在當今快速發展的人工智能領域,大型語言模型(LLMs)正成為科學研究的新興工具。這些模型以其卓越的語言處理能力和零樣本推理而聞名,為解決傳統科學問題提供了全新的途徑。然而,LLMs在特定科學領域的應用面臨挑戰,主要是因為它們缺乏對復雜科學概念的深入理解。
為了克服這一難題,本文提出了一種創新的“領域知識嵌入的提示工程”方法,旨在通過將特定領域的知識整合到提示(prompts)中,來增強大型語言模型(LLMs)在科學領域特別是化學、生物學和材料科學中的應用性能。這種方法在包括能力、準確性、F1分數和幻覺下降等指標上,超越了傳統的提示工程策略。通過針對復雜材料(如MacMillan催化劑、紫杉醇和鋰鈷氧化物)的案例研究,展示了該方法的有效性,并強調了當LLMs配備特定領域的提示時,它們作為科學發現和創新的強大工具的潛力。
方法
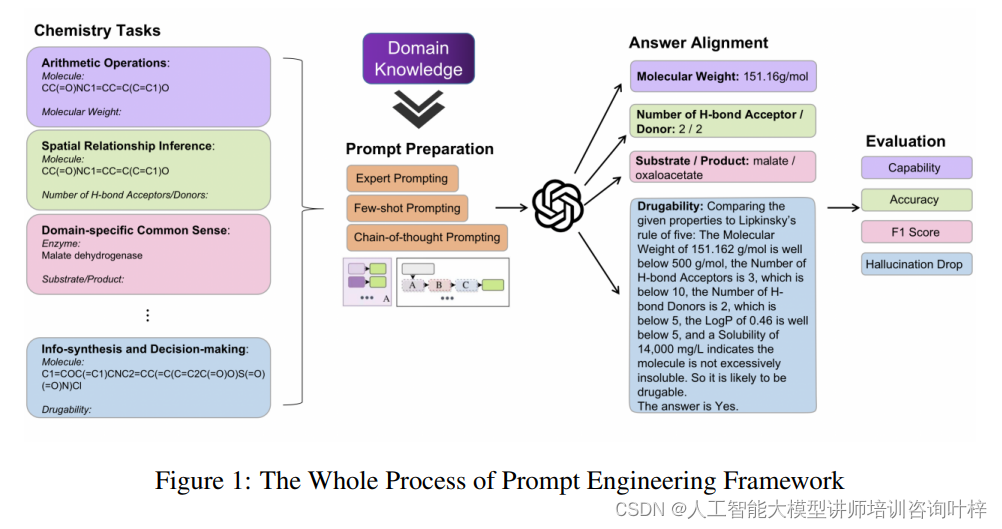
這種方法的核心思想是利用領域專家的知識和推理過程來指導LLMs,使其能夠生成更準確、更具相關性的回答。圖1展示了“提示工程框架的整個過程”(The Whole Process of Prompt Engineering Framework)。該框架從數據集的構建開始,研究人員首先從化學、生物學和材料科學領域中收集和整理相關的信息,創建了專門針對這些領域的數據集。接著,這些數據被用來形成特定的任務,這些任務旨在評估和提升大型語言模型(LLMs)在特定科學問題上的表現。
數據集構建和答案評估方案
數據集的構建是一個關鍵步驟,它直接影響了后續評估大型語言模型(LLMs)性能的準確性和可靠性。研究團隊采取了一種系統化的方法來選擇和構建數據集,以確保它們能夠全面覆蓋化學工程領域的關鍵方面。
