文章目錄
- 0、準備
- 1、緩存穿透:不存在的key
- 2、緩存擊穿:熱點key過期
- 3、緩存雪崩:大批key同時過期
- 4、雙寫一致性
- 4.1 要求高一致性
- 4.2 允許一定的一致延遲
- 5、面試
0、準備
Redis相關概覽:
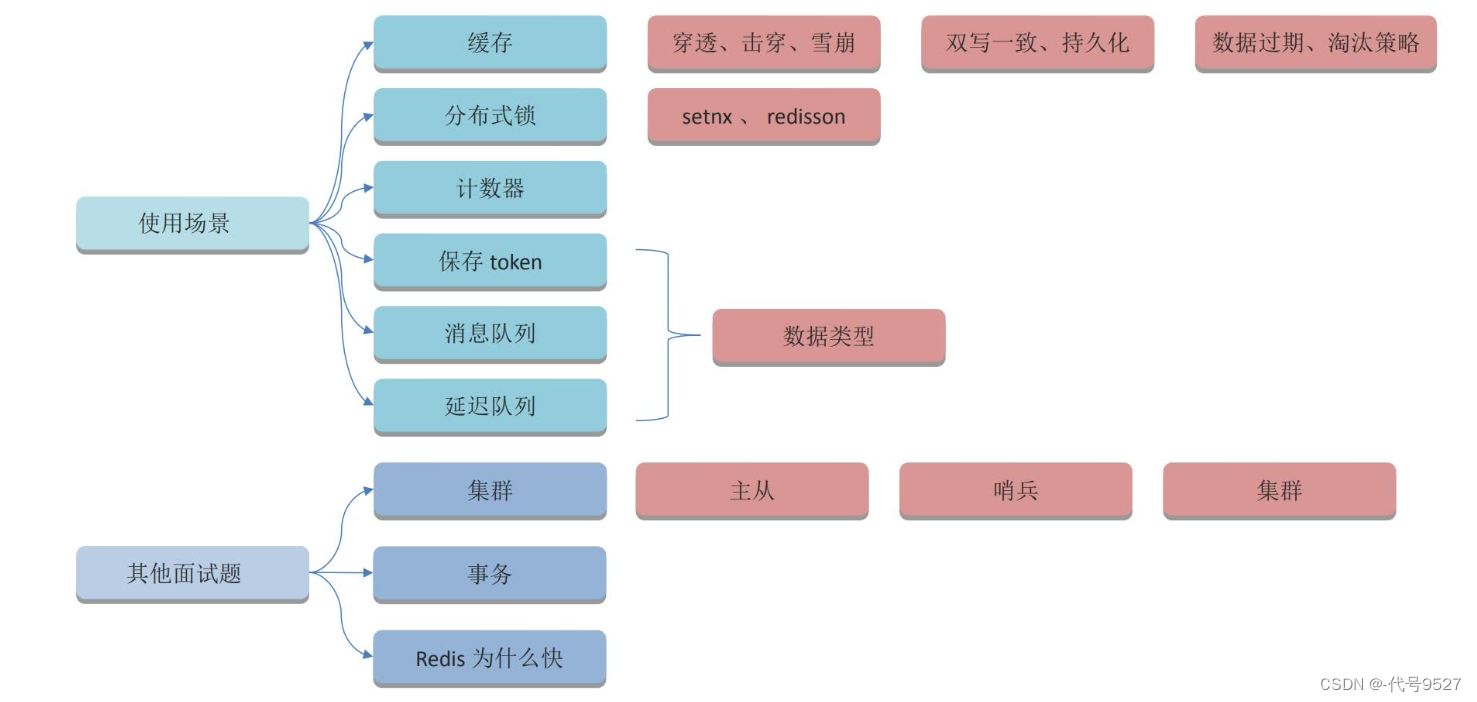
以簡歷上所列的項目為切入點,展開Redis相關的問題:

1、緩存穿透:不存在的key
Client ? Redis ? MySQL,緩存穿透,即中間的Redis形同虛設,請求每次過來都查庫。一般是網站被攻擊時,瘋狂造不存在數據,然后發起請求,沖擊數據庫,消耗數據庫連接池資源,直到服務不可用。
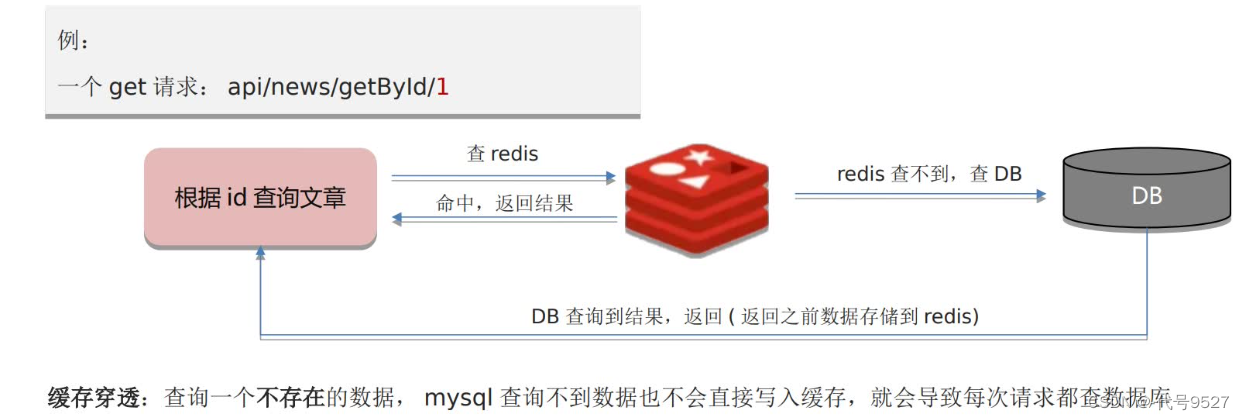
解決方案一:緩存空數據

查到的結果為空也寫進Redis。實現簡單但消耗內存,可能會發生不一致的問題(即庫里有數據了,但緩存里依舊是null,導致查不到最新數據)
解決方案二:布隆過濾器
緩存預熱的時候,往布隆過濾器中添加數據。后面請求過來時,先經過布隆過濾器,判斷ID不存在的話,直接返回,都走不到Redis。
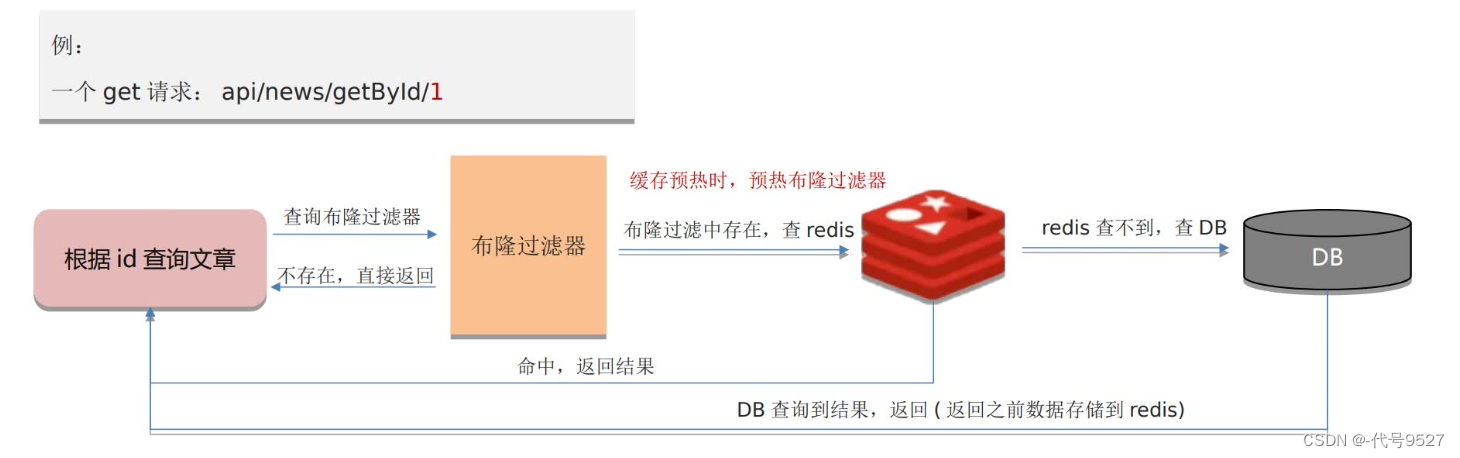
