目錄
一、污點(Taint)?
1.1污點介紹
1.2污點的組成格式
1.3當前 taint effect 支持如下三個選項:
1.4污點的增刪改查
1.4.1驗證污點的作用——NoExecute
1.4.2驗證污點的作用——NoSchedule
1.4.3?驗證污點的作用——PreferNoSchedule?
1.5污點的配置與管理
二、容忍(Tolerations)
2.1容忍的定義
2.2容忍的組成
2.3容忍的配置與管理
2.4其它注意事項
三、資源優化
3.1多master使用
3.2Node更新
3.3維護操作
cordon 和 drain
3.3.1cordon
3.3.2?drain
3.3.3污點、容忍和驅逐
四、Pod啟動階段(相位 phase)
4.1Pod啟動階段
4.2phase 的可能狀態有
?五、k8s常見的排障手段
5.1環境設置
5.2pod事件處理
5.3針對組件故障
5.4針對pod故障
5.5針對網絡故障
一、污點(Taint)?
1.1污點介紹
節點親和性,是Pod的一種屬性(偏好或硬性要求),它使Pod被吸引到一類特定的節點。Taint 則相反,它使節點能夠排斥一類特定的 Pod。
Taint 和 Toleration 相互配合,可以用來避免 Pod 被分配到不合適的節點上。每個節點上都可以應用一個或多個 taint ,這表示對于那些不能容忍這些 taint 的 Pod,是不會被該節點接受的。如果將 toleration 應用于 Pod 上,則表示這些 Pod 可以(但不一定)被調度到具有匹配 taint 的節點上。
使用 kubectl taint 命令可以給某個 Node 節點設置污點,Node 被設置上污點之后就和 Pod 之間存在了一種相斥的關系,可以讓 Node 拒絕 Pod 的調度執行,甚至將 Node 已經存在的 Pod 驅逐出去。
1.2污點的組成格式
污點的組成格式如下:
key=value:effect
每個污點有一個 key 和 value 作為污點的標簽,其中 value 可以為空,effect 描述污點的作用。
1.3當前 taint effect 支持如下三個選項:
- NoSchedule:表示 k8s 將不會將 Pod 調度到具有該污點的 Node 上
- PreferNoSchedule:表示 k8s 將盡量避免將 Pod 調度到具有該污點的 Node 上
- NoExecute:表示 k8s 將不會將 Pod 調度到具有該污點的 Node 上,同時會將 Node 上已經存在的 Pod 驅逐出去
master 就是因為有 NoSchedule 污點,k8s 才不會將 Pod 調度到 master 節點上

1.4污點的增刪改查
#設置污點
kubectl taint node node01 key1=value1:NoSchedule#節點說明中,查找 Taints 字段
kubectl describe node node-name #去除污點
kubectl taint node node01 key1:NoSchedule-kubectl taint node node01 鍵名=鍵值:NoSchedule
#增加污點kubectl taint node node01 鍵名=鍵值:NoSchedule-
kubectl taint node node01 鍵名-
#刪除kubectl describe nodes node01|grep -A5 -i taint
#查看設置污點
kubectl taint node node01 jiangsu=nanjing:NoSchedule鍵=值節點說明中,查找 Taints 字段
kubectl describe node node01|grep -i taints去除污點
kubectl taint node node01 jiangsu:NoSchedule-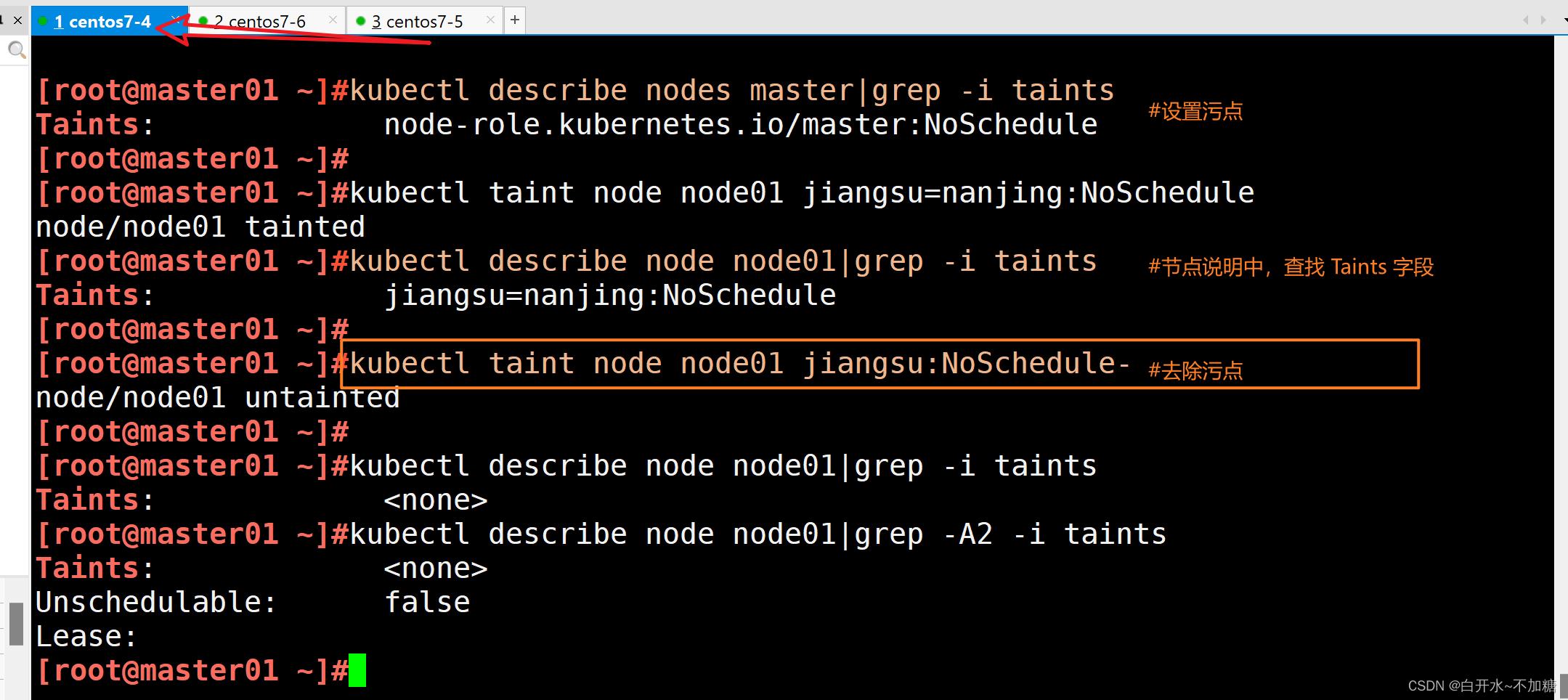