首先,團隊將焦點放在了有機小分子、酶和晶體材料這三個類別上。這些類別不僅在化學工程中具有廣泛的應用,而且各自代表了不同的科學規模和復雜性。有機小分子常用于制藥開發和作為分子探針,酶在生物催化和治療干預中扮演著關鍵角色,而晶體材料則是半導體技術和光伏設備中不可或缺的組成部分。
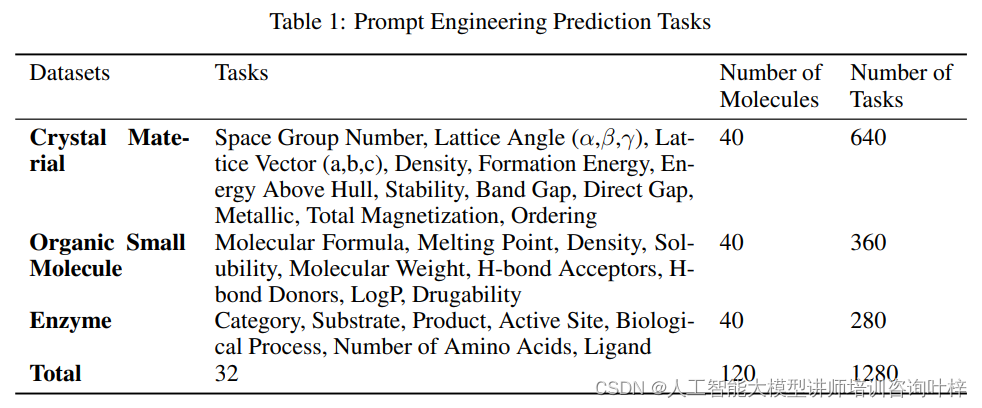
為了確保數據集的質量和相關性,研究團隊從專業的數據庫中提取了數據。例如,有機小分子的數據來源于PubChem數據庫,這是一個包含大量化學結構和相關屬性信息的公共數據庫。對于酶,團隊從UniProt數據庫中提取信息,這是一個提供蛋白質序列和功能信息的數據庫,其數據來源于科學文獻和計算分析。晶體材料的數據則來自Materials Project數據庫,該數據庫提供材料屬性和晶體結構的信息。
在提取了這些物質的信息后,研究團隊設計了一系列問題,這些問題旨在評估LLMs在預測和推理這些物質的物理化學屬性、生物過程和結構信息方面的能力。這些問題覆蓋了從基本的物理化學屬性,如分子公式、熔點、密度、溶解度、分子量,到更復雜的生物過程,如酶的活性位點、底物、產物和生物學途徑。
研究團隊還考慮了不同任務的輸出類型、推理范式和鏈式思考(CoT)的復雜性,將問題分為不同的組別。例如,一些任務可能只需要通過邏輯推理就能得出數值答案,而另一些任務則可能需要依賴實驗數據。一些任務可能需要特定的領域知識來進行文字推理,而其他任務則可能涉及到常見的或不常見的屬性檢索。
為了評估LLMs的性能,研究者們特別設計了一套綜合性能評價體系。這套體系通過多個維度來衡量模型的性能,包括能力(Capability)、準確性(Accuracy)、F1分數(F1 Score)和幻覺下降(Hallucination Drop)。這些指標共同構成了一個多角度的評價框架,旨在深入理解模型在處理科學問題時的實際能力。
