隨著深度學習的發展,語音識別由DNN-HMM時代發展到基于深度學習的“端到端”時代,這個時代的主要特征是代價函數發生了變化,但基本的模型結構并沒有太大變化。總體來說,端到端技術解決了輸入序列長度遠大于輸出序列長度的問題。
采用CTC作為損失函數的聲學模型序列不需要預先將數據對齊,只需要一個輸入序列和一個輸出序列就可以進行訓練。CTC關心的是預測輸出的序列是否和真實的序列相近,而不關心預測輸出的序列中每個結果在時間點上是否和輸入的序列正好對齊。CTC建模單元是音素或者字,因此它引入了Blank。對于一段語音,CTC最后輸出的是尖峰的序列,尖峰的位置對應建模單元的Label,其他位置都是Blank。
Sequence-to-Sequence方法原來主要應用于機器翻譯領域。2017年,Google將其應用于語音識別領域,取得了非常好的效果,將詞錯誤率降低至5.6%。如圖1-4所示,Google提出的新系統框架由三部分組成:Encoder編碼器組件,它和標準的聲學模型相似,輸入的是語音信號的時頻特征;經過一系列神經網絡,映射成高級特征henc,然后傳遞給Attention組件,其使用henc特征學習輸入x和預測子單元之間的對齊方式,子單元可以是一個音素或一個字;最后,Attention模塊的輸出傳遞給Decoder,生成一系列假設詞的概率分布,類似于傳統的語言模型。

而隨著Whisper語音轉換模型的推出開啟了可以用于實際任務的端到端(Task End-to-End)的時代。Whisper是一種自動語音識別(Automatic Speech Recognition,ASR)系統,旨在將語音轉換為文本。作為一款多任務模型,它不僅可以執行多語言語音識別,還可以執行語音翻譯和語言識別等任務。Whisper采用了Transformer架構的編碼器-解碼器模型,使其在各種語音處理任務中表現出色。Whisper模型架構如圖1-5所示。
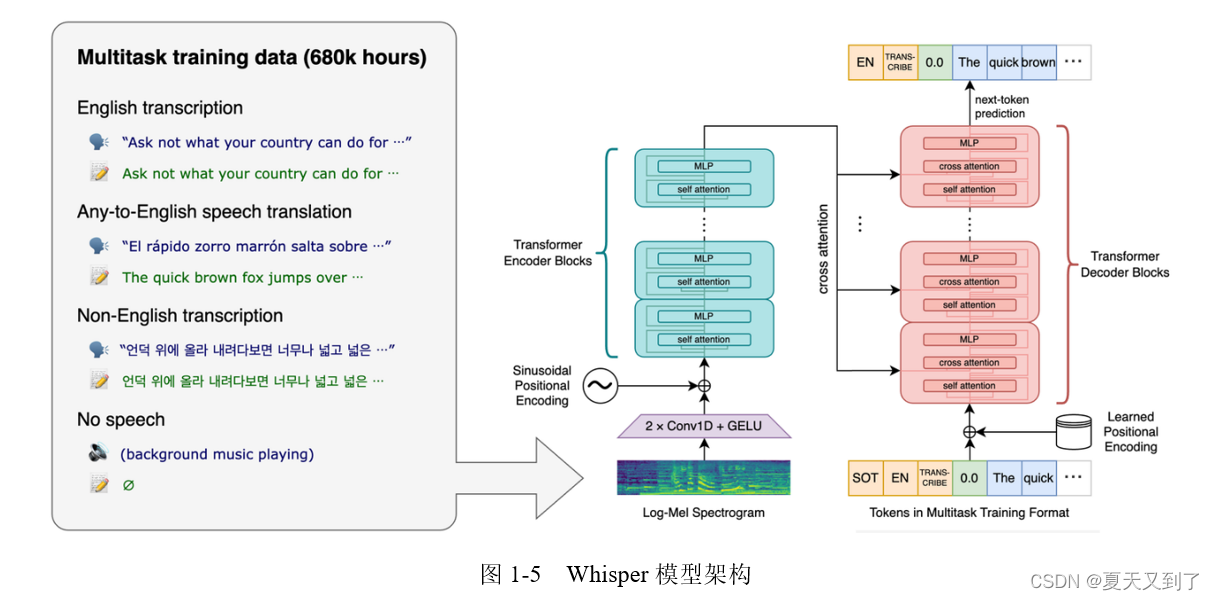
Whisper的核心技術在于其端到端的架構。輸入的語音首先被分成30秒的模塊,然后轉換為log-Mel頻譜圖,再通過編碼器計算注意力,最后將數據傳遞給解碼器。解碼器被訓練用來預測相應的文本,并添加特殊標記,用于執行諸如語言識別、多語言語音轉錄和英語語音翻譯等任務。Whisper還在Transformer模型中使用了多任務訓練格式,利用一組特殊的令牌作為任務說明符或分類目標。Whisper的優點在于其強大的語音識別能力,能夠處理各種口音、背景噪聲和技術語言。
隨著端到端技術的突破,深度學習模型不再需要對音素內部狀態的變化進行描述,而是將語音識別的所有模塊統一成神經網絡模型,使語音識別朝著更簡單、更高效、更準確的方向發展。
本文節選自《PyTorch語音識別實戰》,獲出版社和作者授權發布。
《PyTorch語音識別實戰(人工智能技術叢書)》(王曉華)【摘要 書評 試讀】- 京東圖書 (jd.com)



)



)









)