如此,內存占用少,但實現復雜,且存在誤判(即有的ID不存在,但布隆過濾器會判斷為存在)

bitmap(位圖):一個bit數組,每個單元非0即1。預熱ID的時候,用多個hash函數獲取該ID的hash值,并把bitmap對應位置改為1。后面查數據是否存在時,就用相同的hash函數獲取hash值,查看對應的位置是否都為1。由此,布隆過濾器實現了檢索一個元素是否在一個集合中。
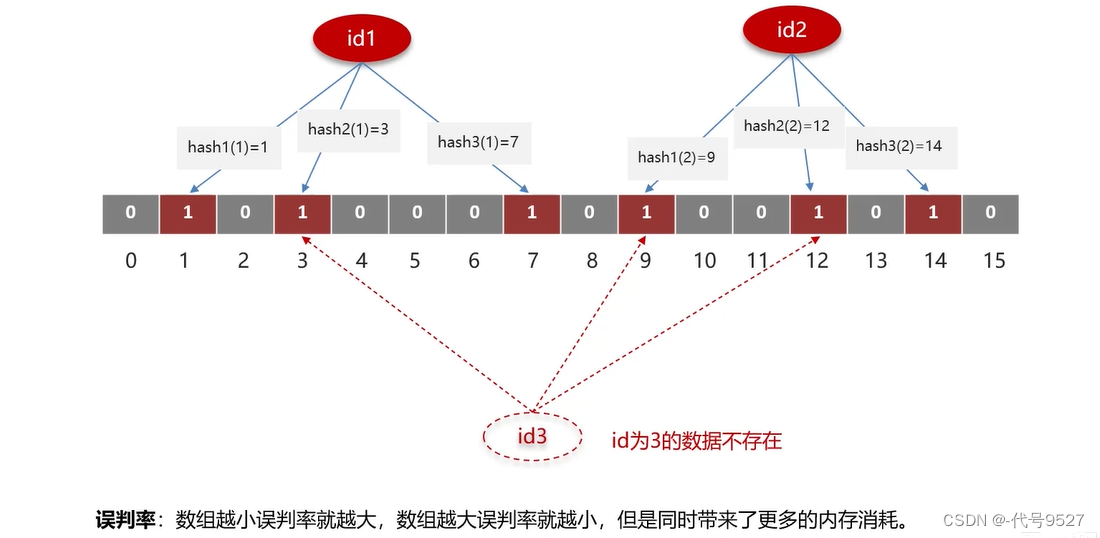
如上,id1和id2點亮了1、3、7和9、12、15的位置為1,id3雖然不存在,但其hash值所在位置都為1,判定為是存在的ID,即誤判。數組越大,誤判率越低。
2、緩存擊穿:熱點key過期
給一個熱點key設置了過期時間,當這個key過期的時候,恰好有大量請求查這個key,這些請求自然都走到了數據庫,可能導致DB服務不可用。如下圖,比如查詢一次MySQL再寫到Redis需要50ms,熱點數據過期后,這50ms內的大量請求都會沖到數據庫

解決方案一:添加互斥鎖
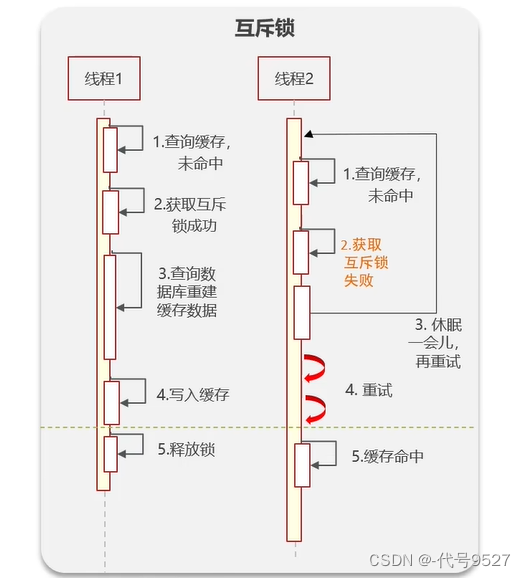
緩存未命中,查庫前,獲取一個互斥鎖,獲取不到則一直重試,如此,后面的線程走不到查庫這一步,直到線程1完成查庫+寫入Redis,其余線程就會命中緩存。如此,保護了數據庫服務且保證了數據強一致性,但性能不好