能力(Capability):這一指標關注的是模型是否能夠對提出的問題給出回答。不同于準確性,能力指標不評價答案的正確性,而是衡量模型對問題的響應能力。如果模型能夠針對問題生成一個回答,無論答案的正確與否,該指標都會給予正面評價。這種評價方式有助于識別模型在特定任務上的可行性,即使在答案不完全準確的情況下。
準確性(Accuracy):與能力指標相輔相成,準確性指標衡量的是模型給出的答案與真實答案之間的一致性。在這一指標下,答案越接近真實情況,獲得的評分就越高。準確性是評價模型性能的關鍵因素,因為它直接關系到模型輸出的可靠性。
F1分數(F1 Score):F1分數是精度(Precision)和召回率(Recall)的調和平均值,常用于評估分類任務的性能。在這項研究中,F1分數用于評估模型在多項選擇題中的表現。一個高的F1分數意味著模型在保持高精確度的同時,也能夠覆蓋到更多的正確答案,從而在綜合評價模型性能時提供了一個平衡的視角。
幻覺下降(Hallucination Drop):這一指標是研究者們為了評估模型產生不準確或“幻覺”回答的傾向而特別引入的。幻覺現象指的是模型在沒有足夠信息支持的情況下,仍然生成看似合理但實際錯誤的答案。幻覺下降指標通過計算模型回答的能力與其準確性之間的差異來量化這一現象,從而幫助研究者識別和改進模型在特定任務上可能出現的問題。
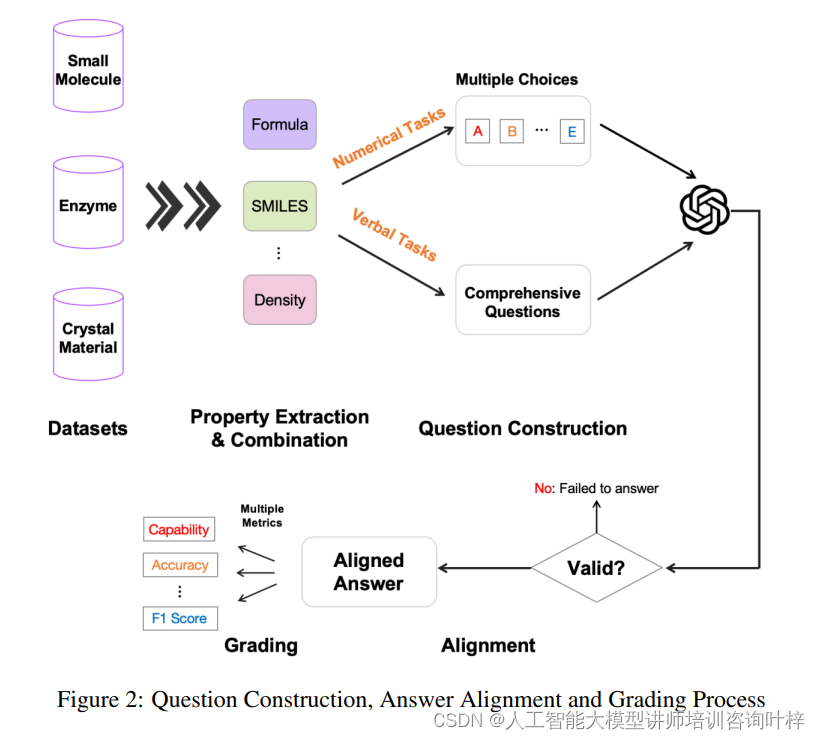
圖2展示了問題構建和答案評估過程的流程。首先,他們會將模型對于每個問題的回答與真實答案進行比較,然后根據上述指標進行打分。例如,在能力指標的評價中,只要模型給出了回答,無論對錯,都會得到一定的分數。而在準確性指標的評價中,答案與真實答案的一致性將直接影響得分。F1分數則需要模型在多項選擇題中的表現既要精確又要全面。最后,幻覺下降指標會根據模型在能力與準確性上的表現差異來計算。
