4
# 5
# 6# 指定步長
for i in range(1, 10, 2):print(i)
# 輸出:
# 1
# 3
# 5
# 7
# 9
while 循環
while循環在條件為真時反復執行循環體中的代碼。當條件變為假時,循環終止。
# while 循環示例
count = 0while count < 5:print(count)count += 1
# 輸出:
# 0
# 1
# 2
# 3
# 4
嵌套循環
循環可以嵌套使用,即在一個循環體內再包含一個循環。
# 嵌套 for 循環
for i in range(3):for j in range(2):print(f"i={i}, j={j}")
# 輸出:
# i=0, j=0
# i=0, j=1
# i=1, j=0
# i=1, j=1
# i=2, j=0
# i=2, j=1
# 嵌套 while 循環
i = 0
while i < 3:j = 0while j < 2:print(f"i={i}, j={j}")j += 1i += 1
# 輸出:
# i=0, j=0
# i=0, j=1
# i=1, j=0
# i=1, j=1
# i=2, j=0
# i=2, j=1
2.5.3 循環控制(break, continue, pass)
在循環中,可以使用break、continue和pass語句來控制循環的執行。
break語句用于終止循環,不再執行循環體中的剩余代碼,并立即退出循環。
# break 示例
for i in range(5):if i == 3:breakprint(i)
# 輸出:
# 0
# 1
# 2
continue語句用于跳過當前迭代的剩余代碼,直接進入下一次迭代。
# continue 示例
for i in range(5):if i == 3:continueprint(i)
# 輸出:
# 0
# 1
# 2
# 4
pass語句用于占位,表示不執行任何操作。通常用于語法上需要語句,但實際不需要執行任何代碼的場合。
# pass 示例
for i in range(5):if i == 3:pass # 這里可以放置以后需要的代碼print(i)
# 輸出:
# 0
# 1
# 2
# 3
# 4
通過學習for和while循環以及循環控制語句,您將能夠在程序中實現重復執行某段代碼的功能,提高代碼的效率和靈活性。
2.6 函數基礎
函數是組織代碼的一種重要方式,通過使用函數,我們可以將重復的代碼封裝到一起,以便在需要的時候調用。
函數可以提高代碼的可讀性和可維護性,使程序更易于理解和修改。
Python中的函數定義和調用非常靈活,支持多種參數傳遞方式,并且可以返回多個值。
掌握函數的定義與調用是Python編程中的重要內容之一。
2.6.1 函數的定義與調用
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
函數名應該具有描述性,能夠表明函數的功能。
函數可以有參數,也可以沒有參數。
定義函數時,還可以指定函數的返回值。函數體由縮進的代碼塊組成,通常包含函數的邏輯和實現。
定義一個簡單的函數
下面是一個簡單的函數示例,它打印一個問候語:
def greet():print("Hello, welcome to Python programming!")
調用函數
定義函數后,我們可以通過函數名加括號的方式來調用它:
greet() # 輸出: Hello, welcome to Python programming!
帶參數的函數
函數可以接受參數,參數可以在函數定義時指定。當函數被調用時,可以將值傳遞給參數。
def greet_user(name):print(f"Hello, {name}, welcome to Python programming!")greet_user("Alice") # 輸出: Hello, Alice, welcome to Python programming!