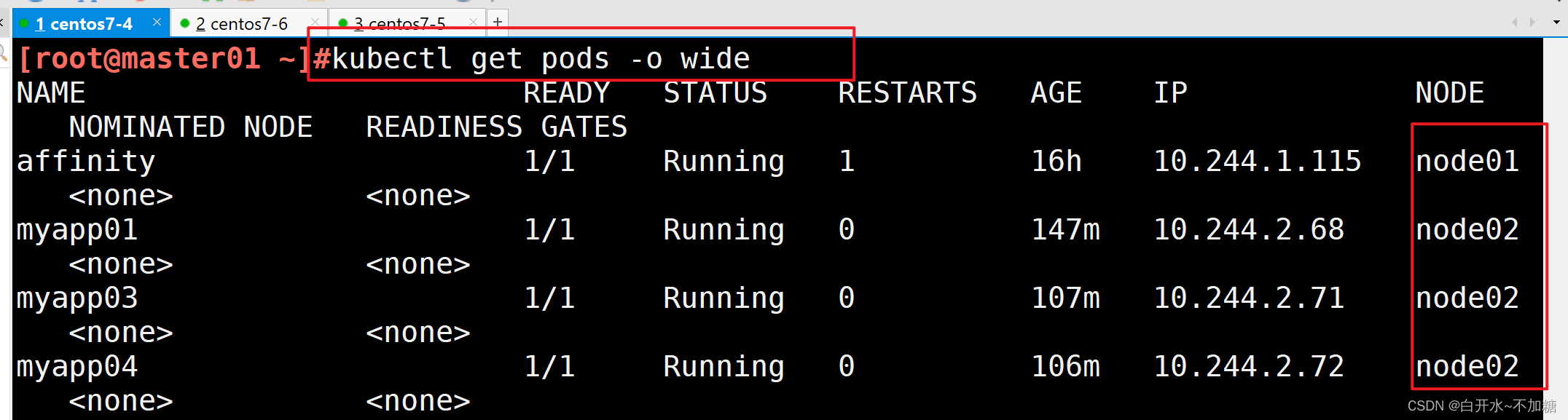
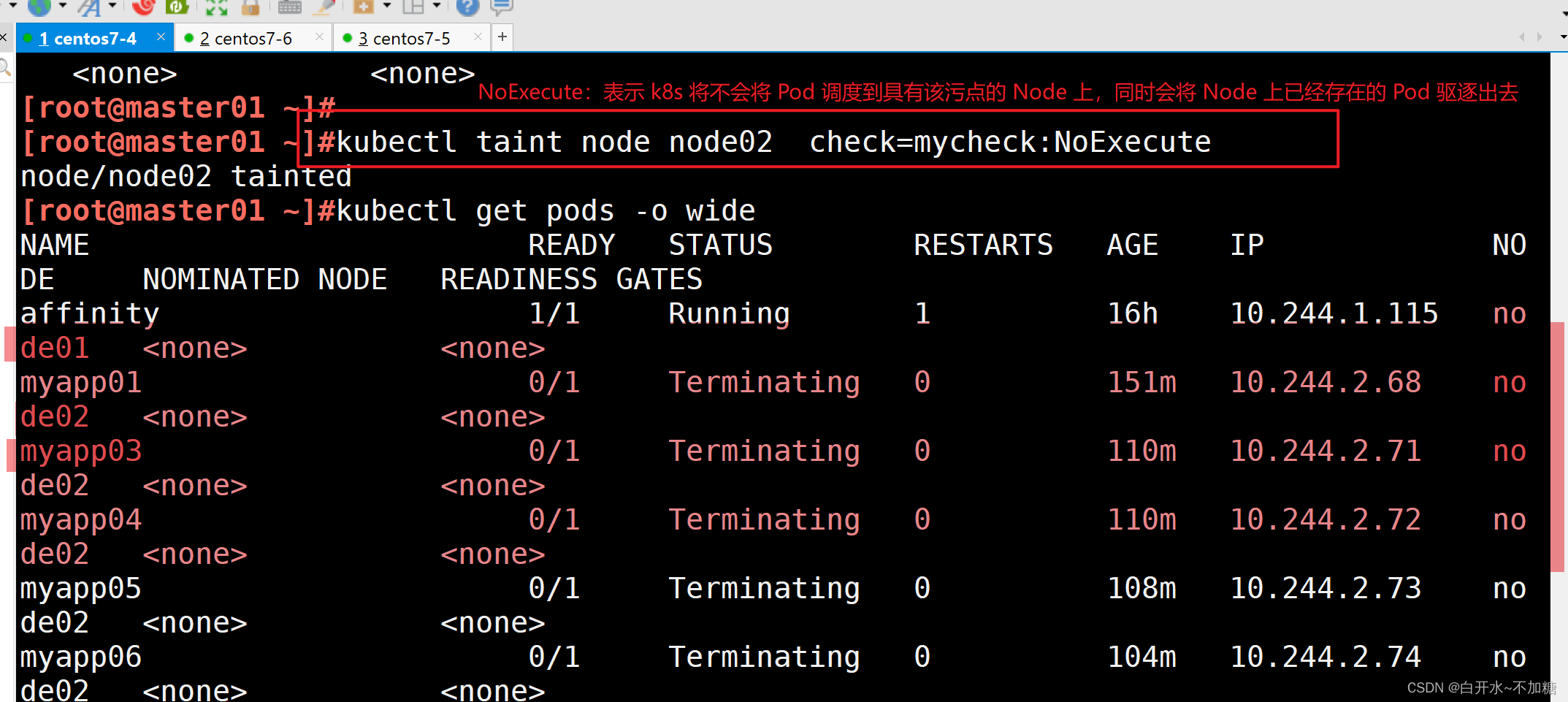
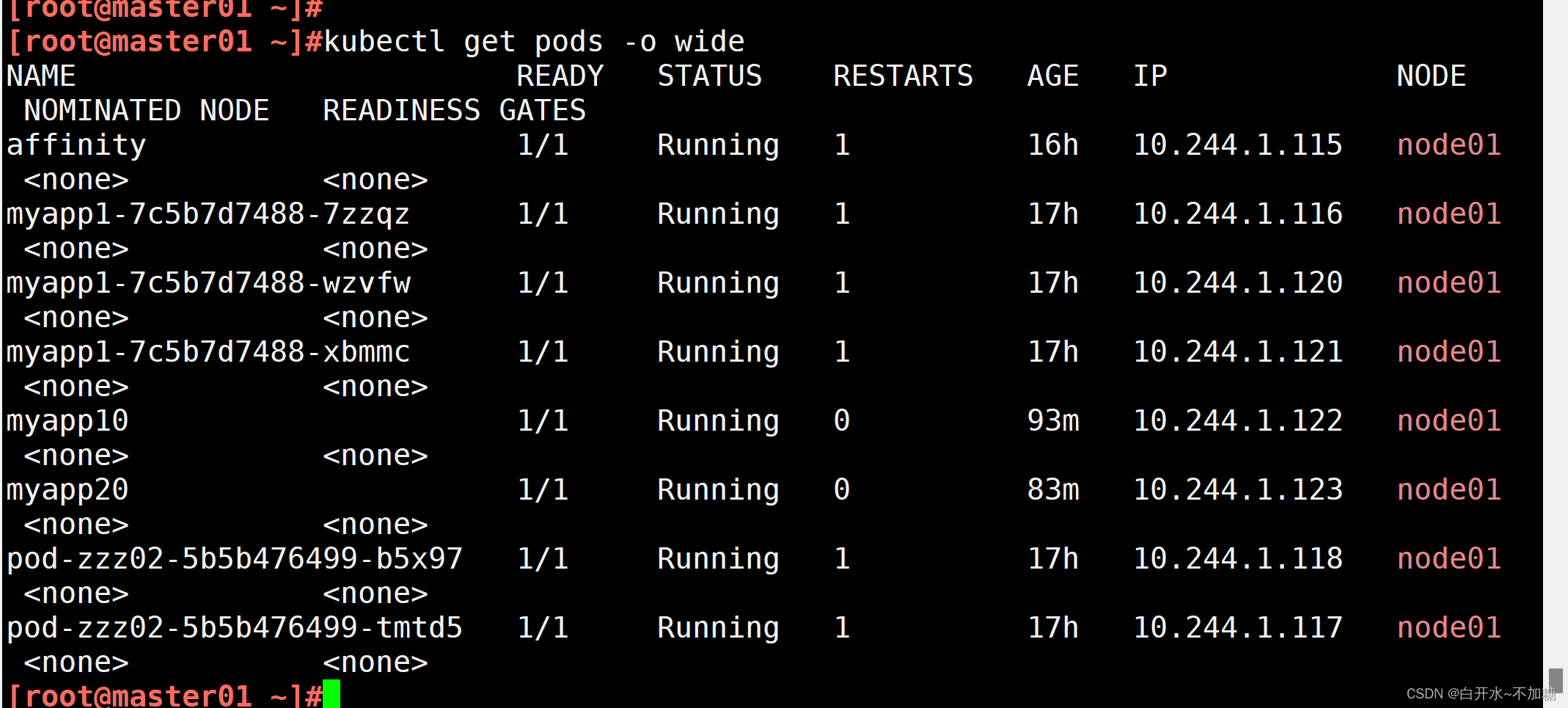
查看 Pod 狀態,會發現 node02 上的 Pod 已經被全部驅逐(注:如果是 Deployment 或者 StatefulSet 資源類型,為了維持副本數量則會在別的 Node 上再創建新的 Pod)
1.4.1驗證污點的作用——NoExecute
kubectl taint node node01 check=no:NoExecute設置了污點為NoExecute效果會不允許新的pod調度到該node 還會自動驅逐運行中的pod



