目錄
一.? 更復雜的新增
?二. 查詢
2.1 聚合查詢
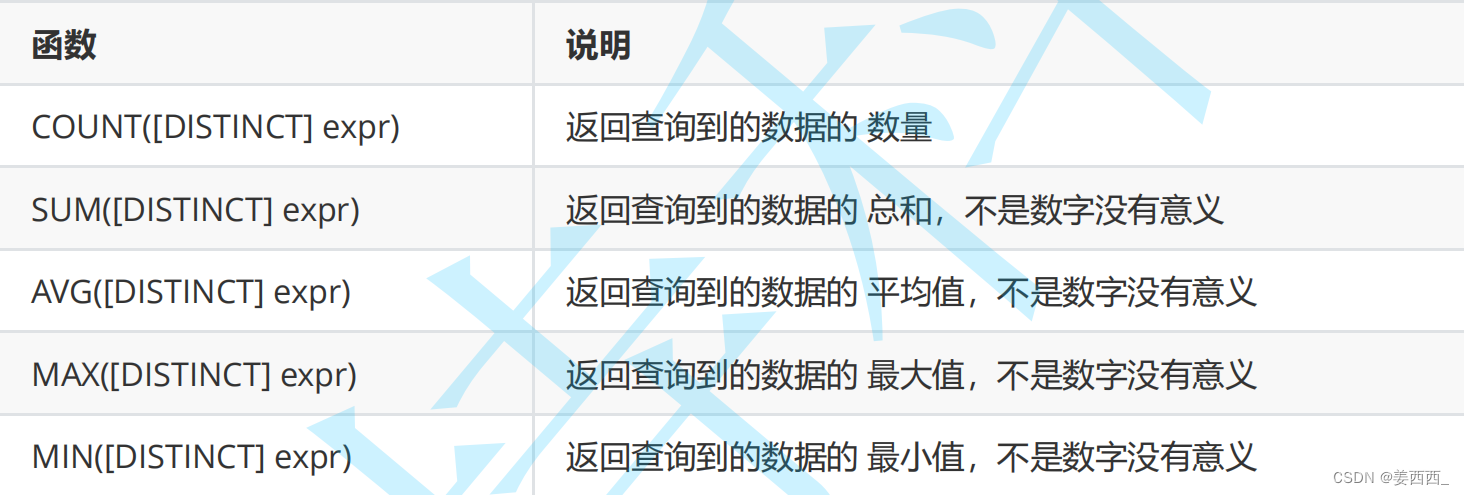
COUNT
SUM
AVG
MAX
?MIN
2.1.2?分組查詢? group by 子句
?2.1.3?HAVING
?2.2?聯合查詢/多表查詢
?2.2.1 內連接
2.2.2 外連接
2.2.3 全外連接
2.2.4 自連接
?2.2.5 子查詢
2.2.6 合并查詢
一.? 更復雜的新增
將從表名查詢到的結果插入到表名2中
insert into 表名2 select .. from 表名1 ...;
創建一個學生表:

創建一個學生表2, 將學生表中的數據加到學生表2中:
 ?注意: 列的類型可以匹配即可插入, 列名和列的類型不一定要完全一致
?注意: 列的類型可以匹配即可插入, 列名和列的類型不一定要完全一致
?二. 查詢
2.1 聚合查詢
前面談到的"表達式查詢", 是針對列和列之間的運算, 聚合查詢, 就是針對行和行之間的運算
對于行之間的運算, sql中提供了"聚合函數" 來完成這里的運算, 相當于是"庫函數"
COUNT
存在這樣的表:
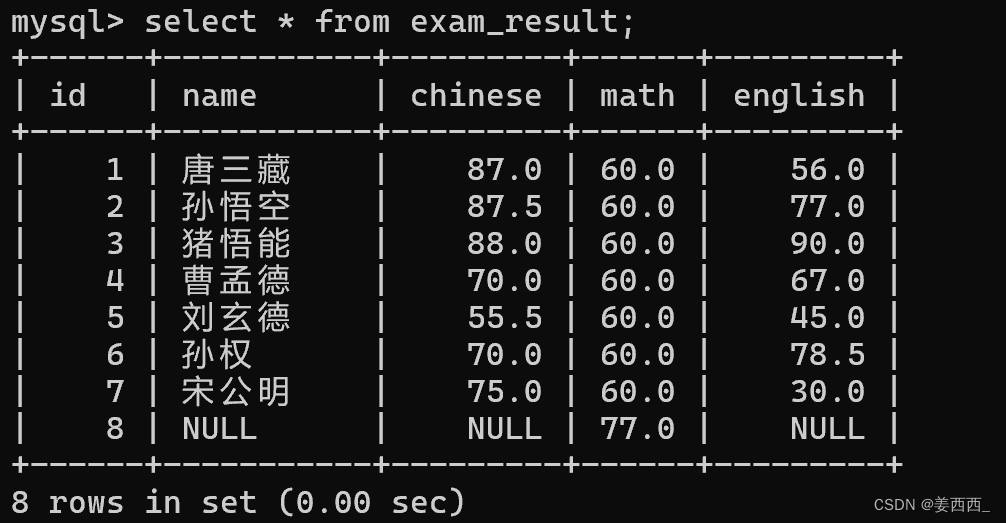

此時, 得到了表的全部行的數量
當前這個寫法, 就相當于先執行了select * from exam_result, 再對結果進行count聚合
如果寫具體的列, 就是針對這一列的結果進行聚合:
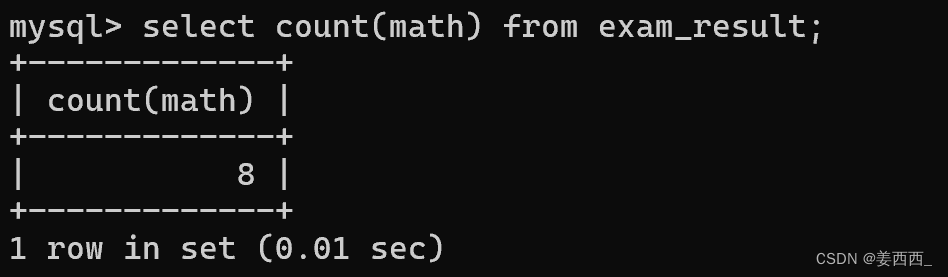
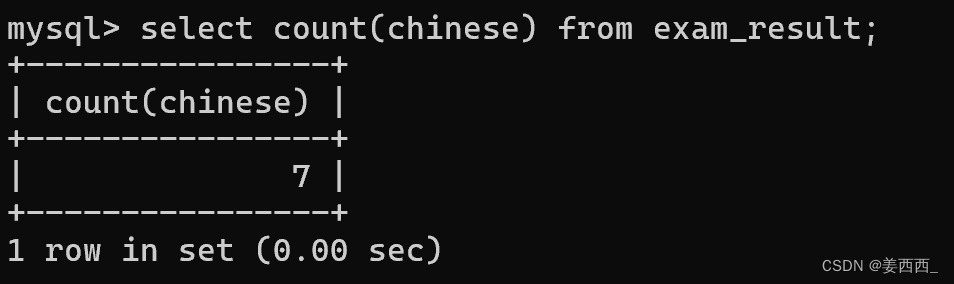 ?發現結果不同, 因為chinese有個空行
?發現結果不同, 因為chinese有個空行
結論: 針對某一列進行聚合的時候, 只關注這一列有多少非NULL的結果 而針對*進行聚合時, 則不再是否非NULL, 全部都記錄
如果在count和( )之間加個空格, 就會報錯
SQL語言大部分情況下對于空格和換行都是很有好的, 但是聚合函數的函數名和括號之間, 不能有空格

