官方文檔:https://python.langchain.com/docs/get_started/introduction/
LangChain是一個能夠利用大語言模型(LLM,Large Language Model)能力進行快速應用開發的框架:
- 高度抽象的組件,可以像搭積木一樣,使用LangChain的組件來實現我們的應用
- 集成外部數據到LLM中,比如API接口數據、文件、外部應用等;
- 提供了許多可自定義的LLM高級能力,比如Agent、RAG等等;
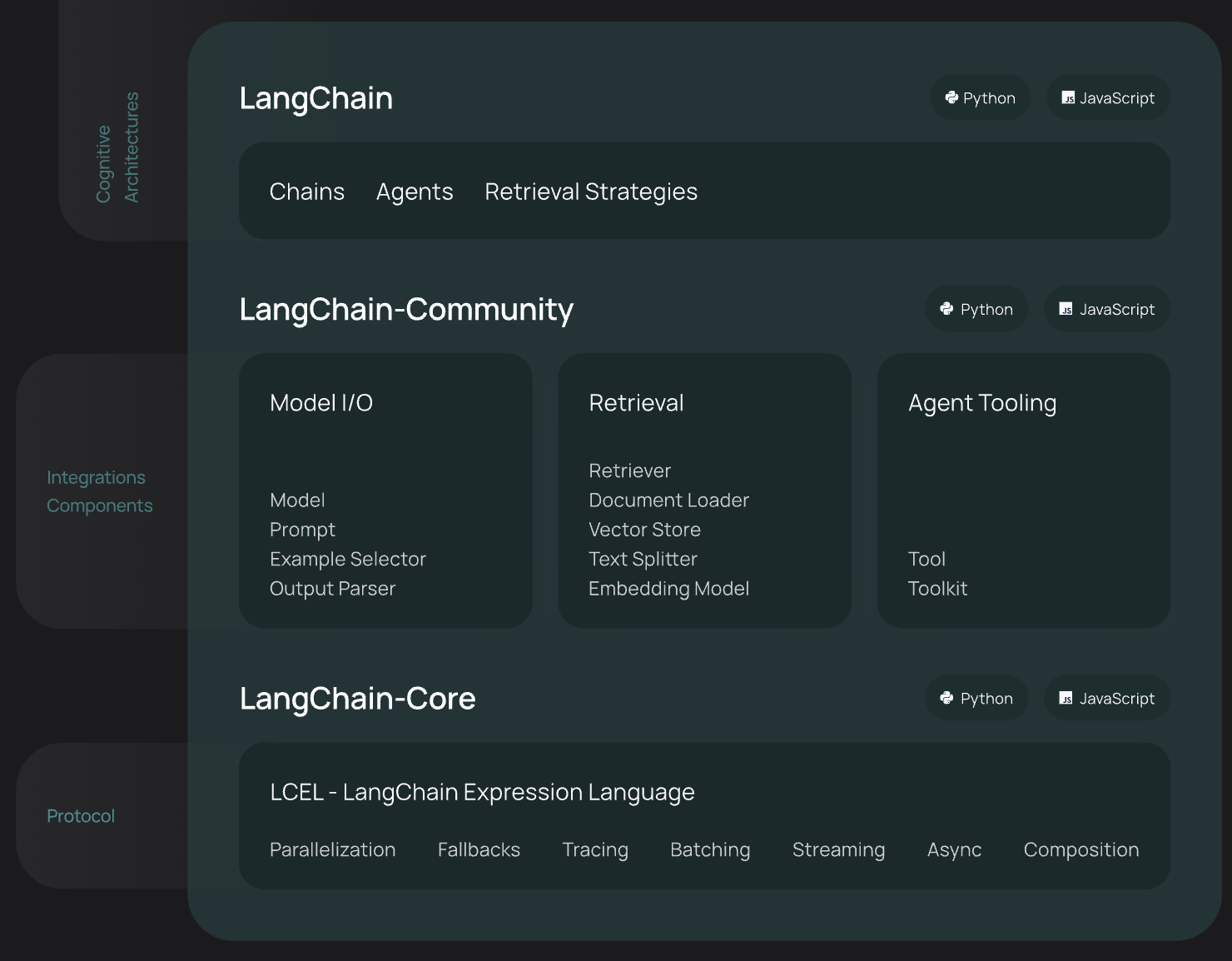
LangChain框架主要由以下六個部分組成:
- Model IO:格式化和管理LLM的輸入和輸出
- Retrieval:檢索,與特定應用數據交互,比如RAG,與向量數據庫密切相關,能夠實現從向量數據庫中搜索與問題相關的文檔來作為增強LLM的上下文
- Agents:決定使用哪個工具(高層指令)的結構體,而tools則是允許LLM與外部系統交互的接口
- Chains:構建運行程序的block-style組合,即能將多個模塊連接起來,實現復雜的功能應用
- Memory:在運行一個鏈路(chain)時能夠存儲程序狀態的信息,比如存儲歷史對話記錄,隨時能夠對這些歷史對話記錄重新加載,保證長對話的準確性
- Callbacks:回調機制,可以追蹤任何鏈路的步驟,記錄日志
Model IO
https://python.langchain.com/docs/modules/model_io/
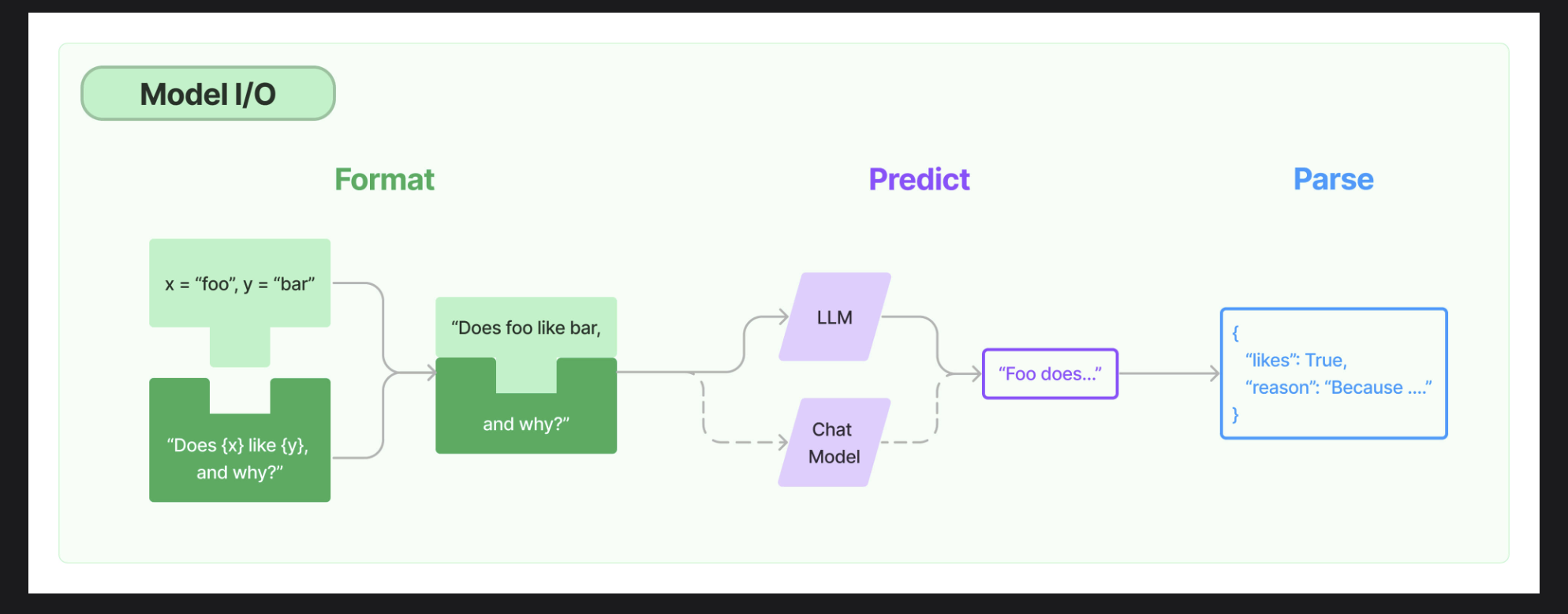
Model IO是直接與LLM交互的核心部分,從上圖可以看出,它包括:
- 對輸入的格式化,涉及的組件是Prompts
- 調用LLM進行預測,涉及的組件是LLM和Chat Model
- 解析LLM的輸出,涉及的組件是Output Parses
在這里先介紹下LLM和Chat Model的區別:
- LLM可以認為是一個文本生成式模型,即大模型會根據用戶輸入的指示,生成一段相關的文本;
- 而Chat Model則是一個聊天驅動的模型,即可以進行多輪對話。
Prompts
示例代碼:prompt_templates.ipynb
prompt是作為用戶的我們提供給LLM的一系列指示(instructions),來指導模型的生成,幫助它理解上下文,來生成相關和連貫的語言輸出,比如回答問題、完成句子、進行對話等等。
prompt templates
prompt模板是一些預定義的方法,用來生成(格式化)LLM的prompt。一個模板可能包含指示、few-shot樣例、適用于一個給定任務的特定的上下文和問題。
LangChain提供了一些與模型無關的模板,可以復用到不同的LLM。
PromptTemplate