解決方案二:邏輯過期
Redis層面,不設置過期時間,但業務層面加一個過期時間,如
| key | value |
|---|---|
| 001 | {“id”:“123”,“title”:“標題1”,"expire":1716368322} |

即明天16:58的時候,這條數據邏輯過期,但你在Redis中還能查到,不過是查到了過期數據,不是最新的。具體流程:
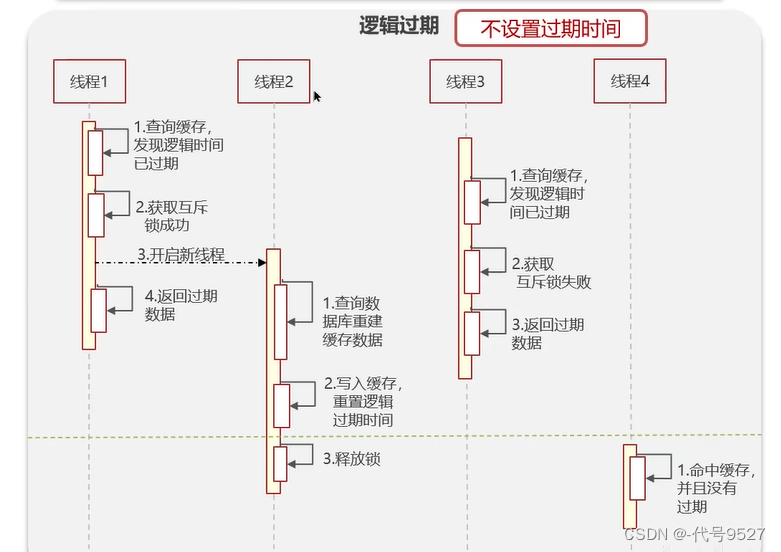
線程1過來查緩存,發現當前時間超過了緩存的邏輯過期時間,于是線程1獲取一個互斥鎖,再開啟一個線程2去查庫 + 更新緩存,自己則先把過期數據返回。此過程中,即使有線程3進來,并發現了已超過邏輯過期時間,它也不會重復去查庫重建緩存,因為它獲取不到互斥鎖,此時線程3會先返回過期數據。 因此,這種方式性能好,但數據一致性不保證。
3、緩存雪崩:大批key同時過期
同一時間段,大量緩存的key過期,或者Redis服務宕機,導致大量請求沖到數據庫

解決思路是:給不同的key添加隨機的TTL(過期時間),如此,大量的key不會同時過期。至于Redis宕機,則可以用Redis哨兵模式或者集群模式、給業務添加多級緩存等方式解決。