1.4.2驗證污點的作用——NoSchedule
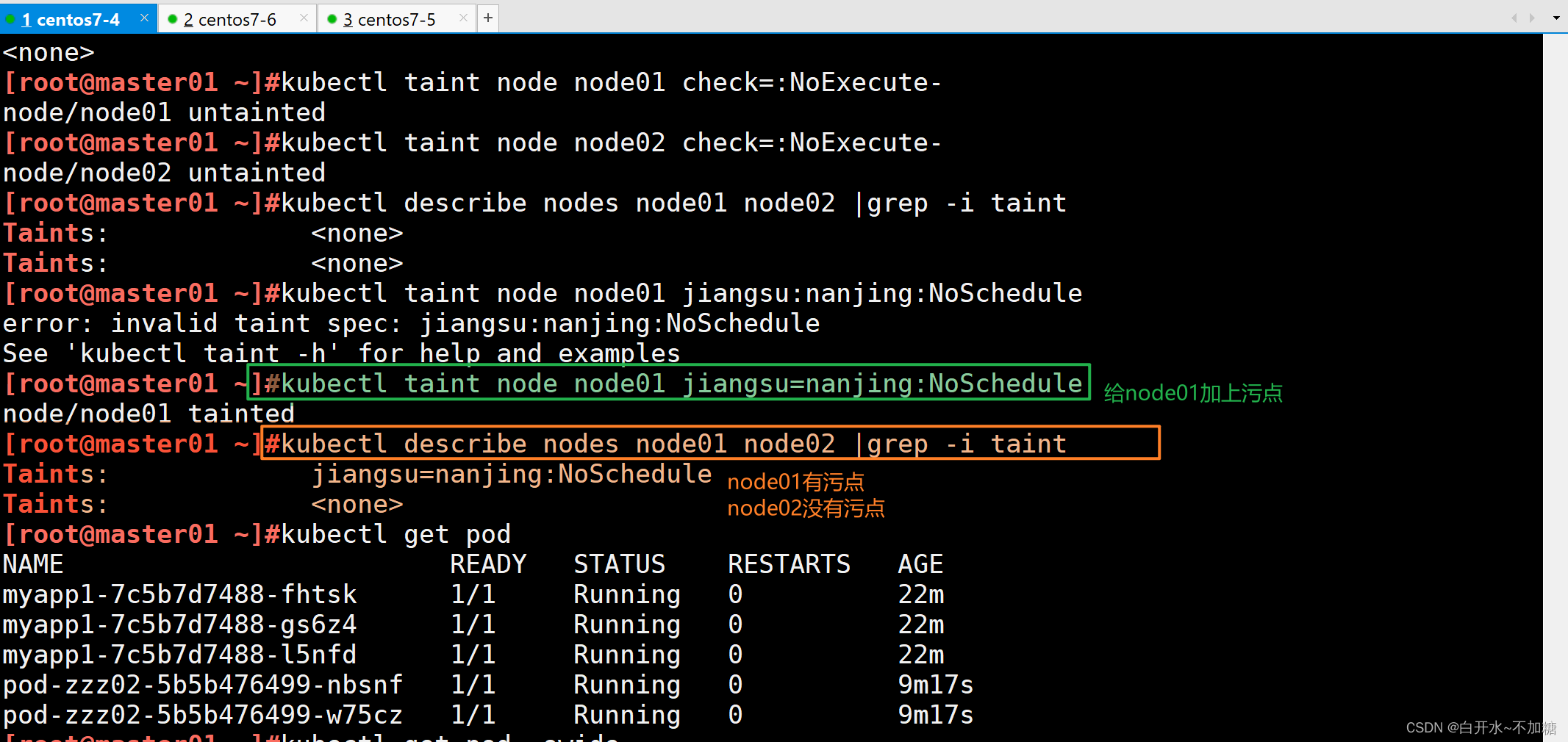
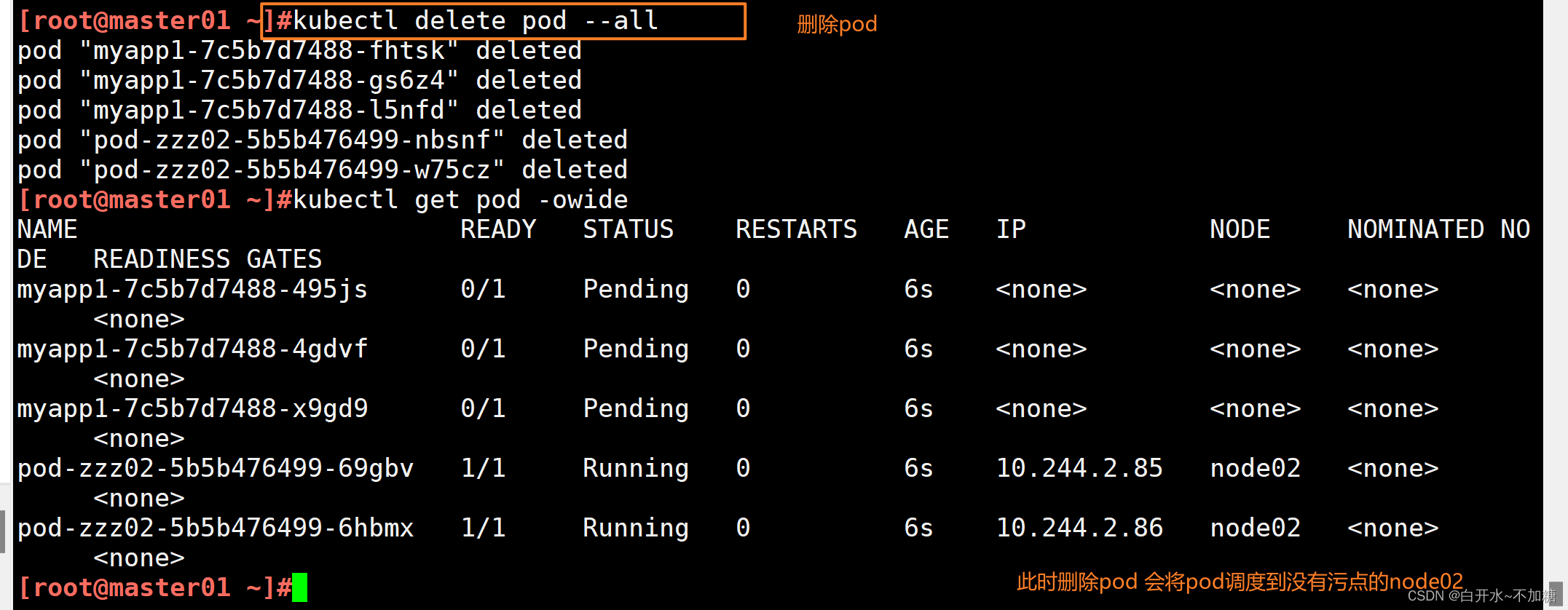