SUM

相當于先執行了select chinese?from exam_result, 再對結果進行sum聚合
括號中寫表達式也可以:
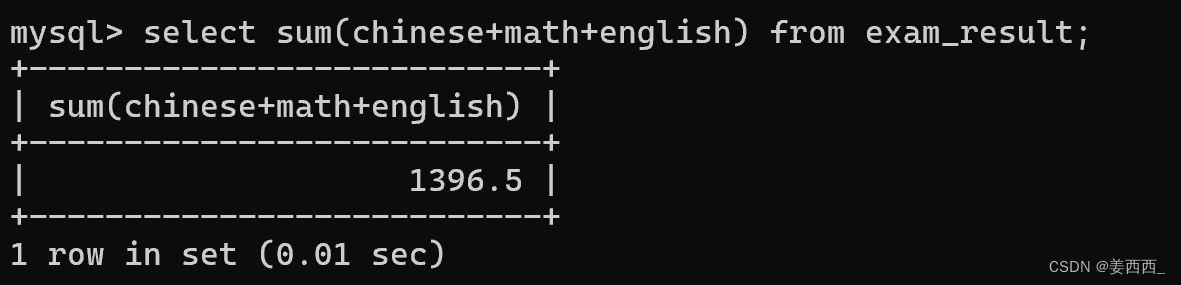
?相當于先執行了select chinese+math+english?from exam_result, 再對結果進行sum聚合
也可以進行帶有別名:

但不能把別名寫在括號中:

能用sum(*) 嗎?
顯然不可以
聚合函數中count(*) 其實是一種特殊情況, 只是單純的統計行數
sum和其他的聚合函數, 涉及到相加或其他計算, 語義上沒有明確定義, 不能用sum(*)
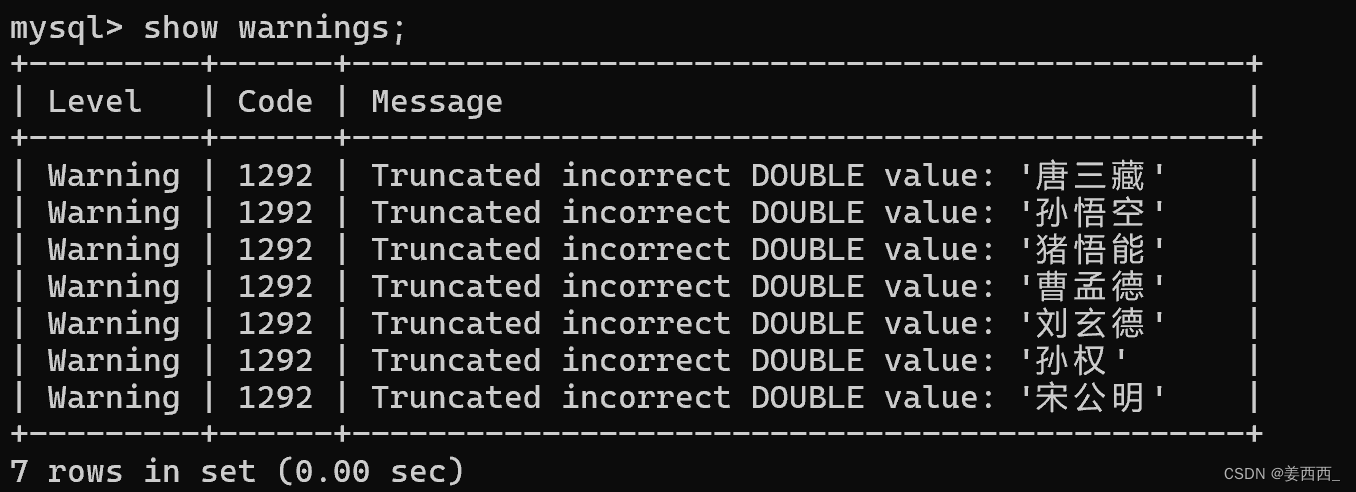
針對非數值的列, 進行加和, 雖然不會報錯, 但是結果是不正確的, 會報警告:
使用show warnings;? 可以查看警告
數據庫試圖將name轉換成double類型(因為SQL是弱類型語言), 但是失敗了
但是如果雖然是varchar類型, 但是你賦值為'1''2''3', 那也是可以相加的, 因為可以進行類型轉換


AVG

MAX

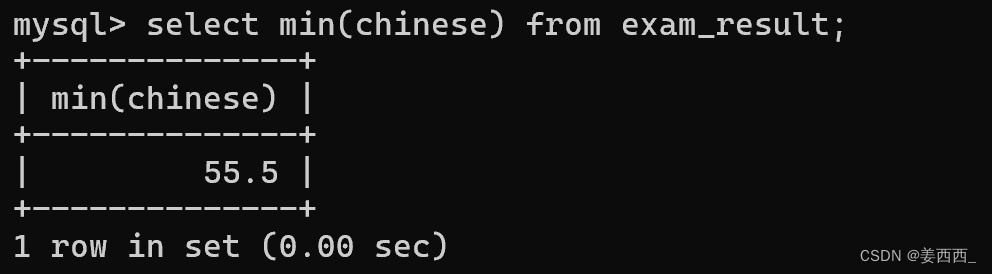
?MIN
2.1.2?分組查詢? group by 子句
指定某個列, 針對這個列, 把值相同的行, 分到同一個組中, 在針對每個組, 分別進行聚合查詢?
添加一個表:

