前言:三維目標檢測技術正逐漸成為計算機視覺領域的重要研究方向。特別是在自動駕駛、增強現實(AR)、虛擬現實(VR)以及機器人導航等應用中,對三維空間內目標的精準檢測與定位顯得尤為重要。然而,傳統的二維目標檢測技術已無法滿足這些復雜場景下的需求,因此,多視圖3D目標檢測技術的崛起,為我們打開了一扇新的大門,本文將首先介紹多視圖3D目標檢測技術的基本原理和常用方法,然后深入探討位置嵌入變換技術的核心算法和關鍵技術。接下來,我們將結合實際應用案例,分析多視圖3D目標檢測技術在現實場景中的挑戰和解決方案。最后,我們將展望這一技術的未來發展趨勢,并探討可能的研究方向和應用前景。
本文所涉及所有資源均在傳知代碼平臺可獲取
目錄
概述
演示效果
核心代碼
寫在最后
概述
多視角圖像中的3D目標檢測由于其在自動駕駛系統中的低成本而具有吸引力,如下圖所示:
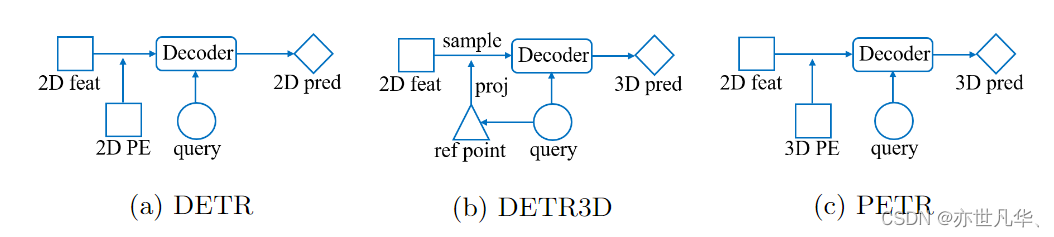
1)在DETR中,每個對象查詢表示一個對象,與Transformer解碼器中的2D特征交互以產生預測的結果。
2)在DETR3D中,由對象查詢預測的3D參考點通過相機參數投影回圖像空間,并對2D特征進行采樣,以與解碼器中的對象查詢進行交互。
3)PETR通過將3D位置嵌入編碼到2D圖像特征中生成3D位置感知特征,對象查詢直接與3D位置感知特征交互,并輸出3D檢測結果。
PETR體系結構具有許多優點,它既保留了原始DETR的端到端的方式,又避免了復雜的2D到3D投影和特征采樣。
??????? 在給定來自N個視角的圖像I={Ii∈R3×HI×WI,i=1,2,...,N}I={Ii?∈R3×HI?×WI?,i=1,2,...,N},這些圖像被輸入到主干網絡中,生成2D多視圖特征F2d=Fi2d∈RC×HF×WF,i=1,2,...,NF2d=Fi2d?∈RC×HF?×WF?,i=1,2,...,N。在3D坐標生成器中,相機視錐空間首先被離散化為三維網格,然后通過相機參數對網格坐標進行變化,生成3D世界空間中的坐標。3D坐標和2D多視圖特征被輸入到3D位置編碼器中,產生3D位置感知特征F3d=Fi3d∈RC×HF×WF,i=1,2,...,NF3d=Fi3d?∈RC×HF?×WF?,i=1,2,...,N。3D特征進一步輸入到Transformer解碼器,并與查詢生成器生成的對象查詢進行交互。更新后的對象查詢用于預測對象類和3D邊界框,如下圖所示:

為了構建2D圖像和3D空間之間的關系,PETR將相機視錐空間中的點投影到3D空間。PETR首先將相機視錐空間離散化以生成大小為(WF,HF,D)(WF?,HF?,D)的網格。網格中的每個點可以表示為pjm=(uj×dj,vi×dj,dj,1)Tpjm?=(uj?×dj?,vi?×dj?,dj?,1)T,其中(uj,vj)(uj?,vj?)是圖像中的像素坐標,djdj?是沿與圖像平面正交的軸的深度值。由于網格由不同的視覺共享,因此可以通過3D逆投影來計算3D世界空間中對應的3D坐標 ,如下:
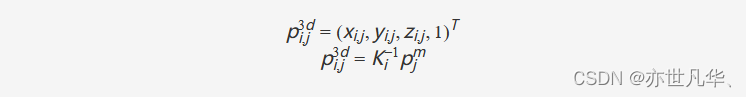
其中Ki∈R4×4Ki?∈R4×4是第i個視圖的變換矩陣,它建立了從3D空間到相機視錐空間的轉換。所有視圖的3D坐標在變換后覆蓋場景的全景圖。PETR進一步對3D坐標進行歸一化。
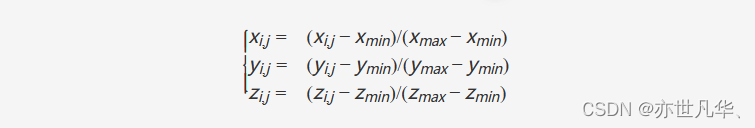
其中[xmin,ymin,zmin,xmax,ymax,zmax][xmin?,ymin?,zmin?,xmax?,ymax?,zmax?]?是3D世界空間中的感興趣區域(RoI),HF×WF×DHF?×WF?×D點的歸一化坐標最終轉置為P3d={Pi3d∈R(D×4)×HF×WF,i=1,2,…,N}P3d={Pi3d?∈R(D×4)×HF?×WF?,i=1,2,…,N}。
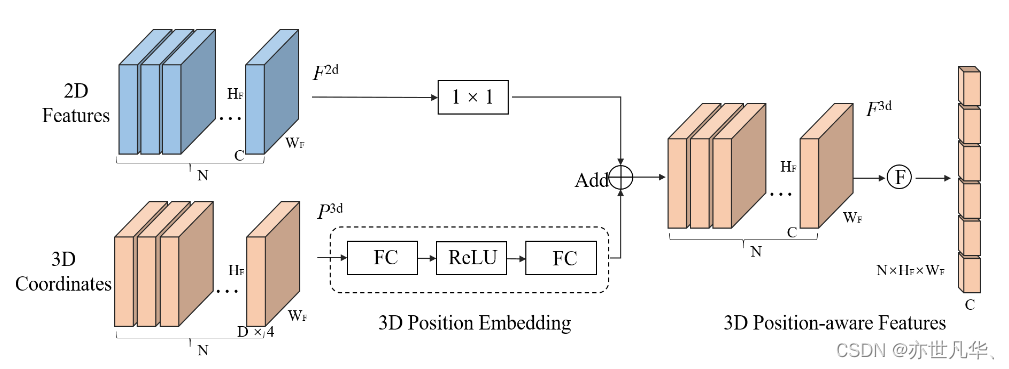
3D位置編碼的目的是通過將2D圖像特征與3D位置信息相關聯來獲得3D特征,3D位置編碼器可以公式化為:Fi3d?=ψ(Fi2d?,Pi3d?),i=1,2,…,N,ψ的方法如下圖所示,給定2D特征F2dF2d和3D坐標P3dP3d,P3dP3d首先輸入到一個多層感知機網絡中轉換到3D位置編碼(PE)之后,3D特征通過一個1x1的卷積層和3D PE相加形成3D位置感知特征。最終,PETR將3D位置感知特征作為transformer解碼器中的key:
查詢生成器:原始DETR直接使用一組可學習參數作為初始對象查詢,可變形DETR和DETR3D基于初始化的對象查詢預測參考點。為了緩解3D場景中的收斂困難,PETR首先在3D世界空間中初始化一組可學習的錨點,這些錨點具有從0到1的均勻分布。然后將3D錨點的坐標輸入到具有兩個線性層的小型MLP網絡,生成初始對象查詢Q0Q0?。
