基本步驟
①首先準備好數據集(DataSet)
②模型的選擇或者設計(Model)
③進行訓練(Train)大部分模型都需要訓練,有些不需要。這一步后我們會確定不同特征的權重
④推理(inferring)

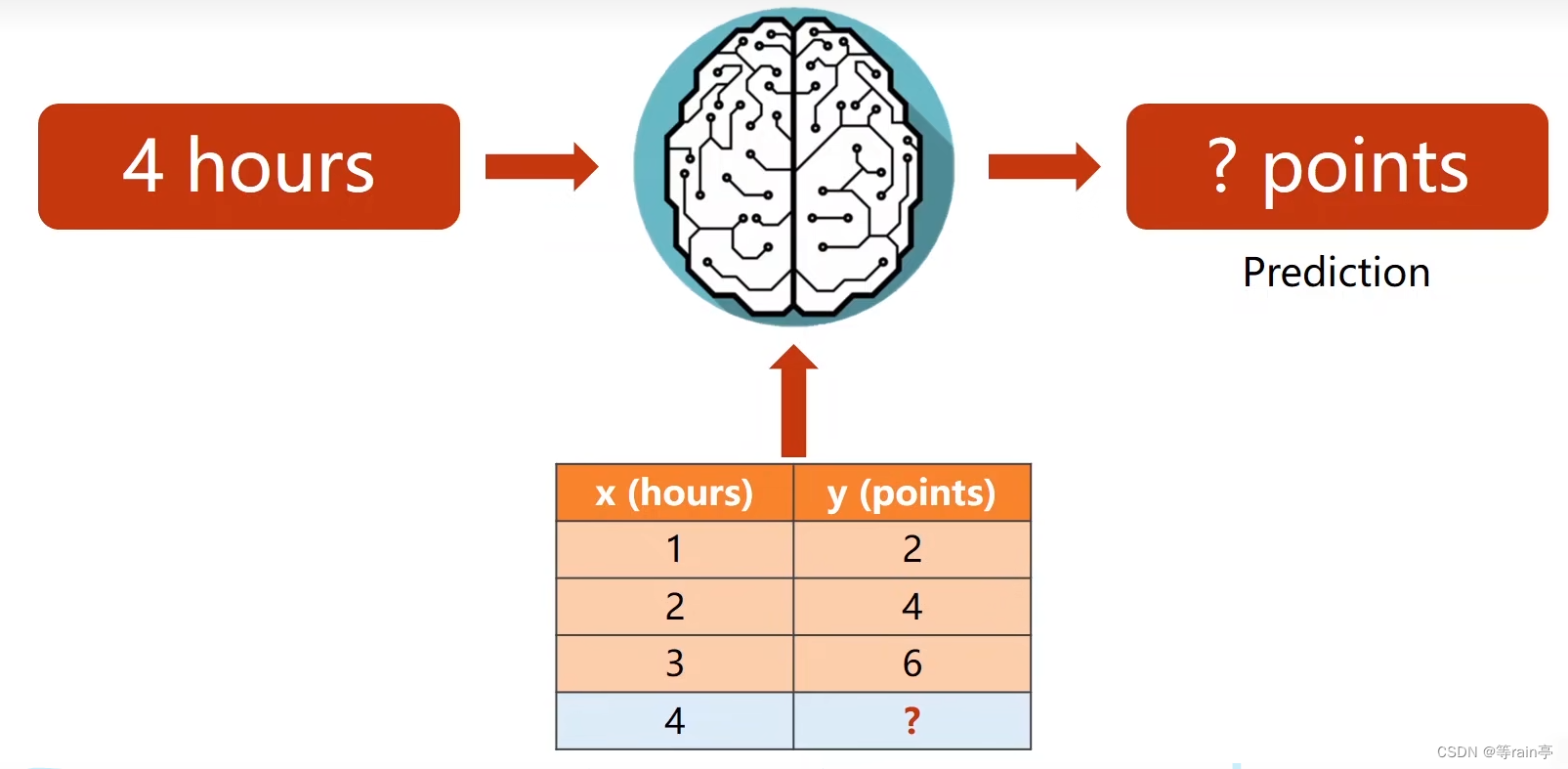
1,2,3hours會有一個結果2,4,6points。這個就是訓練過程,把x和y都給模型,讓他自己學。5hours這個沒有一個對應的y,這個就是我們的預測過程(相當于上面的題目學完了后,現在寫這個題,看能不能寫對)。
對應的就是下圖,表格中的就是DataSet,給機器學習后,傳入4hours(Input)最后得到一個預測結果Output。
數據集DataSet
當然,其實在訓練表中這個4hours其實可以為testSet測試集。在訓練過程中這個對應的y看不見(引用我一位師兄的話,這個其實就是小測驗,最后需要我們預測的那個過程才是期末考試)。因為不能訓練完就直接用,因為這個太不夠準確,需要test進行測試。
所以我們通常在訓練的過程中,通常不會把我們所有的DataSet全部設置為訓練集,還有一部分設測試集。
接下來有一個很大的問題就是數據集,如果我們給定的數據集很片面,不夠完全,我們可能在訓練后出現過擬合的現象(只認識這些訓練的內容),我們希望最終可以有一個比較泛化的能力,在遇到沒見過的圖也可以識別我們學習的內容(也就是我們學習時常說的掌握方法,舉一反三)。
設計模型(Design Model)
什么是一個比較好的模型?
先用線性模型先試試,因為這個比較基本且簡單。如果效果不好再換其他模型。對于我們上面表格中的幾個數據,我們看出,其實比較符合線性的規則。