1.4.3?驗證污點的作用——PreferNoSchedule?
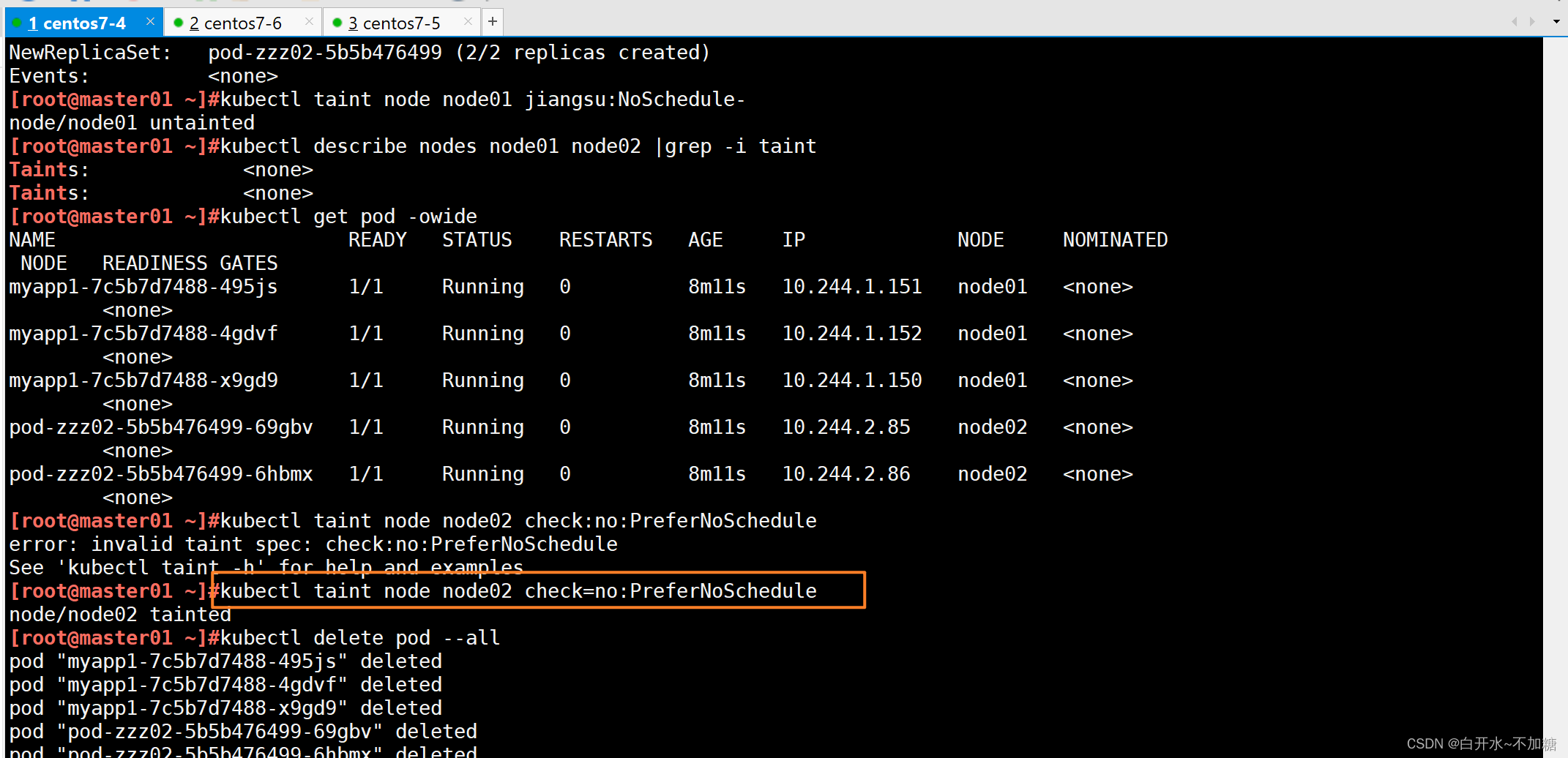

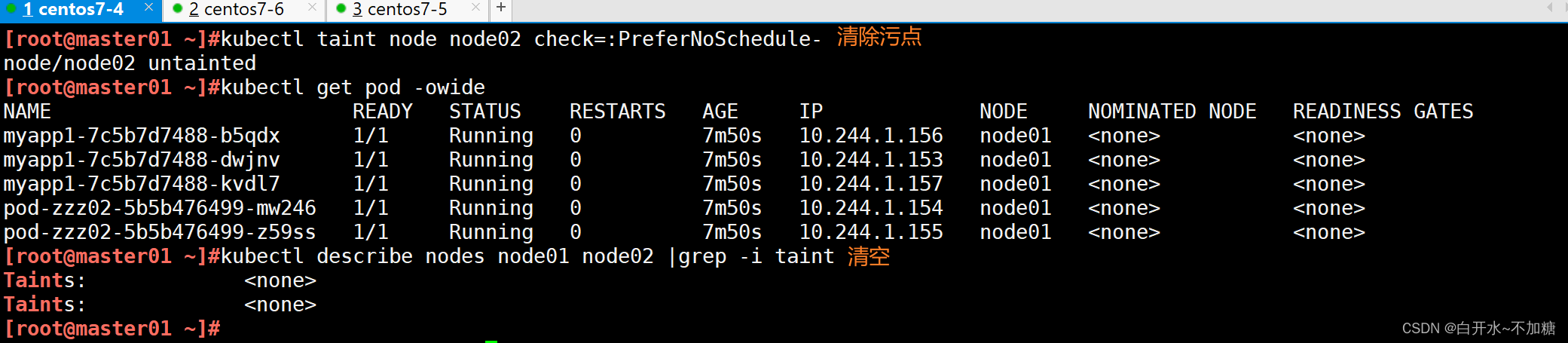
1.5污點的配置與管理
[root@master01 ~]#cd /opt
[root@master01 opt]#mkdir Taint
[root@master01 opt]#cd Taint/
[root@master01 Taint]#kubectl taint node node02 nanjing=222:NoSchedule
node/node02 tainted
[root@master01 Taint]#kubectl describe nodes node02|grep -i taint
Taints: nanjing=222:NoSchedule
[root@master01 Taint]##設置污點效果為NoSchedule,表示不能容忍此污點的新的pod將不會在node02上建立
#已經運行的則不會有影響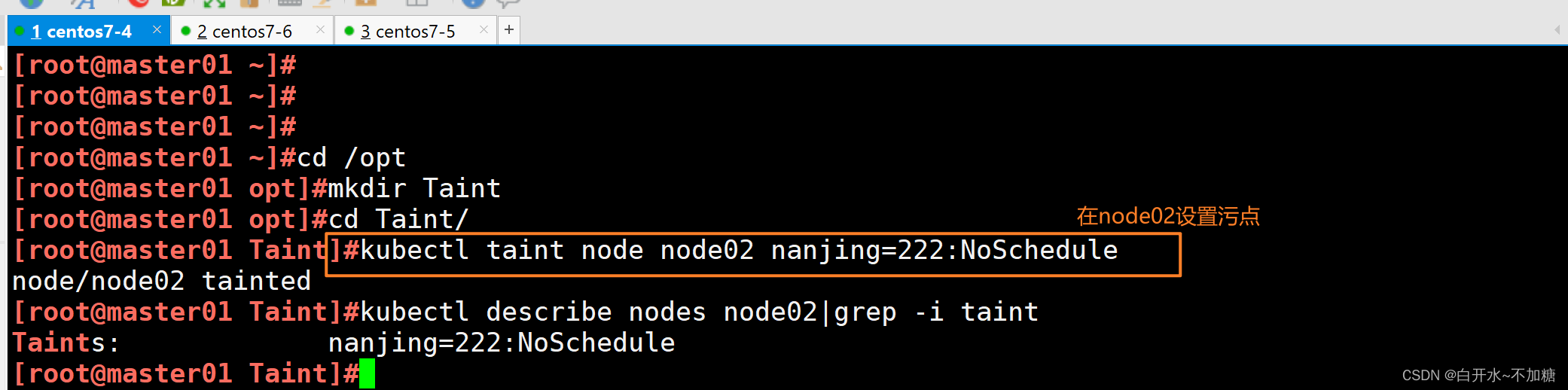
[root@master01 Taint]#vim demo1.yaml
[root@master01 Taint]#cat demo1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: demo1-myapplabels:app: demo1-myapp
spec:replicas: 3selector:matchLabels:app: demo1-myapptemplate:metadata:labels:app: demo1-myappspec:containers:- name: myapp-affinityimage: soscscs/myapp:v1ports:- containerPort: 80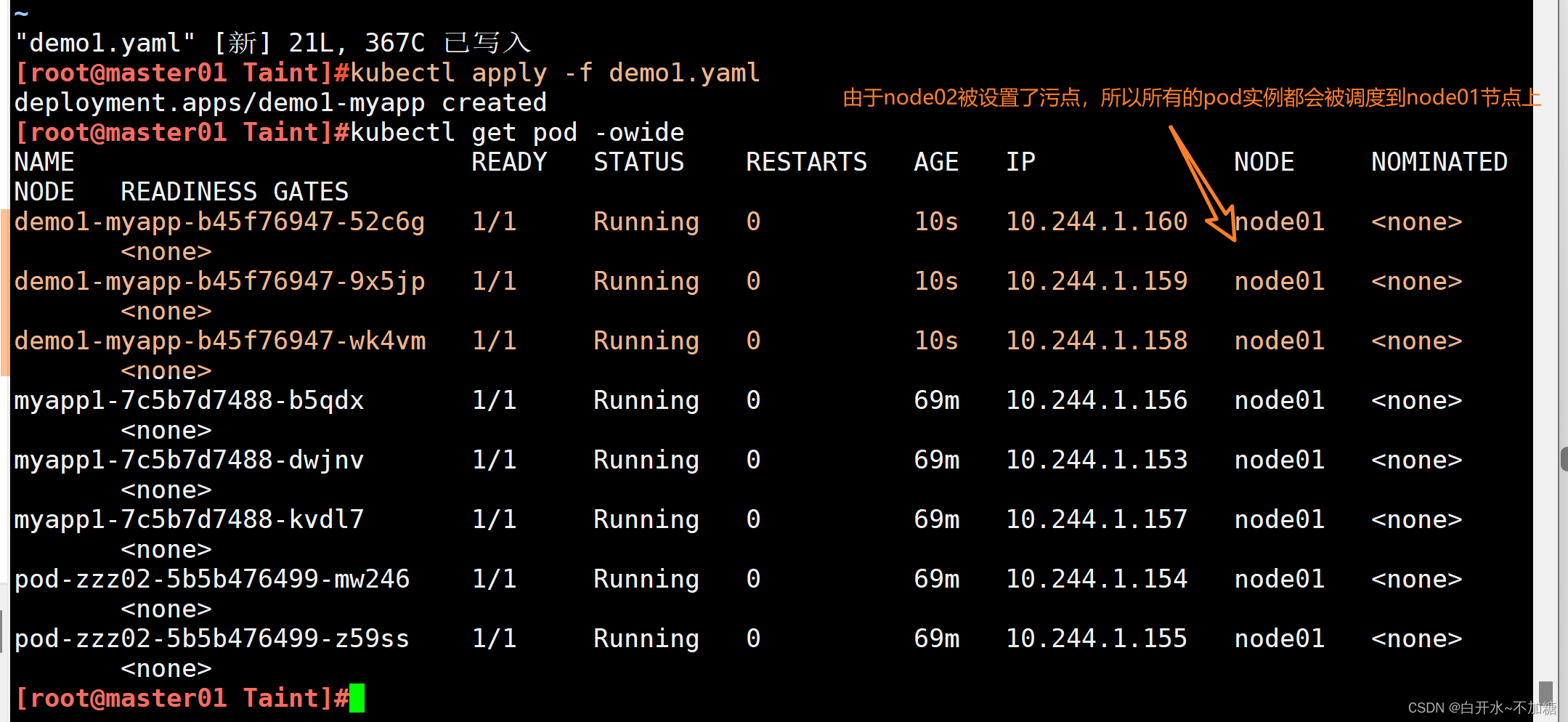
由于node02被設置了污點,所以所有的pod實例都會被調度到node01節點上
注釋
所以在設置污點時,最好新建一個標簽,或在hostname主機標簽等、各node節點值不一樣的標簽上設置污點
帶有污點的節點,可以使用nodeName選項繞過Scheduler調度創建
去除污點

