未來數據庫革新:AI與云原生的融合之旅

1. 智能數據庫管理:AI的魔法
在數字化時代,數據庫技術作為信息管理的核心,正經歷著前所未有的變革。AI(人工智能)和云原生技術的融合,正在重新定義數據庫的性能、可擴展性和智能化水平。本文將深入探討這一融合之旅,分析AI如何賦能數據庫管理,云原生如何成為新時代的引擎,以及全球化數據管理面臨的新挑戰與機遇。
1.1 AI在數據庫優化中的角色:自動化索引、智能查詢、異常偵測
在現代數據庫管理中,AI技術的應用已經成為提升效率和性能的關鍵。本節將深入探討AI在數據庫優化中的三大核心角色:自動化索引、智能查詢處理和異常偵測。
1.1.1 自動化索引
索引是數據庫性能優化的基石,它通過減少數據檢索的時間來提高查詢效率。傳統上,索引的創建和管理依賴于數據庫管理員(DBA)的經驗和手動操作,這不僅耗時,而且容易出錯。AI技術的引入使得索引的自動化管理成為可能,極大地提升了效率和準確性。
自動化索引的核心在于使用機器學習算法來分析查詢模式和數據訪問頻率,從而動態調整索引策略。例如,通過強化學習算法,數據庫系統可以根據查詢的響應時間和資源消耗來自動優化索引策略。數學模型可以表示為:
max ? I ∑ t = 0 T γ t R ( Q t , I t ) \max_{I} \sum_{t=0}^{T} \gamma^t R(Q_t, I_t) Imax?t=0∑T?γtR(Qt?,It?)
其中, I t I_t It? 是在時間 t t t 的索引策略, Q t Q_t Qt? 是查詢集合, R ( Q t , I t ) R(Q_t, I_t) R(Qt?,It?) 是使用索引策略 I t I_t It? 處理查詢 Q t Q_t Qt? 的獎勵(通常是查詢響應時間), γ \gamma γ 是折扣因子。
1.1.2 智能查詢處理
智能查詢處理是AI在數據庫管理中的另一個重要應用。通過分析歷史查詢數據,AI系統可以預測特定查詢的執行時間,并據此優化查詢執行計劃。這種優化不僅包括選擇最佳的查詢執行路徑,還包括動態調整查詢參數,如JOIN操作的順序和類型。
數學上,這可以通過回歸分析來實現,其中查詢的執行時間被建模為查詢特征的函數:
ExecutionTime = f ( QueryFeatures ) + ? \text{ExecutionTime} = f(\text{QueryFeatures}) + \epsilon ExecutionTime=f(QueryFeatures)+?
其中, QueryFeatures \text{QueryFeatures} QueryFeatures 包括查詢的復雜性、數據量等特征, ? \epsilon ? 是誤差項。通過最小化誤差項,可以找到最優的查詢執行策略。
1.1.3 異常偵測
異常偵測是AI在數據庫安全管理中的關鍵應用。通過監控數據庫操作模式,AI系統可以識別異常行為,如未授權的訪問嘗試或數據篡改。這些異常通常通過統計方法或機器學習模型來檢測。
例如,使用高斯分布模型,可以檢測到偏離正常操作模式的異常行為:
P ( x ) = 1 2 π σ 2 e ? ( x ? μ ) 2 2 σ 2 P(x) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} P(x)=2πσ2?1?e?2σ2(x?μ)2?
如果某個操作的特征 x x x 的概率 P ( x ) P(x) P(x) 低于某個閾值,則該操作被視為異常。
在實際應用中,異常偵測系統通常會結合多種算法和模型,以提高檢測的準確性和效率。例如,除了高斯分布模型,還可以使用基于決策樹或神經網絡的異常檢測算法。
通過上述分析,我們可以看到AI在數據庫優化中的重要作用。自動化索引、智能查詢處理和異常偵測不僅提高了數據庫的性能和安全性,還極大地減輕了DBA的工作負擔。隨著AI技術的不斷進步,其在數據庫管理中的應用將更加廣泛和深入。
1.2 機器學習在數據洞察中的應用:預測模型、模式發現、數據凈化
在數據驅動的世界中,機器學習(ML)已成為解鎖數據洞察的關鍵技術。通過預測模型、模式發現和數據凈化,ML不僅提升了數據分析的深度和廣度,還極大地增強了決策的準確性和效率。本節將深入探討機器學習在這些領域的應用及其背后的數學原理。
1.2.1 預測模型
預測模型是機器學習在數據分析中最直接的應用之一。通過分析歷史數據,預測模型可以預測未來的趨勢和行為。例如,在金融領域,可以使用時間序列分析來預測股票價格的變動。
數學上,時間序列預測通常使用自回歸積分滑動平均(ARIMA)模型,其公式可以表示為:
X t = c + ∑ i = 1 p ? i X t ? i + ∑ j = 1 q θ j ? t ? j + ? t X_t = c + \sum_{i=1}^{p} \phi_i X_{t-i} + \sum_{j=1}^{q} \theta_j \epsilon_{t-j} + \epsilon_t Xt?=c+i=1∑p??i?Xt?i?+j=1∑q?θj??t?j?+?t?
其中, X t X_t Xt? 是時間 t t t 的觀測值, c c c 是常數, ? i \phi_i ?i? 和 θ j \theta_j θj? 是模型參數, ? t \epsilon_t ?t? 是誤差項。通過調整參數 p p p 和 q q q,可以優化模型的預測能力。
1.2.2 模式發現
模式發現是機器學習在數據分析中的另一個重要應用。通過聚類分析、關聯規則學習等技術,可以從大量數據中發現有價值的模式和關聯。例如,在市場分析中,可以使用聚類算法將客戶分為不同的群體,每個群體代表具有相似購買行為的客戶。
K-means聚類算法是最常用的聚類方法之一,其數學表達為:
min ? μ 1 , … , μ k ∑ i = 1 n min ? 1 ≤ j ≤ k ∥ x i ? μ j ∥ 2 \min_{\mu_1, \ldots, \mu_k} \sum_{i=1}^n \min_{1 \leq j \leq k} \|x_i - \mu_j\|^2 μ1?,…,μk?min?i=1∑n?1≤j≤kmin?∥xi??μj?∥2
其中, x i x_i xi? 是數據點, μ j \mu_j μj? 是聚類中心, k k k 是聚類的數量。通過迭代優化,算法將數據點分配到最近的聚類中心。
1.2.3 數據凈化
數據凈化是確保數據質量的關鍵步驟。機器學習可以幫助識別和糾正數據中的錯誤和不一致。例如,通過構建分類模型,可以自動檢測和修復數據中的異常值。
分類模型通常使用邏輯回歸或支持向量機(SVM),其數學表達為:
IsAnomaly = { 1 if? P ( x ) < threshold 0 otherwise \text{IsAnomaly} = \begin{cases} 1 & \text{if } P(x) < \text{threshold} \\ 0 & \text{otherwise} \end{cases} IsAnomaly={10?if?P(x)<thresholdotherwise?
其中, P ( x ) P(x) P(x) 是數據點 x x x 的概率, threshold \text{threshold} threshold 是異常檢測的閾值。通過調整閾值,可以控制異常檢測的敏感度。
通過上述分析,我們可以看到機器學習在數據洞察中的強大作用。預測模型、模式發現和數據凈化不僅提高了數據分析的效率和準確性,還為決策提供了堅實的數據支持。隨著技術的不斷進步,機器學習在數據管理中的應用將更加廣泛和深入。
1.3 實時數據流的智能處理:技術與策略
在數字化時代,數據以流的形式不斷產生,實時處理這些數據流成為提升業務響應速度和決策質量的關鍵。機器學習和人工智能技術在實時數據流處理中扮演著至關重要的角色,它們不僅能夠快速分析數據,還能實時識別模式和異常,從而支持即時決策。本節將探討實時數據流智能處理的技術和策略。
1.3.1 實時數據流處理技術
實時數據流處理技術主要包括流處理引擎和實時分析算法。流處理引擎如Apache Kafka和Apache Flink能夠高效地收集和處理大量實時數據。實時分析算法則利用機器學習模型,如決策樹、隨機森林和神經網絡,對數據流進行實時分析。
數學上,實時數據流處理可以看作是一個連續的數據處理過程,其中每個數據點都被即時處理。例如,使用滑動窗口技術,可以對最近的數據點進行分析:
WindowedSum = ∑ i = t ? w + 1 t x i \text{WindowedSum} = \sum_{i=t-w+1}^t x_i WindowedSum=i=t?w+1∑t?xi?
