1. 日志數據的存儲
1.1 Partition
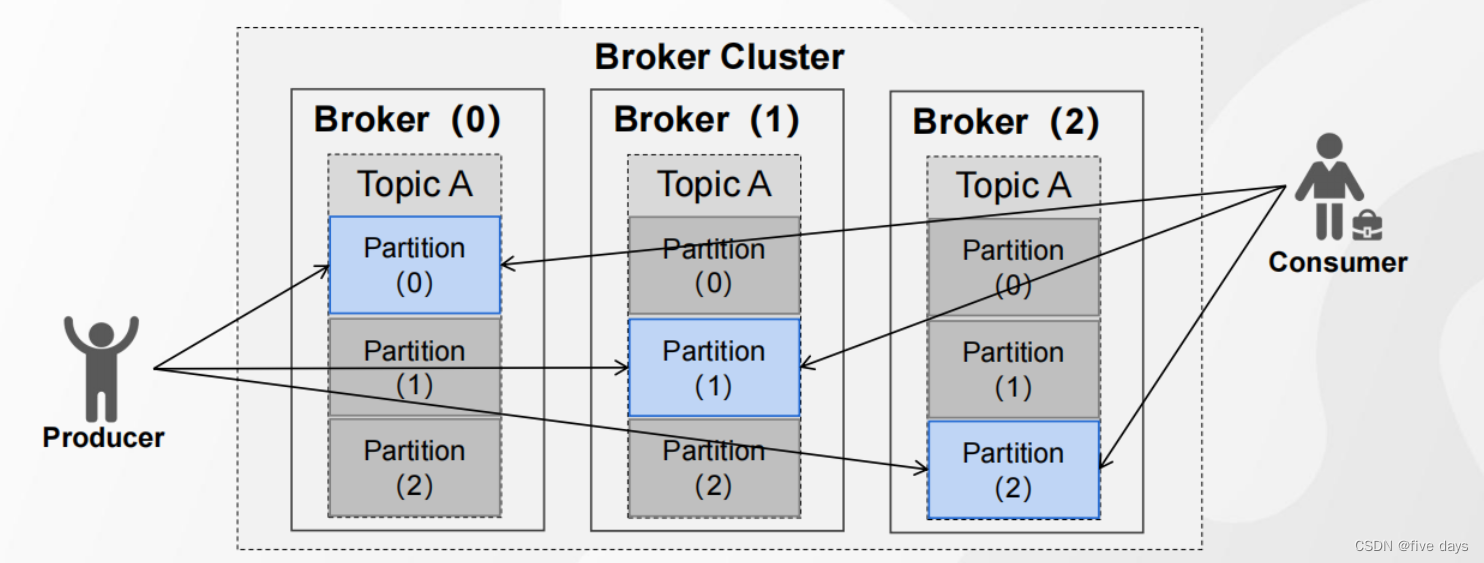
1. 為了實現橫向擴展,把不同的數據存放在不同的 Broker 上,同時降低單臺服務器的訪問壓力,我們把一個Topic 中的數據分隔成多個 Partition2.?每個 Partition 中的消息是有序的,順序寫入,但是全局不一定有序3.?在服務器上,每個 Partition 都有一個物理目錄( TopicN )后面的數字代表分區
?
1.2 Replica副本
1. 為了提高分區的可靠性, Kafka 設計了副本機制2.?副本數必須小于等于節點數,而不能大于 Broker 的數量3.?Leader 對外提供讀寫服務, Follower 唯一的任務就是從 Leader 異步拉取數據
?
1.3 Segment段
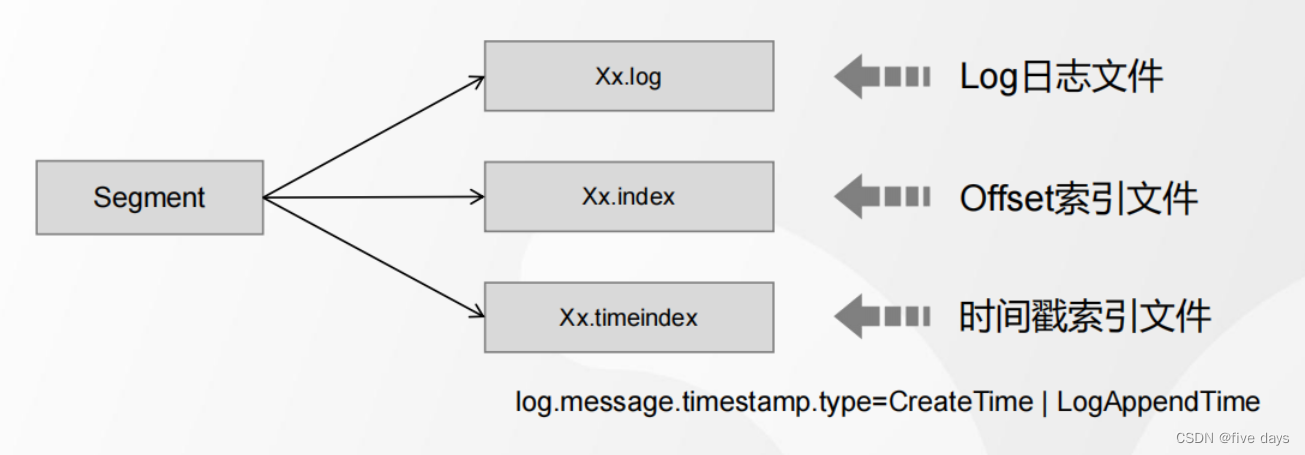
1.?為了防止Log不斷追加導致文件過大,導致檢索消息效率變低,一個Partition又 被劃分成多個Segment來組織數據.