科學預測作為LLM問答問題:
科學預測任務的構建和執行是一個精心設計的流程,它充分利用了大型語言模型(LLMs)的先進能力,尤其是它們的零樣本(zero-shot)和少樣本(few-shot)推理能力。這些能力使得LLMs能夠在沒有針對特定任務進行過專門訓練的情況下,通過理解問題的上下文來生成回答。
研究者們首先將科學問題轉化為LLMs可以處理的問答形式。這種形式允許模型通過分析問題的文本描述來識別關鍵信息,并據此生成答案。例如,一個關于化合物穩定性的問題可能會被構建為:“給定化合物X的屬性Y,它是穩定的嗎?”這樣的格式不僅清晰地指出了問題的核心,也為模型提供了生成答案所需的直接線索。
在提示工程的過程中,研究者們特別關注了提示詞的上下文確定。提示詞是直接呈現給模型的問題描述,它們的選擇和構造對于引導模型生成準確答案至關重要。這個過程可以數學化地表達,即通過確定提示詞P的上下文,使得LLMs能夠有效地給出答案A。這可以表示為函數f(P, Q),其中Q是原始問題,P是提示,A是模型生成的答案,而f代表LLMs本身。
為了優化提示,研究者們采取了一種系統化的方法來評估不同提示對模型輸出的影響。他們的目標是找到能夠最大化模型輸出與真實答案S一致性的提示。這涉及到一個優化問題,可以通過搜索不同的提示詞P來解決。優化的目標是最大化一個評估函數g(f(P, Q), S),該函數衡量模型答案A與真實答案S的一致性。