帶返回值的函數
函數可以返回一個值,使用return關鍵字實現。當函數執行到return語句時,會將結果返回,并結束函數的執行。
def add(a, b):return a + bresult = add(3, 5)
print(result) # 輸出: 8
通過這些示例,您可以看到函數的定義與調用在Python中是多么簡潔和強大。
掌握函數的定義和調用將使您能夠編寫更高效、更模塊化的代碼。
2.6.2 函數參數
函數參數是函數定義中非常重要的一部分,它決定了函數如何接收輸入并進行處理。Python支持多種方式來傳遞參數,使得函數的使用更加靈活和強大。我們將分別介紹位置參數、關鍵字參數、默認參數和不定長參數,并展示它們的綜合使用方法。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
2.6.3 函數返回值
在Python中,函數不僅可以執行一系列操作,還可以返回一個或多個值。函數的返回值用于將函數的計算結果傳遞給調用方,這使得函數更加靈活和實用。理解如何定義和使用函數的返回值是編寫高效代碼的關鍵。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
2.6.4 函數文檔字符串
函數文檔字符串(docstring)是一種用于為函數、模塊、類或方法編寫文檔的字符串。
它幫助開發者了解函數的用途、參數和返回值,從而使代碼更加可讀和可維護。
Python強烈推薦使用文檔字符串來為代碼編寫文檔。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第3章:模塊與包
在Python編程中,模塊和包是組織和管理代碼的重要方式。通過將相關功能分組到模塊和包中,我們可以提高代碼的可重用性和可維護性,并且方便地管理和使用外部庫。
在本章中,我們將學習如何使用Python標準庫、如何安裝和使用第三方庫、以及如何創建和使用自定義模塊和包。
此外,我們還會介紹一些常用的第三方庫,以便您在實際項目中能更高效地完成各種任務。
3.1 標準庫的使用
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
3.2 第三方庫的安裝與使用
除了Python的標準庫外,Python的生態系統中還有大量的第三方庫,這些庫由社區開發和維護,提供了各種強大的功能,極大地擴展了Python的應用范圍。
在這一節中,我們將介紹如何使用pip工具來安裝第三方庫,并展示一些常用第三方庫的安裝示例。
3.2.1 pip的使用
pip是Python的包管理工具,用于安裝和管理Python包。
pip非常強大且易于使用,幾乎所有的第三方庫都可以通過pip進行安裝。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
3.2.2 常用第三方庫安裝示例
以下是一些常用第三方庫的安裝示例,這些庫在各種Python項目中都有廣泛的應用。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
3.3 自定義模塊與包
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
3.4 常用第三方庫介紹
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第4章:文件與異常處理
在編程過程中,處理文件和異常是必不可少的技能。
文件操作涉及讀取和寫入文件內容,而異常處理則用于捕獲和處理程序運行中的錯誤。
在本章中,我們將學習如何進行文件讀寫操作,以及如何處理程序中的異常。
4.1 文件讀寫操作
文件操作是程序與外部數據交互的重要方式。
Python提供了一套完整的文件操作接口,可以方便地進行文件的讀寫操作。我們將探討如何讀取文件、寫入文件,以及各種文件模式的使用。
4.1.1 讀文件
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
4.1.2 寫文件
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
4.1.3 文件模式
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
4.2 文件和目錄操作
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
4.3 異常捕獲與處理
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
4.4 日志記錄
在開發和維護軟件時,日志記錄是一個重要的工具。通過日志記錄,開發者可以跟蹤程序的執行過程、記錄重要的事件和錯誤信息,從而更容易發現和解決問題。
Python提供了功能強大的logging模塊,用于靈活地記錄日志信息。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第二部分:高級進階
第5章:面向對象編程
面向對象編程(OOP)是現代編程范式中非常重要的一種,它通過類和對象將數據和行為進行封裝,從而提高代碼的重用性、可擴展性和可維護性。
Python作為一種面向對象的編程語言,提供了強大而靈活的OOP特性。
在本章中,我們將深入學習面向對象編程的核心概念和技術,包括類與對象、封裝、繼承、多態,以及一些高級話題如靜態方法、類方法、抽象類和接口等。
5.1 類與對象
類和對象是面向對象編程的基礎。
在Python中,類是一種定義數據和行為的模板,而對象是類的實例。
通過定義類和創建對象,我們可以組織和管理程序中的復雜數據和邏輯。
5.1.1 類的定義
在Python中,類使用class關鍵字定義。類可以包含屬性(數據)和方法(函數),用于描述對象的狀態和行為。
示例:定義一個簡單的類
class Person:# 初始化方法,用于創建實例時初始化屬性def __init__(self, name, age):self.name = nameself.age = age# 實例方法,用于描述行為def greet(self):return f"Hello, my name is {self.name} and I am {self.age} years old."
在這個示例中,我們定義了一個名為Person的類。__init__方法是一個特殊的方法,在創建實例時自動調用,用于初始化對象的屬性。greet方法是一個實例方法,用于返回問候語。
5.1.2 對象的創建與使用
對象是類的實例,通過調用類的構造函數來創建。我們可以使用對象來訪問屬性和方法。
示例:創建和使用對象
# 創建Person類的實例
person1 = Person("Alice", 30)
person2 = Person("Bob", 25)# 訪問屬性
print(person1.name) # 輸出: Alice
print(person2.age) # 輸出: 25# 調用方法
print(person1.greet()) # 輸出: Hello, my name is Alice and I am 30 years old.
print(person2.greet()) # 輸出: Hello, my name is Bob and I am 25 years old.
