1 Embedding表征學習的總體架構
目前,推薦算法精排模型大多基于Embedding + MLP范式,模型底層是Embedding層,作用是將高維稀疏的輸入特征轉換為低維稠密的特征向量,并實現一定的模糊查找能力。模型上層是MLP層,作用是對特征向量進行交叉和融合,并提取高階信息,得到最終輸出。Embedding作為推薦模型的第一層,擁有絕大多數參數,意義重大。
Embedding表征學習分為向量構建和向量檢索兩部分。向量構建主要實現Embedding從無到有的過程,其主要方法有序列化建模、圖模型構建和端到端學習。向量檢索主要解決Top K近鄰Embedding檢索問題,其主要方法有哈希算法、基于樹的算法、向量量化算法和近鄰圖算法等。
推薦算法Embedding表征學習的知識框架如圖1所示。
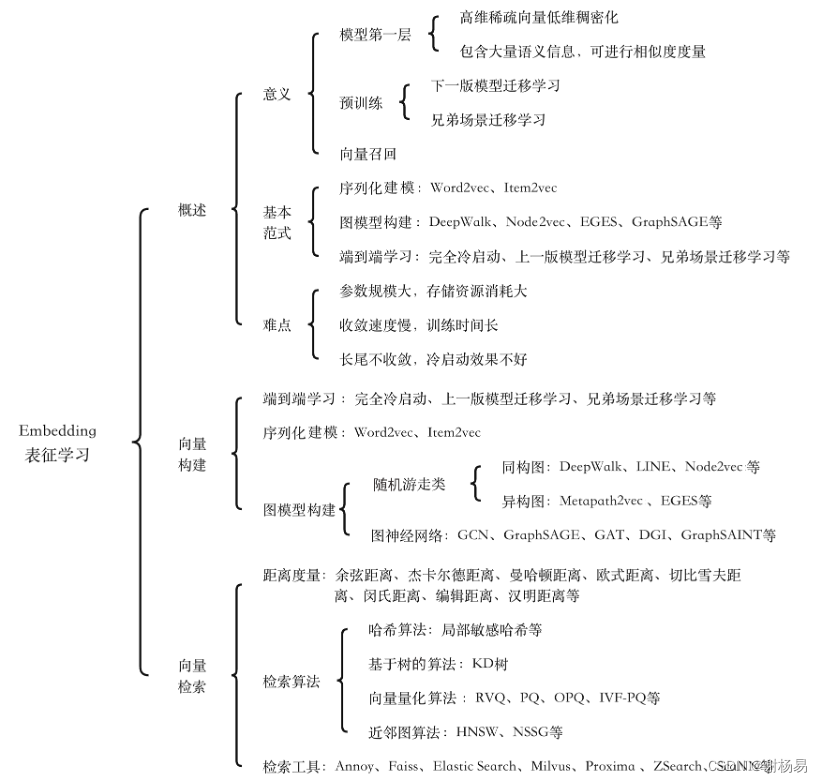
圖1 ?Embedding表征學習的知識框架
2? Embedding概述
Embedding常被稱為“嵌入”或“向量”,它可以將高維稀疏特征轉換為低維稠密向量,實現降維,其最典型的應用是自然語言處理中的詞向量(Word Embedding)。通過Embedding,我們可以將單詞間的語義關系轉換為向量間的距離關系。例如“書籍”和“書本”,兩者語義很相似,詞向量的余弦距離也很接近。
在推薦系統中,每個特征值都可以被向量化。例如用戶ID、用戶性別、物品ID和物品類目等。特征值的物理含義越接近,其Embedding向量距離越短。例如在電商場景中,“拖鞋”和“皮鞋”兩個商品類目特征的向量距離,比“拖鞋”和“紙巾”要小,如圖2所示。