其中, w w w 是窗口大小, x i x_i xi? 是時間 i i i 的數據點。通過調整窗口大小,可以控制分析的粒度和實時性。
1.3.2 實時異常檢測策略
實時異常檢測是實時數據流處理中的一個重要應用。通過監控數據流,系統可以即時識別異常模式,如欺詐行為或系統故障。異常檢測通常基于統計方法或機器學習模型,如高斯分布模型或基于密度的空間聚類(DBSCAN)。
高斯分布模型用于檢測偏離正常模式的數據點:
P ( x ) = 1 2 π σ 2 e ? ( x ? μ ) 2 2 σ 2 P(x) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} P(x)=2πσ2?1?e?2σ2(x?μ)2?
如果數據點 x x x 的概率 P ( x ) P(x) P(x) 低于某個閾值,則該點被視為異常。
1.3.3 實時模式識別策略
實時模式識別是另一種重要的實時數據流處理策略。通過分析數據流,系統可以識別出有價值的模式,如用戶行為模式或市場趨勢。模式識別通常使用聚類算法或序列分析技術。
序列分析技術,如隱馬爾可夫模型(HMM),可以用于識別時間序列數據中的模式:
P ( X ) = ∑ Y P ( X ∣ Y ) P ( Y ) P(X) = \sum_Y P(X|Y) P(Y) P(X)=Y∑?P(X∣Y)P(Y)
其中, X X X 是觀測序列, Y Y Y 是隱藏狀態序列。通過訓練模型參數,可以優化模式識別的準確性。
1.3.4 實時決策支持系統
實時決策支持系統結合了實時數據流處理和機器學習技術,為決策者提供即時數據分析結果。這些系統通常包括數據收集、實時分析和決策反饋三個主要組件。
例如,在金融交易中,實時決策支持系統可以分析市場數據流,即時識別交易機會,并自動執行交易。數學模型可以表示為:
Trade = { 1 if? P ( Profit ) > threshold 0 otherwise \text{Trade} = \begin{cases} 1 & \text{if } P(\text{Profit}) > \text{threshold} \\ 0 & \text{otherwise} \end{cases} Trade={10?if?P(Profit)>thresholdotherwise?
其中, P ( Profit ) P(\text{Profit}) P(Profit) 是預測的盈利概率, threshold \text{threshold} threshold 是決策閾值。
通過上述技術和策略,實時數據流的智能處理不僅提高了數據分析的效率,還增強了決策的實時性和準確性。隨著技術的不斷發展,實時數據流處理將繼續在各個行業中發揮重要作用。
1.4 成功案例:AI如何助力企業通過數據庫優化實現成本削減與效率提升
在數字化轉型的浪潮中,人工智能(AI)已成為企業提升數據庫管理效率和降低成本的強大工具。通過自動化索引、智能查詢處理和實時數據分析,AI不僅優化了數據庫性能,還顯著提高了業務決策的速度和質量。本節將通過幾個具體案例,展示AI如何助力企業在數據庫優化方面取得顯著成效。
1.4.1 自動化索引優化的案例
一家大型電商公司面臨數據庫查詢響應時間過長的問題,嚴重影響了用戶體驗和銷售業績。通過引入AI驅動的自動化索引優化工具,該公司能夠實時分析查詢模式和數據訪問頻率,動態調整索引策略。
數學模型上,自動化索引優化可以表示為:
min ? I ∑ Q ResponseTime ( Q , I ) \min_{I} \sum_{Q} \text{ResponseTime}(Q, I) Imin?Q∑?ResponseTime(Q,I)
其中, I I I 是索引策略, Q Q Q 是查詢集合, ResponseTime ( Q , I ) \text{ResponseTime}(Q, I) ResponseTime(Q,I) 是使用索引策略 I I I 處理查詢 Q Q Q 的響應時間。通過機器學習算法,系統能夠自動找到最優的索引配置,顯著減少了查詢響應時間,提升了用戶體驗。
1.4.2 智能查詢處理的案例
一家金融服務公司需要處理大量復雜的金融數據查詢。通過部署AI驅動的智能查詢處理系統,該公司能夠預測查詢執行時間,并據此優化查詢執行計劃。
智能查詢處理的數學模型可以表示為:
ExecutionTime = f ( QueryComplexity , DataSize ) + ? \text{ExecutionTime} = f(\text{QueryComplexity}, \text{DataSize}) + \epsilon ExecutionTime=f(QueryComplexity,DataSize)+?
其中, QueryComplexity \text{QueryComplexity} QueryComplexity 和 DataSize \text{DataSize} DataSize 是查詢的復雜性和數據量, ? \epsilon ? 是誤差項。通過回歸分析,系統能夠預測查詢的執行時間,并選擇最佳的查詢執行路徑,從而大幅提高了查詢處理效率。
1.4.3 實時數據流分析的案例
一家社交媒體公司需要實時分析用戶行為數據,以優化內容推薦和廣告投放。通過實施AI驅動的實時數據流分析系統,該公司能夠即時識別用戶行為模式,并據此調整推薦算法。
實時數據流分析的數學模型可以表示為:
UserEngagement = g ( UserBehaviorData ) + ? \text{UserEngagement} = g(\text{UserBehaviorData}) + \epsilon UserEngagement=g(UserBehaviorData)+?
