參考資料:活用pandas庫
1、簡介
? ? ? ? 借助“分割-應用-組合”(split-apply-combine)模式,分組操作可以有效地聚合、轉換和過濾數據。
? ? ? ? 分割:基于鍵,把要處理的數據分割為小片段。
? ? ? ? 應用:分別處理每個數據片段。
? ? ? ? 組合:把處理結果組合成新的數據集。
? ? ? ? 該模式的強大在于,可以將原始數據分割成獨立的片段分別進行處理。pandas的groupby工作方式與sql語言的group by相同。
2、聚合
? ? ? ? 聚合也稱“匯總”(summarization),是指某種形式的數據歸約。
(1)基本的單變量分組聚合
# 導入庫
import pandas as pd
# 加載Gapminder數據集
df=pd.read_csv(r"...\data\gapminder.tsv",sep='\t')
# 計算每年平均預期壽命
avg_life_exp_by_year=df.groupby('year').lifeExp.mean()
print(avg_life_exp_by_year)
? ? ? ? 針對上面的例子,可以認為groupby語句創建了一個子集,里面含有各列的唯一值(或者列的唯一對)。
(2)pandas內置的聚合方法
| pandas方法 | numpy/scipy函數 | 說明 |
|---|---|---|
| count | np.count_nonezero | 頻率統計(不包含NaN值) |
| size | 頻率統計(包含NaN值) | |
| mean | np.mean | 求平均值 |
| std | np.std | 樣本標準差 |
| min | np.min | 最小值 |
| quantile(q=0.25) | np.percentile(q=0.25) | 下四分位數 |
| quantile(q=0.50) | np.percentile(q=0.50) | 中位數 |
| quantile(q=0.75) | np.percentile(q=0.75) | 上四分位數 |
| max | np.max | 最大值 |
| sum | np.sum | 求和 |
| var | np.var | 無偏方差 |
| sem | scipy.stats.sem | 平均數標準誤 |
| describe | scipy.stats.describe | 計數、平均數、標準差、25%、50%、75%分位數、最大值 |
| first | 返回第一行 | |
| last | 返回最后一行 | |
| nth | 返回第n行(python從0開始計數) |
# 根據所在的洲分組,針對每個組對預期壽命做匯總統計
continent_describe=df.groupby('continent').lifeExp.describe()
print(continent_describe)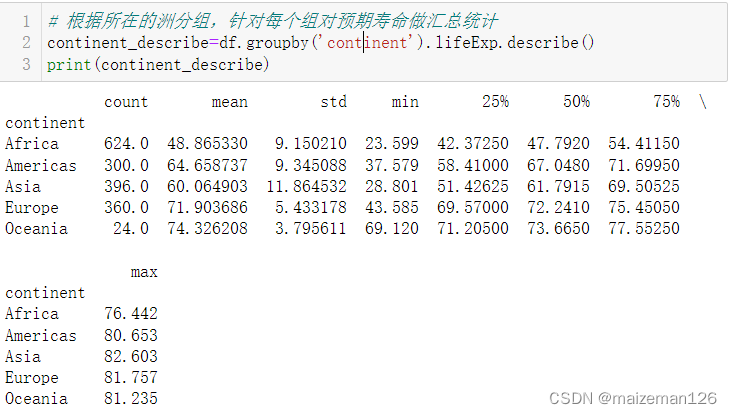
(3)聚合函數
? ? ? ? 除了直接調用聚合方法,還可以調用agg方法或aggregate方法,傳入想用的聚合函數。使用agg或aggregate時,需要使用上表中numpy/scipy函數。
# 導入numpy庫
import numpy as np
# 計算各洲的平均預期壽命
# 使用np.mean函數
cont_le_agg=df.groupby('continent').lifeExp.agg(np.mean)