圖3闡述了不同提示工程方法的主流形式。這些方法包括零樣本提示(Zero-shot Prompting)、少樣本提示(Few-shot Prompting)、專家提示(Expert Prompting)、零樣本鏈式思考(Zero-shot CoT)和少樣本鏈式思考(Few-shot CoT)。在零樣本提示中,LLMs被要求直接回答問題,而不提供任何上下文或示例。少樣本提示則提供了幾個示例,幫助模型理解并復制回答的格式和內容。專家提示通過角色扮演指導,使LLMs能夠生成類似專家所寫的回答。零樣本CoT提示通過加入“讓我們逐步思考”的觸發句,引導模型進行逐步的推理過程。而少樣本CoT提示則進一步提供了解決類似問題的思考鏈示例,以協助模型執行當前任務。
在實際操作中,研究者們可能會測試多個版本的提示,并評估它們在一組科學問題上的表現。他們可能會使用不同的提示策略,并比較這些策略在能力、準確性、F1分數和幻覺下降等指標上的表現。例如,如果研究者們正在處理一個關于晶體材料帶隙的問題,他們可能會設計一個提示,如:“晶體材料的帶隙是指...(這里提供帶隙的定義和重要性),給定材料Z的電子結構,它的帶隙是多少?”這樣的提示不僅提供了問題的具體信息,還通過定義和背景信息來引導模型進行推理。
領域知識嵌入的提示工程:
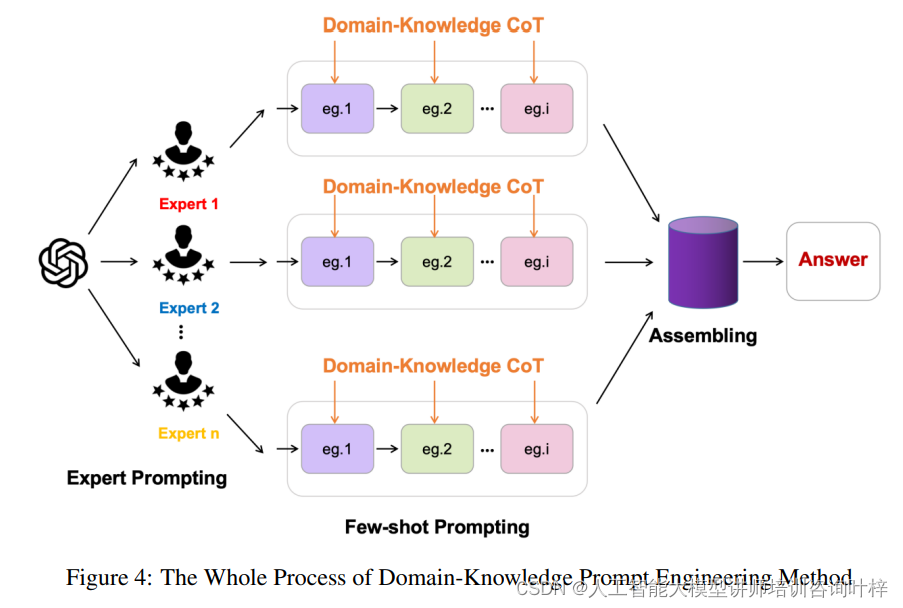
領域知識嵌入的提示工程策略是這項研究的核心創新之一,圖4詳細描述了領域知識嵌入提示工程的步驟,包括角色扮演、CoT(Chain-of-Thought)示例和領域知識整合。它通過結合多個專家的知識和推理過程來增強大型語言模型(LLMs)的科學推理能力。這一策略的實施涉及以下幾個關鍵步驟:
首先,研究團隊匯集了不同領域的專家,這些專家對其專業領域內的知識和常見推理模式有著深刻的理解。這些專家被邀請參與到角色扮演中,他們需要從自己專業的角度出發,提供對特定科學問題的解答。
