1.Redis內存管理
我們的redis是一個內存型數據庫,我們的數據也都是放在內存中的,內存是有限的空間,當數據滿了之后,我們要怎么樣繼續保證redis的可用性呢?我們就需要采取點管理措施和機制來保證我們redis的可用性。
在redis.conf中通過maxmemory來配置
maxmemory 100mb? // 如果配置是0 那么默認是電腦的內存, 如果是32bit 隱式大小為3G
在Redis中有兩個核心的機制來保證我們的可用性: Redis過期策略、Redis淘汰機制
2. Redis過期策略
那么什么是過期策略。首先,我們知道Redis有一個特性,就是Redis中的數據我都是可以設置過期時間的,如果時間到了,這個數據就會從我們的Redis中刪除。
那么過期策略,就是講的是我怎么把Redis中過期的數據從我們Redis服務中移除的。
我們可以類比一個例子,假如我們把Redis容器比作一個冰箱。冰箱里面也會放菜,菜就是我們的數據,數據跟菜都會過期。那么我們冰箱里面假如有菜過期了,我們一般是怎么發現的呢?
2.1 惰性過期
我們在準備拿冰箱里的食物吃的時候,我們就會先去看下,這個東西有沒有過期,如果過期了就仍掉。
那么在Redis里面,就是每次在訪問操作key的時候,判斷這個key是不是過期了,如果過期了就刪除。
源碼驗證 expireIfNeeded方法(db.c文件)
int expireIfNeeded(redisDb *db, robj *key) {if (!keyIsExpired(db,key)) return 0;/* If we are running in the context of a slave,instead of* evicting the expired key from the database, wereturn ASAP:* the slave key expiration is controlled by themaster that will* send us synthesized DEL operations for expiredkeys.** Still we try to return the right information to thecaller,* that is, 0 if we think the key should be stillvalid, 1 if* we think the key is expired at this time. *///如果配置有masterhost,說明是從節點,那么不操作刪除if (server.masterhost != NULL) return 1;/* Delete the key */server.stat_expiredkeys++;propagateExpire(db,key,server.lazyfree_lazy_expire);notifyKeyspaceEvent(NOTIFY_EXPIRED,"expired",key,db->id);//是否是異步刪除 防止單個Key的數據量很大 阻塞主線程 是4.0之后添加的新功能,默認關閉int retval = server.lazyfree_lazy_expire ?dbAsyncDelete(db,key) :dbSyncDelete(db,key);if (retval) signalModifiedKey(NULL,db,key);return retval;
}
?每次調用到相關指令時,才會執行expireIfNeeded判斷是否過期。平時不會判斷是否過期。
優點: 該策略就可以最大化地節省CPU資源,因為它平時都懶得都判斷,所以也沒有啥cpu損耗,只有訪問的時候我才會去判斷一下
缺點: 對內存非常不友好。因為如果沒有再次訪問,該過期刪除的就可能一直堆積在內存里面!從而不會被清除,占用大量內存。
所以我們需要另外一種策略來配合使用,解決內存占用問題。就是我們的定期過期
2.2 定期過期
所謂定期過期,就是我們會每個星期或者每個月去清理一次冰箱,把冰箱里面過期的菜全部扔掉。
在Redis中,就是我也會定期去把過期的數據刪除。
那么究竟多久去清除一次呢,我們在講rehash的時候Redis數據結構擴容源碼分析_redis數據結構擴容機制-CSDN博客?有個方法是serverCron,執行頻率根據redis.conf中的hz配置