二、容忍(Tolerations)
設置了污點的 Node 將根據 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之間產生互斥的關系,Pod 將在一定程度上不會被調度到 Node 上。但我們可以在 Pod 上設置容忍(Tolerations),意思是設置了容忍的 Pod 將可以容忍污點的存在,可以被調度到存在污點的 Node 上。
2.1容忍的定義
作用:通過配置容忍,管理員可以控制Pod在具有特定污點的節點上的行為,從而實現資源的精細管理和隔離。例如,可以使用容忍來確保某些Pod只能運行在具有特定硬件或軟件特性的節點上,或者防止Pod被驅逐到不受信任的節點上
位置:容忍定義在Pod的spec.tolerations字段中。
2.2容忍的組成
容忍通常包含以下幾個部分:
鍵(Key):與污點的鍵相匹配。
值(Value):與污點的值相匹配。如果不指定值,Pod將容忍所有值的同名污點。
效應(Effect):與污點的效應相匹配。常見的效應包括NoSchedule、PreferNoSchedule和NoExecute。
容忍期限(TolerationSeconds)(僅對NoExecute效應有效):指定Pod在節點被賦予NoExecute污點后,能夠繼續在該節點上運行的時間(以秒為單位)。超過這個時間后,Pod將被驅逐。
操作符(Operator):用于指定容忍與污點的匹配方式。常見的操作符包括Equal和Exists。Equal要求鍵、值和效應都完全匹配,而Exists只要求鍵和效應匹配。
2.3容忍的配置與管理
[root@master01 Taint]#vim demo2.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1tolerations: #定義Pod可以容忍的節點污點- key: "check" #污點的鍵。Pod可以容忍具有這個鍵的污點operator: "Equal" #定義如何與污點的值進行比較。Equal表示Pod僅容忍具有指定值的污點value: "nihao" effect: "NoExecute" #污點的效應tolerationSeconds: 60 #當Pod所在的節點被添加了匹配的污點后,Pod可以繼續在該節點上運行的時間(秒)#其中的 key、vaule、effect 都要與 Node 上設置的 taint 保持一致
#operator 的值為 Exists 將會忽略 value 值,即存在即可
#tolerationSeconds 用于描述當 Pod 需要被驅逐時可以在 Node 上繼續保留運行的時間#operator:表示如何與污點的值進行比較,此參數有Equal與Exists兩個選項
#Equal
'Pod將僅容忍節點上鍵(key)和值(value)與toleration中指定的鍵和值相匹配的污點。
例如node01節點上的pla=a,當toleration定義鍵和值為pla與a它會容忍,pla=b則不會容忍
如果value字段在容忍中未指定,則Equal操作符默認會使用空字符串作為值進行比較。'#Exists
'當operator設置為Exists時,Pod將容忍所有具有指定鍵(key)的污點,而不管它們的值(value)
是什么。這允許Pod容忍同一類別(即具有相同鍵)的所有污點,而不必指定特定的值。
例如當有pla這個鍵的所有節點都設置污點時,不需要指定值,所有含有pla鍵的節點,都會被容忍'---
tolerationSeconds:允許pod存在時間
'表示當Pod所在的節點被添加了匹配的污點后,Pod還可以繼續在該節點上運行的時間(秒)
例如上述文件中設置為40,表示該pod在有污點的節點上創建后,如果污點沒有被刪除,它只會
在節點上存在60秒,60秒后,將會被刪除
容忍部署
vim demo2.yaml apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1tolerations:- key: "check"operator: "Equal"value: "a"effect: "NoExecute"tolerationSeconds: 60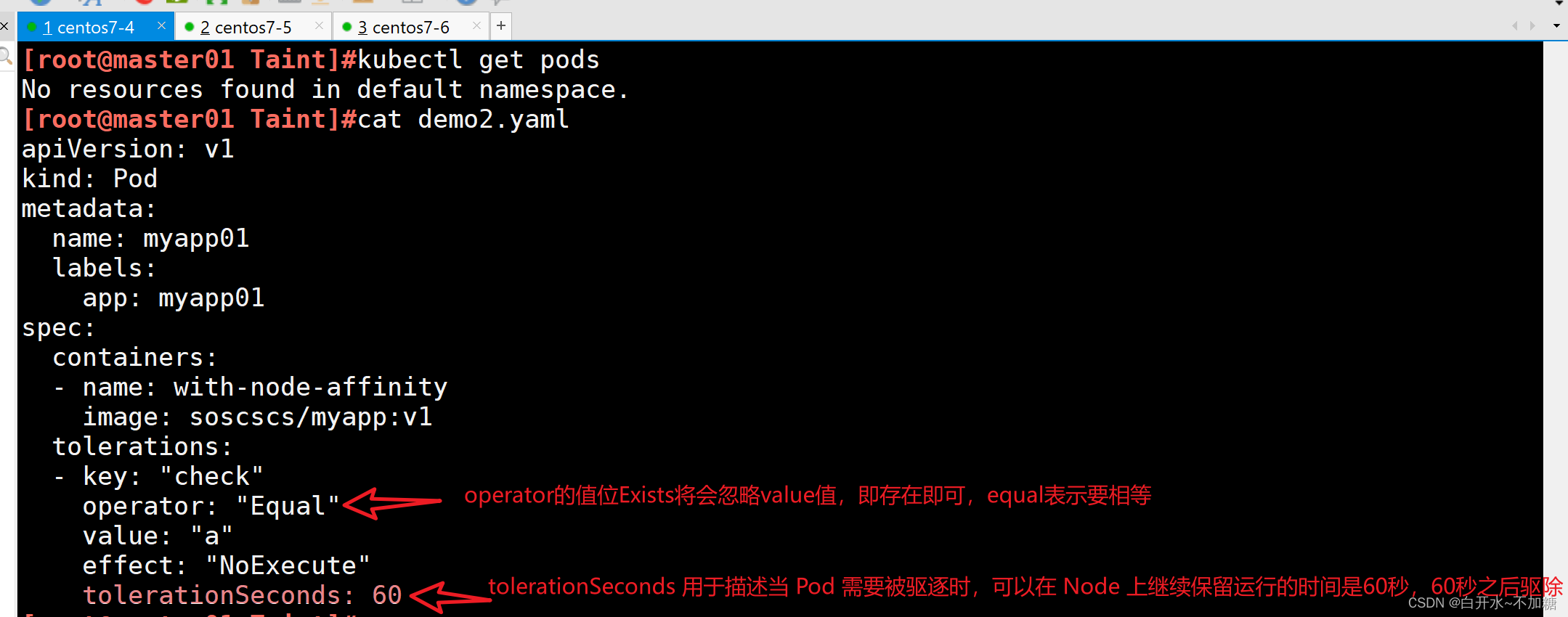
kubectl taint node node02 check=a:NoExecutekubectl apply -f demo2.yamlkubectl get pods -owide -w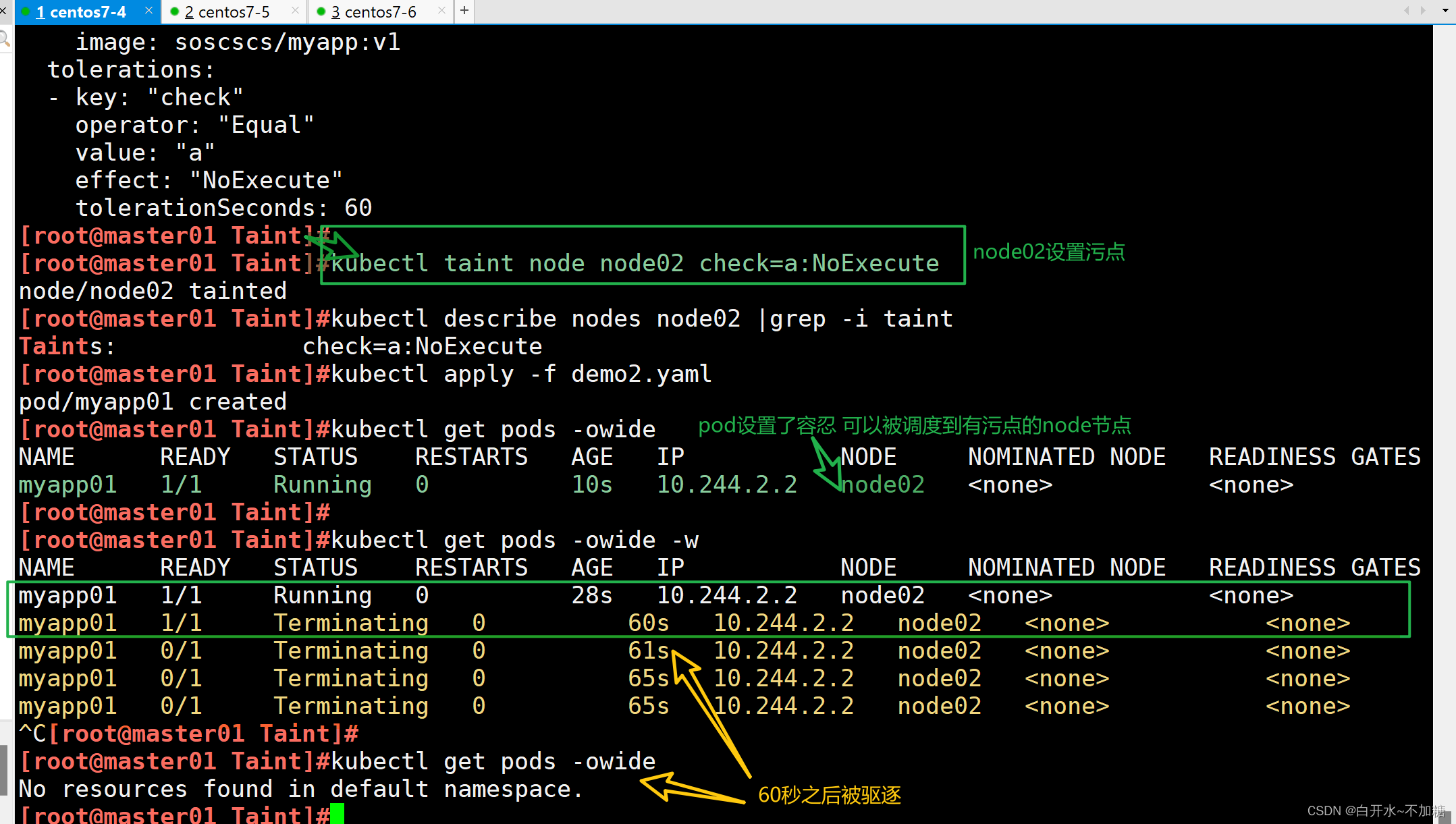
這里我們可以看到60秒后自動將污點進行了剔除,也就是我們設置了容忍60秒,這臺機器有污點,但是還是會調度在這臺機器上持續60秒,60秒左右后離開該機器