其中, UserBehaviorData \text{UserBehaviorData} UserBehaviorData 是用戶行為數據, ? \epsilon ? 是誤差項。通過實時分析用戶行為數據,系統能夠即時調整內容推薦策略,顯著提高了用戶參與度和廣告收入。
通過上述案例,我們可以看到AI在數據庫優化中的巨大潛力。自動化索引、智能查詢處理和實時數據流分析不僅提高了數據庫的性能和效率,還為企業帶來了顯著的成本節約和業務增長。隨著AI技術的不斷進步,其在數據庫管理中的應用將更加廣泛和深入。
1.5 實戰代碼與案例剖析:AI工具優化數據庫的實際操作
在數據庫管理領域,AI工具的應用已成為提升效率和性能的關鍵。本節將深入探討如何通過實際代碼和案例分析,利用AI工具優化數據庫操作。我們將從自動化索引、智能查詢優化、異常檢測和數據凈化四個方面進行詳細闡述。
1.5.1 自動化索引優化
自動化索引優化是提高數據庫查詢性能的重要手段。通過AI算法,可以動態分析查詢模式并自動調整索引策略。以下是一個簡化的Python代碼示例,使用機器學習模型來預測索引需求:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier# 假設df是包含查詢歷史的數據框
df = pd.read_csv('query_history.csv')# 特征工程:提取查詢特征
df['feature1'] = df['query'].apply(lambda x: len(x))
df['feature2'] = df['result_size'] / df['execution_time']# 使用隨機森林分類器預測是否需要索引
model = RandomForestClassifier()
model.fit(df[['feature1', 'feature2']], df['needs_index'])# 預測新查詢的索引需求
new_query = {'feature1': 100, 'feature2': 5}
prediction = model.predict([list(new_query.values())])if prediction == 1:print("需要創建索引")
else:print("不需要創建索引")
在這個例子中,我們使用查詢的長度和結果大小與執行時間的比率作為特征,通過隨機森林分類器預測是否需要為新查詢創建索引。
1.5.2 智能查詢優化
智能查詢優化涉及使用AI算法來分析查詢執行計劃,并提出優化建議。以下是一個使用成本模型來優化查詢的示例:
-- 假設我們有一個查詢優化器,它可以根據查詢成本模型提出優化建議
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 1000;-- 優化器可能會建議創建一個索引來加速查詢
CREATE INDEX idx_customer_id ON orders(customer_id);-- 再次執行查詢以驗證性能提升
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 1000;
在這個SQL示例中,我們首先分析查詢的執行計劃,然后根據優化器的建議創建索引,最后再次分析以驗證性能提升。
1.5.3 異常檢測
異常檢測在數據庫管理中用于識別和處理異常行為,如數據輸入錯誤或惡意攻擊。以下是一個使用統計方法進行異常檢測的Python代碼示例:
import numpy as np# 假設data是包含數據點的數組
data = np.array([1, 2, 3, 4, 5, 100])# 計算平均值和標準差
mean = np.mean(data)
std_dev = np.std(data)# 定義異常檢測閾值
threshold = 2 * std_dev# 檢測異常點
outliers = data[np.abs(data - mean) > threshold]print("異常點:", outliers)
在這個例子中,我們計算數據的平均值和標準差,然后使用這些統計量來檢測偏離正常范圍的異常點。
1.5.4 數據凈化
數據凈化是確保數據質量的關鍵步驟。AI工具可以幫助自動識別和修復數據中的錯誤。以下是一個使用規則引擎進行數據凈化的示例:
# 假設我們有一個包含錯誤數據的數據框df
df = pd.DataFrame({'age': [25, 30, 150, 20],'salary': [50000, 60000, 70000, 80000]
})# 定義規則:如果年齡大于100,則將其設置為NaN
df['age'] = df['age'].apply(lambda x: np.nan if x > 100 else x)print(df)
在這個例子中,我們定義了一個簡單的規則來識別年齡字段中的異常值,并將其設置為NaN,以便進一步處理。
通過上述實戰代碼和案例剖析,我們可以看到AI工具在數據庫優化中的實際應用和效果。這些工具不僅提高了數據庫的性能和效率,還幫助企業節省了大量成本和時間。隨著AI技術的不斷發展,其在數據庫管理中的應用將更加廣泛和深入。
1.6 效果可視化:AI優化成果的直觀展示
在數據庫管理中,AI的應用不僅提升了效率和性能,還帶來了顯著的成本節約。然而,這些成果往往需要通過直觀的方式展示,以便決策者和團隊成員能夠快速理解和評估。本節將探討如何通過可視化技術,展示AI在數據庫優化中的成果。
1.6.1 性能提升的可視化
性能提升是AI優化數據庫最直接的效果之一。通過圖表和儀表盤,可以直觀地展示查詢響應時間、吞吐量和資源利用率的變化。例如,使用折線圖來展示優化前后查詢響應時間的變化:
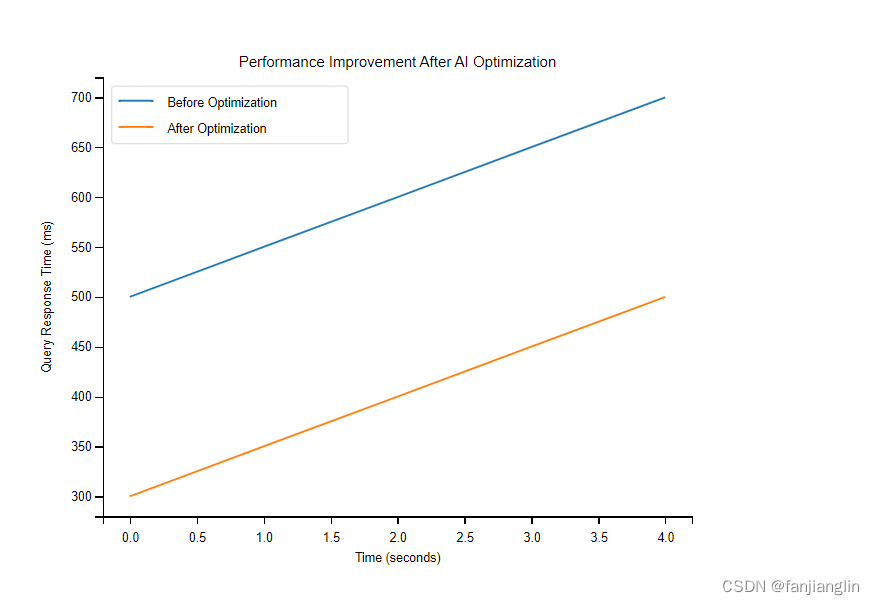
在這個圖中,橫軸代表時間,縱軸代表查詢響應時間。通過對比優化前后的數據點,可以清晰地看到AI優化帶來的性能提升。
1.6.2 成本節約的可視化
成本節約是企業采用AI優化數據庫的另一個重要考量。通過柱狀圖或餅圖,可以展示優化前后硬件資源、能源消耗和維護成本的變化。例如,使用柱狀圖來展示優化前后的成本對比:
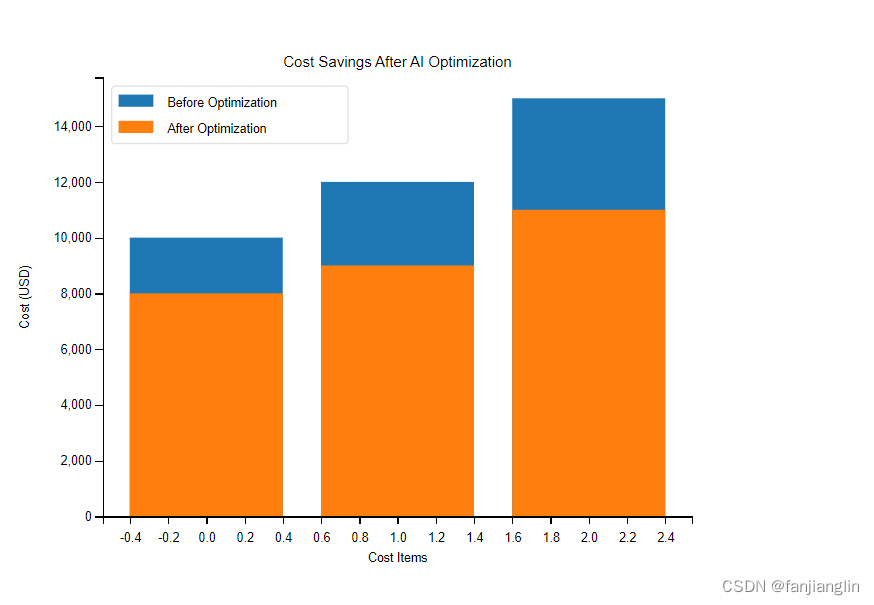
在這個圖中,橫軸代表不同的成本項目,縱軸代表成本金額。通過對比優化前后的柱狀高度,可以直觀地看到成本節約的效果。
1.6.3 異常檢測和數據凈化的可視化
異常檢測和數據凈化是AI在數據庫管理中的重要應用。通過熱力圖或散點圖,可以展示異常數據點和凈化效果。例如,使用熱力圖來展示異常檢測的結果:
在這個圖中,顏色深淺代表異常程度,通過顏色的變化可以直觀地看到異常數據點的分布。
1.6.4 實時數據流處理的可視化
實時數據流處理是AI優化數據庫的另一個關鍵領域。通過實時更新的儀表盤,可以展示數據流的處理速度、實時分析結果和決策支持信息。例如,使用實時儀表盤來展示數據流處理的狀態:
在這個儀表盤上,可以實時看到數據流的處理進度、分析結果和系統狀態,幫助團隊快速響應和決策。
通過上述可視化技術,AI優化數據庫的成果得以直觀展示,不僅增強了決策的信心,還促進了團隊之間的溝通和協作。隨著技術的進步,可視化工具將更加強大和靈活,為數據庫管理帶來更多的便利和效率。

2. 云原生數據庫:新時代的引擎
2.1 云原生數據庫的核心優勢:彈性、可用性、自動化
云原生數據庫作為現代數據管理的新引擎,其核心優勢在于提供了前所未有的彈性、可用性和自動化能力。這些特性不僅極大地提升了數據庫的性能和可靠性,還為企業帶來了靈活性和成本效益。本節將深入探討這些核心優勢,并通過具體的例子和數學模型來解釋其背后的原理。
2.1.1 彈性(Elasticity)
彈性是云原生數據庫最顯著的特性之一,它允許數據庫根據實際需求動態調整資源。這種能力在處理突發流量或季節性數據高峰時尤為重要。例如,一個電商平臺在“黑色星期五”期間可能會遇到比平時多出數倍的訪問量,云原生數據庫可以自動擴展以應對這種流量激增。
數學上,彈性可以通過資源分配的優化模型來描述。假設我們有一個資源分配問題,目標是最大化性能(P),同時滿足成本(C)和延遲(L)的約束:
max ? x P ( x ) \max_{x} P(x) xmax?P(x)
s.t. C ( x ) ≤ C m a x \text{s.t.} \quad C(x) \leq C_{max} s.t.C(x)≤Cmax?