在這個示例中,我們創建了兩個Person類的實例,并訪問了它們的屬性和方法。
5.1.3 類屬性和實例屬性
類屬性是定義在類級別的屬性,所有實例共享;實例屬性是定義在實例級別的屬性,每個實例有獨立的副本。
示例:類屬性和實例屬性
class Person:species = "Homo sapiens" # 類屬性def __init__(self, name, age):self.name = name # 實例屬性self.age = age # 實例屬性def greet(self):return f"Hello, my name is {self.name} and I am {self.age} years old."# 創建實例
person1 = Person("Alice", 30)
person2 = Person("Bob", 25)# 訪問類屬性
print(Person.species) # 輸出: Homo sapiens
print(person1.species) # 輸出: Homo sapiens
print(person2.species) # 輸出: Homo sapiens# 修改類屬性
Person.species = "Human"
print(person1.species) # 輸出: Human# 訪問實例屬性
print(person1.name) # 輸出: Alice
print(person2.age) # 輸出: 25
在這個示例中,species是一個類屬性,所有Person實例共享。name和age是實例屬性,每個實例有獨立的值。
通過學習類與對象的定義和使用,您可以開始在Python中使用面向對象編程來組織和管理代碼。
5.2 封裝、繼承、多態
面向對象編程的三個重要特性是封裝、繼承和多態。通過理解和應用這些特性,可以構建更具模塊化、可維護性和可擴展性的程序。
5.2.1 封裝的概念
封裝是將數據(屬性)和行為(方法)捆綁在一起,并隱藏對象的內部實現細節,僅對外暴露必要的接口。封裝可以提高代碼的安全性和可維護性,防止外部代碼直接訪問和修改對象的內部狀態。
示例:封裝的實現
class Person:def __init__(self, name, age):self.__name = name # 私有屬性self.__age = age # 私有屬性def greet(self):return f"Hello, my name is {self.__name} and I am {self.__age} years old."def get_age(self):return self.__agedef set_age(self, age):if age > 0:self.__age = ageelse:raise ValueError("Age must be positive")# 創建實例
person = Person("Alice", 30)# 訪問私有屬性 (通過方法)
print(person.greet()) # 輸出: Hello, my name is Alice and I am 30 years old.# 修改私有屬性 (通過方法)
person.set_age(35)
print(person.get_age()) # 輸出: 35# 直接訪問私有屬性會導致錯誤
# print(person.__age) # AttributeError: 'Person' object has no attribute '__age'
在這個示例中,__name和__age是私有屬性,不能直接從外部訪問。通過定義公有方法get_age和set_age,我們可以間接訪問和修改私有屬性。
5.2.2 繼承的實現
繼承是一個類(子類)繼承另一個類(父類)的屬性和方法,從而實現代碼重用和擴展。
子類可以擴展或重寫父類的方法,增加新的功能。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
5.3 魔法方法與特殊屬性
魔法方法(Magic Methods),也稱為特殊方法,是Python內置的具有特殊用途的函數。這些方法以雙下劃線(__)開頭和結尾,并用于在特定情況下自動調用。特殊屬性是Python對象自帶的一些屬性,也使用雙下劃線包圍,提供有關對象的元數據和行為控制。
5.3.1 常用魔法方法
魔法方法使得Python的類能夠與內置操作進行交互,提供自定義對象的特殊行為。
init
__init__方法是類的初始化方法,在創建實例時自動調用,用于初始化對象的屬性。
class Person:def __init__(self, name, age):self.name = nameself.age = age# 創建實例時會自動調用__init__方法
person = Person("Alice", 30)
print(person.name) # 輸出: Alice
print(person.age) # 輸出: 30
str