接著,專家們提供了一系列的CoT(Chain-of-Thought)示例。CoT示例是一種展示問題解決過程的方法,它詳細闡述了從識別問題到找到答案的每一個步驟。與傳統的零樣本CoT方法相比,領域知識嵌入的提示工程策略不僅要求模型進行推理,還要求它們在這個過程中利用專家提供的精確背景知識和準確的人類推理示例。
例如,如果LLMs面臨的任務是預測一個有機小分子的溶解度,領域專家可能會提供一個詳細的CoT示例,展示如何根據分子的極性、分子間作用力以及分子大小等因素來推理溶解度。這個示例將包括對這些因素如何影響溶解度的詳細解釋,以及如何將這些因素綜合起來得出最終的預測。
在這一過程中,專家的知識和推理示例被嵌入到提示中,形成了一種多專家混合的提示策略。這種策略不僅提供了一個領域的深度知識,還通過多個專家的視角來豐富問題的解決路徑。這使得LLMs能夠在一個更加豐富和多元的知識背景下進行推理,從而提高了它們生成準確和相關回答的能力。
這種策略還有助于減少LLMs在科學任務中的“幻覺”現象,即模型在缺乏足夠信息的情況下生成看似合理但實際上錯誤的答案。通過提供精確的背景知識和準確的推理示例,領域知識嵌入的提示工程策略引導模型更加貼近人類的科學推理過程。
結果
研究者們對五種不同的提示工程策略進行了評估,包括零樣本(Zero-shot)、少樣本(Few-shot)、專家(Expert)、零樣本鏈式思考(Zero-shot CoT)以及領域知識嵌入的提示工程方法。這些策略在三個數據集上的表現——有機小分子、酶和晶體材料——被全面比較。結果顯示,領域知識嵌入的提示工程方法在多數任務和評價指標上均優于傳統方法。
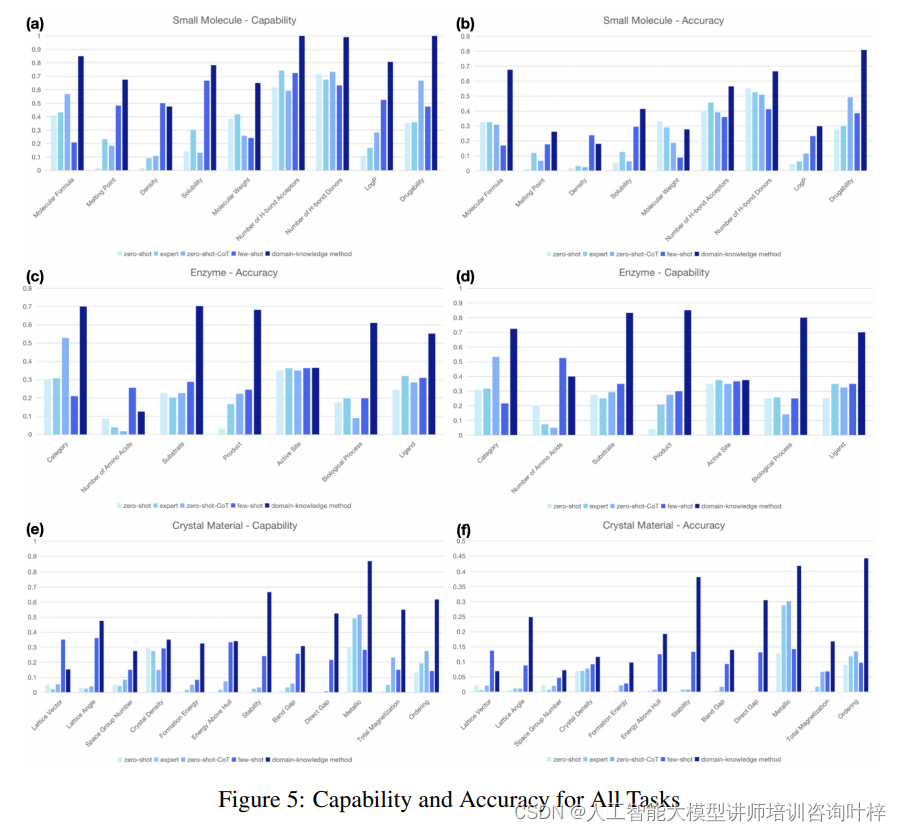
