COCA20000 是美國當代語料庫中最常見的 20000 個詞匯,不過實際上有一些重復,去重之后大概是 17600+ 個,這些單詞是很有用,如果能掌握這些單詞,相信會對英語的能力有一個較大的提升。我很早就下載了這些單詞,并且自己編寫了一個背單詞的簡易工具,如果有需要的同學,可以去看我的博客中搜索。今天這篇博客是利用字典樹來堆單詞的一個可視化。
字典樹可視化詞匯
下面就是一顆簡單的 4 個單詞的字典樹,這個東西用來檢索是很快的,這里我把最后的單詞作為樹的葉子節點。隨著單詞的不斷增加,整個樹也會不斷的膨脹,不過這樣就難以閱讀了,所以我最終選擇是把樹的排列方向變成從又到右的形式。我之后要實現的字典樹和下面這個沒有什么本質的區別,只是更大一些而已,利用的數據就是 COCA 20000 的單詞。
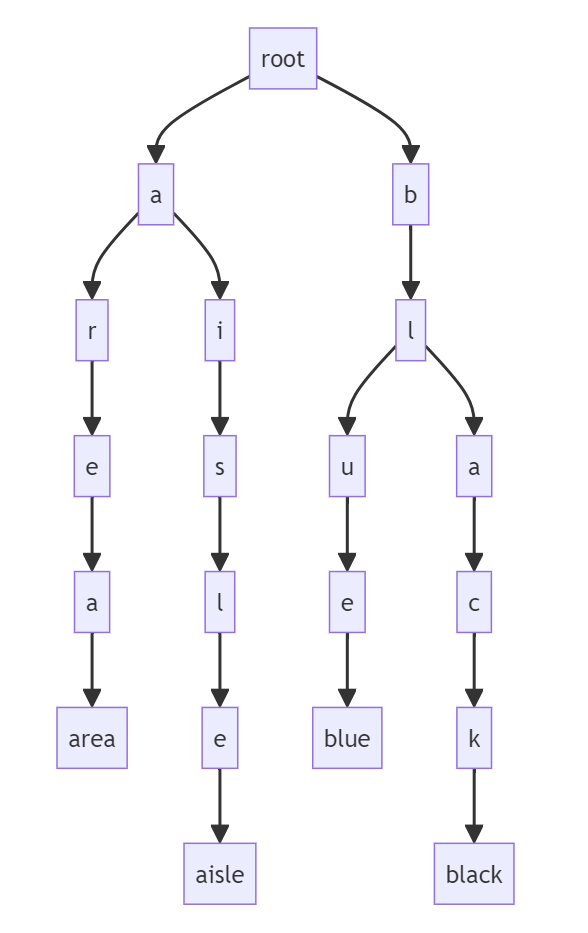
上面這個圖形是使用 mermaid 繪制的,不過最終我采用的是 dot 語言(繪圖指令就在下面),因為 mermaid 可能會遇到性能問題。實際上,dot 語言也是遇到了性能問題,因為單詞實在是太多了,導致最后的圖形太大了。我想了一些可能的優化措施,比如根據首字母來區分單詞,這樣的化加上大小寫總共 52 個字母,可以把大的樹分成 52 個小一點的樹。不過,我也不是真的要去看這個樹,所以就沒有這樣做。
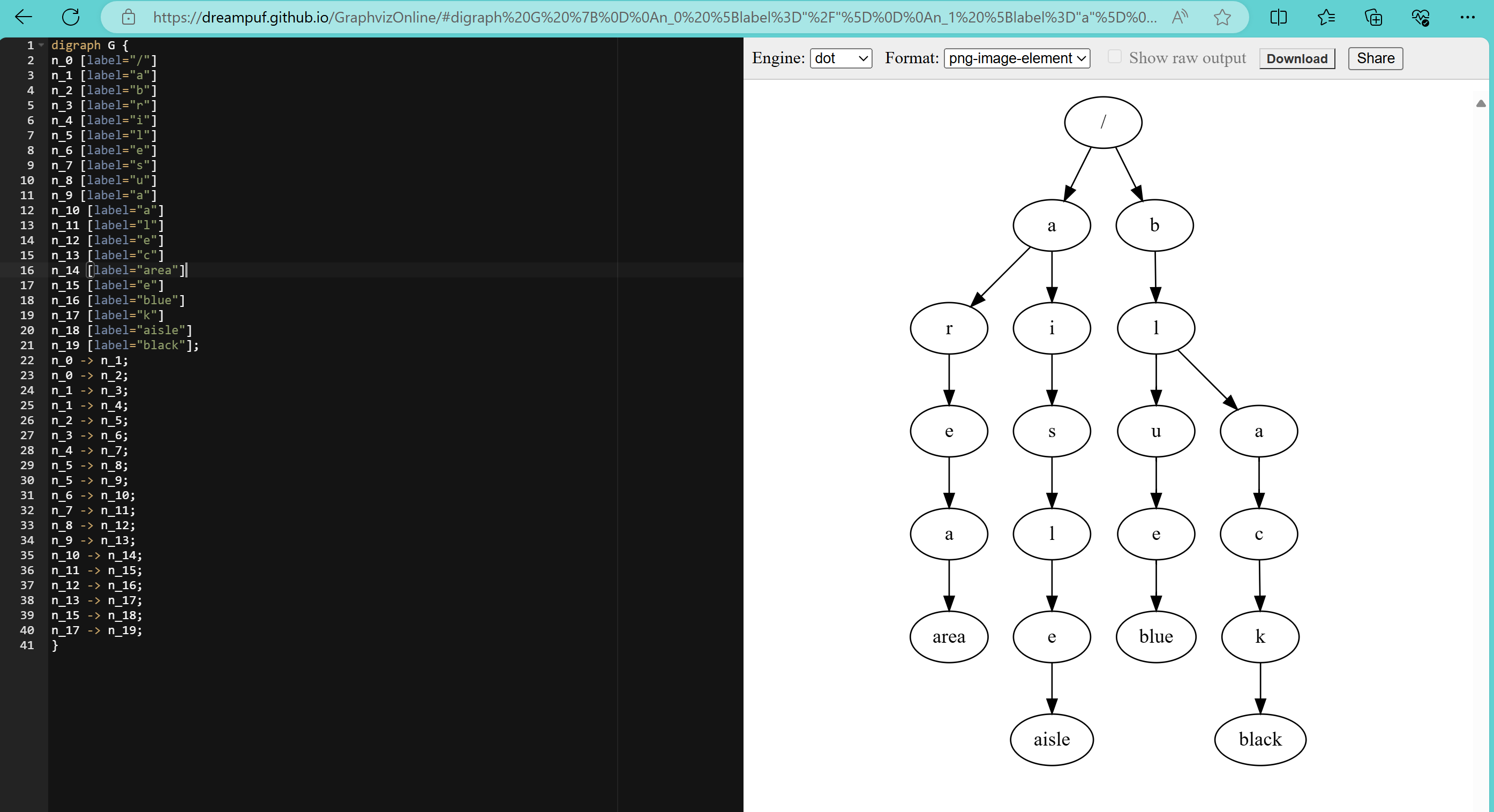
代碼處理
下面是全部的處理代碼。
"""
字典樹
目的是生成 COCA 單詞的字典樹,但是也可以用于其他單詞或者詞語(包括英語)。
