配置文件(config)
- 由于在大型項目中,一種模型需要分:tiny、small、big等很多種,而它們的區別主要在網絡結構,數據的加載,訓練策略等,且差別很多都很小,所以如果每個模型都手動從頭寫一份,很麻煩,為了方便,現在都是直接采用配置文件的形式來定義
- 如yaml文件、py文件等
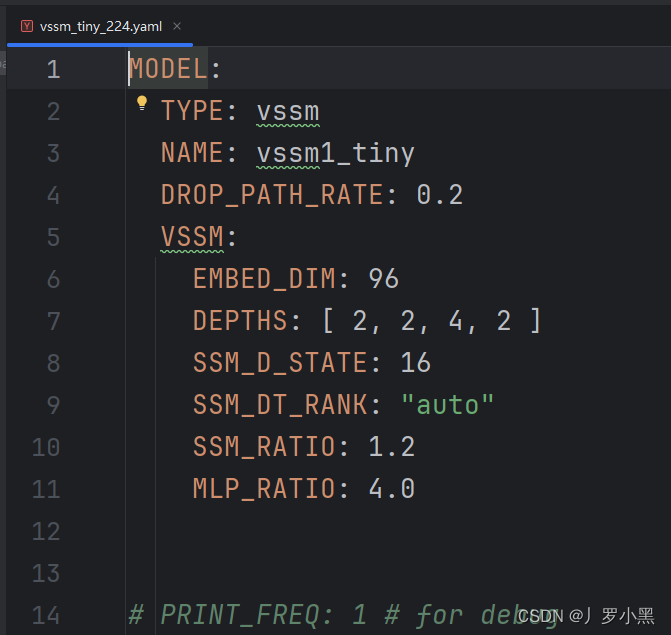
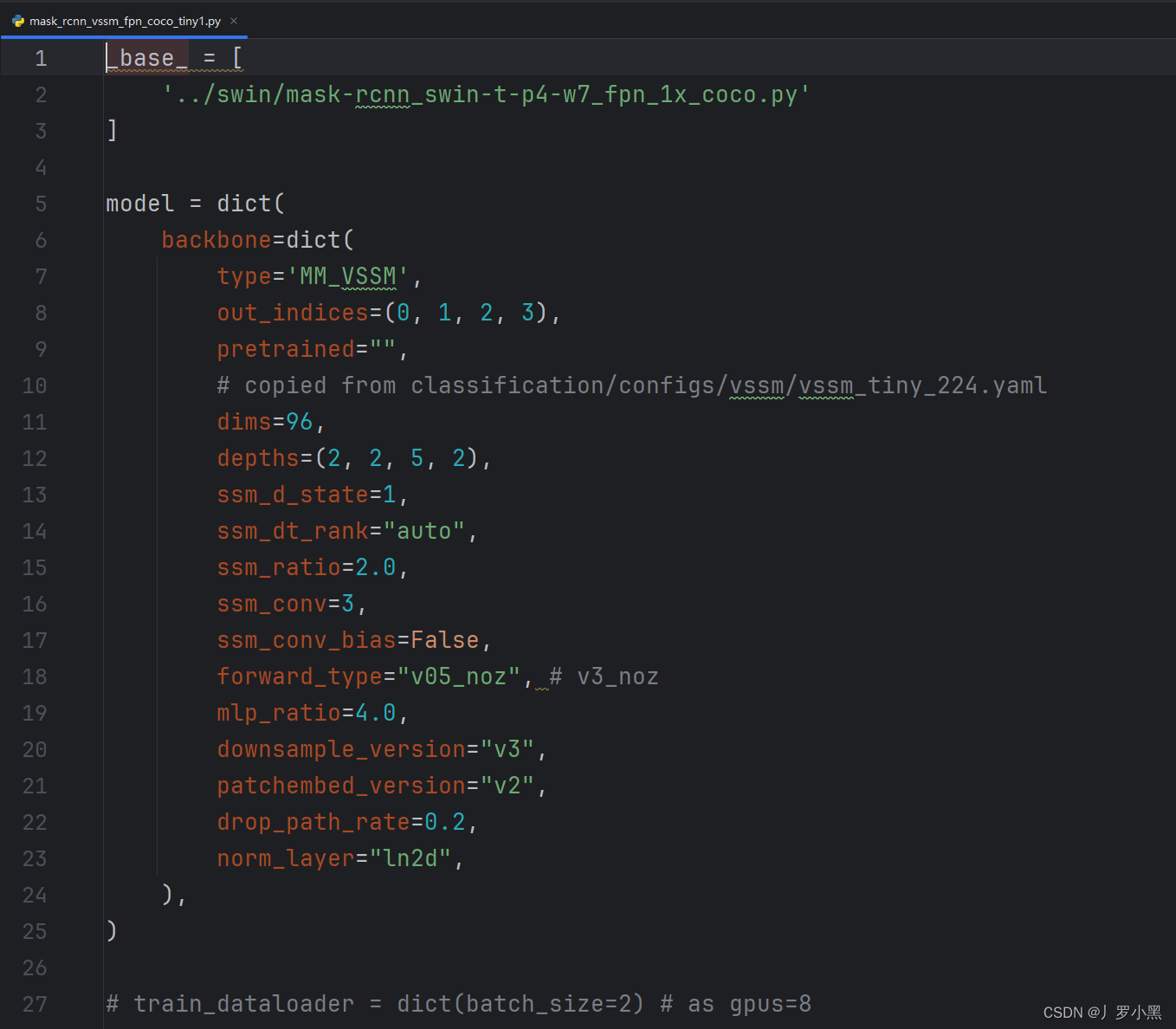
MMdetection的配置文件構成
- 在MMdection的配置文件中,我們根據字段來定義模型訓練的各部分