解碼器:對于解碼器網絡,PETR遵循DETR中的標準Transformer解碼器,它包含了L個解碼層,PETR將解碼層中的交互過程公式化為Ql=Ωl(F3d,Ql?1),l=1,…,LQl?=Ωl?(F3d,Ql?1?),l=1,…,L。在每個解碼器層中,對象查詢通過多頭注意力和前饋網絡與3D位置感知特征交互,迭代交互后,更新后的對象查詢具有高級表示,可用于預測相應的對象。
演示效果
其中紅色邊界框表示自車車輛,Radar結果如下:

lidar 結果如下:

6個相機的結果如下:

核心代碼
下面這段代碼通過對圖像特征進行位置編碼,實現了將圖像特征映射到現實世界的坐標空間,并生成對應的位置嵌入向量:
def position_embeding(self, img_feats, img_metas, masks=None):eps = 1e-5# 首先將所有的特征圖都填充到原始圖像的大小pad_h, pad_w, _ = img_metas[0]['pad_shape'][0]# 在特征圖較大的情況下來獲取它的位置信息B, N, C, H, W = img_feats[self.position_level].shape# 32但是每個間隔維16,因此定義每個圖像放大的倍數為16的形式coords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / Hcoords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / Wif self.LID:# 此時定義的是深度信息,目的是為了轉換嗎index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()index_1 = index + 1# 獲得每個網格的深度箱的大小,但是為什么還要除以65bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))# 此時的結果也是64,但是此時深度箱的大小用來表示什么coords_d = self.depth_start + bin_size * index * index_1else:index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()bin_size = (self.position_range[3] - self.depth_start) / self.depth_numcoords_d = self.depth_start + bin_size * indexD = coords_d.shape[0]# [3,88,32,64]->[88,32,64,3] 通過將特征圖進行離散化形成坐標來生成網格和視錐的形式coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3# 生成齊次坐標系,獲得[x,y,z,1]形式的坐標coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1)# [88,32,64,2] x,y處也包含了深度的信息torch.tensorcoords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps)img2lidars = []for img_meta in img_metas:img2lidar = []# 針對6副圖像,使用np將旋轉矩陣的逆求解處出來for i in range(len(img_meta['lidar2img'])):img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i]))# 將一個batch內的圖像到雷達的數據計算出來img2lidars.append(np.asarray(img2lidar))# [1,6,4,4]img2lidars = np.asarray(img2lidars)# 使img2lidars獲得coords相同的類型和device情況img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4)# [1,1,88,32,64,4,1]->[1,6,88,32,64,4,1]coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1)# [1,6,1,1,1,4,4,4]->[1,6,88,32,64,4,4]img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1)# 6個圖像分別進行相乘形成新的坐標系,從相機視錐空間生成6個視圖現實空間的坐標。