#其中的 key、vaule、effect 都要與 Node 上設置的 taint 保持一致
#operator 的值為 Exists 將會忽略 value 值,即存在即可
#tolerationSeconds 用于描述當 Pod 需要被驅逐時可以在 Node 上繼續保留運行的時間
2.4其它注意事項
- 當不指定 key 值時,表示容忍所有的污點 key
tolerations:- operator: "Exists"- 當不指定 effect 值時,表示容忍所有的污點作用
tolerations:- key: "key"operator: "Exists"- 有多個 Master 存在時,防止資源浪費,可以如下設置
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule//如果某個 Node 更新升級系統組件,為了防止業務長時間中斷,可以先在該 Node 設置 NoExecute 污點,把該 Node 上的 Pod 都驅逐出去
kubectl taint node node01 check=mycheck:NoExecute//此時如果別的 Node 資源不夠用,可臨時給 Master 設置 PreferNoSchedule 污點,讓 Pod 可在 Master 上臨時創建
kubectl taint node master node-role.kubernetes.io/master=:PreferNoSchedule//待所有 Node 的更新操作都完成后,再去除污點
kubectl taint node node01 check=mycheck:NoExecute-三、資源優化
3.1多master使用
當有多個master存在時,可以將備用的master的污點狀態設置為PreferNoSchedule,這樣的話,會盡可能避免此節點,當其它節點不可調用(資源頂峰、節點故障、節點更新等)時,可以使用master進行臨時調度,待資源恢復時,再將pod轉移
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule3.2Node更新
當某個node節點需要資源更新時,為防止業務長時間中斷,可以依次升級node,首先將需要升級的node節點設置污點,將pod資源調度到其它node節點上(如master資源充足也可以臨時調用),等到該節點升級完畢后,去除污點。依次類推,將所有節點更新升級?
kubectl taint node node-name key=value:NoExecute
#設置污點
-------------------------------------------------------------------------------
kubectl taint node node-name key:NoExecute-
#去除污點3.3維護操作
cordon 和 drain
##對節點執行維護操作:
kubectl get nodes
//將 Node 標記為不可調度的狀態,這樣就不會讓新創建的 Pod 在此 Node 上運行
kubectl cordon <NODE_NAME> #該node將會變為SchedulingDisabled狀態//kubectl drain 可以讓 Node 節點開始釋放所有 pod,并且不接收新的 pod 進程。drain 本意排水,意思是將出問題的 Node 下的 Pod 轉移到其它 Node 下運行
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-local-data --force--ignore-daemonsets:無視 DaemonSet 管理下的 Pod。
--delete-local-data:如果有 mount local volume 的 pod,會強制殺掉該 pod。
--force:強制釋放不是控制器管理的 Pod,例如 kube-proxy。注:執行 drain 命令,會自動做了兩件事情:
(1)設定此 node 為不可調度狀態(cordon)
(2)evict(驅逐)了 Pod//kubectl uncordon 將 Node 標記為可調度的狀態
kubectl uncordon <NODE_NAME>3.3.1cordon
作用:阻止新的 Pods 被調度到該節點上。當一個節點被標記為 cordon 時,已經在該節點上運行的 Pods 不會被驅逐,但新的 Pods 不會被調度到這個節點。
使用場景:通常用于節點的維護或升級,確保在維護期間不會有新的工作負載被分配到該節點上。