"""
import jsonclass Node:"""字典樹的一個節點,包含這個節點的值,以及它下面的節點,以及是否是一個單詞的結尾。"""def __init__(self, val, is_end) -> None:self.val = valself.is_end = is_endself.children = {}def set_is_end(self) -> None:"""有些短的單詞要重新設置,否則無法和長的區分開來,例如:are, area"""self.is_end = Trueclass DictTree:"""字典樹"""def __init__(self):self.root = Node('/', False)self.stack = [] # 用來保存單詞def append(self, word: str):"""向字典樹中添加一個單詞: 獲取當前樹的根節點:node = self.root遍歷這個詞的每一個字符 c,1. 如果該字符在當前樹的子樹中,則把當前樹的子樹指向當前樹: node = node.children[c]如果當前字符 c 是最后一個字符,那么: node.is_end = True2. 如果該字符不在當前樹的子樹中,那么新建立一個節點,如果當前字符 c 是最后一個字符:is_end = True把它添加到當前樹的子樹中, node.children[c] = Node(c, is_end)"""node = self.rootfor i, c in enumerate(word):is_end = not i != len(word)-1if node.children.get(c):node = node.children[c]if is_end:node.set_is_end()else:node.children[c] = Node(c, is_end)node = node.children[c]def dumps(self) -> dict:"""序列化成字典對象"""return {"/": self.__dump(self.root)}def __dump(self, node: Node) -> dict:"""序列化成字典對象的內部方法,一個簡單但是并不優雅的遞歸"""ret = {}self.stack.append(node.val)if not node.children:ret["word"] = "".join(self.stack[1:])for k, c in node.children.items():ret[k] = self.__dump(c)self.stack.pop()return ret# 生成dot描述
# 層序遍歷 tips: 使用隊列
def BFS_to_dot(tree) -> str:"""將樹結構以層序遍歷的方式轉換為Dot語言表示的圖形。Dot語言用于描述圖形結構,本函數特別適用于將樹結構可視化。:param tree: 輸入的樹結構,通常是一個字典或類似字典的對象,其中鍵值對表示節點及其子節點。:return: 返回一個表示樹結構的Dot語言字符串。"""