這方法除了做Rehash以外,還會做很多其它的事情,比如
- 清理數據庫中的過期鍵值對
- 更新服務器的各類統計信息,比如時間、內存占用、數據庫占用情況等
- 關閉和清理連接失效的客戶端
- 嘗試進行持久化操作
我們知道了多久會去掃描一下,那么接下來我們需要知道具體是怎么掃的
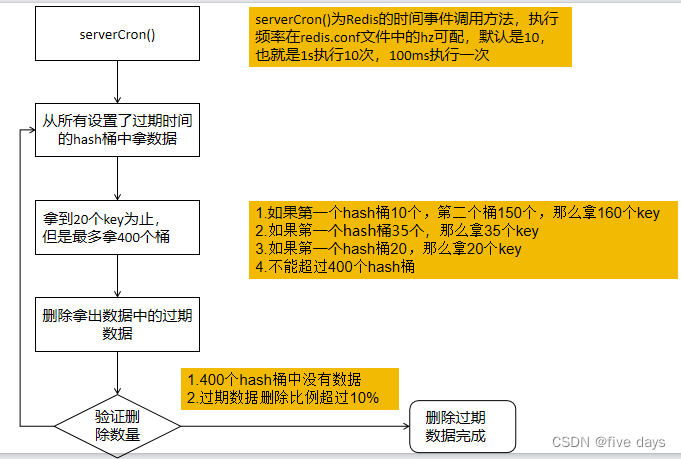
具體實現流程如下:
1. 定時serverCron方法去執行清理,執行頻率根據redis.conf中的hz配置 的值
2. 執行清理的時候,不是去掃描所有的key,而是去掃描所有設置了過期 時間的key(redisDb.expires)
3. 如果每次去把所有過期的key都拿過來,那么假如過期的key很多,就會 很慢,所以也不是一次性拿取所有的key
4. 根據hash桶的維度去掃描key,掃到20(可配)個key為止。假如第一個桶 是15個key ,沒有滿足20,繼續掃描第二個桶,第二個桶20個key,由 于是以hash桶的維度掃描的,所以第二個掃到了就會全掃,總共掃描 35個key
5. 找到掃描的key里面過期的key,并進行刪除
6. 如果取了400個空桶,或者掃描的刪除比例跟掃描的總數超過10%,繼續 執行4、5步。
7. 也不能無限的循環,循環16次后回去檢測時間,超過指定時間會跳出。
?實現流程圖如下:
3.Redis淘汰機制
? ? ?由于Redis內存是有大小的,并且我可能里面的數據都沒有過期,當快滿的時候,我又沒有過期的數據進行淘汰,那么這個時候內存也會滿。內存滿了之后,redis也會放不了新的數據了。
所以,我們不得已需要一些策略來解決這個問題來保證可用性。
類比冰箱扔菜
如果我們發現冰箱的菜滿了,但是冰箱里的菜都是好的,那你會咋辦?
a. 不放入新的,但是可以拿出來吃 -- noeviction
b. 扔掉很久沒有吃的? ---LRU
c. 扔掉很少吃的? -----lfu
d. 扔掉即將快過期的? --- ttl
那么在Redis中究竟是怎么處理的呢?
noeviction: New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database 默認,不淘汰 能讀不能寫
allkeys-lru: Keeps most recently used keys; removes least recently used (LRU) keys 基于偽LRU算法 在所有的key中去淘汰
allkeys-lfu: Keeps frequently used keys; removes least frequently used (LFU) keys 基于偽LFU算法 在所有的key中去淘汰
volatile-lru: Removes least recently used keys with the expire field set to true . 基于偽LRU算法 在設置了過期時間的key中去淘汰
volatile-lfu: Removes least frequently used keys with the expire field set to true . 基于偽LFU算法 在設置了過期時間的key中去淘汰
allkeys-random: Randomly removes keys to make space for the new data added. 基于隨機算法 在所有的key中去淘汰
volatile-random: Randomly removes keys with expire field set to true . 基于隨機算法 在設置了過期時間的key中去淘汰
volatile-ttl: Removes least frequently used keys with expire field set to true and the shortest remaining time-to-live (TTL) value. 根 據過期時間來,淘汰即將過期的
?上述是官網給我們提供了8種不同的策略,只要在config配置中配置maxmemory-policy即可指定相關的淘汰策略
# maxmemory-policy noeviction //默認不淘汰數據,能讀不能寫
?那么現在我們已經知道了有不同的方式去淘汰,那么整個的淘汰流程又是什么呢?LRU跟LFU算法又是什么呢?