- 用于創建一個字符串prompt,其實它就是相當于的Python str.format 。它支持任意數量的變量,包括沒有變量
from langchain.prompts import PromptTemplateprompt_template = PromptTemplate.from_template("Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")"""
'Tell me a funny joke about chickens.'
"""
ChatPromptTemplate
- 用于創建chat model的prompt,是一個chat message的列表。
任何chat message除了相關聯的文本內容,還有一個額外的參數role。比如,OpenAI的ChatGPT,一般有三種role(其他LLM基本也遵循):
- system,用于制作此次對話的人設,它是可選的,不是必要的。如果存在的話,則對話必須以system message為開頭,但如果不存在的話,則人設就是普通的assistant,相當于使用"You are a helpful assistant."作為system message;
- user,作為用戶的我們的輸入,提供了一些訴求來讓assistant(LLM)回答;
- assistant,一般情況是assistant(LLM)的輸出,可以用來存儲多輪對話(user-assistant-user-assistant-…)。但它也可以由我們來寫入,用作一些樣例,比如few-shot,后面再詳細展開。
from langchain_core.prompts import ChatPromptTemplatechat_template = ChatPromptTemplate.from_messages([("system", "You are a helpful AI bot. Your name is {name}."),("human", "Hello, how are you doing?"),("ai", "I'm doing well, thanks!"),("human", "{user_input}"),]
)messages = chat_template.format_messages(name="Bob", user_input="What is your name?")"""
[SystemMessage(content='You are a helpful AI bot. Your name is Bob.'),HumanMessage(content='Hello, how are you doing?'),AIMessage(content="I'm doing well, thanks!"),HumanMessage(content='What is your name?')]