在這里會有3個配置,也就是log的閾值配置。什么時候下進行分段
log.index.size.max.bytes:根據索引文件大小
每一個segment都是由一個log文件和2個index文件組成的,其中時間戳索引的創建方式可以自定義的執行createTime或LogAppendTime.默認是creareTime
?1.4 Sparse Index(稀疏索引)
索引文件的查看可以通過以下命令進行查看

?kfaka索引文件中記錄的Offset不是連續的,而是采用了稀疏索引。根據配置的大小,稀疏索引記錄的是從Log中的哪個位置開始檢索,比如配置的是4kb,則當log文件中向下存儲的數據達到4kb的話,就會記錄一個索引值

?1.5 分區副本在Broker上的分布
創建一個topic
./kafka-topics.sh--bootstrap-server192.168.61.101:9092--create--topic3p3r--partitions3--replication-factor3
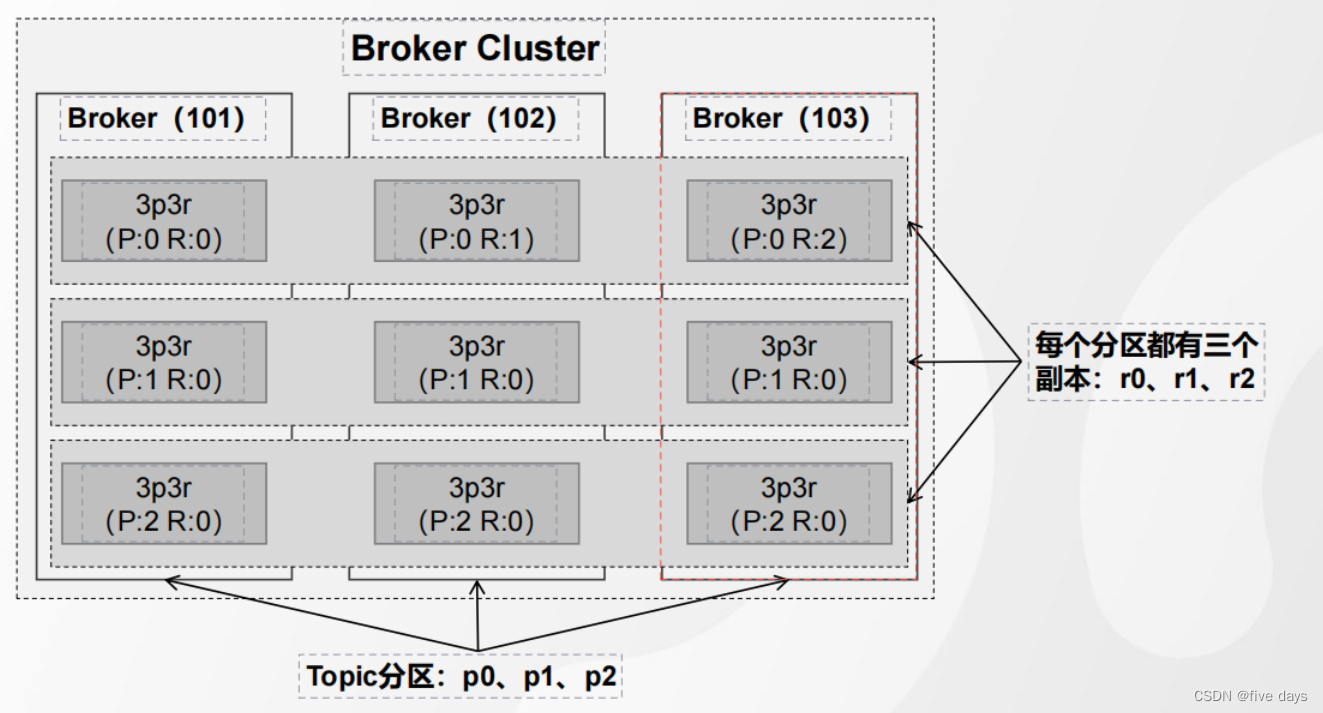
?假設配置的是3p3r,則我們看下服務器上的存儲
查看Topic信息
./kafka-topics.sh--bootstrap-server192.168.61.101:9092--describe--topic3p3r
?其中 Partition是分區,Leader后面代表的是在哪臺服務器上,Replicas就是副本信息,ISR是個副本隊列
?假設配置的是4p2r,則物品們查看topic信息如圖所示
創建、查看topic
./kafka-topics.sh --bootstrap-server 192.168.61.101:9092 --create --topic 4p2r --partitions 4 --replication-factor 2./kafka-topics.sh --bootstrap-server 192.168.61.101:9092 --describe --topic 4p2r


?假設我們配置的是6p2r


由以上我們可以看出,副本分配的兩個基本原則和規律
1、副本會被平均分布在所有的Broker之上