3.1 淘汰流程

如上圖所示
1.首先,我們會有個淘汰池,默認大小是16,并且里面的數據是末尾淘汰制。
2.每次指令操作的時候,自旋會判斷當前內存是否滿足指令所需要的內存
3.如果當前內存不能滿足,會從淘汰池中的尾部拿取一個最適合淘汰的數據
????????3.1 會取樣(配置 maxmemory-samples)從Redis中獲取隨機獲 取到取樣的數據 解決一次性讀取所有的數據慢的問題
????????3.2 在取樣的數據中,根據淘汰算法 找到最適合淘汰的數據
????????3.3 將最合適的那個數據跟淘汰池中的數據比較,是否比淘汰池 中的更適合淘汰,如果更適合,放入淘汰池
????????3.4 按照適合的程度進行排序,最適合淘汰的放入尾部
4.將需要淘汰的數據從Redis刪除,并且從淘汰池移除。
?3.2 LRU算法
LRU, least Recently Used 翻譯過來是最久未使用,根據時間軸來走,仍很久沒用的數據。只要最近有用過,我就默認是有效的。
那么它的一個衡量標準是什么呢?事件對不對!根據使用事件,從近到遠,越遠的越容易淘汰
實現原理
- 首先,LRU是根據這個對象的訪問操作時間來進行淘汰的,那我們需要知道這個對象最后的操作訪問時間。
- 知道了對象的最后操作訪問時間后,我們只需要跟當前的系統時間來進行對比,就能計算出對象已經多久沒有訪問了
源碼驗證
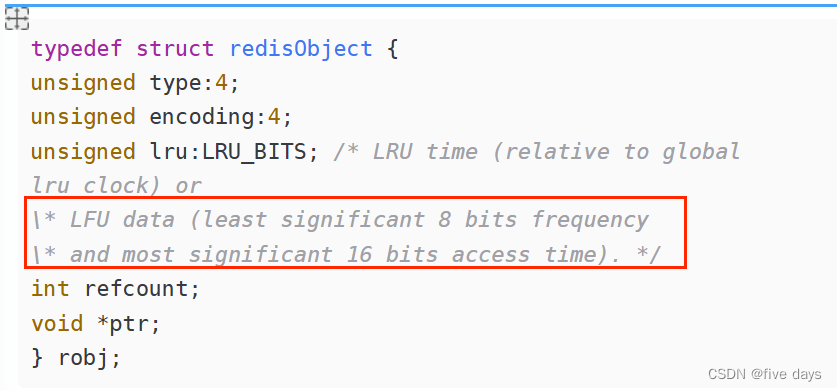
在Redis中,對象都會被一個redisObject對象包裝,這個對象就是我們redis的所有數據結構的對外對象!那么它里面有個字段叫做lru
redisObject對象(server.h文件)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global
lru_clock) or
\* LFU data (least significant 8 bits frequency
\* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;lru這個字段的大小為24bit,那么這個字段記錄的是對象操作訪問時候的秒單位時間的后24bit
long timeMillis=System.currentTimeMillis();
System.out.println(timeMillis/1000); //獲取當前秒
System.out.println(timeMillis/1000 & ((1<<24)-1)); //獲取秒的后24位我們知道了這個對象的最后操作訪問的時間。如果我們要得到這個對象多久沒訪問了,我們是不是就很簡單,用我當前的時間-這個對象的訪問時間就可以了!!!但是這個訪問時間是秒單位時間的后24bit!所以,也是用當前時間的秒單位的后24bit去減!