"""
在LangChain中,human對應上述的user,ai對應上述的assistant。
可以看到生成的prompt其實是填入format并生成對應的Message對象,因此在定義模板時也可以傳入Message對象,如下:
from langchain.prompts import HumanMessagePromptTemplate
from langchain_core.messages import SystemMessagechat_template = ChatPromptTemplate.from_messages([SystemMessage(content=("You are a helpful assistant that re-writes the user's text to ""sound more upbeat.")),HumanMessagePromptTemplate.from_template("{text}"),]
)
這對于構造和復用chat prompts提供了許多靈活性。
Message Prompts
從上一個代碼樣例可以看出,MessagePromptTemplate 是用來構造Message對象的模板,三種role分別對應三種message模板:AIMessagePromptTemplate, SystemMessagePromptTemplate and HumanMessagePromptTemplate。
而LangChain還提供另外一種可以使用任意role的message模板:ChatMessagePromptTemplate
from langchain.prompts import ChatMessagePromptTemplateprompt = "May the {subject} be with you"chat_message_prompt = ChatMessagePromptTemplate.from_template(role="Jedi", template=prompt
)
chat_message_prompt.format(subject="force")
MessagesPlaceholder
- message占位符提供了一種對格式化時呈現什么message的完全控制,其用途在于不確定使用什么role或者想插入一個message列表的場景。
from langchain.prompts import (ChatPromptTemplate,HumanMessagePromptTemplate,MessagesPlaceholder,
)human_prompt = "Summarize our conversation so far in {word_count} words."
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)chat_prompt = ChatPromptTemplate.from_messages([MessagesPlaceholder(variable_name="conversation"), human_message_template]
)
可以看到,上述代碼在chat模板中定義了一個占位符+human message的prompt,相對于確定的human message而言,message占位符則是不確定的message,可以在最終格式化呈現prompt的時候才填充數據,如下面的代碼:
from langchain_core.messages import AIMessage, HumanMessagehuman_message = HumanMessage(content="What is the best way to learn programming?")
ai_message = AIMessage(content="""\
1. Choose a programming language: Decide on a programming language that you want to learn.2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.3. Practice, practice, practice: The best way to learn programming is through hands-on experience\
"""
)chat_prompt.format_prompt(conversation=[human_message, ai_message], word_count="10"
).to_messages()"""
[HumanMessage(content='What is the best way to learn programming?'),AIMessage(content='1. Choose a programming language: Decide on a programming language that you want to learn.\n\n2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.\n\n3. Practice, practice, practice: The best way to learn programming is through hands-on experience'),HumanMessage(content='Summarize our conversation so far in 10 words.')]
"""
Few-shot Prompt
最后再介紹一個實用性比較高,也是提示詞工程經常提及的技巧:few-shot。
上面我們也提到了比如OpenAI的ChatGPT,都是包含三個不同的role:system、user、assistant。我們在user-assistant多輪對話中,塞入一些樣例讓大模型能夠學習到這樣的上下文知識。
比如這樣的形式:user message_1(樣例1的輸入)->assistant message_1(樣例1的輸出,即讓大模型學習應該這樣回答) -> … -> user message_n(最后,放入我們真正的輸入)
from langchain_core.prompts import (ChatPromptTemplate,FewShotChatMessagePromptTemplate,
)examples = [{"input": "2+2", "output": "4"},{"input": "2+3", "output": "5"},
]# This is a prompt template used to format each individual example.
example_prompt = ChatPromptTemplate.from_messages([("human", "{input}"),("ai", "{output}"),]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(example_prompt=example_prompt,examples=examples,
)print(few_shot_prompt.format())
"""
Human: 2+2
AI: 4
Human: 2+3
AI: 5
"""final_prompt = ChatPromptTemplate.from_messages([("system", "You are a wondrous wizard of math."),few_shot_prompt,("human", "{input}"),]
)print(final_prompt.format(input='6+7'))
"""
System: You are a wondrous wizard of math.
Human: 2+2
AI: 4
Human: 2+3
AI: 5
Human: 6+7
"""
LCEL
在這里,先了解下LangChain的基礎模塊: Runnable interface,對于整個LangChain的使用會更為清晰,也就是LCEL作為LangChain的表達語言(LangChain Expression Language)。
Langchain實現了一種"Runable"協議,許多基礎的組件包括上述prompt模板,以及LLM、ChatModel,以及后續的Retriever等等的調用,都繼承于這個接口,當然,這也是為了更好得實現自定義的chains/組件。
它包括以下需要實現的方法:
- invoke:使用單個輸入調用chain,比如LLM
- batch:使用一組輸入調用chain
- stream:流式返回結果
以及對應的異步方法,即需要Python的asyncio await語法實現的并發:
ainvoke、abatch、astream:分別對應上面invoke、batch、stream的異步方法
- astream_log:回溯中間步驟的執行信息,加到最終的返回中
- astream_event:記錄流事件(events)的執行(
langchain-core0.1.14才引入的beta功能)
然后,還可以先了解下每種組件的輸入和輸出,方便后面的學習理解:
| Component | Input Type | Output Type |
|---|---|---|
| Prompt | Dictionary | PromptValue |
| ChatModel | Single string, list of chat messages or a PromptValue | ChatMessage |
| LLM | Single string, list of chat messages or a PromptValue | String |
| OutputParser | The output of an LLM or ChatModel | Depends on the parser |
| Retriever | Single string | List of Documents |
| Tool | Single string or dictionary, depending on the tool | Depends on the tool |
LLMs
示例代碼:llms.ipynb
Large Language Models (LLMs)是LangChain的一個核心組件,但需要注意的是,LangChain自己并不進行LLMs的服務,而是提供一個標準接口去跟許多LLMs供應商(OpenAI,Cohere等)進行交互。
具體來說,LangChain的LLMs組件是一個接收字符串作為輸入,然后返回一個字符串的接口。
下面我們將使用通義千問來作為我們的LLMs供應商,目前許多國產大模型都提供了幾百萬的免費tokens額度,這為我們的學習用途提供了很大的便利,主打一個白嫖。
基礎使用
初始化LLM.
from langchain.llms import Tongyi# api key作為參數傳入
llm = Tongyi(dashscope_api_key='....')# 或者配置環境變量`DASHSCOPE_API_KEY`
llm = Tongyi()
使用LLM進行文本生成.
1、阻塞模式
llm.invoke("有什么關于失業和通貨膨脹的相關性的理論")"""
'在經濟學中,失業和通貨膨脹之間的關系是通過一種叫做菲利普斯曲線(Phillips Curve)的理論來描述的.....'