使用cordon指令,封鎖節點?#其污點狀態默認為node.kubernetes.io/unschedulable:NoSchedul
創建兩個pod,驗證下


恢復調度:使用 kubectl uncordon node01 命令可以恢復節點的調度狀態,允許新的 Pods 調度到該節點上。
[root@master01 data]#kubectl uncordon node01
node/node01 uncordoned
[root@master01 data]#kubectl describe nodes node01|grep -i taints
Taints: <none>
3.3.2?drain
作用:驅逐節點上的所有 Pods,即將它們從節點上移除并重新調度到其他可用的節點上。在執行 drain 操作時,可以指定一些選項,如忽略 DaemonSets 管理的 Pods,或者強制驅逐即使 Pods 有對應的容忍度。
使用場景:當需要對某個節點進行維護、升級或刪除時,可以使用 drain 命令來確保節點上的 Pods 被安全地遷移到其他節點。
命令示例:
kubectl drain node01:基本驅逐命令,會驅逐節點上的所有 Pods(除了 DaemonSets 管理的 Pods)。kubectl drain node01 --ignore-daemonsets=true:忽略 DaemonSets 管理的 Pods,驅逐其他所有 Pods。kubectl drain node01 --force --ignore-daemonsets --delete-local-data:強制驅逐所有 Pods(包括 DaemonSets),并刪除 Pods 的本地數據。注意,使用 --force 選項可能會導致數據丟失,請確保在使用前備份重要數據。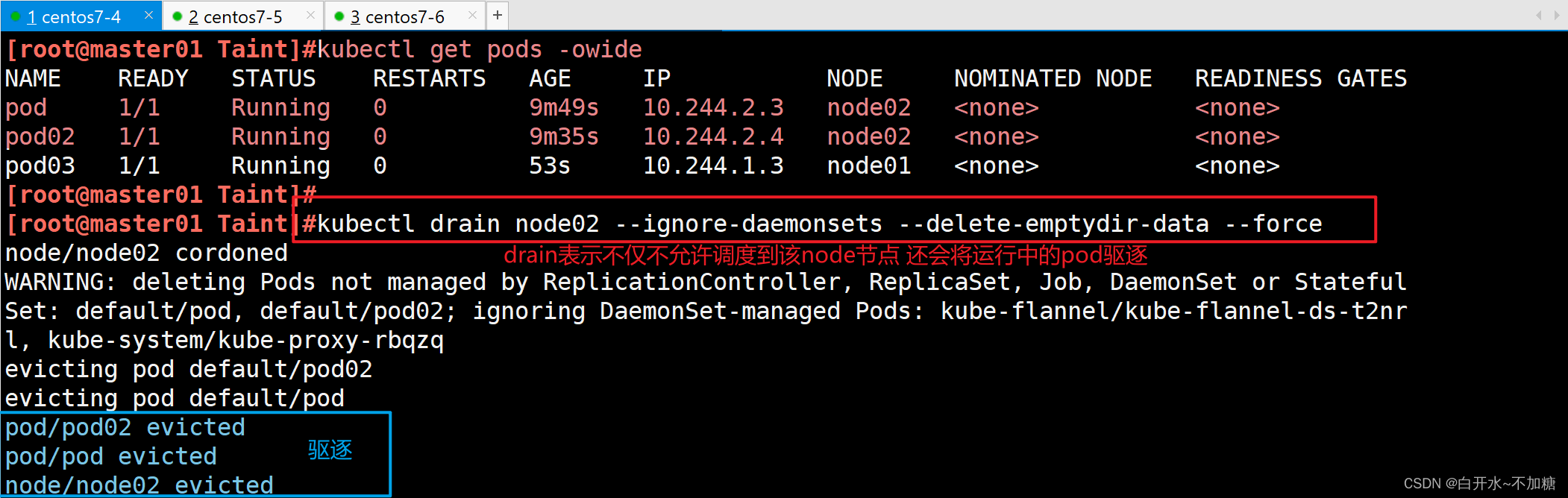
kubectl drain node02 --ignore-daemonsets --delete-emptydir-data --force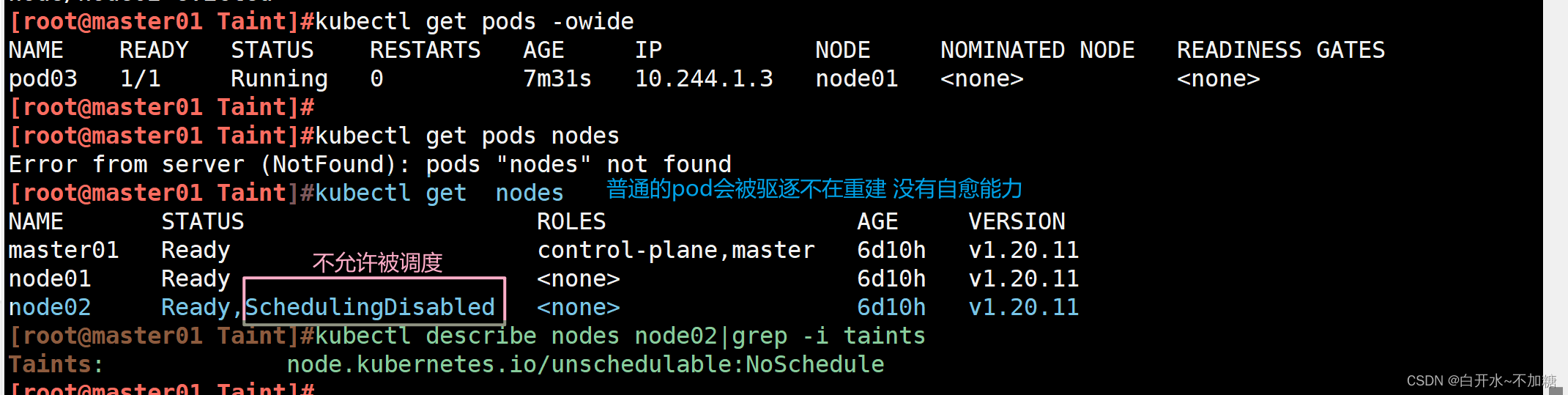
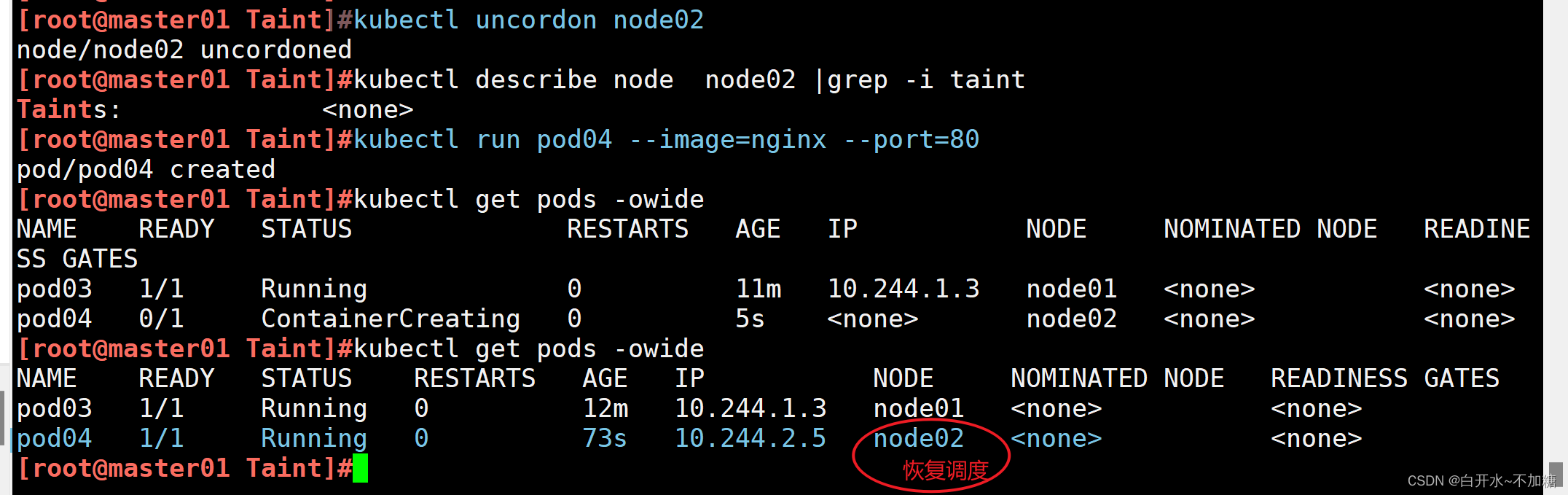
恢復調度:和 cordon 一樣,使用 kubectl uncordon node1 命令可以恢復節點的調度狀態。
[root@master01 Taint]#kubectl uncordon node02
node/node02 uncordoned
[root@master01 Taint]#kubectl describe node node02 |grep -i taint
Taints: <none>
注:執行 drain 命令,會自動做了兩件事情:
(1)設定此 node 為不可調度狀態(cordon)
(2)evict(驅逐)了 Pod??
簡單來說
cordon的作用類似于NoSchedule
drain的作用類似于NoExecute
3.3.3污點、容忍和驅逐
- 污點:是一種用于標記node節點的屬性,它會阻止調度器在該節點上進行創建Pod
- 容忍:用于標記Pod可以在哪些Node節點調度運行,如果一個節點擁有Pod容忍度中指定taint(污點),那么該節點上就可以調度Pod
- 驅逐:是指K8S集群中,刪除Pod的過程,Pod可以會被驅逐,因為節點已經無法繼續運行,或者因為需要將Pod從一個節點轉移到另一個節點
資源不足、硬件升級、 軟件升級等情況會用到驅逐
驅逐Node節點出去進行版本升級,升級結束后再加入