圖5 展示了不同提示工程策略在所有任務上的“能力(Capability)”和“準確性(Accuracy)”的總體表現。領域知識嵌入的提示工程方法在這項評估中顯示出其獨特的優勢。由于這種方法結合了專業知識和推理示例,它能在多個任務上都展現出較高的能力和準確性,特別是在那些需要復雜推理和專業知識的領域。這表明,與傳統的提示工程方法相比,領域知識嵌入的提示可以顯著提高LLMs在科學任務上的性能。
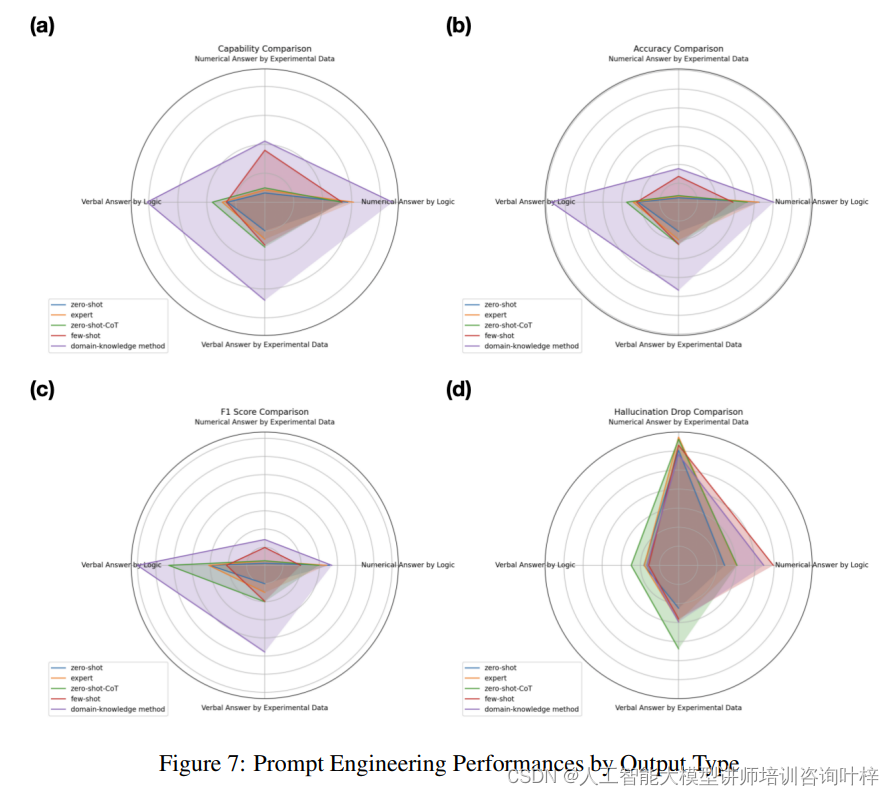
圖 7 通過輸出類型對提示工程的性能進行了細致的比較分析。這一圖表揭示了大型語言模型(LLMs)在不同任務類型上的表現,包括數值邏輯推理、實驗數據推理、邏輯文字推理和基于實驗數據的文字推理。每種任務類型都對模型的理解和推理能力提出了不同的要求。
領域知識嵌入的提示工程方法在所有任務類型上均顯示出其優越性,與傳統的提示工程策略相比,它在“能力”、“準確性”、“F1分數”和“幻覺下降”等關鍵指標上均有顯著提升。特別是在需要復雜邏輯推理的任務上,領域知識嵌入的提示能夠顯著提高LLMs的性能,這表明了將專業知識整合到提示中對于提升模型在科學領域應用的有效性至關重要。
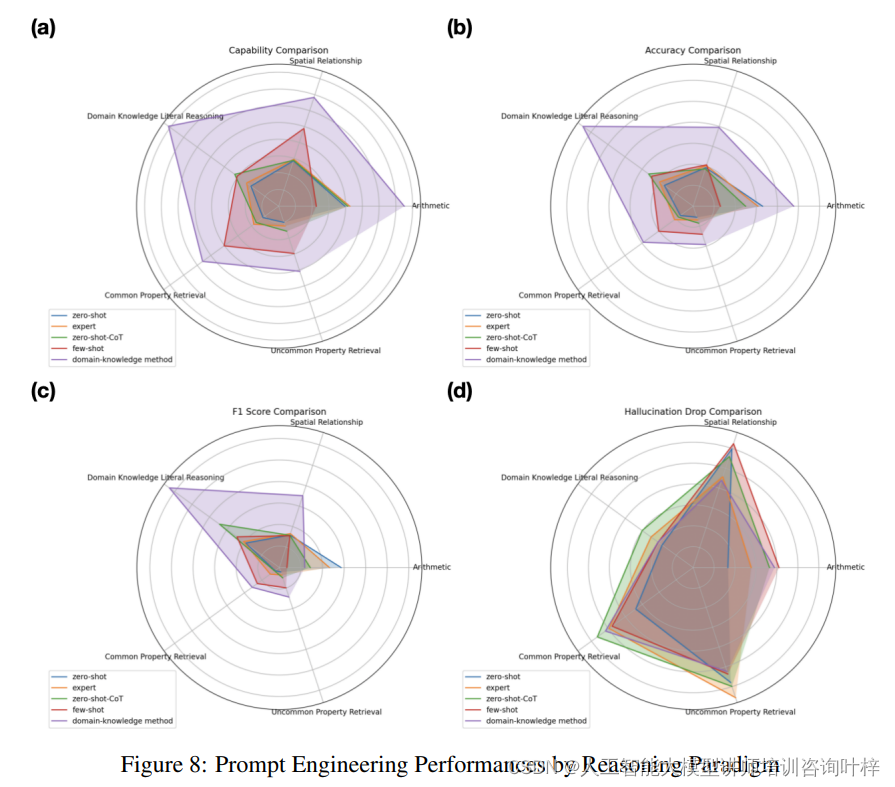
圖8顯示領域知識嵌入的提示工程方法在各種推理范式中均顯示出其有效性,特別是在需要深入領域知識的任務上。例如,在領域知識直接推理任務中,該方法能夠幫助LLMs更好地利用其預訓練階段吸收的專業知識,從而生成更準確和可信的答案。
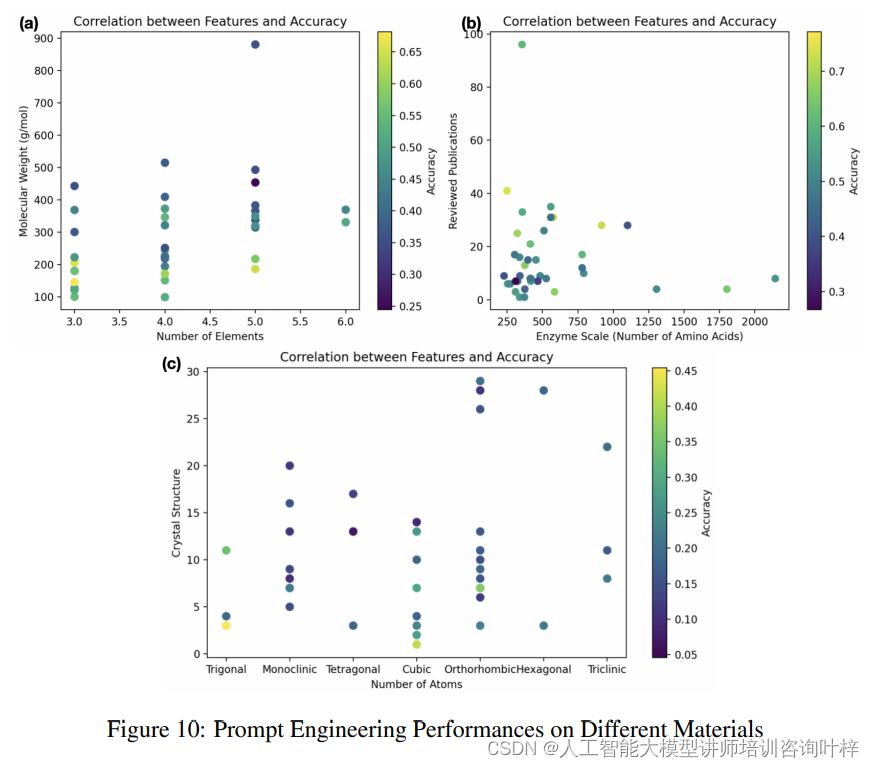
圖10 表展示了大型語言模型(LLMs)在處理有機小分子、酶和晶體材料這三種不同材料類別的任務時的性能差異。