L ( x ) ≤ L m a x L(x) \leq L_{max} L(x)≤Lmax?
其中, x x x 是資源分配的決策變量, P ( x ) P(x) P(x) 是性能函數, C ( x ) C(x) C(x) 和 L ( x ) L(x) L(x) 分別是成本和延遲函數。通過優化這個模型,可以實現資源的最優分配,從而達到彈性的目的。
2.1.2 可用性(Availability)
高可用性是云原生數據庫的另一個關鍵優勢。通過分布式架構和數據復制技術,云原生數據庫能夠在硬件故障或網絡問題發生時保持服務的連續性。例如,Google Cloud的Cloud Spanner提供了99.999%的可用性保證,這意味著每年的停機時間不超過5分鐘。
可用性通常可以通過系統可靠性模型來量化。例如,假設一個系統由n個組件組成,每個組件的可靠性為 R i R_i Ri?,則系統的整體可靠性 R s y s R_{sys} Rsys?可以通過乘積規則計算:
R s y s = ∏ i = 1 n R i R_{sys} = \prod_{i=1}^{n} R_i Rsys?=i=1∏n?Ri?
通過提高單個組件的可靠性或增加冗余組件,可以提高系統的整體可用性。
2.1.3 自動化(Automation)
自動化是云原生數據庫的第三個核心優勢。通過自動化工具和機器學習算法,云原生數據庫可以自動執行諸如備份、恢復、擴展和優化等任務。這種自動化不僅減少了人工干預的需要,還提高了操作的準確性和效率。
自動化可以通過決策樹或強化學習等算法來實現。例如,一個自動化擴展系統可能會使用強化學習來學習在不同負載條件下的最佳擴展策略。數學上,強化學習可以表示為一個馬爾可夫決策過程(MDP):
max ? π E π [ ∑ t = 0 ∞ γ t r t ] \max_{\pi} \mathbb{E}_{\pi} \left[ \sum_{t=0}^{\infty} \gamma^t r_t \right] πmax?Eπ?[t=0∑∞?γtrt?]
其中, π \pi π 是策略, r t r_t rt? 是時間 t t t的獎勵, γ \gamma γ 是折扣因子。通過優化這個目標函數,可以學習到最優的自動化策略。
2.1.4 小結
云原生數據庫的彈性、可用性和自動化特性為企業提供了強大的數據管理能力。通過深入理解這些特性的數學基礎和實現機制,企業可以更有效地利用云原生數據庫來支持其業務需求。隨著技術的不斷進步,云原生數據庫將繼續演化,為企業帶來更多的創新和價值。
2.2 云服務巨頭的解決方案:AWS、Azure、Google Cloud
在云原生數據庫的領域中,三大云服務提供商——亞馬遜網絡服務(AWS)、微軟Azure和谷歌云平臺(Google Cloud)——提供了各自獨特的解決方案,這些方案不僅體現了云原生數據庫的核心優勢,還展示了各自的技術特色和市場定位。本節將深入探討這些解決方案的特點,并通過具體的案例和數學模型來解釋其背后的原理。
2.2.1 亞馬遜網絡服務(AWS)
AWS提供了一系列云原生數據庫服務,其中最著名的是Amazon DynamoDB和Amazon Aurora。DynamoDB是一個完全托管的NoSQL數據庫服務,適用于需要高可擴展性和低延遲的應用。Aurora則是一個兼容MySQL和PostgreSQL的關系型數據庫,它結合了高端商業數據庫的速度和可靠性以及開源數據庫的簡單性和成本效益。
數學上,DynamoDB的性能可以通過其內置的自動擴展功能來優化。例如,假設有一個讀寫請求的速率函數:
R ( t ) = R 0 + k t R(t) = R_0 + kt R(t)=R0?+kt
其中, R 0 R_0 R0? 是初始請求速率, k k k 是增長率, t t t 是時間。DynamoDB可以根據這個函數自動調整其讀寫容量單位,以保持最佳性能。
2.2.2 微軟Azure
Azure的數據庫服務包括Azure SQL Database和Azure Cosmos DB。Azure SQL Database是一個完全托管的關系型數據庫服務,它基于Microsoft SQL Server引擎。Cosmos DB則是一個全球分布式的多模型數據庫服務,支持多種數據模型和API,包括SQL、MongoDB、Cassandra等。
Azure Cosmos DB的全球分布能力可以通過其一致性模型來優化。例如,Cosmos DB提供了五種一致性級別:強一致性、有限過期、會話、一致前綴和最終一致性。選擇合適的一致性級別可以通過以下數學模型來決定:
min ? c Cost ( c ) \min_{c} \text{Cost}(c) cmin?Cost(c)
s.t. Latency ( c ) ≤ L m a x \text{s.t.} \quad \text{Latency}(c) \leq L_{max} s.t.Latency(c)≤Lmax?
Availability ( c ) ≥ A m i n \text{Availability}(c) \geq A_{min} Availability(c)≥Amin?
其中, c c c 是一致性級別, Cost ( c ) \text{Cost}(c) Cost(c) 是成本, Latency ( c ) \text{Latency}(c) Latency(c) 是延遲, Availability ( c ) \text{Availability}(c) Availability(c) 是可用性。通過優化這個模型,可以選擇最適合應用需求的一致性級別。
2.2.3 谷歌云平臺(Google Cloud)
Google Cloud的數據庫服務包括Google Cloud SQL和Google Cloud Spanner。Cloud SQL是一個完全托管的關系型數據庫服務,支持MySQL、PostgreSQL和SQL Server。Cloud Spanner是一個全球分布式的關系型數據庫服務,它提供了水平擴展和高可用性,適用于需要強一致性和復雜事務的應用。
Cloud Spanner的擴展能力可以通過其分布式事務處理機制來優化。例如,假設有一個事務處理模型:
T ( x ) = T 0 + α x T(x) = T_0 + \alpha x T(x)=T0?+αx
其中, T 0 T_0 T0? 是基礎事務處理時間, x x x 是數據量, α \alpha α 是單位數據量的事務處理時間。Cloud Spanner可以根據這個模型自動調整其資源分配,以保持最佳的事務處理性能。
2.2.4 小結
AWS、Azure和Google Cloud提供的云原生數據庫解決方案各有千秋,它們不僅體現了云原生數據庫的核心優勢,還展示了各自的技術特色和市場定位。通過深入理解這些解決方案的數學模型和實現機制,企業可以更有效地選擇和使用云原生數據庫服務,以支持其業務需求。隨著技術的不斷進步,這些云服務提供商將繼續推出更多創新的數據庫解決方案,為企業帶來更多的價值。
2.3 遷移策略:從傳統到云原生的無縫過渡
隨著云原生數據庫技術的不斷成熟,越來越多的企業開始考慮將其傳統數據庫遷移到云原生平臺上。這一過程不僅涉及到技術層面的轉換,還需要考慮業務連續性、數據安全性和成本效益等多方面因素。本節將詳細探討從傳統數據庫到云原生數據庫的遷移策略,包括遷移前的評估、遷移過程中的技術選擇和遷移后的優化。
2.3.1 遷移前的評估
在開始遷移之前,企業需要對現有的數據庫環境進行全面的評估。這包括但不限于數據庫的規模、性能、數據模型、依賴的應用程序以及業務需求。評估的目的是為了確定遷移的可行性,并為遷移過程制定詳細的計劃。
數學上,評估可以通過成本效益分析(CBA)來量化。例如,假設遷移的總成本為 C t o t a l C_{total} Ctotal?,遷移后的預期收益為 B e x p e c t e d B_{expected} Bexpected?,則遷移的凈現值(NPV)可以表示為:
N P V = B e x p e c t e d ? C t o t a l NPV = B_{expected} - C_{total} NPV=Bexpected??Ctotal?