__str__方法定義了對象的字符串表示,用于print()和str()函數。當嘗試以字符串形式打印對象時調用。
class Person:def __init__(self, name, age):self.name = nameself.age = agedef __str__(self):return f"Person(name={self.name}, age={self.age})"person = Person("Alice", 30)
print(person) # 輸出: Person(name=Alice, age=30)
repr
__repr__方法返回對象的官方字符串表示,用于repr()函數和交互解釋器。當開發者需要一個準確且非歧義的對象表示時調用。
class Person:def __init__(self, name, age):self.name = nameself.age = agedef __repr__(self):return f"Person(name='{self.name}', age={self.age})"person = Person("Alice", 30)
print(repr(person)) # 輸出: Person(name='Alice', age=30)
5.3.2 特殊屬性
特殊屬性提供了有關對象的元數據和控制對象行為的機制。
dict
__dict__屬性是一個字典,包含對象的所有可變屬性和它們的值。可以用來查看和修改對象的屬性。
class Person:def __init__(self, name, age):self.name = nameself.age = ageperson = Person("Alice", 30)
print(person.__dict__) # 輸出: {'name': 'Alice', 'age': 30}# 修改屬性
person.__dict__['age'] = 31
print(person.age) # 輸出: 31
class
__class__屬性指向對象的類,提供了訪問對象所屬類的方式。
class Person:def __init__(self, name, age):self.name = nameself.age = ageperson = Person("Alice", 30)
print(person.__class__) # 輸出: <class '__main__.Person'># 檢查對象是否為特定類的實例
print(isinstance(person, Person)) # 輸出: True
5.3.3 綜合示例
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
5.4 類的高級話題
在面向對象編程中,除了基本的類和對象操作外,還有一些高級話題,可以幫助我們創建更強大和靈活的程序。這些包括靜態方法與類方法、抽象類與接口,以及迭代器與生成器。
5.4.1 靜態方法與類方法
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
5.4.3 迭代器與生成器
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第6章:函數式編程
函數式編程是一種編程范式,它強調使用函數來處理數據和進行計算。
與面向對象編程不同,函數式編程主要關注數據的傳遞和轉換,避免使用可變狀態和副作用。
Python支持多種函數式編程特性,包括高階函數、內置函數(如map、filter、reduce)、閉包與裝飾器、以及生成器表達式與列表推導式。
在本章中,我們將探討這些函數式編程的概念和應用。
6.1 高階函數
高階函數是函數式編程的核心概念之一。一個函數如果滿足以下條件之一,就是高階函數:
- 接受一個或多個函數作為參數。
- 返回一個函數。
6.1.1 定義與使用
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
6.2 內置函數
Python 提供了一些內置函數,用于支持函數式編程。最常用的內置函數包括 map、filter 和 reduce。這些函數使得對序列進行操作更加簡潔和高效。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
6.3 閉包與裝飾器
閉包和裝飾器是函數式編程中的兩個重要概念,它們在編寫簡潔和高效的代碼方面起著重要作用。
閉包允許函數捕獲和記住其定義時的環境,而裝飾器是用于增強函數功能的強大工具。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
6.4 生成器表達式與列表推導式
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第7章:并發編程
在現代編程中,并發編程是一個重要的技術領域,用于提高程序的效率和響應能力。并發編程可以通過多線程、多進程和異步編程等方式實現,使得程序能夠同時處理多個任務,從而充分利用系統資源。