最后,降級限流,可用于解決緩存穿透、擊穿、雪崩的解決。即服務請求失敗次數到一定閾值,直接走降級策略(比如不查庫,直接返回空)
//Tips:穿透無中生有key,布隆過濾null隔離緩存擊穿過期key,鎖與非期解難題雪崩大量過期key,過期時間要隨機面試必考三兄弟,可用限流來保底
4、雙寫一致性
相關問題:MySQL和Redis的數據如何進行同步。兩種追求:
- 一致性高
- 允許一定的一致延遲
4.1 要求高一致性

讀操作:命中直接返回。未命中緩存則 查庫 + 寫入緩存
寫操作:數據庫更新時,進行延時雙刪

有數據庫的寫操作時,為了數據一致性,如果不雙刪,只刪一次緩存 + 改庫,則實現方式可以是:
- 先刪緩存,再改庫
- 先改庫,再刪緩存
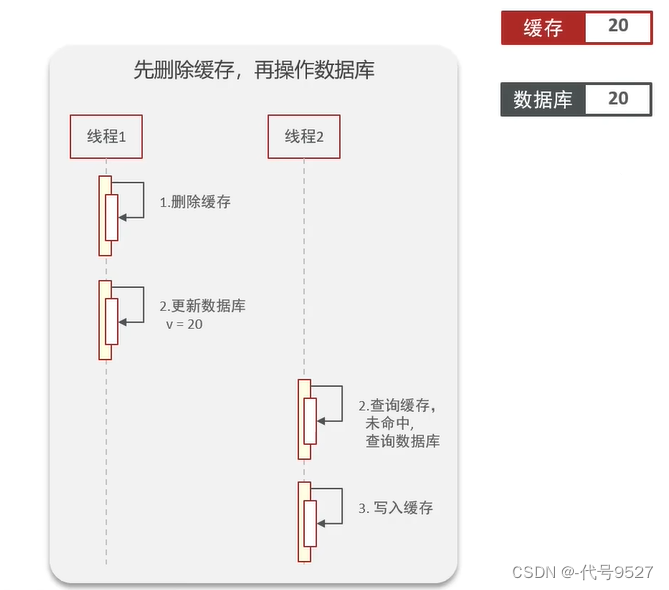
1)若先刪緩存,再改庫:
理想狀態為:線程1刪緩存,再更新數據庫,后面請求過來(對應線程2),先查緩存,未命中,去查庫 + 寫入緩存,一切正常
再看非理想狀況:線程1刪除緩存后掛起,此時緩存為null,庫中為10。然后新的請求進來(對應線程2),CPU切到線程2執行,查緩存未命中,線程2去查庫 + 寫入緩存,線程2執行結束,此時緩存為10,庫中為10。最后線程1解除掛起,繼續執行,線程1去更新了數據庫,此時緩存為10,庫中為20 ,數據不一致!
