關單操作?
- 優先考慮定時任務、Redisson+redis、RocketMQ延遲消息實現(訂單量特別大的時候,不建議使用MQ)
- 每個訂單都有一個消息會增加資源消耗
- 可靠性問題(丟失)
- 大量的無效消息
- 不是所有消息隊列都支持
- 一般通過定時任務實現,像阿里內部就是超時中心(TOC)
- 定時任務:Timer、定時任務線程池、XXL-JOB這種
- 時間不精確
- 無法處理大量訂單
- 掃描數據庫造成壓力大
- 分庫分表后需要全表掃描
- Redisson+redis
- Redisson定義了分布式延遲隊列RDelayedQueue,在zset的基礎上增加了一個基于內存的延遲隊列
- 當添加一個元素到延遲隊列的時候,將數據和超時時間放進zset中,啟動一個延時任務,當任務到期的時候,就將zset中的數據取出來,返回給客戶端使用。
每天100w次登錄請求,4核8G機器如何做JVM調優?
- 首先確定有沒有流量高峰?假設存在某一段時間有峰值,比如30min,那么QPS就是600左右,應該做怎樣的優化?
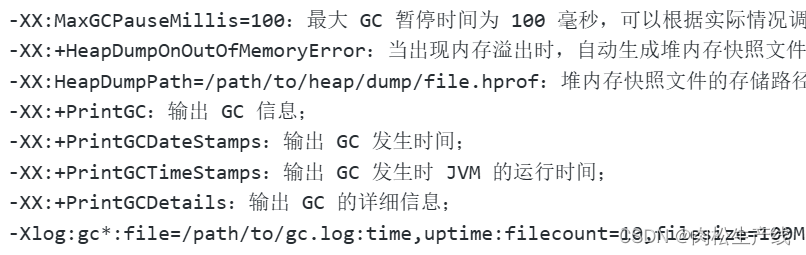
- 將堆內存設置為操作系統的一半。初始和最大設置成一樣的,避免擴容收縮操作,提高穩定性。
- 垃圾收集器選擇:
- 考慮STW和吞吐量的問題
- serial排除,parnew和parallel scavange更關注吞吐量,4G可以使用G1
- 通過-XX:MaxGCPauseMills=100~200之間
- 然后調節G1的一些配置,比如并行線程數,并發線程數
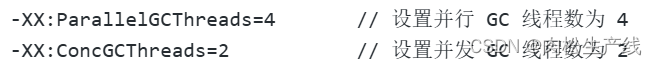

- 添加日志,動態調整
如果QPS提高了一百倍,應該怎么辦?
- DDOS攻擊
- 設計一個支持高并發的系統:
- 架構、性能優化、容錯、可伸縮性等等
- 分布式架構:降低單點故障的風險,提高可伸縮性和性能
- 集群部署:負載均衡,提高可用性和性能
- 緩存
- 異步處理:消息隊列等降低請求響應時間和提高吞吐量
- 預加載:預先加載需要的資源,減少等待時間
- 代碼優化和調優:避免長事務、減小鎖的粒度等,提高性能
- 數據庫優化:索引設計、分庫分表、讀寫分離
- 熔斷降級限流:防止雪崩
- 壓力測試
- 容錯和監控
不使用redis分布式鎖,如何防止用戶重復點擊?
- 滑動窗口限流
- token,判斷token有沒有被消費過,在數據庫判斷
- 前端按鈕
- 一般redis使用不了一般是降級成直接使用數據庫。
購物車功能?
- 不需要把商品的所有信息保存下來,只需要保存SKUID加上數量時間等,至于其他的到時候反查數據庫就可以。
- 未登錄用戶存在cookie和LocalStorage里面
- 登陸的要么存數據庫,要么存redis
- 數據庫和redis各有好處,可靠性,性能權衡,mysql有事務機制。
秒殺系統?
- 高并發瞬時流量
- 架構方面做逐層的流量過濾,經過客戶端、CDN、WEB、緩存、數據庫
- 客戶端做一些隨機請求的過濾
- Nginx做一些流量的過濾,IP限流等等
- 服務器sentinel限流
- 查詢操作寫操作用緩存抗一下,緩存上本地緩存性能要高于分布式緩存
- 熱點數據:
- 拆分+緩存
- 緩存就是做一些預熱,不僅redis做預熱,本地緩存也做預熱,防止熱點key問題
- 數據量大:
- 分庫分表
- 庫存正確扣減:
- 如何避免超賣少賣
- 從redis中取出當前庫存,lua腳本執行達到原子性+有序性,redisson的信號量
- redis中先扣減,發一個MQ消息,之后再做真正的數據庫扣減操作
- 導致少賣:
- 引入對賬機制,比如用zset添加流水記錄,定時拉取一段時間內的所有記錄,然后數據庫比對,發現不一致就進行補償處理
- 如果商家在過程中補貨了?
- 增加一個全局標志位,在補貨過程中不允許扣減庫存,補貨的數量相應的去redis里更新,這樣會導致用戶停滯
- 訂閱binlog,補了多少就去redis修改多少。
- 業務手段:
- 預約
- 預售
- 前端弄些驗證碼
Zset實現點贊和排行榜?
- 朋友圈點贊:
- 首先分析朋友圈點贊是什么功能
- 被點贊人的微信號
- 點贊人的微信號
- 點贊時間
- 通過zset實現
- key被點贊人的這篇朋友圈的ID
- value表示點贊人的微信號
- score表示點贊的時間
- 點贊就更新score,jedis.zadd(key,cow,userId)
- 取消點贊就移除,jedis.zrem(key,userId)
- 查詢就通過ZREVRANGEBYSCORE命令逆序返回點贊人的微信號