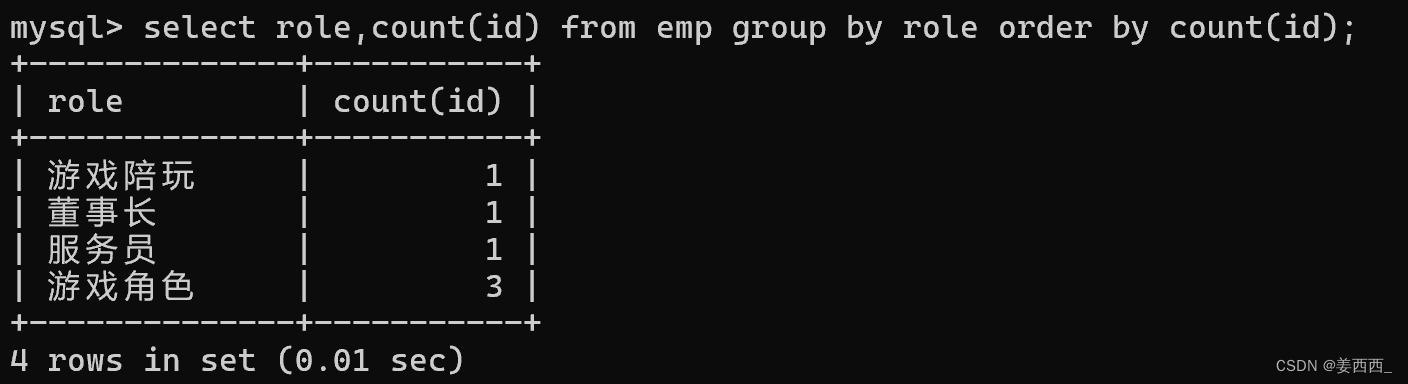
查詢每個角色下有幾個人:

?執行順序:
- ?先執行 select role,id from emp
- ?再根據group by role 設定, 按照role這一列的值, 針對上述查詢結果, 進行分組
分成服務員一組, 游戲陪玩一組, 游戲角色一組, 董事長一組 - ?針對上面的組, 分別執行count聚合操作
- ?將上面的結果整理成臨時表, 返回給客戶端即可
最終結果的臨時表, 這幾個分組的順序誰先誰后可不一定!!
可以針對聚合后的結果進行排序, 而不是干預每個分組中數據的先后順序:
注意:?使用 GROUP BY 進行分組查詢時,SELECT 指定的字段必須是“分組依據字段”,即group by 后面的列, 其他字段若想出現在SELECT 中則必須包含在聚合函數中。
如果這么寫:
每個顯示的結果, 都是每個分組中的其中一條記錄, 但是由于分組之后, 順序是不確定的, 當前你這里顯示的是哪行, 是不確定的, 存在一定的"隨機性", 因此就沒有意義

?2.1.3?HAVING
給聚合查詢指定條件:
1) 聚合之前的條件
查詢每個崗位的平均工資, 但是刨除"馬云"

where寫在group by 前面
2) 聚合之后的條件
查詢每個崗位的平均工資, 但刨除平均工資超過10000的數據
此時, 篩選聚合之后的條件, 就不能用where, 需要用having:

此時having放在group by 后面?
當然, 一個sql中, 上述兩種條件, 都可以存在:
計算每個崗位的平均工資, 刨除"馬云", 也刨除平均工資超過10000的:

?2.2?聯合查詢/多表查詢
上面介紹的都是單表查詢
想要學習多表查詢, 我們先要了解一下"笛卡爾積"的概念
笛卡爾積, 就是得到了一個更大的表, 列數, 是原來兩個表列數的和, 行數, 是原來兩個表列數的積
在sql中, 我們很方便通過select 完成笛卡爾積:
先創建兩個表student 和 class

笛卡爾積:

但是, 笛卡爾積是全排列的過程, 窮舉出了所有的可能性, 自然就會產生以下不符合實際的情況的數據, 例如上述笛卡爾積中, classId只有一個, 只有相同的才是有效數據
那么我們可以加上條件:?