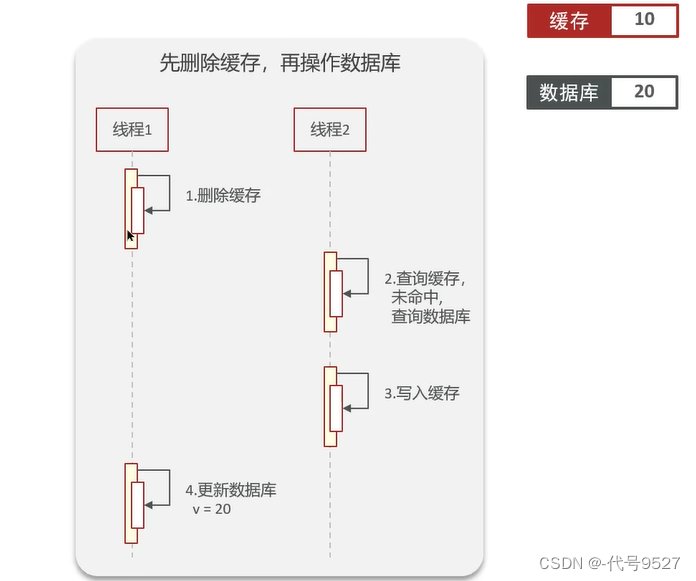
總之,高并發下,線程交替執行,這樣實現會出現數據不一致問題。
2)若先改庫,再刪緩存
理想狀態為:線程2更新數據庫,再刪緩存,此時緩存為null,庫中為20。后面請求過來(對應線程1),先查緩存,未命中,去查庫 + 寫入緩存,一切正常
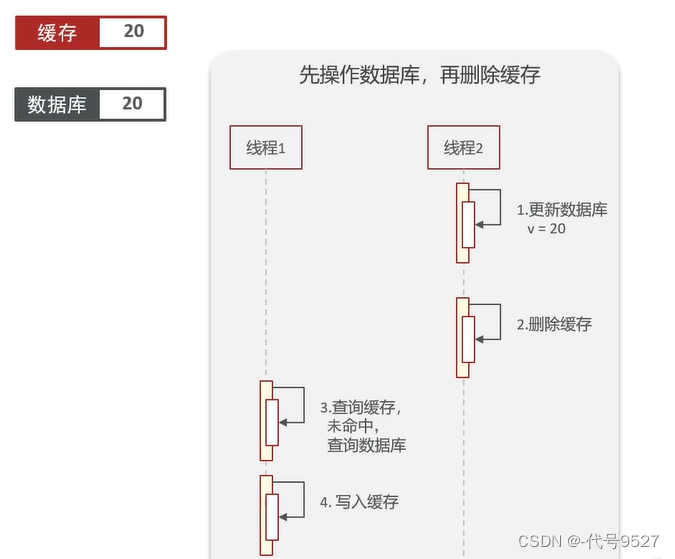
非理想狀態下:比如一開始緩存過期,即緩存中為null,庫中為10,線程1進來未命中緩存,查庫得到10,然后掛起。請求2進來(對應線程2),其進行了update,改庫,并刪緩存,此時,庫中為20,緩存中為null。線程2執行結束,線程1解除掛起繼續執行,將查到的數據,寫入緩存。此時緩存中為10,庫中為20,數據不一致。
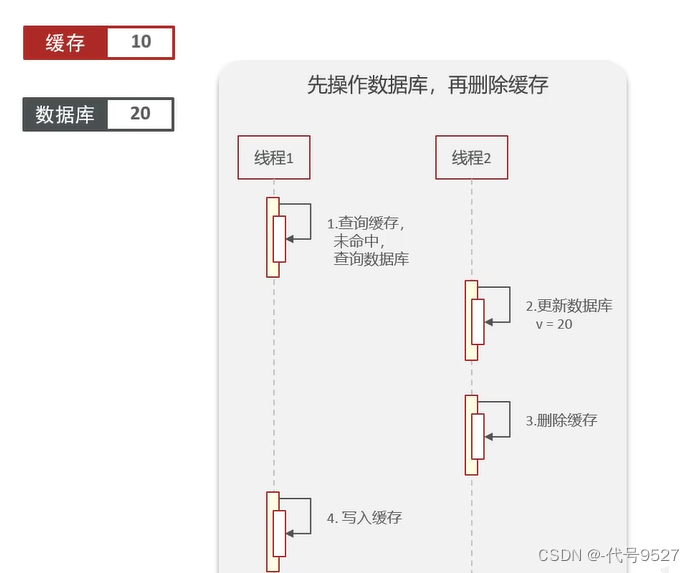
因此,不管先刪緩存還是先改庫,都可能出現數據不一致