在本章中,我們將探討并發編程的基礎知識,包括線程與進程、異步編程,以及并發編程的最佳實踐。
7.1 線程與進程
線程和進程是實現并發編程的兩種主要方式。
線程是操作系統能夠進行運算調度的最小單位,而進程是操作系統進行資源分配和調度的基本單位。
Python 提供了 threading 和 multiprocessing 模塊,分別用于多線程編程和多進程編程。
7.1.1 threading模塊
`
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
7.1.2 multiprocessing模塊
`
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
7.2 異步編程
在現代編程中,處理I/O密集型任務時,異步編程是一種非常有效的技術。
異步編程允許我們在等待I/O操作完成時,繼續執行其他任務,從而提高程序的效率和響應性。在Python中,asyncio模塊提供了強大的異步編程支持。
7.2.1 asyncio模塊基礎
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
7.2.3 異步編程與多線程編程和多進程編程的區別
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
7.3 并發編程最佳實踐
在編寫高效并發程序時,了解常見問題和優化技巧是至關重要的。并發編程不僅涉及如何讓程序運行得更快,還包括確保程序的正確性和穩定性。本節將介紹并發編程中的常見問題和一些優化技巧。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第8章 網絡編程
網絡編程是現代編程的重要組成部分,它使得計算機能夠通過網絡進行通信和數據交換。
在Python中,網絡編程涵蓋了從低級的套接字編程到高級的Web框架應用。
本章將介紹如何使用Python進行網絡編程,包括套接字編程、HTTP請求處理,以及使用流行的Web框架如Flask和Django進行Web應用開發。
8.1 套接字編程
套接字是網絡編程的基礎,它提供了在網絡上傳輸數據的方法。在Python中,socket模塊提供了用于創建和操作套接字的接口。
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
8.3 Web框架初探
Web框架是用于開發Web應用程序的軟件框架,它提供了一些標準的方式來構建和部署Web應用程序。在Python中,Flask和Django是兩種非常流行的Web框架。本節將介紹這兩種框架的基本使用方法,幫助你快速入門Web開發。
8.3.1 Flask簡介與快速入門
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第三部分:實戰演練
第9章:數據分析項目
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
9.3 數據分析案例
通過前面幾節的學習,我們已經掌握了數據清洗、預處理和可視化的基本技能。
現在,我們將通過幾個實際的數據分析案例,來綜合應用這些技能,進行深入的分析和洞察。
9.3.1 電商用戶行為分析
電商平臺的用戶行為分析是一個常見的實際數據分析任務。
我們將使用一個包含用戶瀏覽、點擊和購買行為的數據集,來分析用戶的行為模式和趨勢。
數據集
假設我們有一個包含電商用戶行為的數據集ecommerce_data.csv,其內容如下:
user_id,timestamp,event_type,product_id,category_id
1,2023-01-01 12:01:00,view,1001,2001
1,2023-01-01 12:03:00,click,1001,2001
1,2023-01-01 12:05:00,add_to_cart,1001,2001
1,2023-01-01 12:10:00,purchase,1001,2001
2,2023-01-01 12:15:00,view,1002,2002
2,2023-01-01 12:17:00,click,1002,2002
2,2023-01-01 12:20:00,view,1003,2003
數據清洗與預處理
首先,我們將使用pandas進行數據的清洗與預處理。
import pandas as pd# 讀取數據
df = pd.read_csv('ecommerce_data.csv')# 查看數據集的前幾行
print(df.head())
輸出結果:
user_id timestamp event_type product_id category_id
0 1 2023-01-01 12:01:00 view 1001 2001
1 1 2023-01-01 12:03:00 click 1001 2001
2 1 2023-01-01 12:05:00 add_to_cart 1001 2001