假如我們lrulock=當前時間的秒單位的最后24bit
那么我們如果要得到這個對象多久沒訪問 只需要: lrulock - redisObject.lru
但是我們就會發現一個問題: 24bit是有大小限制的,最大是24個1,那么假如時間一直往前走,這個系統時間的最后24bit肯定會變成24個0
舉個例子
11111111111111111000000000011111110 假如這個是我當前秒單位的時 間,
獲取后8位 是 11111110
11111111111111111000000000011111111
獲取后8位 是 11111111
11111111111111111000000000100000000
獲取后8位 是 00000000 但是比上面的那個二進制肯定要大
?所以,它有個輪詢的概念,它如果超過24位,又會從0開始!所以我們不能直接用系統時間秒單位的24bit去減對象的lru,而是要判斷一下,怎么判斷
舉個生活中的例子
我們的月份,跟我們的24bit的值是一樣的,都有最大值,只不過月份的最 大值是12。
場景一:數據在5月份被操作訪問,現在是8月份 我們可通過:8-5=3 得 到這個對象3個月沒訪問
場景二:數據在5月份被操作訪問,現在是3月份 我們可通過: 12-5+3 得 到這個對象10個月沒訪問
同理
如果redisObject.lru<lrulock,直接通過lrulock-redisObject.lru得到這個對象多久沒訪問
如果redisObject.lru>lrulock,通過lrulock + (24bit的最大值-redisObject.lru)
源碼驗證
?estimateObjectIdleTime方法(evict.c)
unsigned long long estimateObjectIdleTime(robj *o) {//獲取秒單位時間的最后24位unsigned long long lruclock = LRU_CLOCK();//因為只有24位,所有最大的值為2的24次方-1//超過最大值從0開始,所以需要判斷lruclock(當前系統時間)跟緩存對象的lru字段的大小if (lruclock >= o->lru) {//如果lruclock>=robj.lru,返回lruclock-o->lru,再轉換單位return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;} else {//否則采用lruclock + (LRU_CLOCK_MAX - o->lru),得到對象的值越小,返回的值越大,越大越容易被淘汰return (lruclock + (LRU_CLOCK_MAX - o->lru)) *LRU_CLOCK_RESOLUTION;}
}整體流程圖:Redis LRU算法實現| ProcessOn免費在線作圖,在線流程圖,在線思維導圖
總結
用lrulock與redisObject.lru進行比較,因為Lrulock只獲取了當前秒單位時間的后24位,所以肯定有個輪詢
所以,我們會用lrulock跟redisObject.lru進行比較,如果lrulock>redisObject.lru,那么我們用lrulock-redisObject.lru,否則lrulock+(24bit的最大值-redisObject.lru),得到的lru越小,那么返回的數據越大,相差越大的越優先會被淘汰!
3.3 LFU算法
LFU,Least Frequently Used,翻譯成中文就是最不常用的優先淘汰。
不常用,它的衡量標準就是次數,次數越少的越容易被淘汰
這個實現起來應該也很簡單,對象被操作訪問的時候,去記錄次數,每次操作訪問一次,就+1;淘汰的時候,直接去比較這個次數,次數越少的越容易淘汰
LFU的時效性問題
但是LFU有個致命的問題,那就是時效性問題。何為時效性?就是只考慮數量,不考慮時間
舉個生活中的例子:
假如去年有個新聞很火,比如之前的吳亦凡事件,假如點擊量是3000W
那么今年又有個新聞,剛出來,點擊量是100次
本來,我們應該是要讓今年的這個新聞顯示出來的,吳亦凡雖然去年很火,但是由于時間久了,我肯定是不希望上熱搜的。
但是根據LFU來做的話,我們發現淘汰的卻是今年的新聞,這個明顯是不合理的。
導致的問題就是: 新的數據進不去,舊的數據出不來
Redis肯定也是知道這個問題的,那么Redis是怎么解決的呢?
上面的RedisObject中的lru字段有注釋:??
它前面16bit代表的是時間,后8位代表的是一個數值,frequency是頻率,代表的是這個對象的訪問次數。
前16bit時間有什么用呢?大膽猜測應該是跟時效性有關的,那么究竟是怎么解決的呢?