如果 N P V > 0 NPV > 0 NPV>0,則遷移在經濟上是可行的。
2.3.2 遷移過程中的技術選擇
遷移過程中的技術選擇是關鍵步驟,它涉及到選擇合適的云服務提供商、數據庫服務類型以及遷移工具。例如,如果企業選擇AWS作為云服務提供商,它可以選擇使用AWS DMS(Database Migration Service)來實現數據的遷移。
數學上,技術選擇可以通過決策樹分析來優化。例如,假設有多個技術選項 T i T_i Ti?,每個選項的成本為 C i C_i Ci?,收益為 B i B_i Bi?,則可以通過以下公式來選擇最佳技術:
max ? i B i C i \max_{i} \frac{B_i}{C_i} imax?Ci?Bi??
2.3.3 遷移后的優化
遷移完成后,企業需要對新的云原生數據庫進行優化,以確保其性能和可靠性。這可能包括調整數據庫配置、優化查詢性能、實施監控和自動化等。
數學上,優化可以通過性能建模來實現。例如,假設數據庫的性能指標為 P P P,影響性能的因素為 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1?,x2?,…,xn?,則可以通過建立性能模型來優化:
P = f ( x 1 , x 2 , … , x n ) P = f(x_1, x_2, \ldots, x_n) P=f(x1?,x2?,…,xn?)
通過調整 x i x_i xi?的值,可以找到最佳的性能配置。
2.3.4 案例分析
為了更具體地說明遷移策略,我們可以考慮一個實際案例。假設一家金融機構決定將其傳統的Oracle數據庫遷移到Google Cloud的Cloud Spanner。在遷移前,該機構進行了詳細的評估,確定了遷移的成本和收益。在遷移過程中,它使用了Google Cloud的遷移工具,并確保了數據的完整性和一致性。遷移后,該機構對Cloud Spanner進行了優化,提高了查詢性能和系統的可擴展性。
2.3.5 小結
從傳統數據庫到云原生數據庫的遷移是一個復雜的過程,需要企業在技術、業務和成本等多方面進行綜合考慮。通過制定詳細的遷移策略,選擇合適的技術和工具,并進行遷移后的優化,企業可以實現從傳統到云原生的無縫過渡,從而充分利用云原生數據庫的優勢,提升業務的靈活性和競爭力。隨著云原生技術的不斷發展,遷移策略也將不斷演進,為企業帶來更多的機遇和挑戰。
2.4 實戰代碼與案例剖析:傳統數據庫云原生化的步驟
將傳統數據庫遷移到云原生環境是一個復雜但可行的過程,涉及多個步驟和技術決策。本節將通過實戰代碼和案例分析,詳細介紹如何實現這一遷移過程,確保數據的無縫過渡和系統的穩定性。
2.4.1 評估與規劃
在開始遷移之前,首先需要對現有數據庫進行全面的評估。這包括數據庫的類型、大小、性能指標、依賴的應用程序以及業務需求。評估的目的是為了確定遷移的可行性,并為遷移過程制定詳細的計劃。
數學上,評估可以通過成本效益分析(CBA)來量化。例如,假設遷移的總成本為 C t o t a l C_{total} Ctotal?,遷移后的預期收益為 B e x p e c t e d B_{expected} Bexpected?,則遷移的凈現值(NPV)可以表示為:
N P V = B e x p e c t e d ? C t o t a l NPV = B_{expected} - C_{total} NPV=Bexpected??Ctotal?
如果 N P V > 0 NPV > 0 NPV>0,則遷移在經濟上是可行的。
2.4.2 選擇云服務提供商和數據庫服務
根據評估結果,選擇合適的云服務提供商和數據庫服務。例如,如果企業選擇AWS作為云服務提供商,它可以選擇使用Amazon RDS或Amazon Aurora作為目標數據庫服務。
2.4.3 數據遷移
數據遷移是遷移過程中的核心步驟。這通常涉及到使用特定的遷移工具,如AWS DMS(Database Migration Service),來復制數據和結構。以下是一個使用AWS DMS遷移數據的示例代碼片段:
import boto3# 創建DMS客戶端
dms = boto3.client('dms', region_name='us-west-2')# 創建遷移任務
response = dms.create_replication_task(ReplicationTaskIdentifier='my-migration-task',SourceEndpointArn='arn:aws:dms:us-west-2:123456789012:endpoint:source-endpoint',TargetEndpointArn='arn:aws:dms:us-west-2:123456789012:endpoint:target-endpoint',ReplicationTaskSettings='{"遷移設置"}'
)
2.4.4 驗證與測試
遷移完成后,需要對新的云原生數據庫進行驗證和測試,確保數據的完整性和系統的穩定性。這可能包括執行一系列的查詢測試、性能測試和故障恢復測試。
數學上,驗證可以通過統計測試來實現。例如,假設有 n n n個測試用例,通過的用例數為 m m m,則通過率可以表示為:
通過率 = m n \text{通過率} = \frac{m}{n} 通過率=nm?
2.4.5 優化與監控
最后,對新的云原生數據庫進行優化,并實施監控以確保長期穩定運行。這可能包括調整數據庫配置、優化查詢性能、實施自動化監控和報警系統。
數學上,優化可以通過性能建模來實現。例如,假設數據庫的性能指標為 P P P,影響性能的因素為 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1?,x2?,…,xn?,則可以通過建立性能模型來優化:
P = f ( x 1 , x 2 , … , x n ) P = f(x_1, x_2, \ldots, x_n) P=f(x1?,x2?,…,xn?)
通過調整 x i x_i xi?的值,可以找到最佳的性能配置。
2.4.6 案例分析
為了更具體地說明遷移步驟,我們可以考慮一個實際案例。假設一家電子商務公司決定將其傳統的MySQL數據庫遷移到Google Cloud的Cloud SQL。在遷移前,該公司進行了詳細的評估,確定了遷移的成本和收益。在遷移過程中,它使用了Google Cloud的遷移工具,并確保了數據的完整性和一致性。遷移后,該公司對Cloud SQL進行了優化,提高了查詢性能和系統的可擴展性。
2.4.7 小結
從傳統數據庫到云原生數據庫的遷移是一個復雜的過程,需要企業在技術、業務和成本等多方面進行綜合考慮。通過制定詳細的遷移策略,選擇合適的技術和工具,并進行遷移后的優化,企業可以實現從傳統到云原生的無縫過渡,從而充分利用云原生數據庫的優勢,提升業務的靈活性和競爭力。隨著云原生技術的不斷發展,遷移策略也將不斷演進,為企業帶來更多的機遇和挑戰。
2.5 性能對比:云原生與傳統數據庫的性能較量
在數據庫技術的演進中,云原生數據庫的出現為傳統的本地數據庫帶來了新的挑戰和機遇。云原生數據庫以其高度的可擴展性、彈性和自動化管理等特點,逐漸成為企業數據管理的新選擇。本節將深入探討云原生數據庫與傳統數據庫在性能上的對比,通過具體的數學模型和案例分析,揭示兩者之間的差異和優劣。
2.5.1 性能指標的定義
在進行性能對比之前,首先需要明確性能指標。常見的性能指標包括響應時間、吞吐量、并發用戶數、數據一致性和可用性等。這些指標可以通過數學模型來量化,例如響應時間可以用以下公式表示:
T r e s p o n s e = T q u e r y + T p r o c e s s i n g + T n e t w o r k T_{response} = T_{query} + T_{processing} + T_{network} Tresponse?=Tquery?+Tprocessing?+Tnetwork?