3 1 2023-01-01 12:10:00 purchase 1001 2001
4 2 2023-01-01 12:15:00 view 1002 2002
數據清洗與處理
我們需要處理時間戳數據,并提取日期和時間,以便后續分析。
# 將timestamp列轉換為datetime類型
df['timestamp'] = pd.to_datetime(df['timestamp'])# 提取日期和時間
df['date'] = df['timestamp'].dt.date
df['time'] = df['timestamp'].dt.timeprint(df.head())
輸出結果:
user_id timestamp event_type product_id category_id date time
0 1 2023-01-01 12:01:00 view 1001 2001 2023-01-01 12:01:00
1 1 2023-01-01 12:03:00 click 1001 2001 2023-01-01 12:03:00
2 1 2023-01-01 12:05:00 add_to_cart 1001 2001 2023-01-01 12:05:00
3 1 2023-01-01 12:10:00 purchase 1001 2001 2023-01-01 12:10:00
4 2 2023-01-01 12:15:00 view 1002 2002 2023-01-01 12:15:00
數據分析
我們可以通過分析用戶的不同事件類型來了解他們的行為模式。
# 按事件類型統計數量
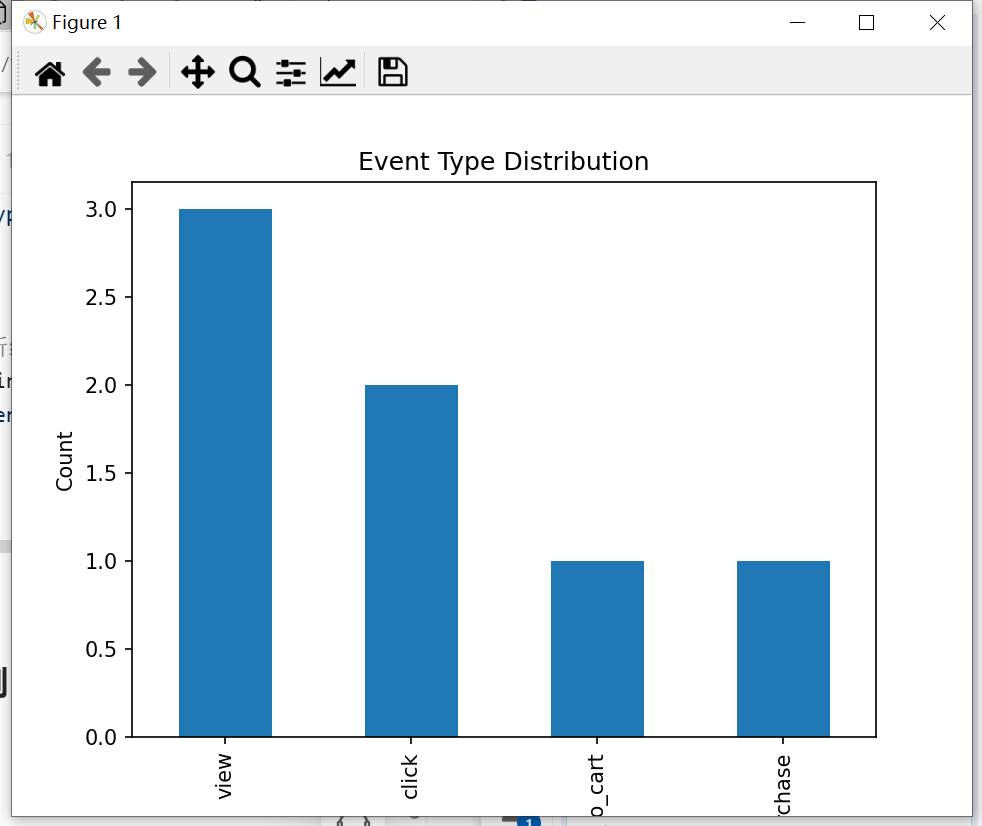
event_counts = df['event_type'].value_counts()
print(event_counts)
輸出結果:
view 3
click 2
add_to_cart 1
purchase 1
Name: event_type, dtype: int64
我們還可以按日期分析用戶的行為趨勢。
# 按日期和事件類型統計數量
daily_events = df.groupby(['date', 'event_type']).size().unstack().fillna(0)
print(daily_events)
輸出結果:
event_type add_to_cart click purchase view
date
2023-01-01 1.0 2.0 1.0 3.0
數據可視化
我們使用matplotlib對分析結果進行可視化展示。
import matplotlib.pyplot as plt# 繪制事件類型分布的柱狀圖
event_counts.plot(kind='bar')
plt.title('Event Type Distribution')
plt.xlabel('Event Type')
plt.ylabel('Count')
plt.show()# 繪制每日事件數量的折線圖
daily_events.plot(kind='line')
plt.title('Daily Event Counts')
plt.xlabel('Date')
plt.ylabel('Count')
plt.show()
9.3.2 其他數據分析示例
示例1:銷售數據分析
假設我們有一個包含銷售數據的數據集sales_data.csv,包括以下字段:date、sales_amount、product_id、region。
date,sales_amount,product_id,region
2023-01-01,100,101,North
2023-01-01,150,102,East
2023-01-02,200,101,North
2023-01-02,250,103,South
2023-01-03,300,102,East
2023-01-03,350,104,West
2023-01-04,400,101,North
2023-01-04,450,103,South
2023-01-05,500,104,West
2023-01-05,550,102,East
數據清洗與預處理
import pandas as pd# 讀取數據
sales_df = pd.read_csv('sales_data.csv')# 查看數據集的前幾行
print(sales_df.head())
輸出結果:
date sales_amount product_id region
0 2023-01-01 100 101 North
1 2023-01-01 150 102 East
2 2023-01-02 200 101 North
3 2023-01-02 250 103 South
4 2023-01-03 300 102 East
數據分析
按日期統計銷售總額。
# 按日期統計銷售總額
daily_sales = sales_df.groupby('date')['sales_amount'].sum()
print(daily_sales)