"""
2、流式模式
for chunk in llm.stream("有什么關于失業和通貨膨脹的相關性的理論"
):print(chunk, end="\n", flush=True)"""
失業
和
通
貨膨脹之間的關系是
經濟學中的一個重要概念,通常被描述
為菲利普斯曲線(Phill
ips Curve)的理論。該理論
由新西蘭經濟學家A.W.H.菲
利普斯在1958
年提出,后來被進一步發展和完善
.....
"""
3、批次調用
llm.batch(["簡單介紹一個唐代詩人","簡單介紹一個宋代詩人"]
)"""
['李白,字太白,號青蓮居士,是唐朝時期著名的浪漫主義詩人,被譽為“詩仙”......','蘇軾,字子瞻,號東坡居士,是北宋時期著名的文學家、書畫家,被后人尊稱為“唐宋八大家”之一......']
"""
自定義LLM
當你在本地部署了一個大模型,比如基于Ollama或者Xinference,那么你可以自定義封裝LangChain的LLM接口,便可以像內置的LLMs一樣使用。
首先,你需要繼承LLM這個基類來自動變成上述提到的Runable,然后下面是必須重寫實現的方法:
| Method | Description |
|---|---|
_call | Takes in a string and some optional stop words, and returns a string. Used by invoke. |
_llm_type | A property that returns a string, used for logging purposes only. |
- 這里可以看到,
LLM這個基類已經幫我們實現了invoke的方法,但它是需要調用_call方法的,返回的是字符串 - 但其實,更多的情況下比如Tongyi等模型,是重寫
_generate函數來實現invoke調用,因為_generate函數返回的LLMResult結構體,可以附帶更多信息,比如tokens消耗等 - 因為整個invoke的調用順序是這樣的:
BaseLLM.invoke->LLM._generate->LLM._call,因此當你實現了_generate函數,就不需要再去調用_call
下面幾個則是非必須實現的方法:
| Method | Description |
|---|---|
_identifying_params | Used to help with identifying the model and printing the LLM; should return a dictionary. This is a @property. |
_acall | Provides an async native implementation of _call, used by ainvoke. |
_stream | Method to stream the output token by token. 看了源碼,如果不實現_stream的話,則默認是調用invoke,然后轉為迭代器返回。 |
_astream | Provides an async native implementation of _stream; in newer LangChain versions, defaults to _stream. |
接下來,我們還是以官網的教程和例子來實現一個非常簡單的自定義LLM,它的功能僅僅是回復輸入的前n個字符。
from typing import Any, Dict, Iterator, List, Mapping, Optionalfrom langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from langchain_core.outputs import GenerationChunkclass CustomLLM(LLM):"""A custom chat model that echoes the first `n` characters of the input."""n: intdef _call(self,prompt: str,stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> str:"""Run the LLM on the given input.Override this method to implement the LLM logic.Args:prompt: The prompt to generate from.stop: Stop words to use when generating. Model output is cut off at thefirst occurrence of any of the stop substrings.If stop tokens are not supported consider raising NotImplementedError.run_manager: Callback manager for the run.**kwargs: Arbitrary additional keyword arguments. These are usually passedto the model provider API call.Returns:The model output as a string. Actual completions SHOULD NOT include the prompt."""if stop is not None:raise ValueError("stop kwargs are not permitted.")return prompt[: self.n]def _stream(self,prompt: str,stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> Iterator[GenerationChunk]:"""Stream the LLM on the given prompt.This method should be overridden by subclasses that support streaming.Args:prompt: The prompt to generate from.stop: Stop words to use when generating. Model output is cut off at thefirst occurrence of any of these substrings.run_manager: Callback manager for the run.**kwargs: Arbitrary additional keyword arguments. These are usually passedto the model provider API call.Returns:An iterator of GenerationChunks."""for char in prompt[: self.n]:chunk = GenerationChunk(text=char)if run_manager:run_manager.on_llm_new_token(chunk.text, chunk=chunk)yield chunk@propertydef _identifying_params(self) -> Dict[str, Any]:"""Return a dictionary of identifying parameters."""return {# The model name allows users to specify custom token counting# rules in LLM monitoring applications (e.g., in LangSmith users# can provide per token pricing for their model and monitor# costs for the given LLM.)"model_name": "CustomChatModel",}@propertydef _llm_type(self) -> str:"""Get the type of language model used by this chat model. Used for logging purposes only."""return "custom"