print(cont_le_agg)
# agg和aggregate功能相同
cont_le_agg2=df.groupby('continent')['lifeExp'].aggregate(np.mean)
print(cont_le_agg2)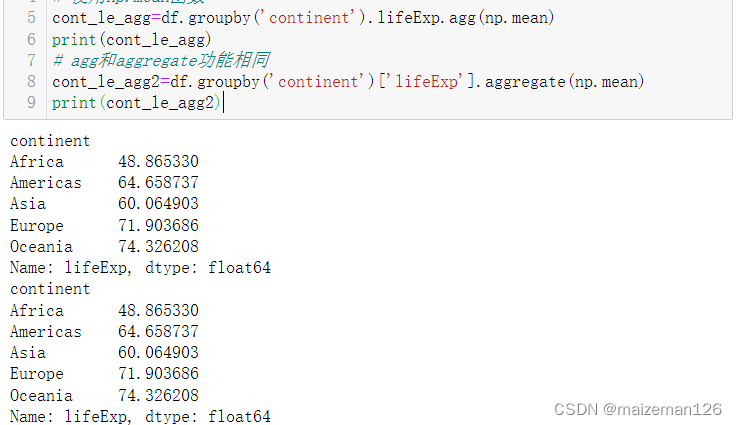
# 自定義函數的聚合
# 創建自定義函數
def my_mean_diff(values,diff_value):"""計算平均值和diff_value之差"""n=len(values)sum=0for value in values:sum+=valuemean=sum/nreturn (mean-diff_value)# 計算全球平均預期壽命的平均值
global_mean=df.lifeExp.mean()
print(global_mean)
# 還有多個參數的自定義聚合函數
agg_mean_diff=df.groupby('continent').lifeExp.\
agg(my_mean_diff,diff_value=global_mean)
print(agg_mean_diff)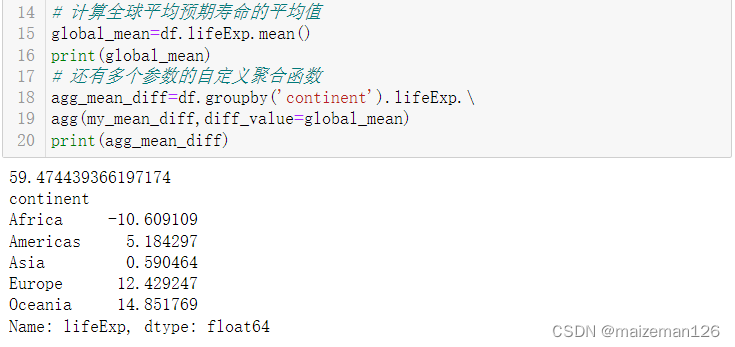
(4)同時傳入多個函數
? ? ? ? 如果想同時計算多個聚合函數,可以先把他們全部放入一個python列表,然后把整個列表傳入agg或aggregate中。這里所用函數仍然是上表中的sumpy/scipy函數。
# 按洲計算lifeExp的非零個數、平均值和標準差
gdf=df.groupby('continent').lifeExp.agg([np.count_nonzero,np.mean,np.std])
print(gdf)
(5)在agg/aggregate中使用字典
? ? ? ? 對于分組的DataFrame指定的dict時,鍵是DataFrame的列,值是聚合計算使用的函數。這種方法允許對一個或多個變量進行分組,對不同列同時使用不同的聚合函數。
? ? ? ? 可以在groupby之后把一個dict傳入Series中,直接做匯總統計并將其返回,dict的鍵是新的列名,這與把dict傳入分組的DataFrame時的行為不同,不建議使用。
# 對DataFrame使用字典聚合不同列
# 對于每一年,計算平均值lifeExp、中位數pop和中位數gdfPercap
gdf_dict=df.groupby('year').agg({"lifeExp":"mean","pop":"median","gdpPercap":"median"})
print(gdf_dict)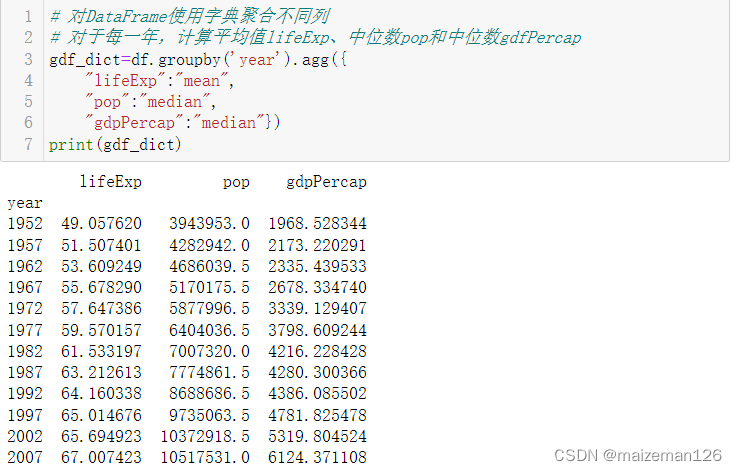
gdf=df.groupby('year')['lifeExp'].\
agg([np.count_nonzero,np.mean,np.std]).\
rename(columns={'count_nonzero':'count','mean':'avg','std':'std_dev'}).\
reset_index() # 返回一個普通DataFrameprint(gdf)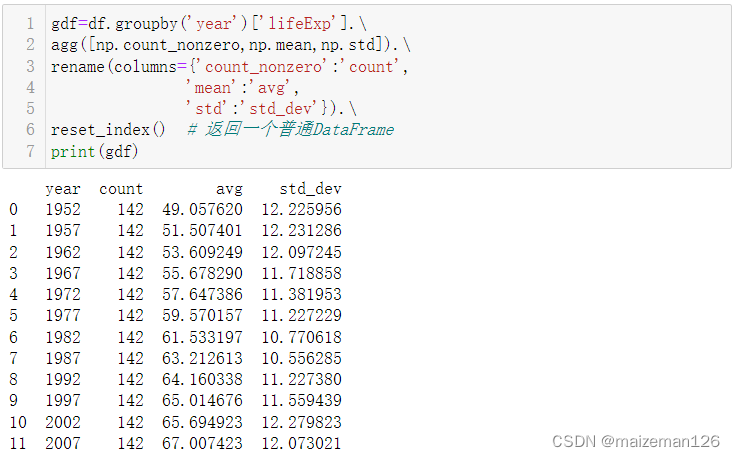









)




![Collection(一)[集合體系]](http://pic.xiahunao.cn/Collection(一)[集合體系])


)