輸出結果:
date
2023-01-01 250
2023-01-02 450
2023-01-03 650
2023-01-04 850
2023-01-05 1050
Name: sales_amount, dtype: int64
數據可視化
繪制每日銷售總額的折線圖。
import matplotlib.pyplot as plt# 繪制每日銷售總額的折線圖
daily_sales.plot(kind='line')
plt.title('Daily Sales Amount')
plt.xlabel('Date')
plt.ylabel('Sales Amount')
plt.show()
進一步分析
按地區統計銷售總額。
# 按地區統計銷售總額
region_sales = sales_df.groupby('region')['sales_amount'].sum()
print(region_sales)
輸出結果:
region
East 1000
North 700
South 700
West 850
Name: sales_amount, dtype: int64
繪制按地區統計銷售總額的柱狀圖。
# 繪制按地區統計銷售總額的柱狀圖
region_sales.plot(kind='bar')
plt.title('Total Sales Amount by Region')
plt.xlabel('Region')
plt.ylabel('Sales Amount')
plt.show()
示例2:天氣數據分析
假設我們有一個包含天氣數據的數據集weather_data.csv,包括以下字段:date、temperature、humidity、weather_condition。
date,temperature,humidity,weather_condition
2023-01-01,5,80,Cloudy
2023-01-02,7,78,Sunny
2023-01-03,6,82,Rainy
2023-01-04,10,75,Sunny
2023-01-05,12,70,Sunny
2023-01-06,8,85,Cloudy
2023-01-07,9,88,Rainy
2023-01-08,11,77,Sunny
2023-01-09,13,72,Sunny
2023-01-10,14,68,Sunny# 讀取數據
weather_df = pd.read_csv('weather_data.csv')# 查看數據集的前幾行
print(weather_df.head())# 按天氣條件統計平均溫度和濕度
weather_stats = weather_df.groupby('weather_condition').agg({'temperature': 'mean', 'humidity': 'mean'})
print(weather_stats)# 繪制天氣條件與平均溫度和濕度的關系圖
weather_stats.plot(kind='bar')
plt.title('Weather Condition vs Temperature and Humidity')
plt.xlabel('Weather Condition')
plt.ylabel('Average Values')
plt.show()
在本節中,我們通過電商用戶行為分析和其他數據分析示例,展示了如何應用數據清洗、預處理和可視化技術,進行深入的分析和洞察。
這些實際案例不僅幫助我們鞏固了前面學到的知識,還提供了寶貴的經驗,指導我們在實際項目中應用數據分析技術。
第10章 Web應用開發
在本章中,我們將介紹如何使用Django開發一個簡單的學生管理系統。
通過這個項目,你將學會如何使用Django創建和管理數據庫模型、編寫視圖、設計URL模式、創建表單和模板,并了解Django的認證和權限系統。以下是本章的詳細章節目錄:
10.1 Django簡介與環境配置
10.1.1 Django簡介
Django是一個高級Python Web框架,旨在快速開發和簡化復雜的數據庫驅動網站的創建。
它強調代碼復用、組件即插即用、快速開發和不重復造輪子原則。
10.1.2 環境配置與安裝
首先,我們需要確保在系統上安裝了Python和pip,然后使用以下命令安裝Django:
pip install django
10.1.3 創建Django項目
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
10.2 創建與管理數據庫模型
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
10.3 編寫視圖和URL配置
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
10.4 創建表單和處理用戶輸入
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
第11章 爬蟲實戰