它的使用方法與LangChain內置LLMs是相同:
llm = CustomLLM(n=5)
print(llm)
"""
CustomLLM
Params: {'model_name': 'CustomChatModel'}
"""llm.invoke("This is a foobar thing")
"""
'This '
"""for token in llm.stream("hello"):print(token, end="|", flush=True)
"""
h|e|l|l|o|
"""llm.batch(["woof woof woof", "meow meow meow"])
"""
['woof ', 'meow ']
"""
緩存
緩存的使用場景是存在多次相同的文本生成請求,直接從緩存中獲取結果進行回復,既可以提升性能,又可以減少對LLM供應商的請求,從而節省費用。
其中,最為簡單的緩存方式便是內存,對應的實現類為:InMemoryCache,每次的prompt和結果都會存儲在內存中。
%%timeset_llm_cache(InMemoryCache())# The first time, it is not yet in cache, so it should take longer
llm.predict("說一個笑話")
"""
CPU times: user 137 ms, sys: 77.9 ms, total: 215 ms
Wall time: 1.26 s'一朵花為什么很好笑?因為它很有梗。'
"""%%time# The second time it is, so it goes faster
llm.predict("說一個笑話")
"""
CPU times: user 752 μs, sys: 317 μs, total: 1.07 ms
Wall time: 1.03 ms'一朵花為什么很好笑?因為它很有梗。'
"""
除了內存的緩存,LangChain還提供了RedisCache這種借助外部工具的緩存實現,可以實現服務重啟的緩存不失效和分布式緩存。
LangChain提供了許多內置的緩存方式:LLM Caching
消耗追蹤
實現代碼:callbacks、custom tongyi
LangChain內置了OpenAI API的tokens消耗追溯,可以得到一個具體請求的消耗tokens和費用,但目前只支持了OpenAI的,并且不支持stream調用的消耗追溯。我參考LangChain內置方法,實現了一套能夠追蹤更通用化的消耗,并且支持stream,使用方式和返回結果與內置實現完全一致。
(這里要吐槽下LangChain設計的缺陷,內置的stream調用是上層的抽象類(父類)的方法,很難把信息放在llm_output,只能放在實現類的_stream方法中返回的generation_info,但目前每一個LLMs都缺少模型名稱或者tokens消耗的信息,只能自己重寫對應模型的_stream方法,把信息都帶入generation_info)
from callbacks.manager import get_cn_llm_callbackwith get_cn_llm_callback() as cb:llm.invoke("有什么關于失業和通貨膨脹的相關性的理論")print(cb)
"""
Tokens Used: 429Prompt Tokens: 18Completion Tokens: 411
Successful Requests: 1
Total Cost (CYN): ¥0.008579999999999999
"""# stream調用需要使用重寫的Tongyi類
from tongyi.llm import CustomTongyi# dashscope_api_key作為參數傳入
# 或者配置環境變量`DASHSCOPE_API_KEY`
llm = CustomTongyi()with get_generic_llms_callback() as cb:for chunk in llm.stream("有什么關于失業和通貨膨脹的相關性的理論"):print(chunk, end="|", flush=True)print(cb)"""
在|經濟學|中|,失業和通貨|膨脹之間的關系被廣泛研究,主要|理論有菲利普斯曲線(| Phillips Curve)和納克斯的“|自然失業率”理論.....
Tokens Used: 301Prompt Tokens: 18Completion Tokens: 283
Successful Requests: 1
Total Cost (CYN): ¥0.006019999999999999
"""
Chat Model
示例代碼:chatmodel.ipynb
正如上述提到,Chat Model則是一個聊天驅動的大語言模型,可以進行多輪對話。
LangChain內置了絕大部分市場上的大語言模型,可能部分模型沒有LLM實現類,但是都會有ChatModel實現類。
Messages類型
Chat models使用chat message作為輸入和輸出,除了上述提到的三種基本messages類型,還有另外兩種:
- SystemMessage:用于制作此次對話的人設;
- HumanMessage:用戶的輸入;
- AIMessage:模型的輸出;
- FunctionMessage:函數調用(function call)的結果,除了對應的
role和content參數外,還有一個name參數,表示對應名稱的函數的執行結果 - ToolMessage:工具調用(tool call)的結果,同樣有額外的參數
tool_call_id,表示對應id的工具的執行結果。
函數和工具的調用暫且不在這個章節進行闡述,留到后續有專門的章節。
基礎使用
其實,Chat model的使用與LLMs比較類似,只是輸入和輸出的格式不同。
初始化LLM.
from langchain_community.chat_models import ChatTongyi# api key作為參數傳入
chat = ChatTongyi(dashscope_api_key='.....')# 或者配置環境變量`DASHSCOPE_API_KEY`
chat = ChatTongyi()
使用LLM進行文本生成.
1、阻塞模式
from langchain_core.messages import HumanMessage, SystemMessagemessages = [SystemMessage(content="你是一個數學專家"),HumanMessage(content="什么是勾股定理"),
]chat.invoke(messages)"""
AIMessage(content='勾股定理是古希臘數學家畢達哥拉斯發現的一個幾何學基本定理,也被稱為畢達哥拉斯定理......', response_metadata={'model_name': 'qwen-turbo', 'finish_reason': 'stop', 'request_id': '09f736aa-84b9-9a31-b249-1cf1a779b034', 'token_usage': {'input_tokens': 22, 'output_tokens': 142, 'total_tokens': 164}}, id='run-0978a38d-3611-4c89-97e2-05280f578591-0')
"""
可以看到,Chat model的invoke函數不僅返回了模型的回復內容content,還附帶了response_metadata,包含一些模型調用信息。
2、流式模式
for chunk in chat.stream(messages):print(chunk.content, end="|", flush=True)"""
勾|股|定|理是古希臘數學|家畢達哥拉斯發現的一個幾何|學基本定理,也被稱為畢|達哥拉斯定理......