# 并且只選取x,y,z三個數據coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3]# 位置坐標來進行歸一化處理,pos_range是3D感興趣區域,先前都設置好了coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0])coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2])# 除去不再目標范圍內的數據coords_mask = (coords3d > 1.0) | (coords3d < 0.0) # [1,6,88,32,64,3]->[1,6,88,32,192]->[1,6,88,32] 設定一個閾值,超過該閾值我們不再需要coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5)# 當取值為1的時候,此時是我們希望屏蔽的數據coords_mask = masks | coords_mask.permute(0, 1, 3, 2)# [1,6,88,32,64,3]->[1,6,64,3,32,88]->[6,192,32,88]coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W)# 將其轉換為現實世界的坐標coords3d = inverse_sigmoid(coords3d)# embedding_dim是depth的四倍coords_position_embeding = self.position_encoder(coords3d)return coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask下面這段代碼主要功能是將輸入的特征進行處理,然后輸入到 Transformer 網絡中進行計算。具體來說,該函數的執行過程如下:
1)從 mlvl_feats 中選擇第一個特征,并獲取其大小信息。
2)根據輸入的大小信息,生成一個掩碼 masks,用于遮擋無效區域。
3)對特征進行扁平化,并通過線性層進行變換,得到查詢嵌入 query_embeds。
4)如果需要,生成位置編碼,將其與查詢嵌入相加得到最終的查詢嵌入。
5)將查詢嵌入輸入到 Transformer 網絡中進行計算,得到輸出結果 outs_dec。
6)對輸出結果進行后處理,得到分類分數和回歸預測值。
def forward(self, mlvl_feats, img_metas):"""Forward function.Args:mlvl_feats (tuple[Tensor]): Features from the upstreamnetwork, each is a 5D-tensor with shape(B, N, C, H, W).Returns:all_cls_scores (Tensor): Outputs from the classification head, \shape [nb_dec, bs, num_query, cls_out_channels]. Note \cls_out_channels should includes background.all_bbox_preds (Tensor): Sigmoid outputs from the regression \head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \Shape [nb_dec, bs, num_query, 9]."""# 因為此時兩者的結構式一致的,因此選擇第一個,且選擇特征圖較大的情況、x = mlvl_feats[0]batch_size, num_cams = x.size(0), x.size(1)# batch為1,且6個相機視角,每個視角下的大小都一致,因此選取第一個的形式input_img_h, input_img_w, _ = img_metas[0]['pad_shape'][0] masks = x.new_ones( # [1,6,512,1408] 不太確定此時的mask用來遮擋什么物體(batch_size, num_cams, input_img_h, input_img_w))for img_id in range(batch_size):for cam_id in range(num_cams):img_h, img_w, _ = img_metas[img_id]['img_shape'][cam_id]masks[img_id, cam_id, :img_h, :img_w] = 0# x.flatten(0,1)將第0維到第1維拍成第0維,其余保持不變 # x: [1,6,256,32,88]->[6,256,32,88]->[6,256,32,88] 不理解input的目的,是為了多加一個非線性嗎x = self.input_proj(x.flatten(0,1)) x = x.view(batch_size, num_cams, *x.shape[-3:])# interpolate masks to have the same spatial shape with x [1,6,512,1408]->[1,6,32,88]# 在mask上進行采樣,生成新的mask的形式,但此時mask的作用是什么呢masks = F.interpolate(masks, size=x.shape[-2:]).to(torch.bool)if self.with_position:# pos_embedding是PETR的重點,包含了坐標系的轉換等一系列 此時生成的是3D位置嵌入coords_position_embeding, _ = self.position_embeding(mlvl_feats, img_metas, masks)pos_embed = coords_position_embeding# 如果具有多個視角,那么不同的視角也需要使用位置編碼來進行操作if self.with_multiview:# [1,6,32,88]->[1,6,384,32,88]->[1,6,256,32,88]sin_embed = self.positional_encoding(masks)sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())pos_embed = pos_embed + sin_embedelse:pos_embeds = []for i in range(num_cams):xy_embed = self.positional_encoding(masks[:, i, :, :])pos_embeds.append(xy_embed.unsqueeze(1))sin_embed = torch.cat(pos_embeds, 1)sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())pos_embed = pos_embed + sin_embedelse:if self.with_multiview:pos_embed = self.positional_encoding(masks)pos_embed = self.adapt_pos3d(pos_embed.flatten(0, 1)).view(x.size())else:pos_embeds = []for i in range(num_cams):pos_embed = self.positional_encoding(masks[:, i, :, :])pos_embeds.append(pos_embed.unsqueeze(1))pos_embed = torch.cat(pos_embeds, 1)# [900,3] pos2posemb3d: [900,384]reference_points = self.reference_points.weight# 針對每個query形成一個嵌入的形式[900,256],線形層來生成查詢query_embeds = self.query_embedding(pos2posemb3d(reference_points))# query是直接從Embedding生成 [1,900,3]reference_points = reference_points.unsqueeze(0).repeat(batch_size, 1, 1) #.sigmoid()# 利用transformer架構來獲取query填充后的信息,之后用于計算class和bboxouts_dec, _ = self.transformer(x, masks, query_embeds, pos_embed, self.reg_branches)# 通過nan_to_num()將NaN轉換為可處理的數字 [6,1,900,256]outs_dec = torch.nan_to_num(outs_dec)outputs_classes = []outputs_coords = []for lvl in range(outs_dec.shape[0]):reference = inverse_sigmoid(reference_points.clone())assert reference.shape[-1] == 3outputs_class = self.cls_branches[lvl](outs_dec[lvl])tmp = self.reg_branches[lvl](outs_dec[lvl])tmp[..., 0:2] += reference[..., 0:2]tmp[..., 0:2] = tmp[..., 