其中, T r e s p o n s e T_{response} Tresponse? 是總響應時間, T q u e r y T_{query} Tquery? 是查詢時間, T p r o c e s s i n g T_{processing} Tprocessing? 是處理時間, T n e t w o r k T_{network} Tnetwork? 是網絡傳輸時間。
2.5.2 云原生數據庫的性能優勢
云原生數據庫通常具有以下性能優勢:
- 彈性擴展:云原生數據庫可以根據負載自動擴展資源,這可以通過以下數學模型來描述:
R s c a l e = α × L R_{scale} = \alpha \times L Rscale?=α×L
其中, R s c a l e R_{scale} Rscale? 是資源擴展量, α \alpha α 是擴展系數, L L L 是負載量。
- 高可用性:云原生數據庫通過分布式架構提供高可用性,可用性可以通過以下公式計算:
A v a i l a b i l i t y = M T B F M T B F + M T T R × 100 % A_{vailability} = \frac{MTBF}{MTBF + MTTR} \times 100\% Availability?=MTBF+MTTRMTBF?×100%
其中, M T B F MTBF MTBF 是平均故障間隔時間, M T T R MTTR MTTR 是平均修復時間。
- 自動化管理:云原生數據庫的自動化管理可以減少人為錯誤,提高系統穩定性。
2.5.3 傳統數據庫的性能特點
傳統數據庫雖然在某些方面可能不如云原生數據庫靈活,但它們在以下方面可能具有優勢:
-
成熟穩定:傳統數據庫經過長時間的發展,通常具有較高的穩定性和成熟度。
-
定制化:傳統數據庫可以根據特定需求進行深度定制,這可以通過以下公式來描述:
P c u s t o m i z a t i o n = β × D P_{customization} = \beta \times D Pcustomization?=β×D
其中, P c u s t o m i z a t i o n P_{customization} Pcustomization? 是定制化程度, β \beta β 是定制化系數, D D D 是需求復雜度。
- 性能優化:傳統數據庫可以通過硬件升級和優化配置來提升性能。
2.5.4 性能對比案例分析
為了更具體地展示云原生與傳統數據庫的性能對比,我們可以考慮一個實際案例。假設一家金融機構需要處理大量的交易數據,它可以選擇使用傳統的Oracle數據庫或者云原生的Google Cloud Spanner。通過對比兩者的響應時間、吞吐量和可用性,可以得出以下結論:
- 在響應時間方面,Spanner由于其分布式架構和自動擴展能力,可能在高負載下表現更好。
- 在吞吐量方面,Oracle數據庫可能在單點性能上略有優勢,但在大規模并發處理上可能不如Spanner。
- 在可用性方面,Spanner的高可用性設計使其在故障恢復和災難恢復方面具有明顯優勢。
2.5.5 小結
云原生數據庫與傳統數據庫在性能上各有千秋,企業在選擇時需要根據自身的業務需求和成本考慮進行權衡。隨著云原生技術的不斷成熟,其在性能上的優勢將越來越明顯,但傳統數據庫在某些特定場景下仍然具有不可替代的價值。通過深入分析和對比,企業可以更好地理解兩者的性能差異,從而做出更合適的選擇。隨著技術的不斷進步,數據庫技術將繼續演化,為企業帶來更多的可能性和挑戰。
2.6 深度閱讀:云原生數據庫的最佳實踐與案例研究推薦
隨著云原生數據庫技術的快速發展,越來越多的企業和開發者開始關注如何在實際應用中有效地利用這些技術。本節將推薦一些關于云原生數據庫的最佳實踐和案例研究,幫助讀者深入理解云原生數據庫的實際應用和優化策略。
2.6.1 云原生數據庫的最佳實踐
云原生數據庫的最佳實踐通常包括以下幾個方面:
-
資源優化:合理配置數據庫資源,以滿足業務需求同時避免資源浪費。例如,通過監控數據庫的CPU和內存使用情況,動態調整資源分配。
-
性能調優:通過優化查詢、索引和數據模型,提高數據庫的響應速度和吞吐量。性能調優可以通過以下數學模型來量化:
P o p t i m i z a t i o n = T b e f o r e ? T a f t e r T b e f o r e × 100 % P_{optimization} = \frac{T_{before} - T_{after}}{T_{before}} \times 100\% Poptimization?=Tbefore?Tbefore??Tafter??×100%
其中, P o p t i m i z a t i o n P_{optimization} Poptimization? 是性能提升的百分比, T b e f o r e T_{before} Tbefore? 和 T a f t e r T_{after} Tafter? 分別是優化前后的響應時間。
- 高可用性和災難恢復:設計高可用的數據庫架構,確保在硬件故障或自然災害時數據的安全和服務的連續性。高可用性可以通過以下公式來評估:
A v a i l a b i l i t y = M T B F M T B F + M T T R × 100 % A_{vailability} = \frac{MTBF}{MTBF + MTTR} \times 100\% Availability?=MTBF+MTTRMTBF?×100%
其中, M T B F MTBF MTBF 是平均故障間隔時間, M T T R MTTR MTTR 是平均修復時間。
- 安全性:實施嚴格的安全策略,包括數據加密、訪問控制和審計日志,以保護數據不受未授權訪問和惡意攻擊。
2.6.2 案例研究推薦
以下是一些值得深入研究的云原生數據庫案例:
-
Netflix的Cassandra云原生部署:Netflix使用Cassandra作為其云原生數據庫,實現了高度的可擴展性和靈活性。該案例詳細介紹了Netflix如何通過自動化工具和監控系統來管理和優化其Cassandra集群。
-
Spotify的云原生數據倉庫:Spotify采用Google BigQuery作為其云原生數據倉庫,有效地處理和分析了大量的用戶數據。該案例研究了Spotify如何通過BigQuery實現數據驅動的決策支持。
-
Airbnb的實時數據處理:Airbnb使用Apache Kafka和Google Cloud Pub/Sub構建了其實時數據處理系統,實現了對用戶行為的實時監控和分析。該案例展示了如何通過云原生技術實現復雜的數據流處理。
2.6.3 小結
云原生數據庫的最佳實踐和案例研究為我們提供了寶貴的經驗和知識,幫助我們更好地理解和應用這些先進的技術。通過深入閱讀和分析這些案例,我們可以學習到如何在實際業務中有效地部署和優化云原生數據庫,從而提升企業的數據處理能力和業務競爭力。隨著云原生技術的不斷發展,未來的數據庫管理將更加智能、高效和安全,為企業帶來更多的創新和價值。
3. 全球化數據管理:新挑戰與機遇
3.1 跨地域數據策略:同步、復制、分片
在全球化的商業環境中,企業面臨著跨地域數據管理的挑戰。為了確保數據的一致性、可用性和性能,企業需要采取有效的數據策略,如數據同步、復制和分片。本節將深入探討這些策略的原理、實施方法和數學模型,并通過具體案例分析,展示它們在實際應用中的效果。
3.1.1 數據同步
數據同步是指在不同地理位置的數據庫之間保持數據的一致性。這通常涉及到實時或定期的數據傳輸,以確保所有數據庫副本都包含最新的數據變更。數據同步可以通過以下數學模型來描述:
S s y n c = T u p d a t e T p r o p a g a t i o n S_{sync} = \frac{T_{update}}{T_{propagation}} Ssync?=Tpropagation?Tupdate??
其中, S s y n c S_{sync} Ssync? 是同步效率, T u p d a t e T_{update} Tupdate? 是數據更新時間, T p r o p a g a t i o n T_{propagation} Tpropagation? 是數據傳播到所有副本的時間。
3.1.2 數據復制
數據復制是指在多個地理位置創建數據庫的副本,以提高數據的可用性和讀取性能。復制策略可以分為同步復制和異步復制。同步復制確保所有副本的數據完全一致,而異步復制則允許副本之間存在一定的延遲。數據復制的數學模型可以表示為:
R r e p l i c a t i o n = N r e p l i c a s N t o t a l R_{replication} = \frac{N_{replicas}}{N_{total}} Rreplication?=Ntotal?Nreplicas??
其中, R r e p l i c a t i o n R_{replication} Rreplication? 是復制率, N r e p l i c a s N_{replicas} Nreplicas? 是副本數量, N t o t a l N_{total} Ntotal? 是總的數據庫數量。
3.1.3 數據分片
數據分片是將大型數據庫分割成多個較小的部分,每個部分稱為一個分片。分片可以基于數據的某個屬性(如用戶ID、地理位置等)進行。分片策略有助于提高數據庫的性能和可管理性。數據分片的數學模型可以表示為:
S s h a r d i n g = S d a t a S s h a r d S_{sharding} = \frac{S_{data}}{S_{shard}} Ssharding?=Sshard?Sdata??