"""
當然,還有跟LLMs一樣的批次調用、異步調用等等,如上面LCEL章節提到那些基礎函數。
自定義Chat model
上述提到了Chat model的輸入和輸出都是message,因此自定義的Chat model也需要符合同樣的輸入和輸出類型。
并且繼承BaseChatModel基類,實現以下方法:
| Method/Property | Description | Required/Optional |
|---|---|---|
_generate | Use to generate a chat result from a prompt | Required |
_llm_type (property) | Used to uniquely identify the type of the model. Used for logging. | Required |
_identifying_params (property) | Represent model parameterization for tracing purposes. | Optional |
_stream | Use to implement streaming. | Optional |
_agenerate | Use to implement a native async method. | Optional |
_astream | Use to implement async version of _stream. | Optional |
接下來,仍然是一個簡單的例子,實現取prompt里最后一個message的前n個字符的功能。
from typing import Any, AsyncIterator, Dict, Iterator, List, Optionalfrom langchain_core.callbacks import (AsyncCallbackManagerForLLMRun,CallbackManagerForLLMRun,
)
from langchain_core.language_models import BaseChatModel, SimpleChatModel
from langchain_core.messages import AIMessageChunk, BaseMessage, HumanMessage
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
from langchain_core.runnables import run_in_executorclass CustomChatModelAdvanced(BaseChatModel):"""A custom chat model that echoes the first `n` characters of the input.When contributing an implementation to LangChain, carefully documentthe model including the initialization parameters, includean example of how to initialize the model and include any relevantlinks to the underlying models documentation or API.Example:.. code-block:: pythonmodel = CustomChatModel(n=2)result = model.invoke([HumanMessage(content="hello")])result = model.batch([[HumanMessage(content="hello")],[HumanMessage(content="world")]])"""model_name: str"""The name of the model"""n: int"""The number of characters from the last message of the prompt to be echoed."""def _generate(self,messages: List[BaseMessage],stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> ChatResult:"""Override the _generate method to implement the chat model logic.This can be a call to an API, a call to a local model, or any otherimplementation that generates a response to the input prompt.Args:messages: the prompt composed of a list of messages.stop: a list of strings on which the model should stop generating.If generation stops due to a stop token, the stop token itselfSHOULD BE INCLUDED as part of the output. This is not enforcedacross models right now, but it's a good practice to follow sinceit makes it much easier to parse the output of the modeldownstream and understand why generation stopped.run_manager: A run manager with callbacks for the LLM."""# Replace this with actual logic to generate a response from a list# of messages.last_message = messages[-1]tokens = last_message.content[: self.n]message = AIMessage(content=tokens,additional_kwargs={}, # Used to add additional payload (e.g., function calling request)response_metadata={ # Use for response metadata"time_in_seconds": 3,},)##generation = ChatGeneration(message=message)return ChatResult(generations=[generation])def _stream(self,messages: List[BaseMessage],stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> Iterator[ChatGenerationChunk]:"""Stream the output of the model.This method should be implemented if the model can generate outputin a streaming fashion. If the model does not support streaming,do not implement it. In that case streaming requests will be automaticallyhandled by the _generate method.Args:messages: the prompt composed of a list of messages.stop: a list of strings on which the model should stop generating.If generation stops due to a stop token, the stop token itselfSHOULD BE INCLUDED as part of the output. This is not enforcedacross models right now, but it's a good practice to follow sinceit makes it much easier to parse the output of the modeldownstream and understand why generation stopped.run_manager: A run manager with callbacks for the LLM."""last_message = messages[-1]tokens = last_message.content[: self.n]for token in tokens:chunk = ChatGenerationChunk(message=AIMessageChunk(content=token))if run_manager:# This is optional in newer versions of LangChain# The on_llm_new_token will be called automaticallyrun_manager.on_llm_new_token(token, chunk=chunk)yield chunk# Let's add some other information (e.g., response metadata)chunk = ChatGenerationChunk(message=AIMessageChunk(content="", response_metadata={"time_in_sec": 3}))if run_manager:# This is optional in newer versions of LangChain# The on_llm_new_token will be called automaticallyrun_manager.on_llm_new_token(token, chunk=chunk)yield chunk@propertydef _llm_type(self) -> str:"""Get the type of language model used by this chat model."""return "echoing-chat-model-advanced"@propertydef _identifying_params(self) -> Dict[str, Any]:"""Return a dictionary of identifying parameters.This information is used by the LangChain callback system, whichis used for tracing purposes make it possible to monitor LLMs."""return {# The model name allows users to specify custom token counting# rules in LLM monitoring applications (e.g., in LangSmith users# can provide per token pricing for their model and monitor# costs for the given LLM.)"model_name": self.model_name,}
與內置Chat model同樣的調用方式:
model = CustomChatModelAdvanced(n=3, model_name="my_custom_model")model.invoke([HumanMessage(content="hello!"),AIMessage(content="Hi there human!"),HumanMessage(content="Meow!"),]
)"""
AIMessage(content='Meo', response_metadata={'time_in_seconds': 3}, id='run-ddb42bd6-4fdd-4bd2-8be5-e11b67d3ac29-0')
"""# 輸入也支持字符串,可以等同于`[HumanMessage(content="cat vs dog")]`
for chunk in model.stream("cat vs dog"):print(chunk.content, end="|")
"""
c|a|t||
"""
緩存
緩存機制與LLMs基本也是一致的。
from langchain.globals import set_llm_cache
from langchain.cache import InMemoryCache%%timeset_llm_cache(InMemoryCache())# The first time, it is not yet in cache, so it should take longer
chat.invoke("說一個笑話")"""
CPU times: user 69.4 ms, sys: 9.48 ms, total: 78.9 ms
Wall time: 999 msAIMessage(content='小王剪了一個中分,然后他就變成了小全。', response_metadata={'model_name': 'qwen-turbo', 'finish_reason': 'stop', 'request_id': '7fb3f662-e3b1-9f2d-ae2c-0b8a1a909aec', 'token_usage': {'input_tokens': 11, 'output_tokens': 13, 'total_tokens': 24}}, id='run-8e663365-66d5-4876-9714-f88857aea39d-0')
"""%%time# The second time it is, so it goes faster
chat.invoke("說一個笑話")
"""
CPU times: user 1.27 ms, sys: 794 μs, total: 2.07 ms
Wall time: 1.33 msAIMessage(content='小王剪了一個中分,然后他就變成了小全。', response_metadata={'model_name': 'qwen-turbo', 'finish_reason': 'stop', 'request_id': '7fb3f662-e3b1-9f2d-ae2c-0b8a1a909aec', 'token_usage': {'input_tokens': 11, 'output_tokens': 13, 'total_tokens': 24}}, id='run-8e663365-66d5-4876-9714-f88857aea39d-0')
"""
同樣的,除了內存的緩存,LangChain還提供了RedisCache這種借助外部工具的緩存實現,可以實現服務重啟的緩存不失效和分布式緩存。
其他內置的緩存方式:LLM Caching
消耗追蹤
實現代碼:callbacks、custom tongyi
正如上述提到的,我參考LangChain內置方法,實現了一套能夠追蹤更通用化的消耗,并且支持stream,使用方式和返回結果與內置實現完全一致。 它也同樣適用于Chat model,不過要在調用stream的時候記錄消耗,仍然需要自己使用自定義的Chat model類。
from callbacks.manager import get_generic_llms_callbackmessages = [SystemMessage(content="你是一個數學專家"),HumanMessage(content="什么是勾股定理"),]with get_generic_llms_callback() as cb:chat.invoke(messages)print(cb)
"""
Tokens Used: 153Prompt Tokens: 22Completion Tokens: 131
Successful Requests: 1
Total Cost (CYN): ¥0.0027960000000000003
"""from tongyi.chat_model import CustomChatTongyi# dashscope_api_key作為參數傳入
# 或者配置環境變量`DASHSCOPE_API_KEY`
chat = CustomChatTongyi(dashscope_api_key='....')with get_generic_llms_callback() as cb:for chunk in chat.stream(messages):print(chunk.content, end="|", flush=True)print()print(cb)
"""
勾|股|定|理是古希臘數學|家畢達哥拉斯發現的一個幾何|學基本定理,也被稱為畢|達哥拉斯定理......
