一、混淆矩陣的定義
????????混淆矩陣是一種用于評估分類模型性能的評估指標。當模型對數據進行預測并將數據分配到預定義的類別時,混淆矩陣提供了一種直觀的方式來總結這些預測與數據實際類別之間的對應關系。具體來說,它是一個表格。
二、分類模型性能評估一級指標
分類模型的性能評估指標有三個等級,一級評估指標如下:
- 真正例(True Positives, TP):模型預測為正類,實際上也是正類的樣本數。
- 假正例(False Positives, FP):模型預測為正類,但實際上為負類的樣本數。
- 真負例(True Negatives, TN):模型預測為負類,實際上也是負類的樣本數。
- 假負例(False Negatives, FN):模型預測為負類,但實際上為正類的樣本數。
混淆矩陣就是根據一級分類指標得到的一張表。?
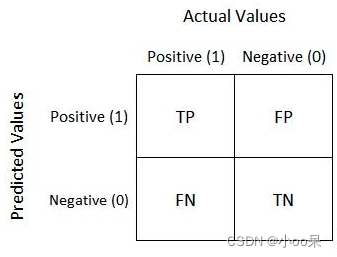
我自己的理解是三句話:
第一句:分類你可以理解成猜迷,猜的對不對用“T真,F假”來表示。
第二句:你猜的這個東西的時候,你猜測它類別是“P正”還是“N負”。
第三句:你猜的這個東西,它本身的分類用“標簽label”表示。
所以按照上面的三句話理解,舉幾個例子:
情況一:這個東西,本來的“標簽”是“正”的,我猜它是“正”,意味著我猜對了,故TP。
情況二:這個東西,本來的“標簽”是“負”的,我猜它是“負”,意味著我猜對了,故TN。
情況三:這個東西,本來的“標簽”是“正”的,我猜它是“負”,意味著我猜錯了,故FN。
情況四:這個東西,本來的“標簽”是“負”的,我猜它是“正”,意味著我猜錯了,故FP。
二、分類模型性能評估二級指標
????????分類模型的二級評估指標在之前的文章中提到過,但沒有總結過。因此在本文章簡單總結一下:
| 二級指標 | 公式 | 意義 |
| 準確率(Accuracy) | 分類模型所有判斷正確的結果占總觀測值的比重 | |
| 精確率(Precision) | 在模型預測是Positive的所有結果中,模型預測對的比重 | |
| 召回率(Recall) (又叫靈敏度Sensitivity) | 在真實值是Positive的所有結果中,模型預測對的比重 | |
| 特異度(Specificity) | 在真實值是Negative的所有結果中,模型預測對的比重 |
更多更詳細的知識點,在往期文章中有提到,下面是跳轉鏈接:
【機器學習300問】25、常見的模型評估指標有哪些?![]() https://blog.csdn.net/qq_39780701/article/details/136407056?
https://blog.csdn.net/qq_39780701/article/details/136407056?
三、分類模型新能評估三級指標
????????分類模型的三級評估指標就是F1分數,在之前的文章中提到過。這里就不贅述了。
【機器學習300問】32、F1分數是什么?![]() https://blog.csdn.net/qq_39780701/article/details/136607068
https://blog.csdn.net/qq_39780701/article/details/136607068
四、混淆矩陣舉例說明?
????????以一個圖片多分類問題為例,想要判斷一張圖片是“貓”、“狗”和“豬”其中的哪一種。

?混淆矩陣中的數值是樣本數量,如果我們要計算準確率accuracy,那么可以統計所有表中數字的總和做分母。對角線相加做分子(因為對角線上的元素代表模型預測結果是正確的)。可以算出



