上面這條線是我們真實值的線。
?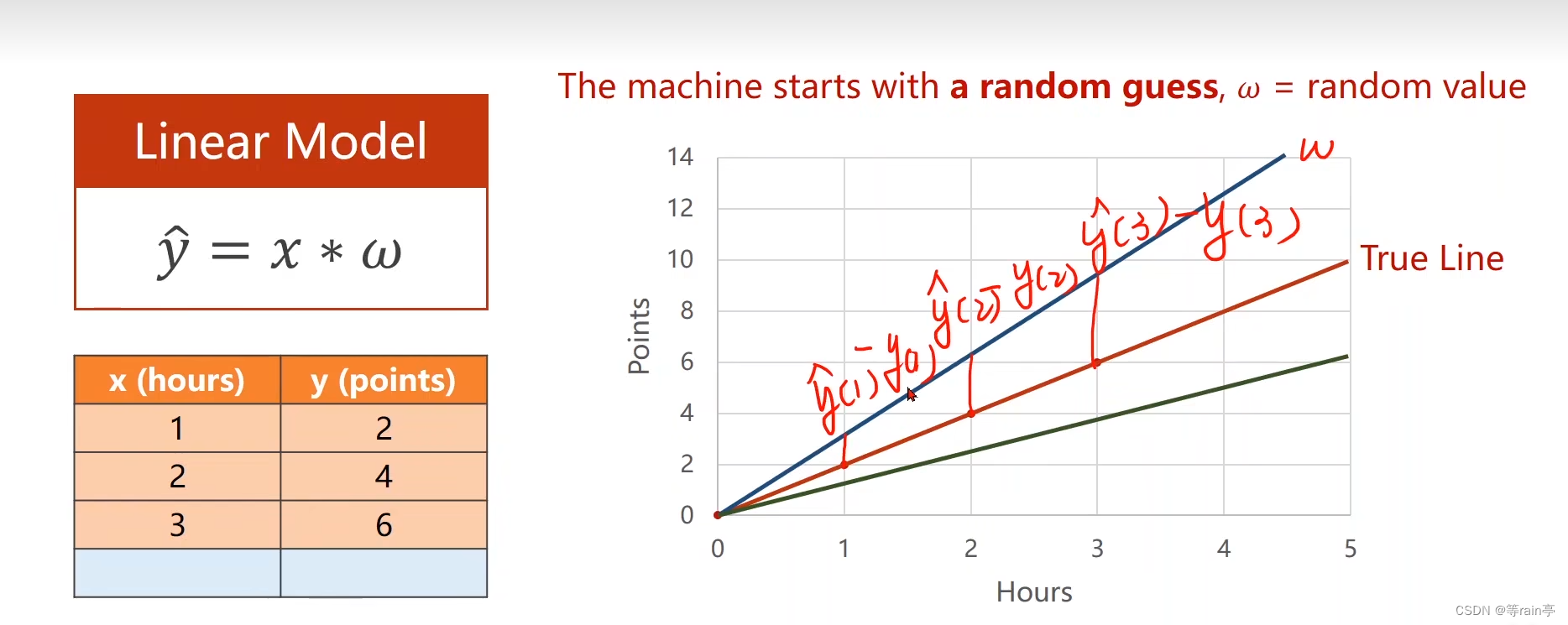 由于我們給的數據比較簡單,但是現實是很少會出現這樣的情況的。所以通常來說會線隨機預測一個w(權重weight),然后通過在1,2,3hours對應的points與真實值進行對比,evaluate Model Error 。我們就把這個評估模型稱為損失loss。
由于我們給的數據比較簡單,但是現實是很少會出現這樣的情況的。所以通常來說會線隨機預測一個w(權重weight),然后通過在1,2,3hours對應的points與真實值進行對比,evaluate Model Error 。我們就把這個評估模型稱為損失loss。
如果我們現在假設這個w為3,按照我們loss的公式。? 分別計算出loss值,最后測得平均的loss值。
 當然你也可以假設不同的w,看看哪一種的loss最小。
當然你也可以假設不同的w,看看哪一種的loss最小。