if not tree:returnqueue = [tree["/"]] # 把樹的根本身作為第一個節點加入隊列count = 0 # 子節點計數parent_count = 0 # 父節點計數parent_map = {0: "/"} # 記錄父節點序號和它的值nodes = ['n_0 [label="/"]'] # 點集edges = [] # 邊集while queue:node = queue.pop(0)if isinstance(node, dict):for val, child in node.items():queue.append(child)count += 1v = val if val != "word" else childparent_map[count] = vdot_node = f'n_{count} [label="{v}"]'dot_edge = f"n_{parent_count} -> n_{count};"nodes.append(dot_node)edges.append(dot_edge)parent_count += 1node_str = "\n".join(nodes)edge_str = "\n".join(edges)return f"digraph G {{\nrankdir=LR;\n{node_str};\n{edge_str}\n}}"if __name__ == "__main__":in_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_no_order.txt"out_json_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_dt_tree.json"out_dot_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_dt_tree.dot"dt = DictTree()with open(in_file, "r", encoding="utf-8") as file:for word in [line.strip() for line in file.readlines()]:dt.append(word)dt_dumps = dt.dumps()# 序列化json寫入with open(out_json_file, "w", encoding="utf-8") as file:json.dump(dt_dumps, file)# dot寫入with open(out_dot_file, "w", encoding="utf-8") as file:file.write(BFS_to_dot(dt_dumps))print("EOF")生成的文件
這里生成的 json 文件是壓縮形式的,如果格式化的化,就超過 4m 了。

渲染圖形
因為我安裝了 graphviz 的插件,所以我直接在 VSCode 查看生成的 dot 文件時,它就在渲染了,不過渲染失敗了。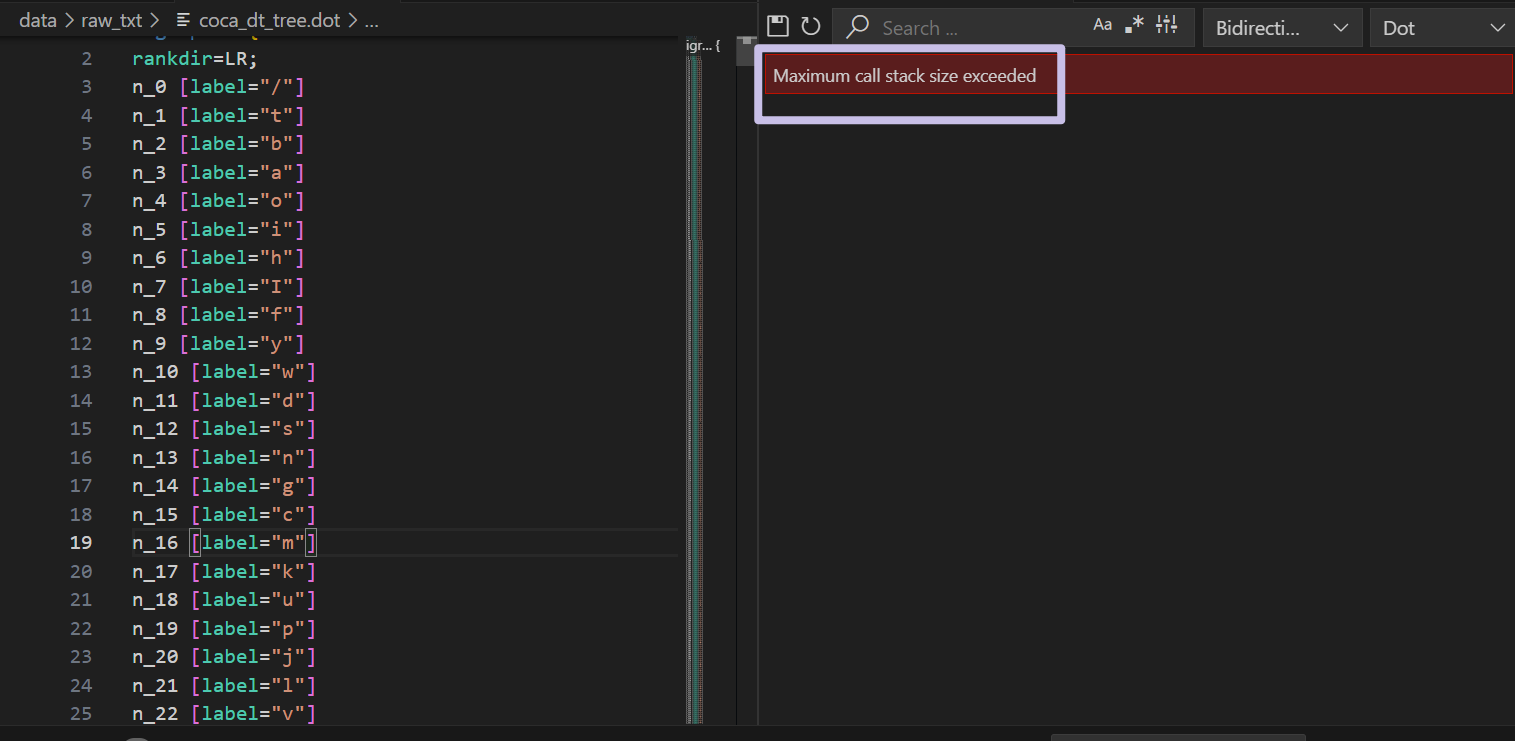
因為這個文件太大了,有十幾萬行(定義的節點就有幾萬個了)。