- 配置文件的運作方式
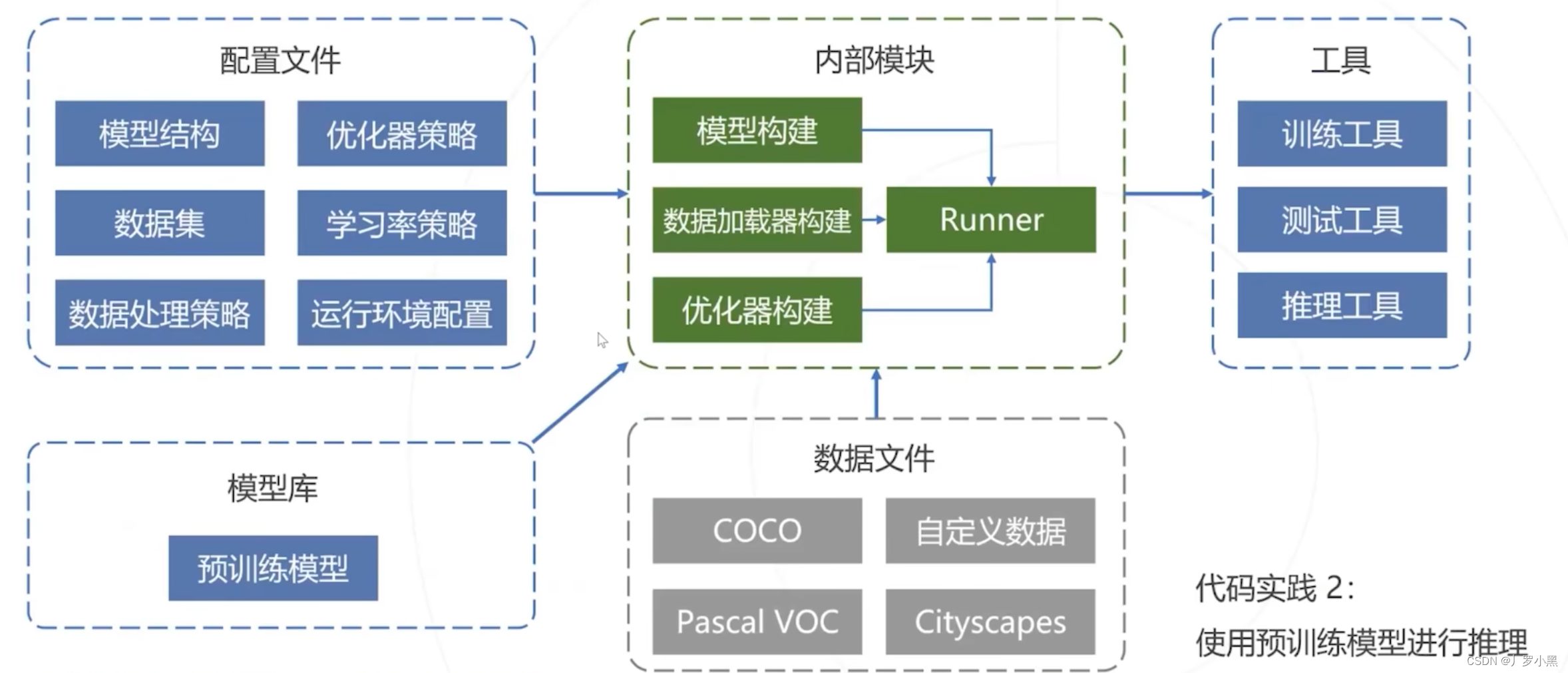
使用MMdection來訓練自己的檢測模型