這個是兩個可能會使用的公式。
 通過計算得到這樣的結果,當然通常很難算出0這個值,所以在找w的時候可以使用窮舉法。也就是如下圖,把在0-4之間的每個值都算一下,找到最小的loss。
通過計算得到這樣的結果,當然通常很難算出0這個值,所以在找w的時候可以使用窮舉法。也就是如下圖,把在0-4之間的每個值都算一下,找到最小的loss。
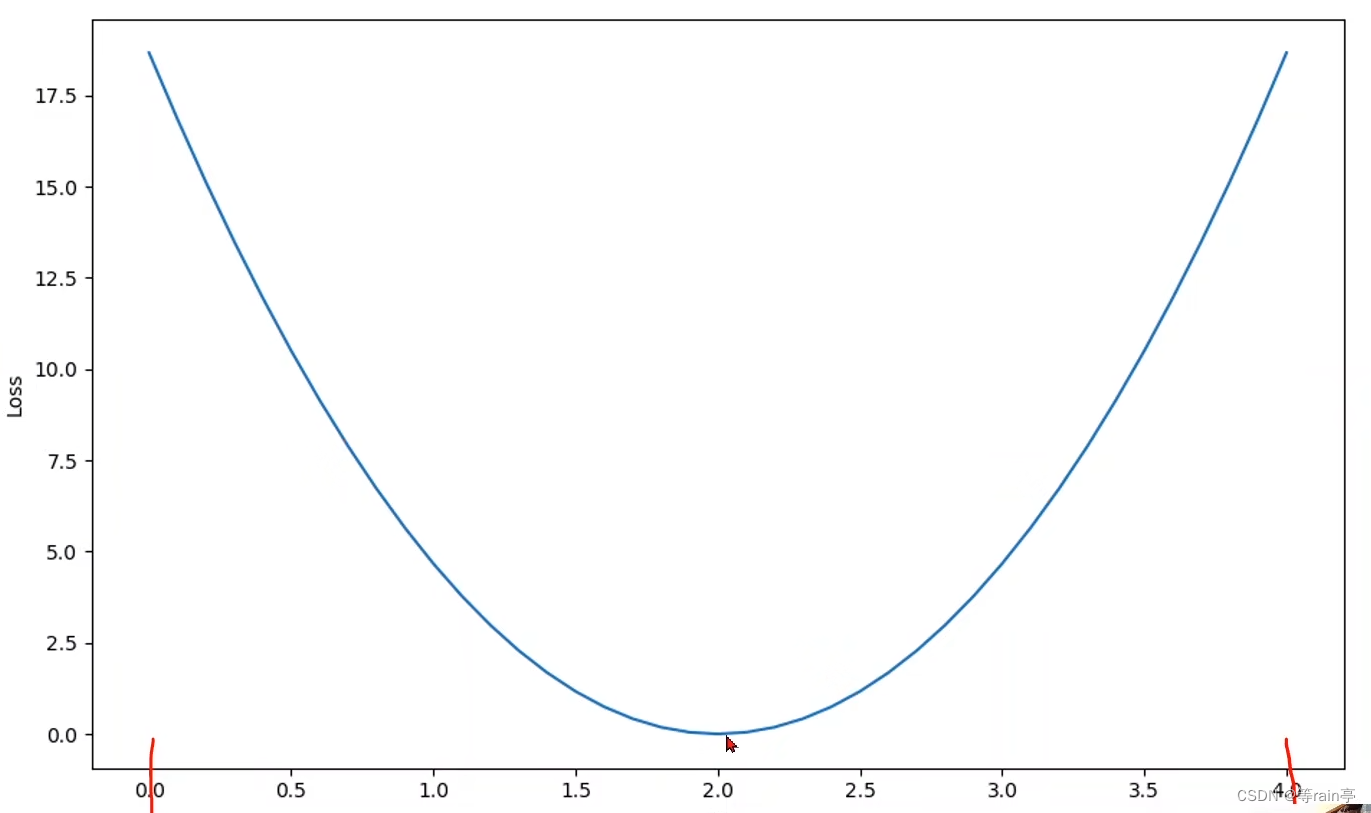 但是我們無法在實數域中把所有的值都找出來,所以實現上圖采用的代碼如下。?
但是我們無法在實數域中把所有的值都找出來,所以實現上圖采用的代碼如下。?
import numpy as np
import matplotlib.pyplot as pltx_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]def forword(x):return x*wdef loss(x,y):y_pred = forword(x)return (y_pred-y)*(y_pred-y)w_list = []
mse_lis = []for w in np.arange(0.0,4.0,0.1):print('w',w)l_sum = 0for x_val,y_val in zip(x_data,y_data):y_pred_val = forword(x_val)loss_val = loss(x_val,y_val)l_sum+=loss_valprint('\t',x_val,y_val,y_pred_val,loss_val)print('MSE=',l_sum/3)w_list.append(w)mse_lis.append(l_sum/3)運行結果為:
 ?畫圖:
?畫圖:
plt.plot(w_list,mse_lis)
plt.ylabel('Lose')
plt.xlabel('W')
plt.show?
但是這里需要提一下,通常我們的橫坐標不是w,我們訓練通常讓橫坐標為epoch(訓練幾輪)
下面這張圖是昨天剛訓練完的一個結果,注意在訓練過程中一定要注意存盤,因為往往訓練時間很長,如果出錯就要重新訓練,所以我們要記住定時存盤。還有要注意可視化問題,希望在訓練過程中得到的結果可視化出來,讓我們更好去判斷結果。



)



)


)