其中, S s h a r d i n g S_{sharding} Ssharding? 是分片效率, S d a t a S_{data} Sdata? 是總數據量, S s h a r d S_{shard} Sshard? 是單個分片的數據量。
3.1.4 案例分析:跨地域數據策略的實施
為了更具體地說明這些策略的應用,我們可以考慮一個跨國電子商務公司的案例。該公司在全球多個地區設有數據中心,需要確保所有用戶都能快速訪問其服務。通過實施以下策略,該公司實現了高效的跨地域數據管理:
-
數據同步:使用實時同步技術,確保所有數據中心的庫存數據保持一致,從而避免了超賣的情況。
-
數據復制:在每個數據中心創建主數據庫的副本,以提高讀取性能和容錯能力。通過監控復制延遲,確保數據的一致性。
-
數據分片:根據用戶的地理位置將用戶數據分片,使得用戶請求可以被最近的數據中心處理,從而減少延遲。
3.1.5 小結
跨地域數據策略是全球化數據管理的關鍵組成部分。通過合理選擇和實施數據同步、復制和分片策略,企業可以有效地應對數據一致性、可用性和性能的挑戰。隨著技術的不斷進步,這些策略將繼續演化,為企業帶來更多的靈活性和效率。通過深入理解和應用這些策略,企業可以更好地適應全球化的商業環境,實現數據驅動的決策和創新。
3.2 數據一致性與合規性:全球數據管理的法律與隱私考量
在全球化的數據管理實踐中,確保數據的一致性和合規性是企業面臨的關鍵挑戰。隨著數據保護法規的日益嚴格,企業不僅需要關注技術層面的數據同步和復制,還必須深入理解并遵守各國的法律和隱私規定。本節將探討如何在跨地域數據管理中實現數據一致性和合規性,并提供相關的法律和隱私考量。
3.2.1 數據一致性的技術挑戰
數據一致性是指在分布式系統中,所有數據副本保持同步和一致的狀態。在跨地域數據管理中,由于網絡延遲、數據復制延遲和并發操作等因素,保持數據一致性是一個復雜的問題。數據一致性可以通過以下數學模型來量化:
C c o n s i s t e n c y = N c o n s i s t e n t N t o t a l × 100 % C_{consistency} = \frac{N_{consistent}}{N_{total}} \times 100\% Cconsistency?=Ntotal?Nconsistent??×100%
其中, C c o n s i s t e n c y C_{consistency} Cconsistency? 是數據一致性的百分比, N c o n s i s t e n t N_{consistent} Nconsistent? 是保持一致的數據副本數量, N t o t a l N_{total} Ntotal? 是總的數據副本數量。
3.2.2 合規性的法律框架
合規性要求企業在處理個人數據時遵守相關的法律和規定。例如,GDPR要求企業在處理歐盟居民的個人數據時必須遵循數據最小化、目的限制、存儲限制和數據主體權利等原則。合規性可以通過以下數學模型來評估:
C c o m p l i a n c e = N c o m p l i a n t N t o t a l × 100 % C_{compliance} = \frac{N_{compliant}}{N_{total}} \times 100\% Ccompliance?=Ntotal?Ncompliant??×100%
其中, C c o m p l i a n c e C_{compliance} Ccompliance? 是合規性的百分比, N c o m p l i a n t N_{compliant} Ncompliant? 是符合法律要求的數據處理操作數量, N t o t a l N_{total} Ntotal? 是總的數據處理操作數量。
3.2.3 隱私保護的技術措施
為了保護用戶隱私,企業需要實施各種技術措施,如數據加密、匿名化和訪問控制。數據加密可以通過數學算法來實現,例如使用RSA算法進行非對稱加密:
E c i p h e r t e x t = R S A ( E p r i v a t e , D p l a i n t e x t ) E_{ciphertext} = RSA(E_{private}, D_{plaintext}) Eciphertext?=RSA(Eprivate?,Dplaintext?)
其中, E c i p h e r t e x t E_{ciphertext} Eciphertext? 是加密后的密文, E p r i v a t e E_{private} Eprivate? 是私鑰, D p l a i n t e x t D_{plaintext} Dplaintext? 是明文數據。
3.2.4 案例分析:跨國公司的數據合規策略
考慮一家跨國公司,其業務遍布全球,需要處理來自不同國家和地區的用戶數據。該公司采取了以下策略來確保數據一致性和合規性:
-
數據同步:使用分布式事務處理技術,確保在不同地理位置的數據庫之間實現強一致性。
-
合規性審查:定期進行合規性審查,確保所有數據處理活動符合當地法律和國際標準。
-
隱私保護:實施端到端的數據加密,確保數據在傳輸和存儲過程中的安全性。同時,對敏感數據進行匿名化處理,以保護用戶隱私。
3.2.5 小結
在全球數據管理中,數據一致性和合規性是企業必須面對的重要挑戰。通過采用先進的技術和策略,企業可以有效地實現數據一致性,并確保遵守相關的法律和隱私規定。隨著數據保護法規的不斷發展,企業需要持續關注法律變化,并調整其數據管理策略,以適應不斷變化的全球數據環境。通過深入理解和應用這些策略,企業可以更好地保護用戶隱私,同時確保數據的準確性和可用性,從而在全球市場中保持競爭力。
3.3 實戰代碼與案例剖析:全球數據管理的有效策略
在全球化的商業環境中,數據管理策略的有效性直接關系到企業的運營效率和合規性。本節將通過具體的實戰代碼和案例剖析,展示如何實施全球數據管理的有效策略。我們將探討數據同步、復制、分片以及合規性管理的實際操作,并提供相關的數學模型和算法。
3.3.1 數據同步的實戰代碼
數據同步是確保跨地域數據庫一致性的關鍵技術。以下是一個簡化的數據同步實戰代碼示例,使用Python語言和MySQL數據庫:
import mysql.connector
from mysql.connector import errorcode# 配置數據庫連接
config = {"user": "username","password": "password","host": "192.168.1.1","database": "database_name","raise_on_warnings": True
}try:cnx = mysql.connector.connect(**config)cursor = cnx.cursor()# 同步數據query = ("SELECT * FROM table_name")cursor.execute(query)for (column1, column2, ...) in cursor:print("{} / {} / ...".format(column1, column2))cursor.close()cnx.close()except mysql.connector.Error as err:if err.errno == errorcode.ER_ACCESS_DENIED_ERROR:print("Something is wrong with your user name or password")elif err.errno == errorcode.ER_BAD_DB_ERROR:print("Database does not exist")else:print(err)
3.3.2 數據復制的實戰代碼
數據復制是提高數據可用性和讀取性能的常用策略。以下是一個使用MySQL的復制功能進行數據復制的實戰代碼示例:
-- 在主數據庫上配置復制
CHANGE MASTER TO MASTER_HOST='master_host_name', MASTER_USER='replication_user_name', MASTER_PASSWORD='replication_password', MASTER_LOG_FILE='recorded_log_file_name', MASTER_LOG_POS=recorded_log_position;-- 啟動復制
START SLAVE;
3.3.3 數據分片的實戰代碼
數據分片是將大型數據庫分割成多個較小的部分,以提高性能和管理效率。以下是一個使用哈希函數進行數據分片的實戰代碼示例:
def hash_shard(key, num_shards):return hash(key) % num_shards# 示例使用
key = "user_id_123"
num_shards = 10
shard_id = hash_shard(key, num_shards)
print("Shard ID for key {} is {}".format(key, shard_id))
3.3.4 合規性管理的實戰代碼
合規性管理涉及到數據處理活動的監控和審計。以下是一個使用Python和SQLite進行數據審計的實戰代碼示例:
import sqlite3# 連接到SQLite數據庫
conn = sqlite3.connect('audit.db')
cursor = conn.cursor()# 創建審計表
cursor.execute('''CREATE TABLE IF NOT EXISTS audit_log(timestamp TEXT, user TEXT, action TEXT)''')# 記錄審計日志
cursor.execute("INSERT INTO audit_log VALUES (CURRENT_TIMESTAMP, 'user_name', 'data_action')")# 提交更改并關閉連接
conn.commit()
conn.close()
3.3.5 案例剖析:跨國公司的數據管理策略
考慮一家跨國公司,其業務遍布全球,需要處理來自不同國家和地區的用戶數據。該公司采取了以下策略來確保數據一致性和合規性:
-
數據同步:使用分布式事務處理技術,確保在不同地理位置的數據庫之間實現強一致性。
-
合規性審查:定期進行合規性審查,確保所有數據處理活動符合當地法律和國際標準。
-
隱私保護:實施端到端的數據加密,確保數據在傳輸和存儲過程中的安全性。同時,對敏感數據進行匿名化處理,以保護用戶隱私。
3.3.6 小結
通過實戰代碼和案例剖析,我們可以看到全球數據管理的有效策略是如何在實際中應用的。這些策略不僅涉及技術層面的實現,還包括法律和隱私的考量。隨著技術的不斷進步,企業需要持續關注并適應新的數據管理技術和法規要求,以確保在全球化競爭中保持領先地位。通過深入理解和應用這些策略,企業可以更好地保護用戶隱私,同時確保數據的準確性和可用性,從而在全球市場中保持競爭力。
3.4 架構可視化:全球化數據管理架構的直觀展示
在全球化數據管理中,架構可視化是一種強大的工具,它幫助企業和技術團隊直觀地理解和優化復雜的數據管理架構。通過圖形化的展示,我們可以更清晰地看到數據流、系統交互和架構設計,從而更有效地進行決策和優化。本節將探討如何通過可視化技術來展示全球化數據管理架構,并提供一些實用的工具和方法。
3.4.1 數據流的可視化
數據流可視化是展示數據如何在不同系統和服務之間流動的過程。這通常涉及到使用流程圖、時序圖或數據流圖來表示數據的傳輸路徑。例如,一個簡單的數據流圖可以表示如下:
在這個圖中,用戶(A)向應用服務器(B)發送請求,應用服務器處理請求并從數據庫(C)獲取數據,最后將響應返回給用戶。
3.4.2 系統架構的可視化
系統架構可視化涉及到使用架構圖來展示系統的組件和它們之間的關系。這可以幫助理解系統的整體結構和組件之間的依賴關系。例如,一個云原生數據庫的架構圖可能包括以下組件:
- 數據庫實例
- 負載均衡器
- 存儲服務
- 安全層
這些組件可以通過UML圖或更直觀的圖形工具如Draw.io來展示。
3.4.3 數據分片和復制的可視化
數據分片和復制是全球化數據管理中的關鍵技術。通過可視化,我們可以展示數據如何被分割成多個部分,并在不同的地理位置進行復制。例如,一個數據分片的可視化可能展示如下:
在這個圖中,主數據庫(A)將數據分片到三個不同的分片數據庫(B, C, D)。
3.4.4 合規性和安全性的可視化
合規性和安全性是全球化數據管理中不可忽視的方面。通過可視化,我們可以展示數據如何被加密、匿名化以及如何遵守各種數據保護法規。例如,一個數據加密的可視化可能展示如下:
在這個圖中,明文數據(A)被加密成密文數據(B),然后存儲在安全的存儲系統(C)中。
3.4.5 案例分析:跨國公司的數據管理架構可視化
考慮一家跨國公司,其業務遍布全球,需要處理來自不同國家和地區的用戶數據。該公司通過以下步驟實現了數據管理架構的可視化:
-
數據流可視化:使用流程圖展示了數據從用戶到應用服務器再到數據庫的完整路徑。
-
系統架構可視化:通過架構圖展示了云原生數據庫的各個組件及其交互。
-
數據分片和復制可視化:展示了數據如何在不同地理位置進行分片和復制。
-
合規性和安全性可視化:展示了數據如何在整個流程中保持安全和合規。
3.4.6 小結
架構可視化是理解和優化全球化數據管理架構的關鍵工具。通過清晰地展示數據流、系統架構、數據分片和復制以及合規性和安全性,企業和技術團隊可以更有效地進行決策和優化。隨著技術的不斷進步,可視化工具和方法也將不斷發展,幫助我們更好地應對全球化數據管理的挑戰。通過深入理解和應用這些可視化策略,企業可以更好地保護用戶隱私,同時確保數據的準確性和可用性,從而在全球市場中保持競爭力。

4. 結語:展望未來
在本文中,我們深入探討了未來數據庫革新的關鍵領域,包括智能數據庫管理、云原生數據庫以及全球化數據管理。這些技術的發展不僅推動了數據處理能力的飛躍,也為企業帶來了前所未有的機遇和挑戰。在結語部分,我們將展望這些技術的未來趨勢,探討它們如何影響不同行業,并提供個人和企業的行動建議。
4.1 技術融合的趨勢:AI、云原生與區塊鏈的協同作用
隨著技術的不斷進步,AI、云原生和區塊鏈等技術的融合將成為推動數據庫革新的重要力量。AI的智能分析能力與云原生的彈性、自動化特性相結合,將使數據管理更加高效和智能。例如,通過機器學習算法優化數據庫查詢,可以顯著減少查詢時間,提高數據檢索效率。此外,區塊鏈技術的引入可以增強數據的安全性和不可篡改性,這對于金融、醫療等行業的數據管理尤為重要。
數學上,我們可以通過優化理論來分析和設計這些系統的效率。例如,使用線性規劃或整數規劃來優化資源分配,確保在有限的資源下實現最大的性能提升。公式如下:
maximize c T x subject?to A x ≤ b , x ≥ 0 \text{maximize} \quad c^T x \\ \text{subject to} \quad A x \leq b, \quad x \geq 0 maximizecTxsubject?toAx≤b,x≥0
其中, x x x 是決策變量, c c c 是目標函數的系數, A A A 和 b b b 是約束條件。
4.2 數據管理的未來挑戰:隱私保護與合規性
隨著數據量的激增,數據隱私和合規性成為全球數據管理面臨的主要挑戰。GDPR等法規的實施要求企業必須嚴格遵守數據保護規定,這不僅涉及技術層面的數據加密和匿名化處理,還需要在組織結構和業務流程上進行相應的調整。
在數學上,隱私保護可以通過差分隱私(Differential Privacy)來實現,其核心思想是在數據發布時添加一定的隨機性,以保護個體信息不被識別。差分隱私的數學定義如下:
? ? differentially?private ? ? S ? R a n g e ( M ) , Pr ? [ M ( x ) ∈ S ] ≤ e ? Pr ? [ M ( x ′ ) ∈ S ] \epsilon-\text{differentially private} \iff \forall S \subseteq Range(M), \quad \Pr[M(x) \in S] \leq e^\epsilon \Pr[M(x') \in S] ??differentially?private??S?Range(M),Pr[M(x)∈S]≤e?Pr[M(x′)∈S]
其中, M M M 是一個隨機算法, x x x 和 x ′ x' x′ 是相鄰數據集, ? \epsilon ? 是一個小的正數,控制隱私保護的程度。
4.3 教育與培訓:培養未來的數據庫專家
面對這些技術變革,教育與培訓成為關鍵。未來的數據庫專家不僅需要掌握傳統的數據庫知識,還需要深入理解AI、云原生和區塊鏈等新興技術。教育機構和企業應合作開發新的課程和培訓項目,以確保人才的持續供應和技術的順利過渡。
4.4 結語:行動建議
對于個人,建議積極學習新技術,特別是AI和云原生相關的知識,以提升自身的競爭力。對于企業,建議制定長期的技術發展規劃,投資于新技術和人才培訓,同時密切關注行業法規的變化,確保合規性。
總之,未來的數據庫技術將繼續以驚人的速度發展,為我們帶來更多的可能性和挑戰。讓我們擁抱變化,共同迎接這個充滿機遇的新時代。




下載鏈接】)
)





-- FGHIJ開頭)