這樣寫, 會產生二義性, 因為兩個列名是相等的, 那么我們可以通過?表名. 列名?的方式訪問各自的列
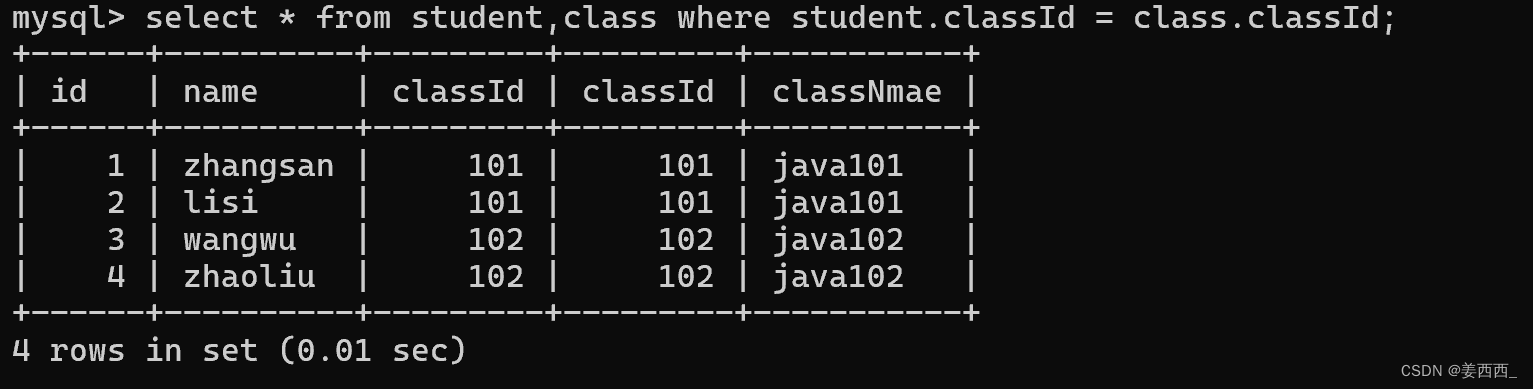
?這個就是多表查詢/聯合查詢的sql
像?where student.classId = class.classId 這種專門用來篩選出有效數據的條件, 也稱為"連接條件", 上述多表查詢的操作, 也可以稱為"連接操作".
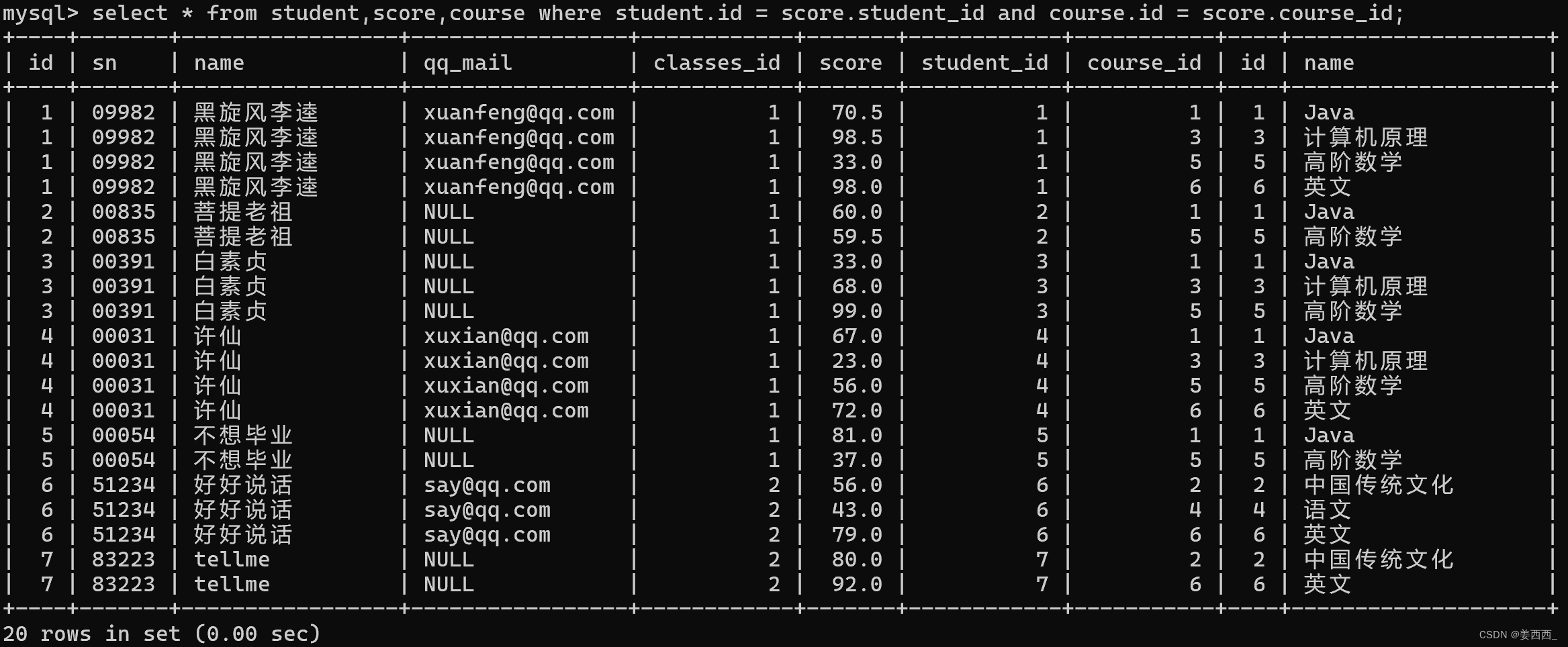
創建四張表:

1) 查詢'許仙'同學的成績
第一步: 先確定要查詢的信息來自哪些表
許仙同學的名字在學生表中, 成績在分數表中, 所以要針對學生表和分數表進行聯合查詢
第二步: 針對這兩個表進行笛卡爾積
學生表是8條記錄, 分數表是20條記錄, 笛卡爾積應該有160條記錄
第三步: 加上連接條件, 去掉無效數據
第四步: 再根據題目, 補充其他的條件
第五步: 去掉不必要的列
因為題目要求只要許仙的成績

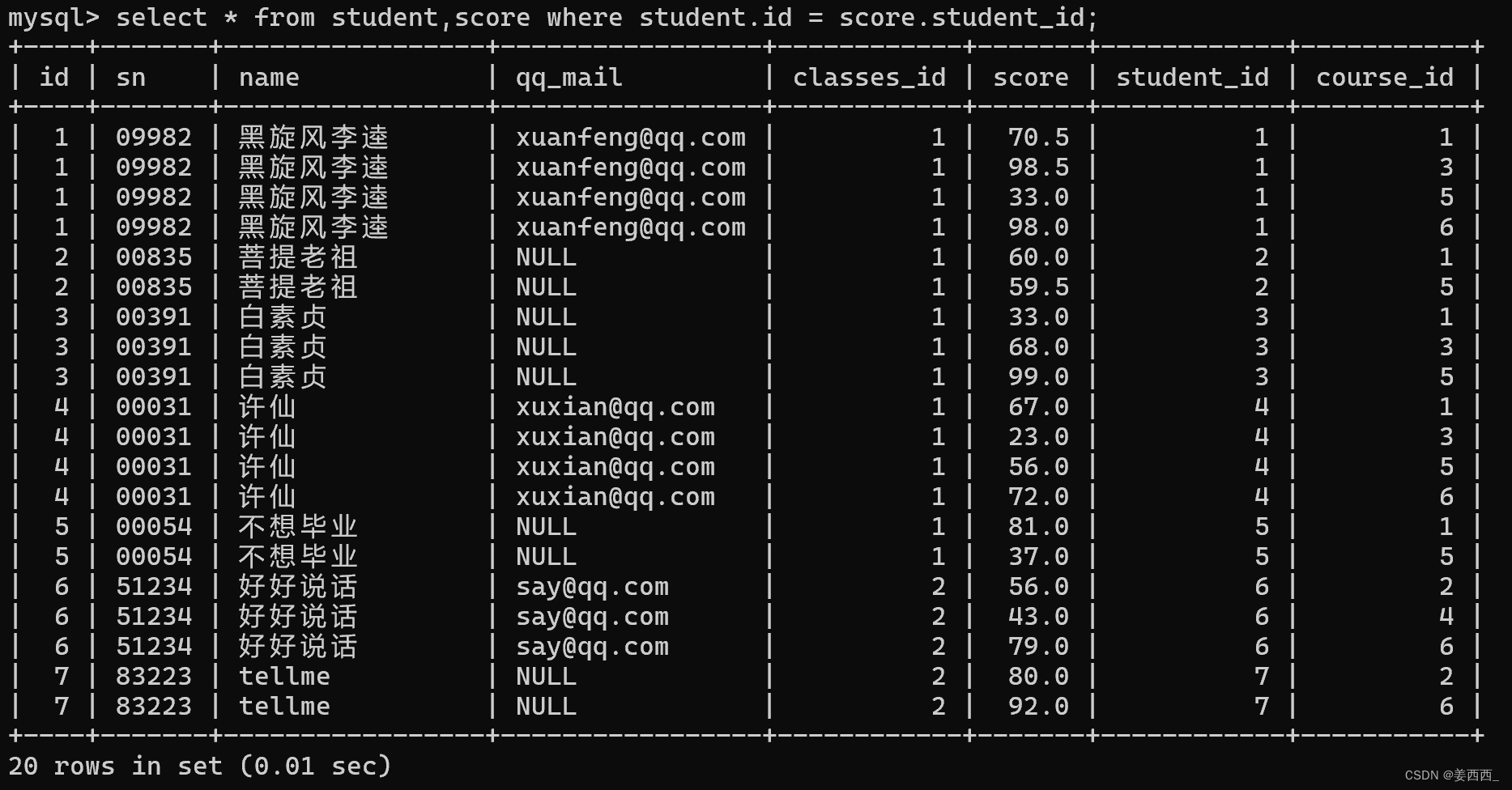
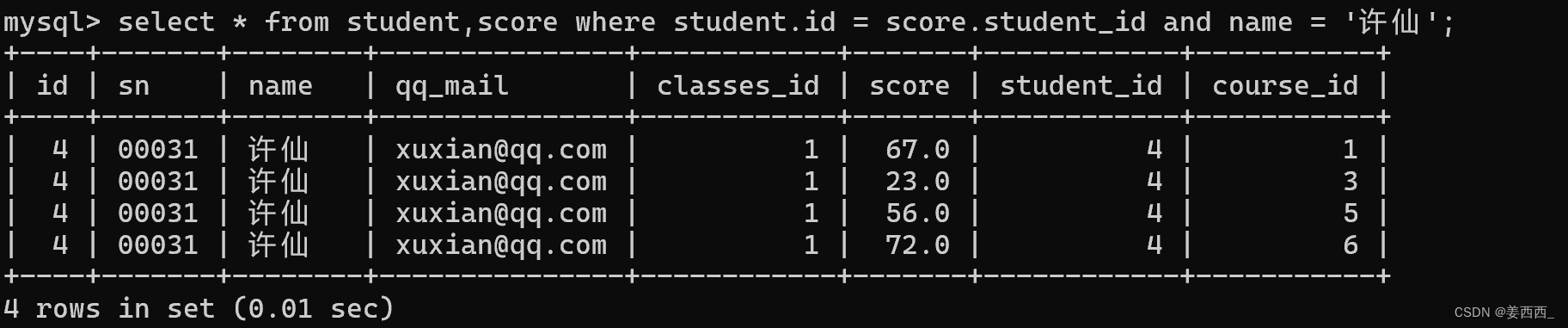