對于有機小分子,研究者們發現,隨著分子復雜性的增加,即分子重量的增加和元素組成的多樣化,LLMs的預測準確性逐漸下降。特別是,當分子重量超過300 g/mol或包含超過五種不同元素時,性能顯著下降。
在酶的預測方面,LLMs的準確性與當前對這些酶的研究深度密切相關,而與酶的大小,即氨基酸數量,關系不大。這意味著,如果一個酶在學術界得到了廣泛的研究和理解,LLMs預測其屬性的準確性就越高。
對于晶體材料,LLMs在預測那些具有較大、更復雜組成以及低對稱性晶體結構的材料時準確性降低。然而,屬于三斜、立方或六角晶系的晶體結構更可能產生更好的預測結果,這可能是因為這些結構更規則,且在科學文獻中的數據更豐富。

圖11 在論文中展示了針對 MacMillan 第二代咪唑啉酮催化劑的提示工程案例研究。MacMillan 催化劑因其在有機催化領域的開創性貢獻而獲得了 2021 年諾貝爾化學獎,這一創新對合成化學和化學工業產生了深遠的影響。在這一案例研究中,研究者們利用領域知識嵌入的提示工程方法,旨在評估 LLMs 在整合有關分子復雜細節和預測其潛在應用方面的性能。通過精心設計的提示,LLMs 能夠展示其在分析 SMILES 序列和進行基本算術運算方面的熟練程度。LLMs 還能夠利用催化劑的機理和示例,準確預測特定底物的催化產物,從而凸顯了模型在為化學催化劑的實際應用和工業應用提供信息方面的潛力。
領域知識嵌入的提示工程證明了其在化學、材料科學和生物學等領域的有效性。未來的工作可以探索將該方法擴展到其他科學領域,如物理學、地質學和醫學,以及整合外部數據集和特定領域的工具,以進一步提升LLMs的推理能力。
論文鏈接:https://arxiv.org/pdf/2404.14467


)


|哪些函數不能實現成虛函數和虛析構函數的理解)