圖2 ?特征值物理含義越接近,Embedding向量距離越短
在深度學習中,Embedding可以通過一個全連接層實現。 原始輸入數據通常是一個獨熱編碼向量。由于輸入數據一般是獨熱向量,因此全連接可以退化為一個查表操作。
3 Embedding表征學習的意義
Embedding是大多數推薦算法模型的第一層,其訓練質量在很大程度上決定了模型的成敗。Embedding表征學習已經在召回和排序等領域得到了廣泛應用,意義重大,主要如下。
- Embedding是模型的第一層,可以將高維稀疏的輸入特征轉換為低維稠密的特征向量,輸入上層全連接神經網絡。同時,它包含大量語義信息,可以很好地度量特征間的相似度,并具備一定的模糊查找能力。一般來說,兩個特征越相似,其Embedding向量距離越短。
- Embedding可以用于預訓練。為了加快訓練速度,可以將當前模型的Embedding作為下一版模型或者兄弟場景模型的預訓練參數,從而實現熱啟動(Warm Start)。Embedding一般擁有推薦模型的絕大部分參數,因此模型訓練速度往往取決于Embedding的收斂速度。預訓練Embedding可以加快模型訓練速度,并減少對樣本量的依賴。另外,對于長尾特征Embedding難收斂的問題,預訓練一般也能起到一定作用。
- Embedding可以應用在召回和排序等很多領域。利用Embedding向量可以計算任意用戶和物品的相似度,從而為目標用戶推薦與其距離最近的Top K物品,這就是典型的u2i召回。Embedding還可以計算物品和物品間的相似度,從而基于目標用戶點擊過或購買過的物品,推薦與之最相似的Top K物品,這就是典型的i2i召回。需要注意的是,不要直接把排序模型的Embedding用在召回任務上,二者的候選集和優化目標差別很大。
4 ?Embedding表征學習的基本范式
Embedding訓練一直以來都是推薦算法中的難點,因為其參數規模很大,導致收斂速度慢。Embedding的訓練方法主要有以下幾種。
- 端到端學習。最簡單的方法是將Embedding層參數隨機初始化,然后和模型其他層一起訓練。這種方法的一致性很好,可以保證Embedding與模型其他層的目標完全一致,但缺點也很明顯,主要是整體訓練速度受限于Embedding的收斂速度,且需要大量樣本。除了隨機初始化,還可以利用上一版模型或者兄弟場景模型對Embedding參數初始化,然后微調(Finetune),從而加快模型收斂速度。
- 序列化建模。類似于自然語言處理中的Word2vec,基于Skip-gram或CBOW算法對用戶行為序列構建正負樣本并訓練模型,最終得到Embedding。Item2vec便采用了這種方法,6.2節會重點闡述。
- 圖模型構建。先利用用戶行為構建用戶和物品關系圖,然后訓練模型并得到圖節點的Embedding,主要有游走類和圖神經網絡兩種方式。其中,游走類可以利用物品ID構建同構圖,例如DeepWalk和Node2vec;也可以加入物品屬性特征,構建異構圖,例如Metapath2vec和EGES。圖神經網絡是一個很大的技術方向,也是目前推薦算法中比較前沿的技術,可以使用GraphSAGE、GAT、DGI、GraphSAINT和AdaGCN等經典模型,6.3、6.4、6.5節會重點闡述。

Skip-gram模型結構

DeepWalk的主要實現步驟

Metapath2vec和Metapath2vec++的Skip-gram網絡結構圖

EGES模型結構圖

GraphSAGE應用流程圖
5?Embedding表征學習的主要難點
Embedding表征學習的難點主要如下。
- 參數規模大,存儲資源消耗大。特別是用戶ID和物品ID等高維稀疏特征,其枚舉值很多,必須使用維度較高的Embedding向量才能對其進行充分表征。Embedding的維度一般建議取特征枚舉值個數的四次方根,枚舉值多,向量維度高,會導致參數規模過大。Embedding通常會占據模型體積的80%以上,消耗極多的存儲資源。
- 收斂速度慢,訓練時間長。從梯度下降反向傳播中可以看出,輸入特征為0的Embedding向量無法更新。特征輸入層往往比較稀疏,其他層則稠密得多,這導致Embedding層參數的訓練機會比其他層少很多。另外,Embedding層需要訓練的參數很多,這加劇了其收斂速度慢的問題。一般來說,模型整體訓練時間取決于Embedding層的收斂速度,預訓練Embedding對緩解這一問題有一定的作用。
- 長尾不收斂,冷啟動效果不好。長尾特征值在樣本中出現的概率低、數據稀疏,容易出現不收斂的問題,特別是對于用戶ID和物品ID等高維特征,收斂難度更大,對冷啟動造成了很大影響。近幾年,Group Embedding方法的應用對緩解這一問題起到了一定的作用。


對URL的編碼和解碼方式以及重要性——IE瀏覽器必須對中文URL進行編碼)

)


協會亮相香港國際葡萄酒和烈酒展覽會)
 qml誕生的原因 和Qt Creator開發環境的介紹)





——Linux系統中的常用命令)