2) 使用join ... on? 多表查詢的另一種寫法
第一步: 確認信息來自學生表和分數表
第二步: 笛卡爾積(用join實現笛卡爾積)
第三步: 指定連接條件(用on 代替where)
?第四步: 補充其他條件
第五步: 保留必要列, 去掉其他列




3) 查詢所有同學的總成績
第一步: 信息出自學生表 分數表
第二步: 學生表和分數表進行笛卡爾積
第三步: 指定連接條件
第四步: 添加其他條件, 此處需要添加聚合操作, 按照學生的姓名進行分組
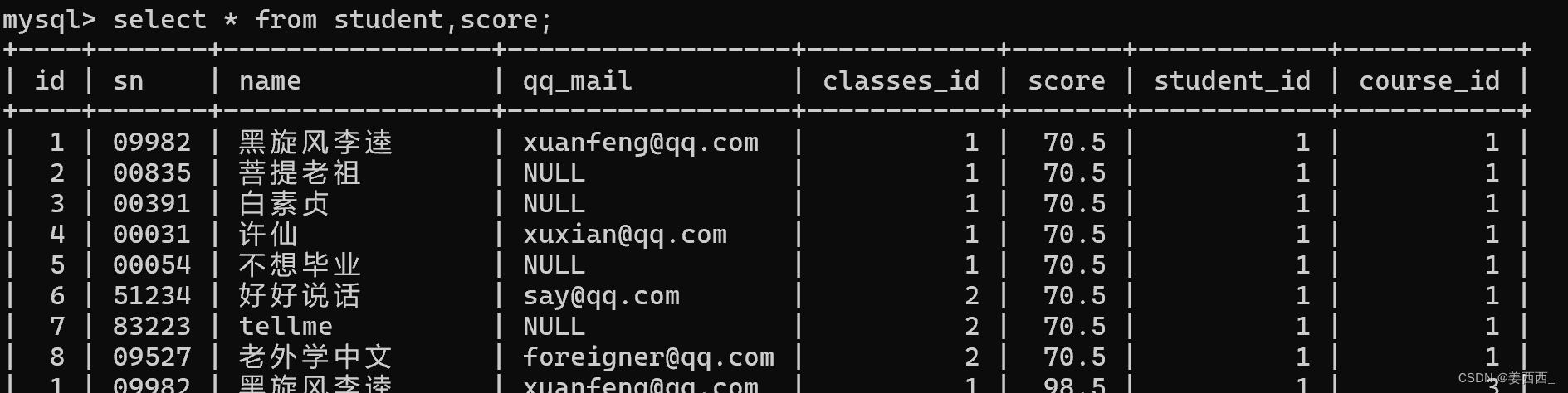
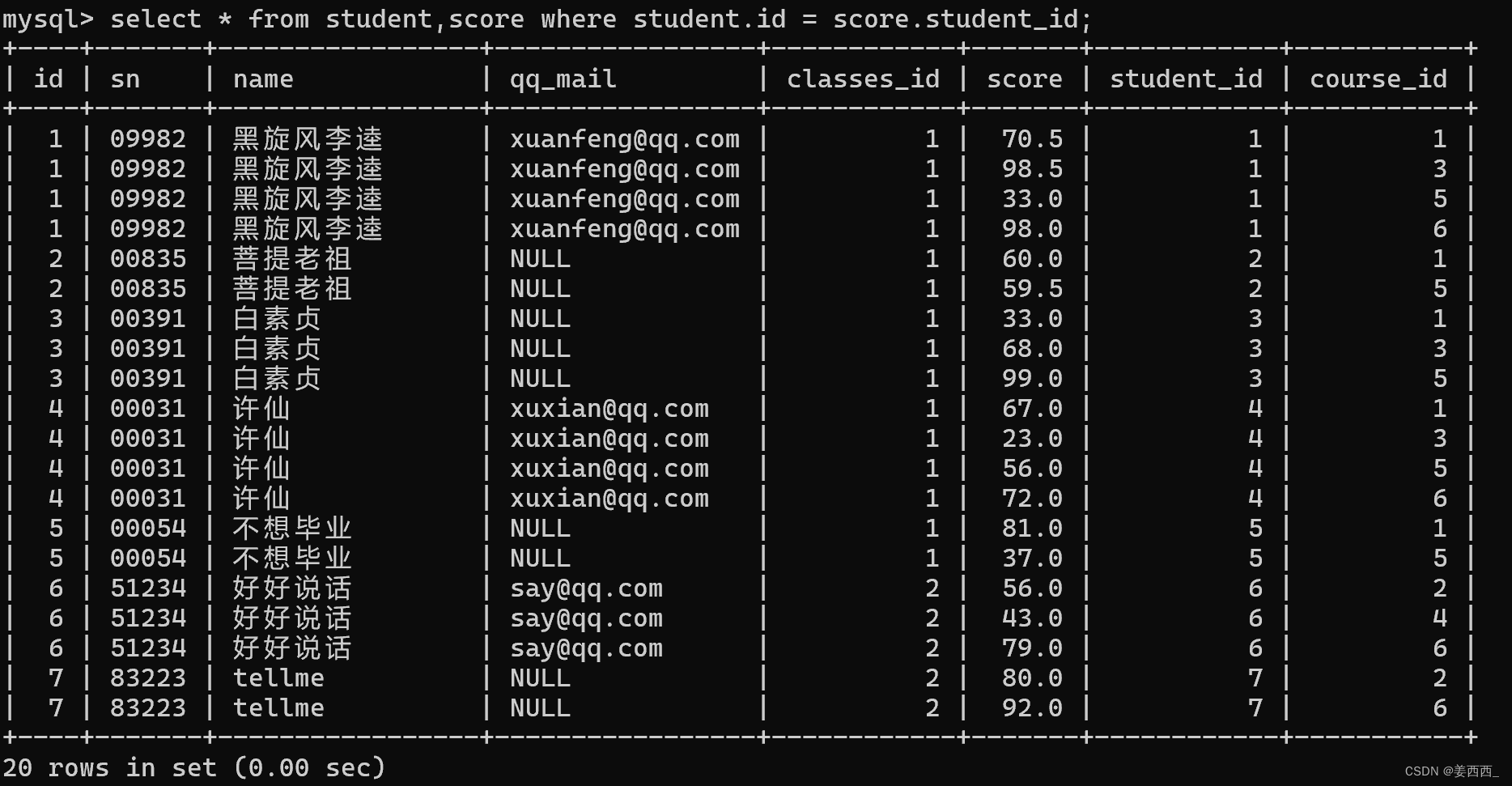