由于平臺的字數限制, 這里省略了500+字,具體請參見尼恩的穿透AI系列之 《Python學習圣經:從0到1精通Python,打好AI基礎》PDF
說在最后:有問題找老架構取經
毫無疑問,與傳統應用架構師相比, AI架構師更有錢途, 這個代表未來的架構。
前面講到,尼恩指導的那個一個成功案例,是一個9年經驗 網易的小伙伴,拿到了一個年薪近80W的大模型架構offer,逆漲50%,那是在去年2023年的 5月。
- 驚天大逆襲:8年小伙20天時間提75W年薪offer,逆漲50%,秘訣在這
不到1年,小伙伴也在團隊站穩了腳跟,成為了名副其實的大模型架構師。回想當時,尼恩本來是規劃指導小伙做通用架構師的( JAVA 架構、K8S云原生架構), 當時候為了他的錢途, 尼恩也是 壯著膽子, 死馬當作活馬指導他改造為 大模型架構師。
沒想到,由于尼恩的大膽嘗試, 小伙伴成了, 相當于他不到1年時間, 職業身價翻了1倍多,現在可以拿到年薪 200W的offer了。
應該來說,小伙伴大成,實現了真正的逆天改命。
既然有一個這么成功的案例,尼恩能想到的,就是希望能幫助更多的社群小伙伴, 成長為大模型架構師,也去逆天改命。
技術是相通的,架構也是。
尼恩架構團隊的大模型《LLM大模型學習圣經》是一個系列,初步的規劃包括下面的內容:
-
《Python學習圣經:從0到1精通Python,打好AI基礎》
-
《LLM大模型學習圣經:從0到1吃透Transformer技術底座》
-
《LangChain學習圣經:從0到1精通LLM大模型應用開發的基礎框架》
-
《LLM大模型學習圣經:從0到1精通RAG架構,基于LLM+RAG構建生產級企業知識庫》
-
《SpringCloud + Python 混合微服務架構,打造AI分布式業務應用的技術底層》
-
《LLM大模型學習圣經:從0到1吃透大模型的頂級架構》
本文是第1篇,作者是資深架構師 Andy(負責初稿) +43歲老架構師尼恩(負責升華,帶給大家一種俯視技術,技術自由的高度)。
尼恩架構團隊會持續迭代和更新,后面會有實戰篇,架構篇等等出來。 并且錄制配套視頻。
在尼恩的架構師哲學中,開宗明義:架構和語言無關,架構的思想和模式,本就是想通的。
架構思想和體系,本身和語言無關,和業務也關系不大,都是通的。
所以,尼恩用自己的架構內功,以及20年時間積累的架構洪荒之力,通過《LLM大模型學習圣經》,給大家做一下系統化、體系化的LLM梳理,使得大家內力猛增,成為大模型架構師,然后實現”offer直提”, 逆天改命。
尼恩 《LLM大模型學習圣經》PDF 系列文檔,會延續尼恩的一貫風格,會持續迭代,持續升級。
這個文檔將成為大家 學習大模型的殺手锏, 此文當最新PDF版本,可以來《技術自由圈》公號獲取。
本文是第3篇,第一作者是Andy,第二作者是尼恩。后面的文章,尼恩團隊會持續迭代和更新。 并且錄制配套視頻。
當然,除了大模型學習圣經,尼恩團隊,持續深耕技術,為大家輸出更多,更深入的技術體系,思想體系。
多年來,用深厚的架構功力,把很多復雜的問題做清晰深入的穿透式、起底式的分析,寫了大量的技術圣經:
- Netty 學習圣經:穿透Netty的內存池和對象池(那個超級難,很多人窮其一生都搞不懂),
- DDD學習圣經: 穿透 DDD的建模和落地,
- Caffeine學習圣經:比如Caffeine的底層架構,
- 比如高性能葵花寶典
- Thread Local 學習圣經
- 等等等等。
上面這些學習圣經,大家可以通過《技術自由圈》公眾號,找尼恩獲取。
大家深入閱讀和掌握上面這些學習圣經之后,一定內力猛漲。
所以,尼恩強烈建議大家去看看尼恩的這些核心內容。
另外,如果學好了之后,還是遇到職業難題, 沒有面試機會,怎么辦?
可以找尼恩來幫扶、領路。
尼恩已經指導了大量的就業困難的小伙伴上岸.
前段時間,幫助一個40歲+就業困難小伙伴拿到了一個年薪100W的offer,小伙伴實現了 逆天改命 。
另外,尼恩也給一線企業提供 《DDD 的架構落地》企業內部培訓,目前給不少企業做過內部的咨詢和培訓,效果非常好。

尼恩技術圣經系列PDF
- 《NIO圣經:一次穿透NIO、Selector、Epoll底層原理》
- 《Docker圣經:大白話說Docker底層原理,6W字實現Docker自由》
- 《K8S學習圣經:大白話說K8S底層原理,14W字實現K8S自由》
- 《SpringCloud Alibaba 學習圣經,10萬字實現SpringCloud 自由》
- 《大數據HBase學習圣經:一本書實現HBase學習自由》
- 《大數據Flink學習圣經:一本書實現大數據Flink自由》
- 《響應式圣經:10W字,實現Spring響應式編程自由》
- 《Go學習圣經:Go語言實現高并發CRUD業務開發》
……完整版尼恩技術圣經PDF集群,請找尼恩領取
《尼恩 架構筆記》《尼恩高并發三部曲》《尼恩Java面試寶典》PDF,請到下面公號【技術自由圈】取↓↓↓









-之Vite 還是 (Create React App) CRA? 用Vite創建項目)







(牛客小白月賽95))