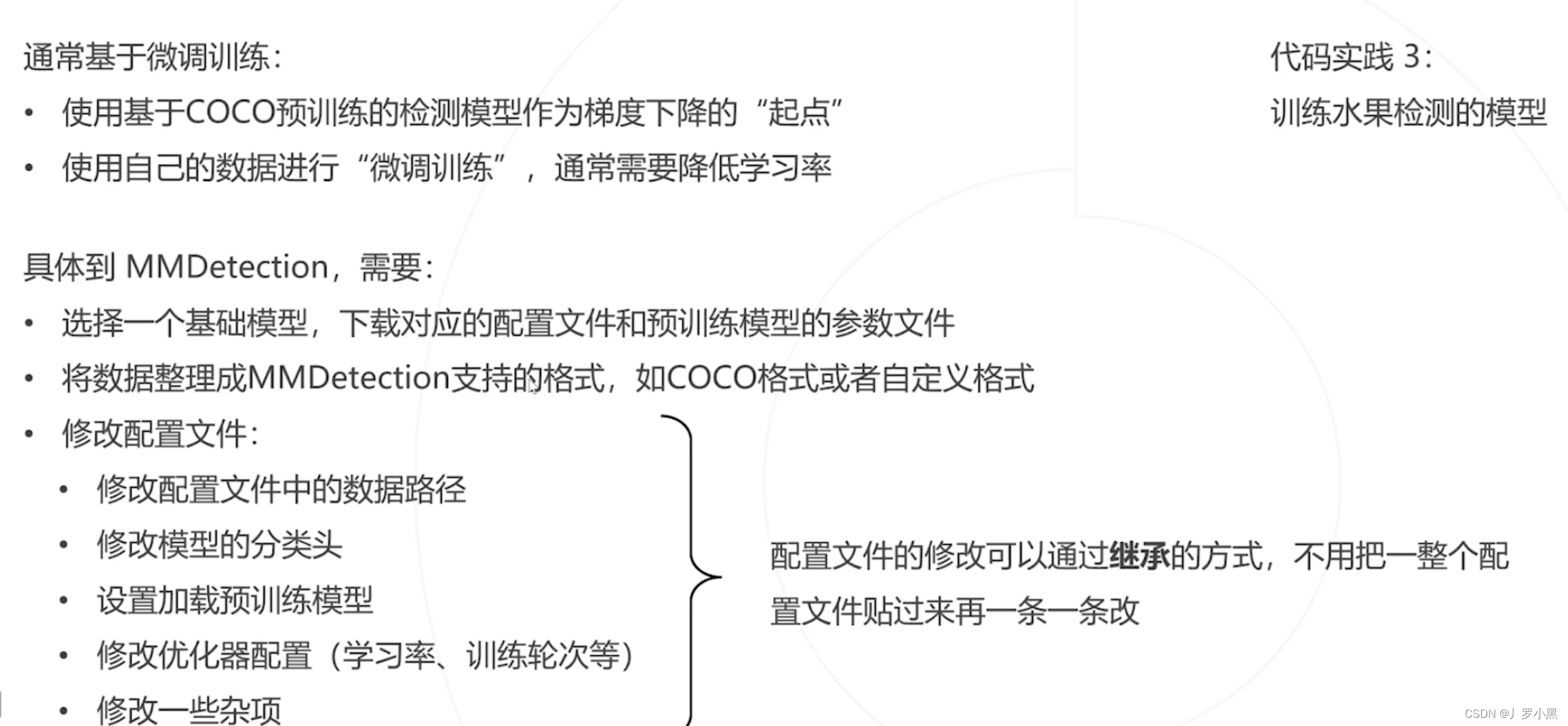
-
coco數據集的組織形式