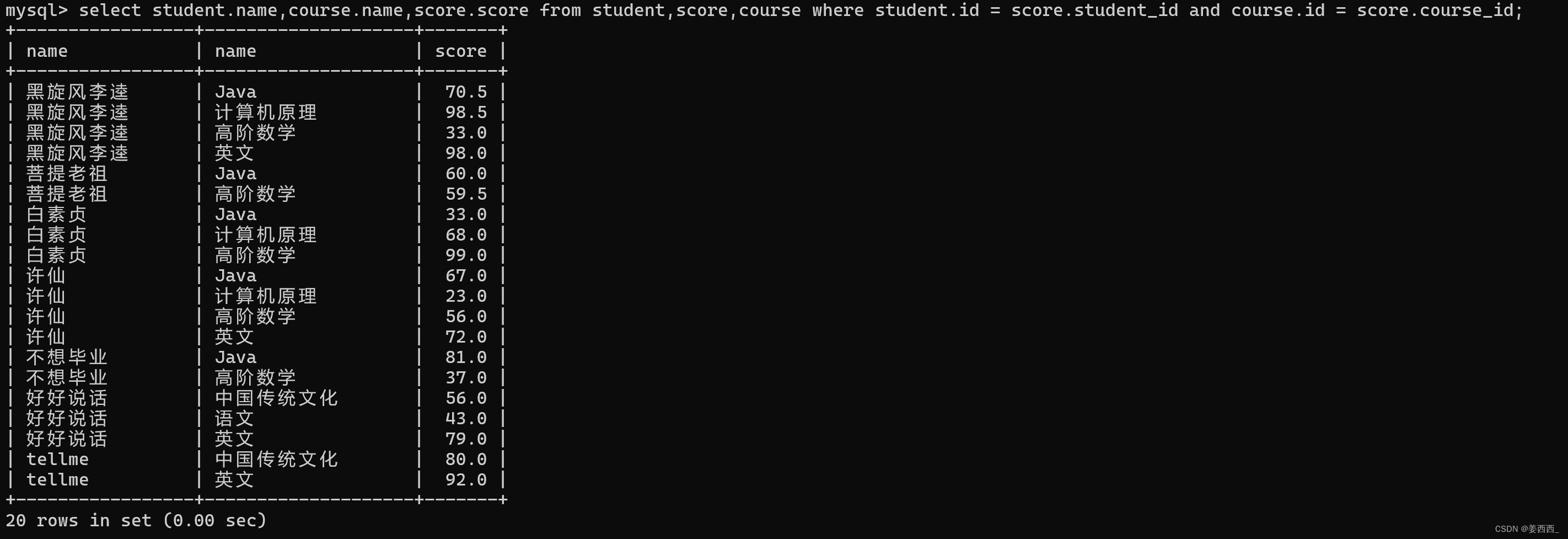
?4) 列出同學的成績, 課程的名字, 課程的成績
第一步: 信息來自三個表, 學生表, 課程表, 分數表
第二步: 笛卡爾積
第三步: 指定連接條件
第四步: 對列進行精簡
針對多張表查詢, 使用join on 可讀性更好