四、Pod啟動階段(相位 phase)
4.1Pod啟動階段
Pod 創建完之后,一直到持久運行起來,中間有很多步驟,也就有很多出錯的可能,因此會有很多不同的狀態。
一般來說,pod 這個過程包含以下幾個步驟:
(1)調度到某臺 node 上。kubernetes 根據一定的優先級算法選擇一臺 node 節點將其作為 Pod 運行的 node
(2)拉取鏡像
(3)掛載存儲配置等
(4)運行起來。如果有健康檢查,會根據檢查的結果來設置其狀態。
Pod啟動階段?
第一步:controller manager管理的控制器創建pod副本
第二步:scheduler調度器根據調度算法選擇最合適的node節點調度pod
第三步:kubelet拉取鏡像
第四步:kubelet掛載存儲卷
第五步:kubelet創建并運行容器
第六步:kubelet根據容器探針的探測結果設置Pod狀態
4.2phase 的可能狀態有
- Pending:表示APIServer創建了Pod資源對象并已經存入了etcd中,但是它并未被調度完成(比如還沒有調度到某臺node上),或者仍然處于從倉庫下載鏡像的過程中。
- Running:Pod已經被調度到某節點之上,并且Pod中所有容器都已經被kubelet創建。至少有一個容器正在運行,或者正處于啟動或者重啟狀態(也就是說Running狀態下的Pod不一定能被正常訪問)。
- Succeeded:有些pod不是長久運行的,比如job、cronjob,一段時間后Pod中的所有容器都被成功終止,并且不會再重啟。需要反饋任務執行的結果。
- Failed:Pod中的所有容器都已終止了,并且至少有一個容器是因為失敗終止。也就是說,容器以非0狀態退出或者被系統終止,比如 command 寫的有問題。
- Unknown:表示無法讀取 Pod 狀態,通常是 kube-controller-manager 無法與 Pod 通信。
?五、k8s常見的排障手段
在k8s的操作中,由于組件較多,任何一步有錯誤,都可能導致整個k8s集群陷入不可以狀態,下面我就結合工作中的一些操作做一總結
5.1環境設置
防火墻策略、核心防護可能會導致節點之間無法通信
swap分區會導致kubelet無法啟動,kubelet無法啟動,意味著網絡插件與kube-proxy容器無法啟動
集群信息:使用kubectl get node查看集群信息,確保節點之間通信正常
5.2pod事件處理
kubectl describe <資源類型> <資源名稱>:查看資源詳細信息
kubectl get events:指令查看所有事件信息,并使用grep過濾關鍵字?
kubectl exec –it pod_name bash :進入容器查看,只限于處于Running狀態
kubectl logs pod_name:查看pod日志,在Failed狀態下
journalctl -xefu kubelet:查看kubelet日志
//查看Pod事件
kubectl describe TYPE NAME_PREFIX //查看Pod日志(Failed狀態下)
kubectl logs <POD_NAME> [-c Container_NAME]//進入Pod(狀態為running,但是服務沒有提供)
kubectl exec –it <POD_NAME> bash//查看集群信息
kubectl get nodes//發現集群狀態正常
kubectl cluster-info//查看kubelet日志發現
journalctl -xefu kubelet5.3針對組件故障
kubectl get nodes 查看node節點運行狀態
kubectl describe nodes <node節點名稱> 查看node節點的詳細信息和資源描述
kubectl get cs 查看master組件的健康狀態
kubectl cluster-info 查看集群信息journalctl -u -f kubelet 跟蹤查看kubelet進程日志5.4針對pod故障
kubectl get pods -o wide 查看Pod的運行狀態和就緒狀態
kubectl describe <pods|其它資源類型> <資源名稱> 查看資源的詳細信息和事件描述,主要是針對處于Pending狀態的故障
kubectl logs <Pod資源名稱> -c <容器名稱> -f -p 查看Pod容器的主進程日志,主要是針對進入Running狀態后的故障,比如Failed異常問題
kubectl exec -it <Pod資源名稱> -c <容器名稱> sh|bash 進入Pod容器查看容器內部相關的狀態信息,比如進程、端口、文件、流量等狀態信息
kubectl debug -it <Pod資源名稱> --image=<臨時工具容器的鏡像名> --target=<目標容器> 在Pod中創建臨時工具容器進入目標容器進行調試,主要針對沒有調試工具的容器使用
nsenter -n --target <容器ID> 在Pod容器宿主機使用nsenter轉換網絡namespace,直接在宿主機進入目標容器的網絡命名空間進行抓包等調試工作5.5針對網絡故障
kubectl get svc 查看service資源的clusterIP、port、nodePort等信息
kubectl describe svc <svc資源名稱> 查看service資源的標簽選擇器、endpoints端點等信息
kubectl get pods --show-lables 查看Pod的標簽
?


)


-C++-OD統一考試(C卷D卷))

—— 深入了解導航控制)





)

能否同時支持多個實時數據庫?)
-Server端)

)