- 首先分析朋友圈點贊是什么功能
- 排行榜
- 在score相同時,會按照value排序
- 那么score設置為分數+(1-時間戳小數)
查找附近的人的功能?
- 通過Redis的GEOADD將用戶的經緯度存在一個指定的鍵值中,然后通過redis的GEORADIUS命令查詢指定經緯度附近一定范圍的用戶。
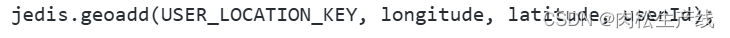
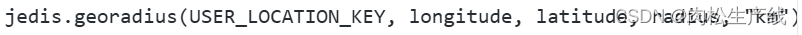
消息隊列推好還是拉好?
- 推模式就是在消費端和消息中間件建立TCP長連接或者注冊一個回調,有數據就通過長連接或者回調將數據推送
- 拉就是消費者輪詢,通過不斷輪詢檢查有沒有數據。
- 拉可以自己掌握消息數量和速度,但是輪詢有對中間件有一定的壓力
- 推消息是實時的,缺點就是如果生產速度大于消費速度消費者會產生堆積,容易壓垮。
- 看消費者和消息中間件是不是雙向通信。
- 使用長輪詢:發起一個長輪詢請求,有消息就返回,沒有就等一會兒,等到有新消息到達。還沒有就等下一次長輪詢。
如何進行SQL調優的?
- 首先定位到慢sql的地方
- 接下來分析
- 索引失效:查詢執行計劃是否執行了索引
- 多表join:嵌套循環,外循環的每條記錄都要和內循環的記錄做比較,n張表就O(N^n)的復雜度。Mysql8中增加了Hash join,驅動表的數據會構建一張hash表,然后被驅動表的去進行匹配,最后聚合,但是有內存限制,此時就可以通過基于磁盤的hash joi,分批加載,到達O(N)的復雜度。
- 索引離散度低:
- 查詢字段太多:避免冗余查詢
- 表數據量太大:建立索引不一定能解決了,通過數據歸檔,比如只保留半年內的數據,或者說是分庫分表、分區。
- 數據庫連接不夠:業務量大就分庫,慢SQL、長事務,并發大的情況下存在排隊,就可以像上迷案的秒殺服務那樣解決。還有一個改造Mysql,比如阿里的Inventory-Hint。
- 表結構不合理:做一些反范式化,冗余字段,避免join。
- 數據庫參數不合理,增加事務文件大小,緩沖池大小,read線程數
- 參數調優
不用synchronized實現線程安全單例?
餓漢可以,靜態內部類、枚舉也可以,還能用CAS實現,但是其實loadclass就是synchronized修飾的。
private static final AtomicReference<Lazy> INSTANCE=new AtomicReference<>();//CAS實現//原子性可見性有序性都保證了,但是會造成CPU開銷public static Lazy casInstance(){while (true){Lazy singleton = INSTANCE.get();if (null!=singleton){return singleton;}Lazy ans = new Lazy();if (INSTANCE.compareAndSet(null,ans)){return singleton;}}}本地緩存和分布式緩存有什么區別?
- 兩種不同的緩存架構,主要區別在于數據的存儲和管理方式
- 本地緩存是指將數據存儲在單個應用程序中,提高性能,減少數據庫訪問次數,但是在集群環境中,多個本地緩存中數據可能不一致。Caffeine,異步化比較好
- 分布式緩存的優點在于共享數據,提高系統的可伸縮性和可用性,但是有數據一致性、故障恢復,管理和維護成本。
多級緩存是怎么應用的?
- 客戶端緩存、CDN緩存、Nginx這兩個放靜態資源,然后本地、分布式緩存
Innodb用跳表,redis用B+數可以嗎?
-
關系型數據庫以表的形式存儲,非關系型以key-value的形式存儲
-
B+磁盤友好(順序性,以及磁盤預讀,頁分裂時就讀取或者修改一頁),跳表內存友好(多級索引結構,磁盤IO性能低)
接口很慢如何定位問題?
- 阿里的arthas定位,比如是哪個商品相關的,然后分析SQL,進行SQL調優
如何保證REDIS中的數據都是熱點數據?
- 數據預熱,先將熱的數據先加進去
- 熱點數據更新:熱key檢測
- 過期策略:LRU或者LFU
- 緩存淘汰策略
用了一鎖二查三更新,為什么還有重復數據?
- 存在鎖已經釋放了,但是事務還沒提交,然后后面進來的接著操作。
- 主要就是因為事務的粒度大于鎖的粒度
- 聲明式事務@Transactional改為編程式事務

一個接口QPS3000,接口RT為200ms,需要幾臺機器?
- 那么就是單線程一秒處理5個請求,假設tomcat有200個線程,那么吞吐量就是1000個/s
- 實際需要做壓測,然后預估2-3倍數,大概6-9臺機器。
商城系統如何設計一個數據一致性方案?
- 比如下單的時候需要有訂單系統、庫存系統、積分系統、郵件系統、外部機構這些組成
- 像完整的分布式事務的話:
- 訂單系統和庫存系統就考慮強一致性
- 積分系統考慮最終一致性
- 郵件考慮最大努力通知
- 像外部的話,很多因素影響,一般是在協議上約定:
- 風控通過,投保一定成功
- 先資金流理賠,再補齊信息流
- 每天異步同步一次就可以了
如何實現緩存預熱?
- 啟動預熱:

- 定時任務:類似于秒殺活動,開始前一天先把相關數據放進redis里面
- 用時加載
- 緩存加載器:比如caffeine就有,定義一些機制
應用占用內存持續升高,堆內存、元空間都沒變化,可能原因?
- bytebuffer使用直接內存,未回收
- 線程棧
- JNI或者本地代碼




-- FGHIJ開頭)









 關閉窗口不生效的處理方案)