2 、 partition 的多個副本應該分配在不同的 Broker 上
基于上面的規則,分區副本最終落入哪個節點,還會收到兩個隨機數的影響
1、第一個隨機數:startIndex,決定了第一個分區的第一個副本的放置位置
2 、第二個隨機數: nextReplicaShift ,決定了分區中,副本跟副本的間距nextReplicaShift%(BrokerSize-1)
這樣設計的目的在于提高Broker服務器的容災能力?
2. 消息保留與清理機制
對于一些太久的日志,我們需要一定的清理策略。
當開啟清理策略后,有兩種方式提供開發者選擇
log.cleanup.policy=delete (默認項) // 刪除策略log.cleanup.policy=compact? ? // 壓縮策略
?2.1 刪除策略(delete)
kafka可以通過定時任務實現日志數據的刪除,默認5分鐘執行一次
log.retention.check.interval.ms=300000
那么要刪除什么樣的數據呢?kafka提供了兩個緯度以及對應不同的配置
時間緯度
log.retention.hours(默認值是168個小時,時間戳超過的數據會被刪除)
log.retention.minutes (默認值是空,優先級比小時高)log.retention.ms (默認值是空,優先級比分鐘高)
若產生消息的速度不均勻,有時多、有時少,就可以根據日志大小刪除
log.retention.bytes (表示所有日志文件的總大小,默認值是 -1 ,代表不限制大小)log.segment.bytes (對單個 Segment 文件大小進行限制,默認值 1G )
?2.2 壓縮策略(compact)
若設置為壓縮策略compact,則表示不清楚日志,只對日志數據進行壓縮處理
思考問題: 如果同一個key重復寫入多次,是會存儲多次?還是會更新?
kafka中是存儲多次的,如:?_ _consumer_offsets
那么壓縮策略是怎么做的呢?(將相同的key進行去重壓縮)

3. Broker高可用架構
高可用,無非就是選舉機制、數據的一致性也就是主從同步,以及對于故障的處理,由于kafka是直接數據存儲在磁盤中的,因此無需考慮持久化,Broker的高可用 涉及到一系列的動作?