所以還是在本地來生成,我已經配置好了 graphviz 的環境了。一開始是生成的 png 格式,不過它提示分辨率有問題,因為節點太多了,導致生成的圖形其實沒法觀看了。所以最終還是選擇了 svg 和 pdf 格式,其中 pdf 格式生成的特別慢,至少是 20 分鐘以上了。

生成的 svg 和 pdf

這兩個文件的渲染都特別費勁,我的電腦打開有點吃力了。


對它的理解
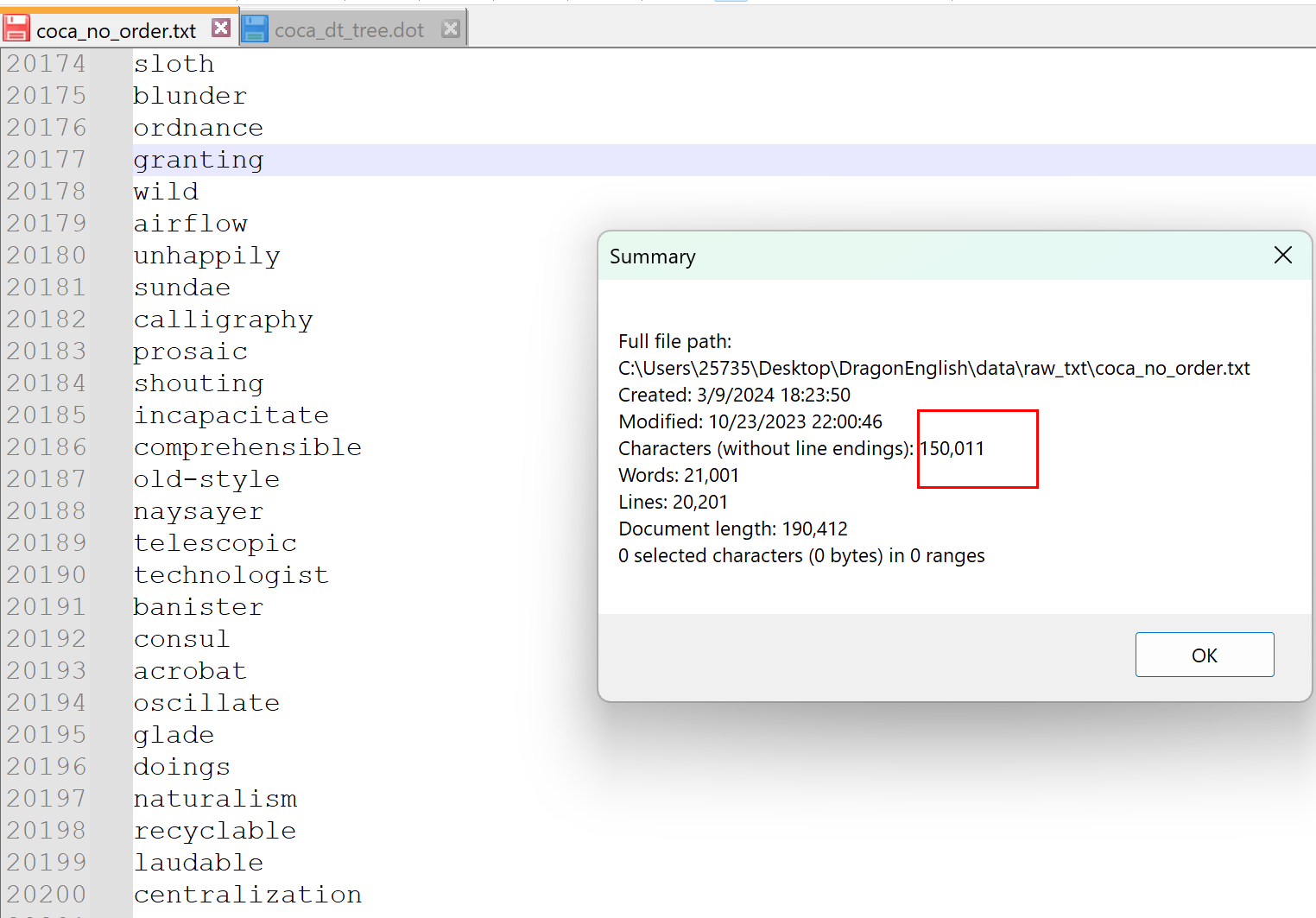
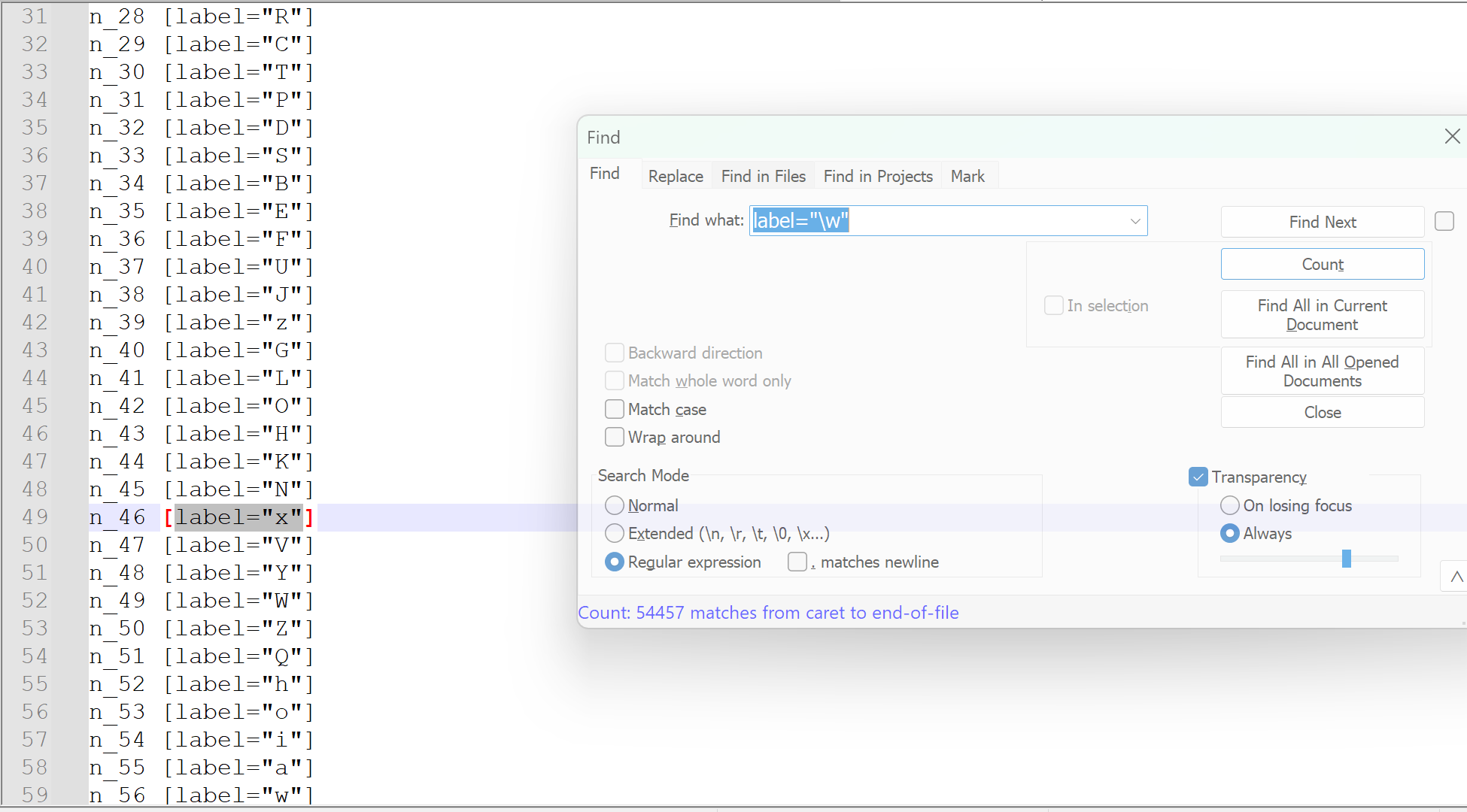
如果是這 20000 個單詞,它們的字母數是 150011 個,這是一個十分龐大的數字了。但是觀察上面的字典樹可以發現,其實有些單詞是含有共同部分的,在計算的時候可以省去這部分,對于字典樹來說就是計算其中的節點數就行了。因為我把完整的單詞也算做節點了,所以要只計算單個字母的節點,這里我使用正則表達式來計算,最終的結果是: 54457 個。我覺得它對于我們記憶單詞有一個很好的啟示,那就是我們記憶單詞并不是孤立的記憶每一個單詞,每個單詞之間是有聯系的,隨著記憶的單詞越多,對于單詞的掌握應該也是越來越熟悉的,但是太少了還是看不出來。而且這里只有前綴的聯系,實際上還包括后綴的聯系等。我會把這篇博客中產生的文件上傳到 CSDN 中,如果有感興趣的同學也可以自己下載體驗。
)

?)






![【Qt秘籍】[008]-Qt中的connect函數](http://pic.xiahunao.cn/【Qt秘籍】[008]-Qt中的connect函數)


)




行為型模式---訪問者模式(visitor))

