說明
實現基于LVQ(Learning Vector Quantization,學習向量量化)神經網絡的乳腺腫瘤診斷分類任務。LVQ是一種監督學習算法,通常用于模式識別和分類任務。
算法思路介紹:
-
導入數據:
- 加載名為"data.mat"的數據文件,其中包含乳腺腫瘤診斷所需的特征和標簽信息。
- 將數據集隨機打亂,并將其分為訓練集和測試集。這里采用了方法:隨機打亂數據集并取前500個樣本作為訓練集,剩余的樣本作為測試集。
-
創建網絡:
- 使用LVQ神經網絡,通過函數創建一個網絡。LVQ網絡的特點是具有明確的輸出神經元和學習向量,適用于分類任務。
- 指定了網絡的輸入特征范圍、輸出神經元數量(在這里為20個)、不同類別樣本的比例以及學習率等參數。這些參數的選擇對網絡的性能和分類結果影響很大。
-
設置網絡參數:
? ? ? ?在這一步,設置了網絡的訓練參數,包括迭代次數、顯示頻率、學習率和訓練目標。這些參數決定了網絡在訓練過程中如何調整權重和學習樣本的過程。 -
訓練網絡:
? ? ? ? 使用函數對創建的LVQ網絡進行訓練,輸入訓練數據和對應的目標標簽。網絡將根據輸入數據和目標標簽的差異進行權重的調整,以最小化分類誤差。 -
仿真測試:
- 訓練好網絡后,使用函數對測試集進行仿真測試,得到測試集的分類結果。
- 根據LVQ網絡的輸出結果,將連續的輸出轉換為離散的類別標簽。
-
結果顯示:
? ? ? 統計和顯示了各種診斷結果,包括總體病例數量、訓練集病例數量、測試集病例數量、良性和惡性乳腺腫瘤的確診數量、誤診數量以及確診率等信息。
? ? ? ? 代碼實現了一個簡單的乳腺腫瘤分類器,通過LVQ神經網絡對乳腺腫瘤進行良性和惡性的分類,并輸出了分類結果和相關統計信息,以評估分類器的性能。
部分代碼(完整代碼在最后):
%% 創建網絡
count_B=length(find(Tc_train==1));
count_M=length(find(Tc_train==2));
rate_B=count_B/500;
rate_M=count_M/500;
net=newlvq(minmax(P_train),20,[rate_B rate_M],0.01,'learnlv1');
% 設置網絡參數
net.trainParam.epochs=1000;
net.trainParam.show=10;
net.trainParam.lr=0.1;
net.trainParam.goal=0.1;
%% 訓練網絡
net=train(net,P_train,T_train);
%% 仿真測試
T_sim=sim(net,P_test);
Tc_sim=vec2ind(T_sim);
result=[Tc_sim;Tc_test]
%% 結果顯示
total_B=length(find(data(:,2)==1));
total_M=length(find(data(:,2)==2));
number_B=length(find(Tc_test==1));
number_M=length(find(Tc_test==2));
number_B_sim=length(find(Tc_sim==1 & Tc_test==1));
number_M_sim=length(find(Tc_sim==2 &Tc_test==2));
disp(['病例總數:' num2str(569)...' 良性:' num2str(total_B)...' 惡性:' num2str(total_M)]);
disp(['訓練集病例總數:' num2str(500)...' 良性:' num2str(count_B)...' 惡性:' num2str(count_M)]);
disp(['測試集病例總數:' num2str(69)...' 良性:' num2str(number_B)...' 惡性:' num2str(number_M)]);
disp(['良性乳腺腫瘤確診:' num2str(number_B_sim)...' 誤診:' num2str(number_B-number_B_sim)...' 確診率p1=' num2str(number_B_sim/number_B*100) '%']);
disp(['惡性乳腺腫瘤確診:' num2str(number_M_sim)...' 誤診:' num2str(number_M-number_M_sim)...' 確診率p2=' num2str(number_M_sim/number_M*100) '%']);結果展示:
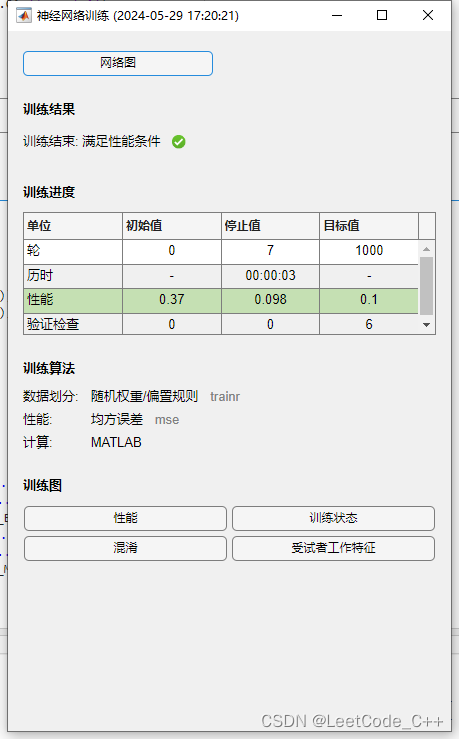

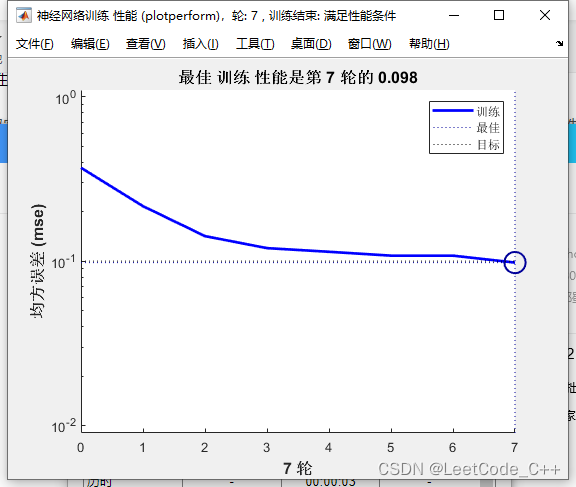









); 會導致內存泄露嗎?里面有SurfaceView ViewBinding)




)