0:2].sigmoid()tmp[..., 4:5] += reference[..., 2:3]tmp[..., 4:5] = tmp[..., 4:5].sigmoid()outputs_coord = tmpoutputs_classes.append(outputs_class)outputs_coords.append(outputs_coord)all_cls_scores = torch.stack(outputs_classes)all_bbox_preds = torch.stack(outputs_coords)# 轉換為3D場景下的數據all_bbox_preds[..., 0:1] = (all_bbox_preds[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0])all_bbox_preds[..., 1:2] = (all_bbox_preds[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1])all_bbox_preds[..., 4:5] = (all_bbox_preds[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2])outs = {'all_cls_scores': all_cls_scores,'all_bbox_preds': all_bbox_preds,'enc_cls_scores': None,'enc_bbox_preds': None, }return outs下面這段代碼是一系列指令,用于配置并準備運行一個復雜的3D目標檢測項目所需的環境和依賴:
# 新建一個虛擬環境
conda activate petr
# 下載cu111 torch1.9.0 python=3.7 linux系統
wget https://download.pytorch.org/whl/cu111/torch-1.9.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
pip install 'torch下載的位置'
wget https://download.pytorch.org/whl/cu111/torchvision-0.10.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
pip install 'torchvison下載的地址'
# 安裝MMCV
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
# 安裝MMDetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
git checkout v2.24.1
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..# 安裝MMsegmentation
sudo pip install mmsegmentation==0.20.2# 安裝MMdetection 3D
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..# 安裝PETR
git clone https://github.com/megvii-research/PETR.git
cd PETR
mkdir ckpts ###pretrain weights
mkdir data ###dataset
ln -s ../mmdetection3d ./mmdetection3d
ln -s /data/Dataset/nuScenes ./data/nuscenes寫在最后
????????在本文中,我們深入探討了多視圖3D目標檢測中的位置嵌入變換技術,這一領域不僅是當前計算機視覺研究的熱點,更是未來諸多智能應用系統的核心技術支撐。通過詳細解析位置嵌入變換的原理、算法以及其在多視圖3D目標檢測中的應用,我們不難發現,這一技術正逐步改變著我們對于目標檢測與定位的認知。.
????????視圖3D目標檢測位置嵌入變換技術將在更多領域得到應用。自動駕駛汽車、無人機導航、增強現實技術、智能安防系統等等,都將受益于這一技術的突破。我們有理由相信,在不遠的將來,這一技術將如同今天的智能手機一樣,深入到我們生活的方方面面,改變我們的世界。
詳細復現過程的項目源碼、數據和預訓練好的模型可從該文章下方附件獲取。
【傳知科技】關注有禮???? 公眾號、抖音號、視頻號


)







)

?)






![【Qt秘籍】[008]-Qt中的connect函數](http://pic.xiahunao.cn/【Qt秘籍】[008]-Qt中的connect函數)