- 選舉出一個Controller
- 從分區中選舉出Leader角色
- 主從同步
- Replica故障處理
3.1 選舉機制
3.1.1 Controller選舉
Controller其實就是一個Broker,由它來負責選舉出新的Leader,那么Controller是怎么選舉出來的呢
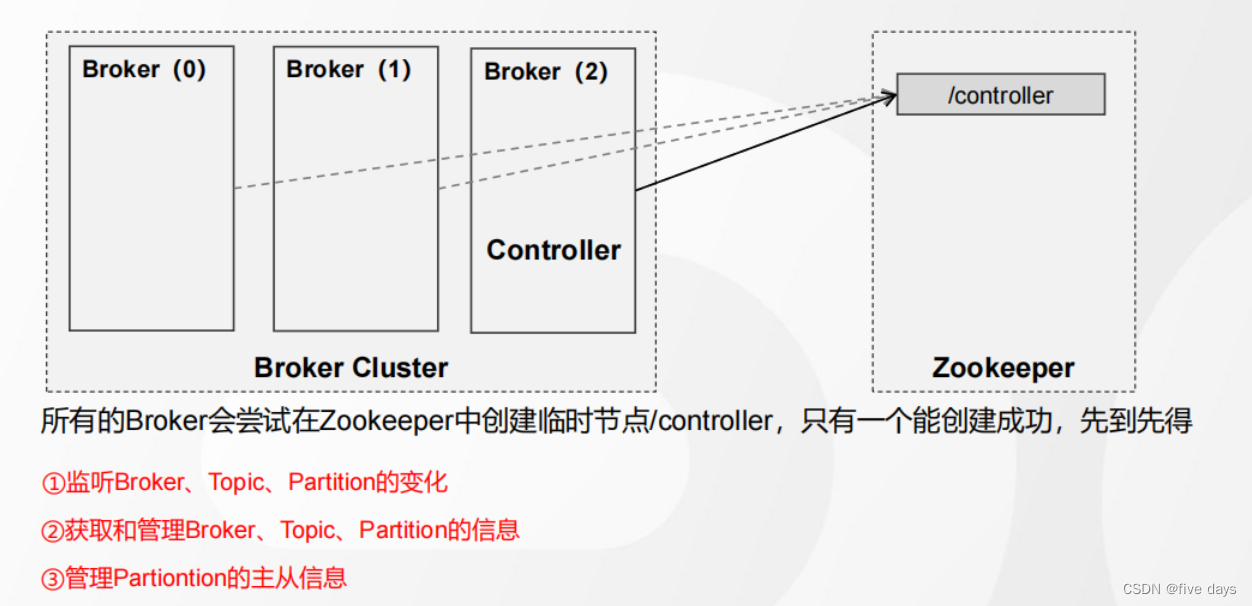
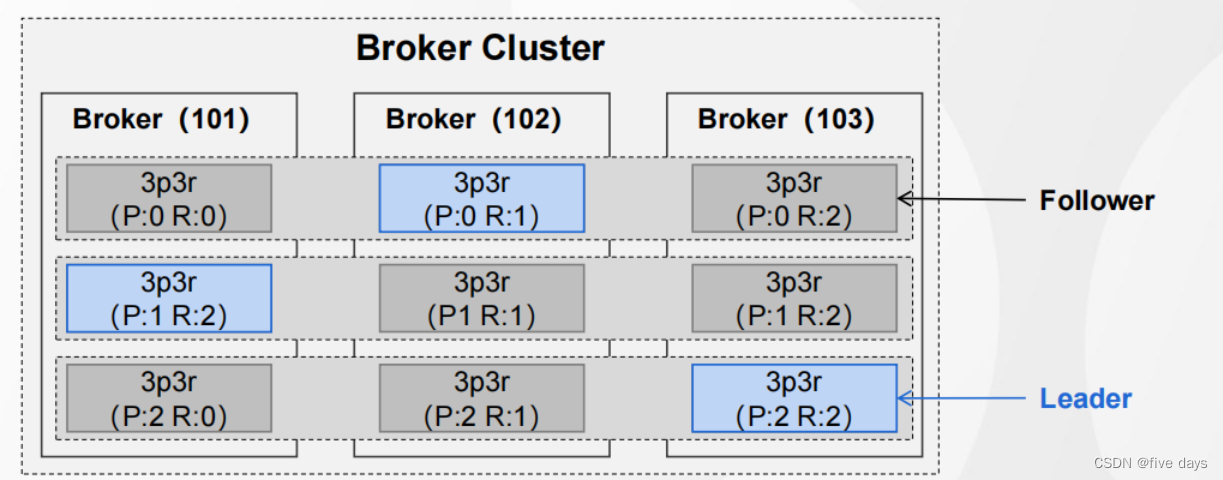
?3.1.2 分區副本Leader的選舉
在講解Leader選舉前,我們先復習以下博客Kafka之Producer原理-CSDN博客中提到的ISR機制的幾個概念
AR ( Assigned-Replicas ),一個分區所有的副本ISR ( In-Sync Replicas ),在 AR 中,跟 Leader 保持積極同步數據的副本OSR ( Out-Sync-Replicas ),在 AR 中,跟 Leader 同步滯后的副本AR = ISR + OSR
- ?當Leader副本發生故障時,只有在ISR中的副本才能參與新Leader的選舉
- 問題:如果ISR為空呢? unclean.leader.election.enable配置為false OSR也可以進行選舉
- Kafka采用了類似于繼位傳嫡的選舉協議,選擇ISR中位置靠前的節點成為新的Leader.