Tokens Used: 190Prompt Tokens: 22Completion Tokens: 168
Successful Requests: 1
Total Cost (CYN): ¥0.003536
"""
模型關鍵參數
在這里以openai gpt為例,列舉下幾個影響大語言模型表現的關鍵參數,可以更好地理解和使用(大部分主流模型一般都是包含這些參數的):
- max_tokens:模型返回的最大tokens,max_tokens+input_tokens=模型支持的上下文最大長度(context length,比如gpt-3.5-turbo-16k支持最大16k tokens的長下文)
- temperature:采樣溫度,越大的值可以讓模型輸出更加隨機
- top_p:同樣是采樣系數,表示模型會考慮前
top_p概率質量的tokens - frequency_penalty:頻率懲罰,在生成新tokens對它們截止當前的出現頻率的懲罰,越大的只可以降低模型重復相同tokens的概率
- presence_penalty:存在懲罰,在生成新tokens對它們截止當前已經存在的的懲罰,越大的值可以增加模型闡述新主題的概率
Output Parsers
示例代碼:output_parser.ipynb
從前面可以看到,LLM和ChatModel的輸出都是自然語言文本,也就是字符串,但在對接過程中,如果大模型能夠按照特定的格式進行返回,比如常用的json,這將為開發提供極大的便捷。
結構體解析
我們可以定一個數據結構的類,主要包含一些成員變量來存儲解析結果,也就是可以從大模型的輸出文本中,對應這些成員變量的含義來提取對應的信息。
首先,我們定義一個關于笑話的Joke類:
- 包含兩個成員變量,description便是告訴大模型這個變量需要存儲哪些信息
@validator("setup")可以來檢驗大模型解析的結果是否符合預期
from langchain.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator# Define your desired data structure.
class Joke(BaseModel):setup: str = Field(description="開啟一個笑話的問題")punchline: str = Field(description="解答笑話的答案")# You can add custom validation logic easily with Pydantic.@validator("setup")def question_ends_with_question_mark(cls, field):if field[-1] != "?":raise ValueError("Badly formed question!")return field
接著,使用LangChain內置的解析器PydanticOutputParser,通過Prompt組件來構建提示詞,輸入到ChatModel組件,大模型的輸出再經過解析器得到解析后的數據。
這樣一個流程其實就是Chains,正如開頭提到,Chains便是多個組件連接起來的序列組合,一步一步地執行,然后將結果傳遞給下一步。 在LangChain中使用|符號將多個組件連接起來。
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)prompt = PromptTemplate(template="根據用戶的輸入進行解答.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)# And a query intended to prompt a language model to populate the data structure.
chain = prompt | chat | parser
chain.invoke({"query": "講一個笑話"})
"""
Joke(setup='為什么電腦永遠不會感冒?', punchline='因為它有Windows(Windows,意為窗戶,這里指電腦不會打開,所以不會受冷)')
"""
這里,我們進一步揭開這個解析器的面紗,先來看看解析器是如何指導提示詞的:
parser.get_format_instructions()
"""
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{"properties": {"setup": {"title": "Setup", "description": "開啟一個笑話的問題", "type": "string"}, "punchline": {"title": "Punchline", "description": "解答笑話的答案", "type": "string"}}, "required": ["setup", "punchline"]}
```
"""
可以看到,解析器會干預提示詞,指導大模型輸出json格式的字符串,然后字段的含義便是我們定義的Joke類的成員變量的description,這樣其實就很容易將對應的字段提取出來,寫入導對應的成員變量了。
json解析
json解析器與上面的結構體解析器使用相同的提示詞指導,只是最后返回dict格式的數據。
from langchain_core.output_parsers import JsonOutputParser# Set up a parser + inject instructions into the prompt template.
parser = JsonOutputParser(pydantic_object=Joke)chain = prompt | chat | parserchain.invoke({"query": "講一個笑話"})
"""
{'setup': '為什么電腦永遠不會感冒?', 'punchline': '因為它有Windows(窗戶)但是不開!'}
"""
其他內置解析器
LangChain內置了許多解析器,可以去官方文檔查看支持的所有解析器類型。
自定義解析器
LangChain提供了兩種自定義方法:
- 使用
RunnableLambda或RunnableGenerator,這可以符合LCEL。 - 繼承一個輸出解析器的基礎類。
Runnable Lambdas.
from typing import Iterablefrom langchain_core.messages import AIMessage, AIMessageChunkdef parse(ai_message: AIMessage) -> str:"""Parse the AI message."""return ai_message.content.swapcase()chain = chat | parse
chain.invoke("hello")
"""
'hELLO! hOW CAN i ASSIST YOU TODAY?'