-
coco數據集的標注格式
-
所有標注信息存儲在一個JSON對象中,包含以下信息:images–所有原始圖像信息、annotations–所有標注信息、categories–全部物體類別信息



-
其中:name表示當前的物體類別,supercategories表示當前物體的超類,如car的超類為vehicle
-
我們將自己的數據集按照以上的格式整理好后,還需要更改模型的配置文件(有些模型是繼承coco_instance.py,需要仔細查找),如下:
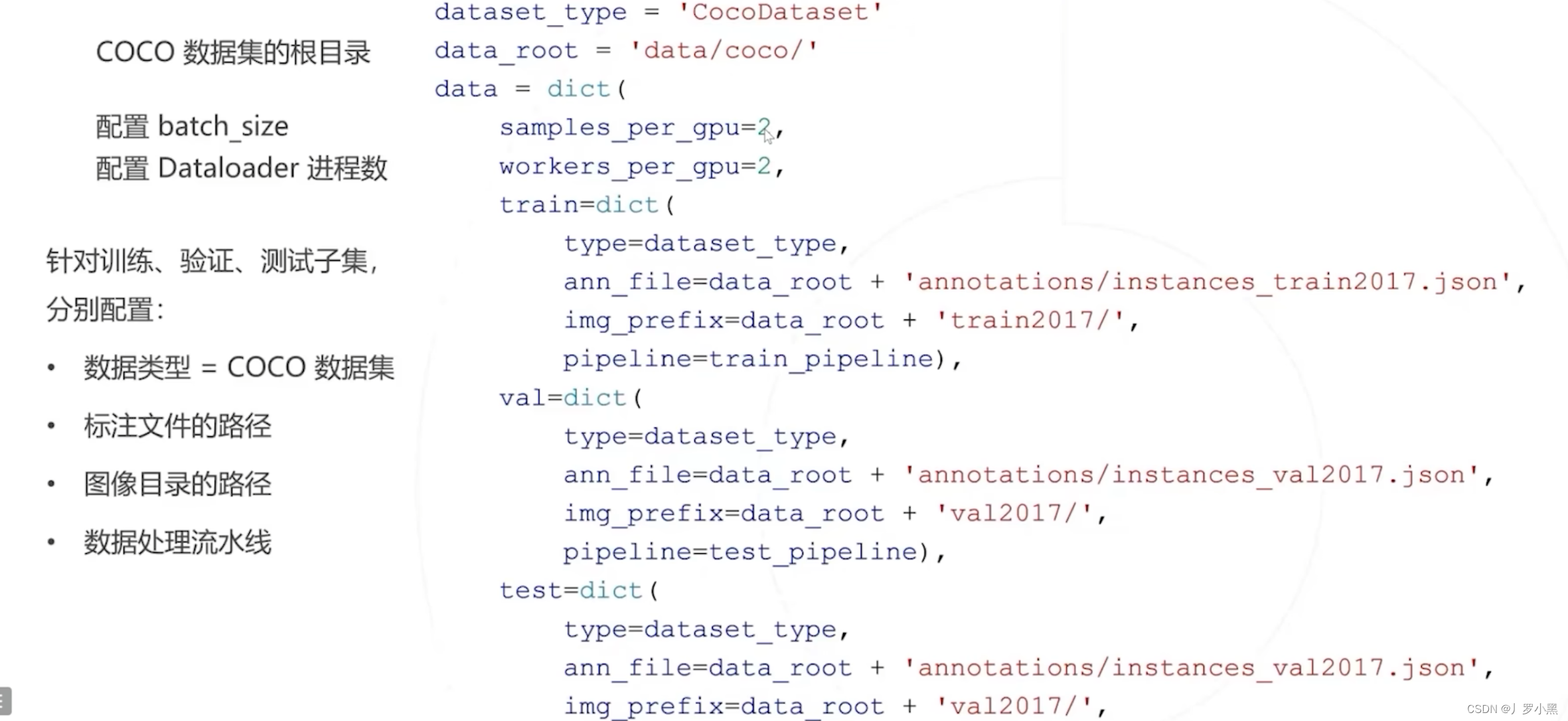
-
重點是需要修改:數據集的路徑、batch_size、進程數
-
在將原始圖像輸入進模型之前,我們可能還需要對圖像進行:隨機裁剪與縮放、水平翻轉、像素值歸一化、轉換為PyTorch Tensor等操作,這些操作我們統一放在數據處理流水線,即pipeline中。對于微調訓練,通常情況是不需要進行更改的
-
下圖為分類的pipeline:

-
由于檢測有框,所以多了一個annotations,對于框也需要進行跟原始圖片一樣的操作,下圖是檢測的:

)
)




:QStyle類)
)


)
)


)