3.2 主從同步
從節點和主節點的同步過程如下:
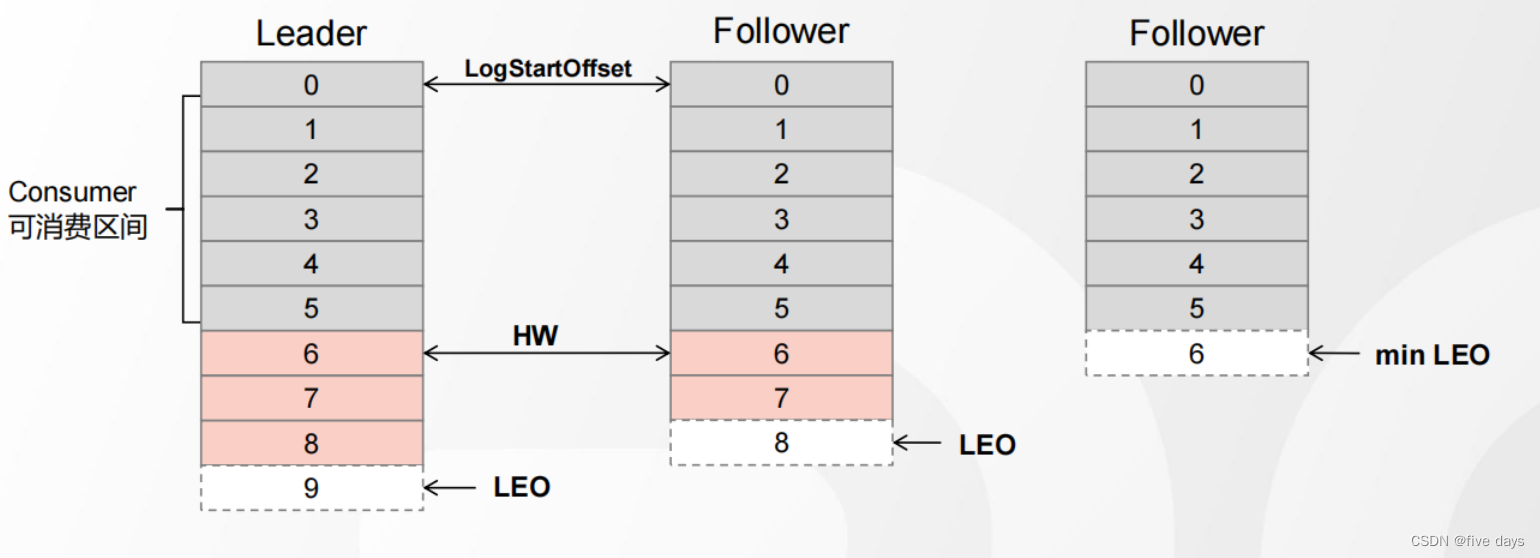
1 、首先, Follower 節點向 Leader 發送一個 fetch 請求2 、然后, Leader 向 Follower 發送數據3 、接著, Follower 接收到數據響應后,依次寫入消息、并更新 LEO 值4 、最后, Leader 更新 HW ( ISR 最小的 LEO )5 、循環上述過程,直至所有 Follower 完成數據同步
?整體流程圖如下所示:

?
?
?Kafka設計的ISR復制,既可以在保障數據一致性,又可以提供高吞吐量(ISR隊列中清除響應不積極的Follower節點)
3.3 Replica故障處理
- Follower發生故障,會被先提出ISR,Follower恢復之后,從HW開始同步數據
- Leader發生故障,會先選舉出一個新的Leader,其它的Follower將高于HW的消息截取掉,然后從新的Leader同步數據
4. 總結
? ? ? ? 本文介紹Broker服務器,主要講了Broker中日志的存儲,從大到小依次為Partition、Segment,副本機制的具體存儲形式,是怎么進行負載均衡和容災保障的,在Segment中我們直到了Segment是由一個Log文件和兩個索引文件組成的,索引文件主要起的是一個提升查詢效率的作用。隨后當kafka中log文件過大的時候,kagka中提供了兩種維度上的刪除策略以及相同key去重壓縮的compact策略。最后,kafka高可用中的選舉機制是先到先得選舉Controller,再根據ISR副本隊列嫡長子繼位的算法進行Leader的選舉;以及Kafka中的主從同步是以高水位HW為界限,不斷的同步數據,直到LEO值相等完成數據的同步。最后講到了副本故障的處理,針對follwe節點故障,則直接踢出ISR隊列,Leader故障,就會觸發選舉機制,選舉出一個新的Leader,最后數據從LEO處以上的開始同步,高于HW的消息全部截斷。













![[原創][Delphi多線程]TThreadedQueue的經典使用案例.](http://pic.xiahunao.cn/[原創][Delphi多線程]TThreadedQueue的經典使用案例.)