"""
可以看到,這種方法非常簡單,僅需定義一個基本方法,接收Chat model的輸出AIMessage,上面的例子的解析器是將Chat model的回復文本轉換大小寫。
Runnable Generators.
from langchain_core.runnables import RunnableGeneratordef streaming_parse(chunks: Iterable[AIMessageChunk]) -> Iterable[str]:for chunk in chunks:yield chunk.content.swapcase()streaming_parse = RunnableGenerator(streaming_parse)chain = chat | streaming_parsefor chunk in chain.stream("tell me about yourself in one sentence"):print(chunk, end="|", flush=True)
"""
i| AM| A| LARGE LANGUAGE MODEL CREATED BY| aLIBABA cLOUD, DESIGNED TO ANSWER QUESTIONS AND| PROVIDE INFORMATION ON VARIOUS TOPICS.|
"""
流式模式支持同樣簡單,僅需要定義一個方法,接收Chat model的輸出AIMessageChunk迭代器,遍歷對每次Chat model的流式返回進行處理,即streaming_parse方法是對每一塊chunk進行處理,而非上面的parse方法是對LLM返回的完整數據進行處理。
繼承解析器基類.
from langchain_core.exceptions import OutputParserException
from langchain_core.output_parsers import BaseOutputParser# The [bool] desribes a parameterization of a generic.
# It's basically indicating what the return type of parse is
# in this case the return type is either True or False
class BooleanOutputParser(BaseOutputParser[bool]):"""Custom boolean parser."""true_val: str = "YES"false_val: str = "NO"def parse(self, text: str) -> bool:cleaned_text = text.strip().upper()if cleaned_text not in (self.true_val.upper(), self.false_val.upper()):raise OutputParserException(f"BooleanOutputParser expected output value to either be "f"{self.true_val} or {self.false_val} (case-insensitive). "f"Received {cleaned_text}.")return cleaned_text == self.true_val.upper()@propertydef _type(self) -> str:return "boolean_output_parser"
可以看到,其實跟上面直接定義解析方法是差不多,只不過是繼承重寫了parse函數。這個例子實現了:判斷LLM返回是否為YES或NO,然后對應True或False的布爾值。
調用方法也是跟上面一樣遵從LCEL,便不再展示了。
解析LLM原始輸出.
模型的輸出其實經常包含一些額外信息metadata的,因此如果解析器需要這部分信息的話,可以使用下面的方法。
from typing import Listfrom langchain_core.exceptions import OutputParserException
from langchain_core.messages import AIMessage
from langchain_core.output_parsers import BaseGenerationOutputParser
from langchain_core.outputs import ChatGeneration, Generationclass StrInvertCase(BaseGenerationOutputParser[str]):"""An example parser that inverts the case of the characters in the message.This is an example parse shown just for demonstration purposes and to keepthe example as simple as possible."""def parse_result(self, result: List[Generation], *, partial: bool = False) -> str:"""Parse a list of model Generations into a specific format.Args:result: A list of Generations to be parsed. The Generations are assumedto be different candidate outputs for a single model input.Many parsers assume that only a single generation is passed it in.We will assert for thatpartial: Whether to allow partial results. This is used for parsersthat support streaming"""if len(result) != 1:raise NotImplementedError("This output parser can only be used with a single generation.")generation = result[0]if not isinstance(generation, ChatGeneration):# Say that this one only works with chat generationsraise OutputParserException("This output parser can only be used with a chat generation.")return generation.message.content.swapcase()chain = anthropic | StrInvertCase()
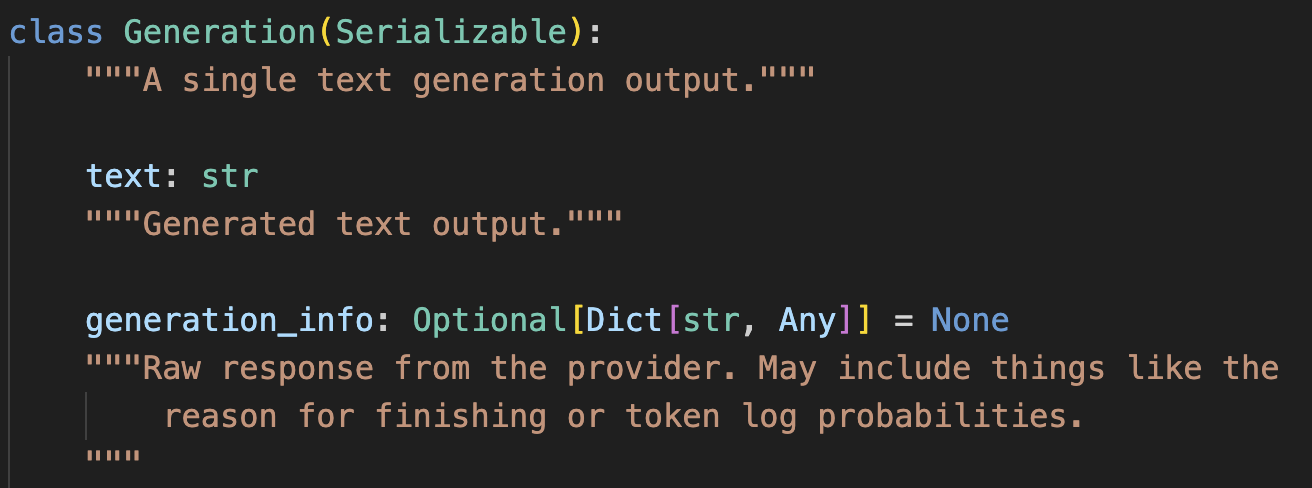
因為,這里處理的 Generation是包含LLM的回復text和一些額外信息generation_info的。
并且像這個例子,還可以定義只支持Chat model的解析。
完整代碼倉庫
github


















)