我們再來看個生活中的例子
大家應該充過一些會員,比如我這個年紀的,小時候喜歡充騰訊的黃鉆、 綠鉆、藍鉆等等。
但是有一個點,假如哪天我沒充錢了的話,或者沒有續VIP的時候,我這個 鉆石等級會隨著時間的流失而降低。比如我本來是黃鉆V6,但是一年不充 錢的話,可能就變成了V4。
那么有了這個例子,在redis中,我們是不是也可以猜測: 這個時間是記錄的這個對象有多久沒訪問了,如果超過了多久沒訪問,就去減少對應的次數。
源碼驗證:
LFUDecrAndReturn方法(evict.c)
unsigned long LFUDecrAndReturn(robj *o) {
//lru字段右移8位,得到前面16位的時間
unsigned long ldt = o->lru >> 8;
//lru字段與255進行&運算(255代表8位的最大值),
//得到8位counter值
unsigned long counter = o->lru & 255;
//如果配置了lfu_decay_time,用LFUTimeElapsed(ldt) 除以配置的值
//LFUTimeElapsed(ldt)源碼見下
//總的沒訪問的分鐘時間/配置值,得到每分鐘沒訪問衰減多少
unsigned long num_periods = server.lfu_decay_time ?
LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
//不能減少為負數,非負數用couter值減去衰減值
counter = (num_periods > counter) ? 0 : counter -
num_periods;
return counter;
}?衰減因子的配置
lfu-decay-time 1 //多少分鐘沒操作訪問就去衰減一次
?后8bits的次數,最大值是255,肯定不夠,但是我們可以讓數據達到255很難,就是每個數值都是訪問了多少次才+1,那么redis究竟是怎么做的呢?
LFULoglncr方法(evict.c文件)
uint8_t LFULogIncr(uint8_t counter) {//如果已經到最大值255,返回255 ,8位的最大值if (counter == 255) return 255;//得到隨機數(0-1)double r = (double)rand()/RAND_MAX;//LFU_INIT_VAL表示基數值(在server.h配置) 默認為5double baseval = counter - LFU_INIT_VAL;//如果達不到基數值,表示快不行了,baseval =0if (baseval < 0) baseval = 0;//如果快不行了,肯定給他加counter//不然,按照幾率是否加counter,同時跟baseval與lfu_log_factor相關//都是在分子,所以2個值越大,加counter幾率越小double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;return counter;
}?所以,LFU加的邏輯我們可以總結下:
- 最大只能到255, 如果到了255,不往上加
- 如果當前次數5<count<255,那么越往上,加的概率越低?lfu-log-factor配置 的值越大,添加的幾率越小!
- 如果小于等于5,每次訪問必加1,因為p=1,r是0到1之間的隨機數,必然小于p
來看一波官方給的壓測數據
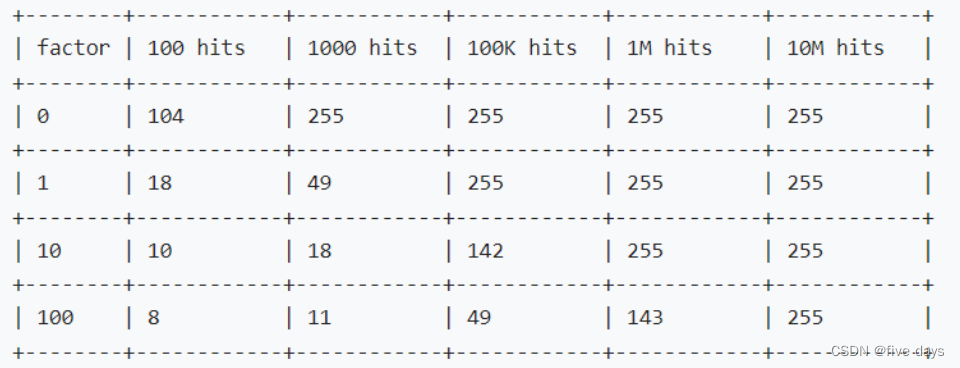
factor因子與點擊量的關系。?





)

:動態內存管理和柔性數組)






)
:適配器模式——Adapter)