?2.2.1 內連接
上述我們所有的鏈接都是內連接?
select * from 表1,表2 where 連接條件
select * from 表1 (inner) join 表2 on 連接條件
2.2.2 外連接
select * from 表1 left/right join 表2 on 條件....;
注意: 只能使用join ..on.., 在join的前面加上left / right 關鍵字, 表示"左外連接" 和 "右外連接"
?外連接和內連接一樣, 也是基于笛卡爾積的方式來計算的, 但是對于空值/不存在的值, 處理方式是存在區別的
1)對于數據"一一對應"的情況
對于學生表和分數表,
任何一個學生數據, 都能在分數表中找到分數結果
任何一個分數結果, 也能在學生表中找到名字信息
此時, 進行內連接和外連接, 效果是一樣的
??簡單創建兩張表:
內連接:
外連接: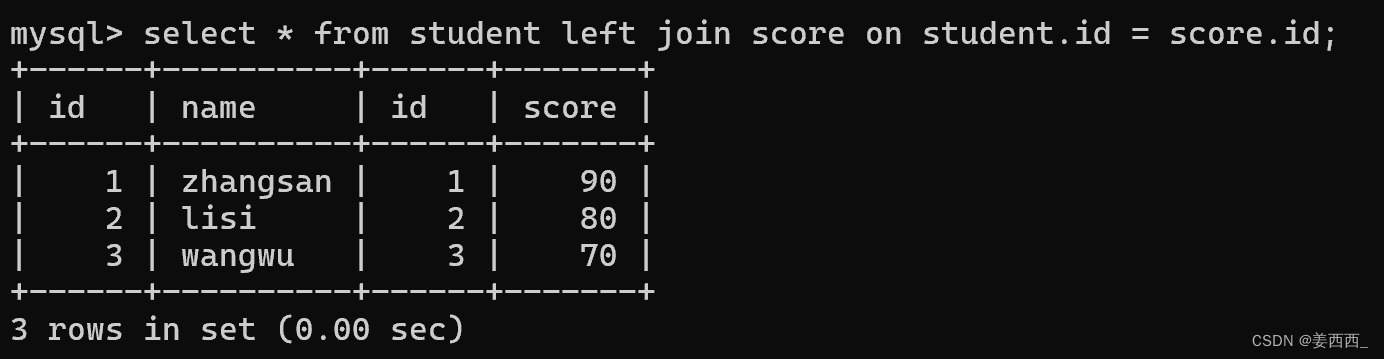
2)對于數據"非一一對應"的情況?
?如果我們對上述數據進行調整:
此時, wangwu的分數信息, 在分數表中不存在了
分數表中, id為4的信息, 在學生表中也不存在
內連接:
此時, 得到的結果, 是包含在兩個表中都有的數據
左外連接: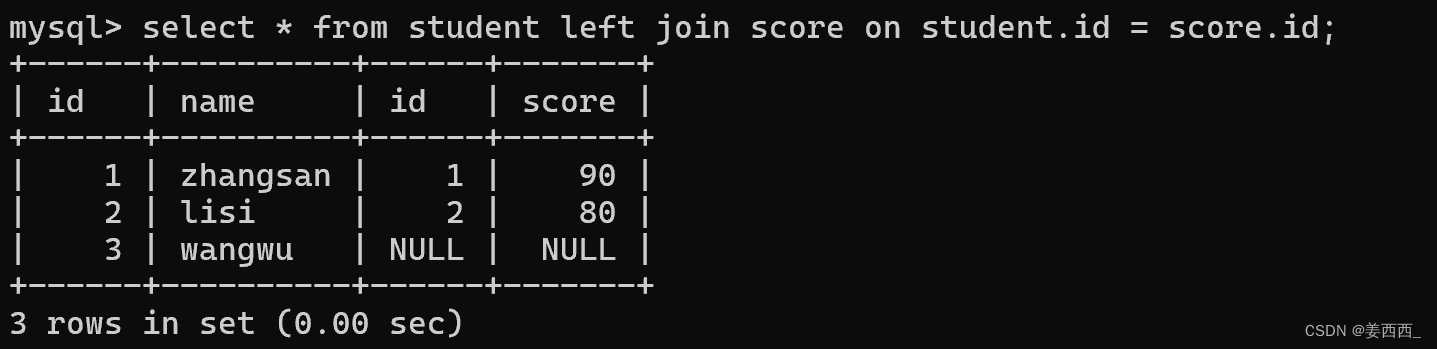
對于左外連接, 以左側的表為基準, (寫作student left join score, 此時student就是左側表, score就是右側表), 保證左側表中的每一個數據, 都會存在, 左側表數據在右側表不存在的列, 會用null填充
右外連接:
右外連接與左外連接類似, 以右側表為基準, 使右表中的每個數據都存在, 對應坐標中不存在的數據都用null填充
2.2.3 全外連接
結合左連接和右連接
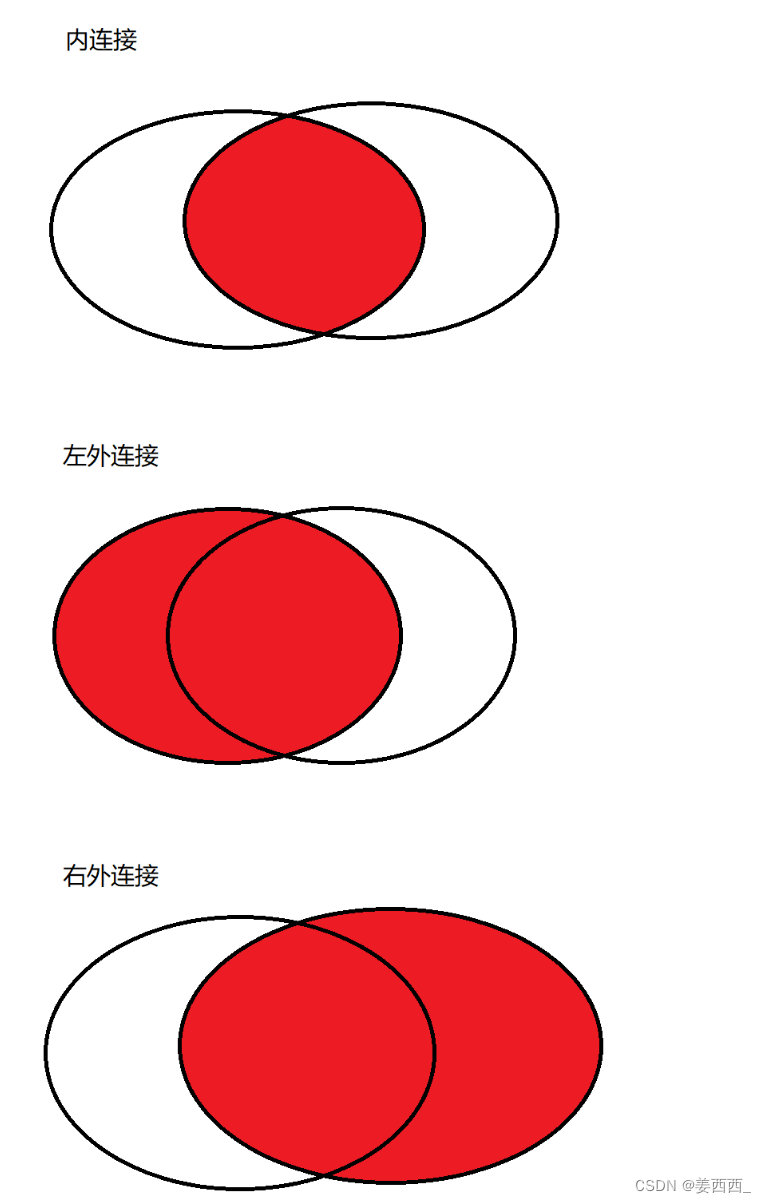
站在集合的角度看待上述幾種鏈接:

2.2.4 自連接
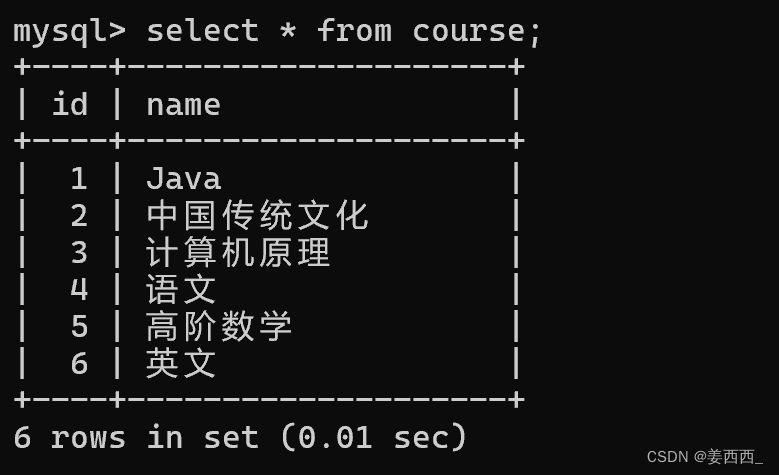
同一個表, 自己和自己計算笛卡爾積
例:
還是使用上面的表
顯示所有"計算機原理"成績比"java"成績高的成績信息
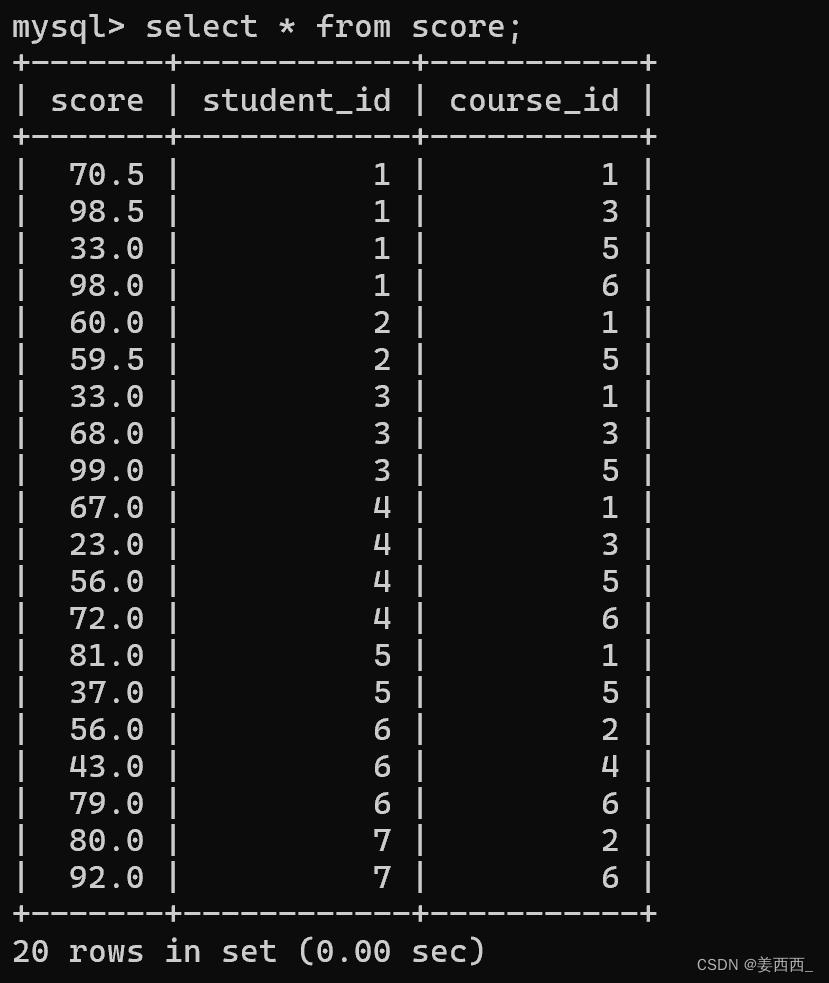
我們想要比較的是同一個學生的3號課程比1號課程成績高的數據, 發現我們要比較的score在不同的行中, 之前我們進行的各種條件查詢, 都是基于列和列之間的比較, 聚合函數時行和行之間的運算, 沒法進行行和行之間的比較, 這時我們就要想辦法將行和行之間的關系, 轉化成列和列之間的關系, 此時, 自連接就出現了
當我們直接進行自連接時, 發現會報錯:
此時我們要給表起個別名:
繼續添加條件:
?2.2.5 子查詢
把多個sql嵌套成了一個sql
1) 單行子查詢: 返回一行記錄的查詢
查詢"不想畢業"同學的同班同學:
先知道"不想畢業"同學的班級, 再去找同班同學
子查詢:
將得出的單條記錄直接用sql語句代替
2)多行子查詢: 返回多條記錄的子查詢 用in關鍵字
查詢"語文"或"英文"課程的成績信息:
先知道"語文"或"英文"的課程id, 再去找成績:
?
子查詢:

用in()來圈定范圍
2.2.6 合并查詢
把多個查詢結果合并到一起, 使用union關鍵字
查詢id<3,或者名字為"英文"的課程
?另外, union允許從不同的表分別查詢, 只要每個表查詢的結果集合列的類型和列的個數匹配, 都能合并, 列的名字無所謂, 但是or只能針對一個表
union在合并是會自動去重, 如果不想要去重操作, 可以使用union all

)
![【Qt秘籍】[009]-自定義槽函數/信號](http://pic.xiahunao.cn/【Qt秘籍】[009]-自定義槽函數/信號)





)





、Map】)

)
![[AIGC] 使用Flink SQL統計用戶年齡和興趣愛好](http://pic.xiahunao.cn/[AIGC] 使用Flink SQL統計用戶年齡和興趣愛好)
——類 第三篇)
)