==> 延時雙刪:先刪緩存,數據庫更新完后,再刪一次緩存。至于為什么要延時后第二次刪,是因為如果數據庫是主從模式,讀寫分離,那就需要等主節點把數據同步到從節點。但這個延時的大小不好控制,還是可能出現臟數據。想強一致,可用分布式鎖。
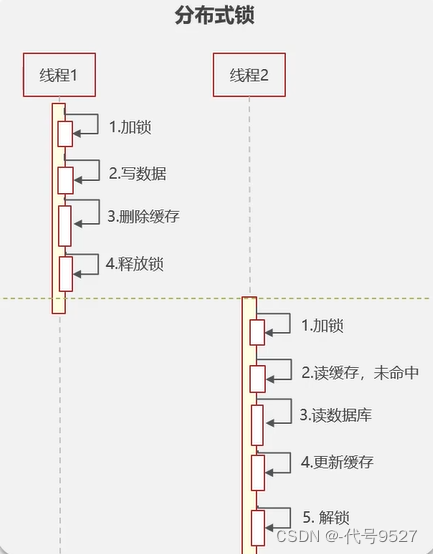
一個線程在更新數據前,加鎖,update庫 + 刪緩存后,釋放鎖。期間,其余線程不能讀寫。以上可優化為:讀數據的時候,添加共享鎖,讀讀共享,讀寫互斥。寫數據的時候,加排他鎖,阻塞其他線程的讀和寫。如此,實現數據強一致性,但性能低。
4.2 允許一定的一致延遲
異步通知,保證數據的最終一致性。業務服務更新庫后,發消息到MQ,緩存服務監聽MQ,去更新緩存

以上實現對業務代碼有一定的侵入性,需要添加發消息的代碼。可把MQ替換為Canal:
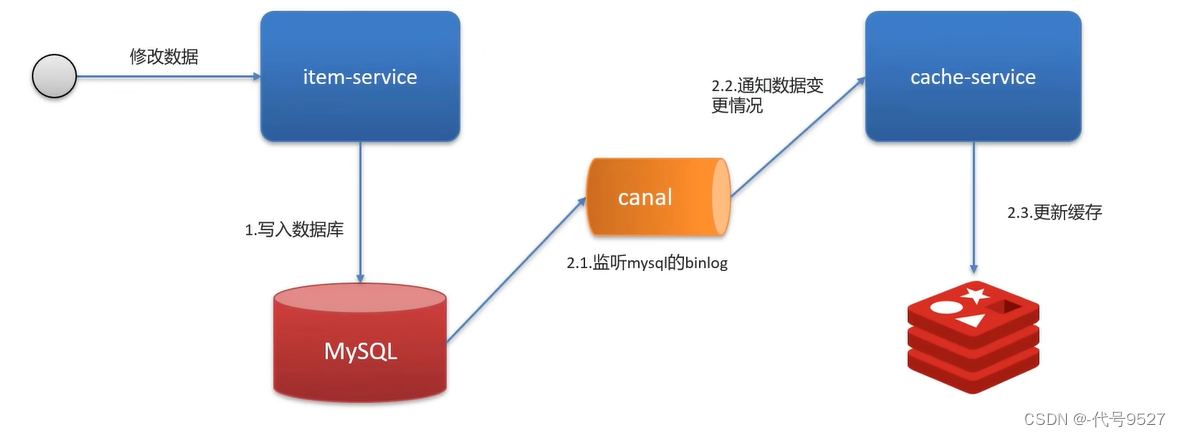
阿里的Canal基于MySQL的主從同步實現。數據庫一旦發生改變,二進制的binlog記錄DDL語句和DML語句,Canal偽裝成MySQL的一個從節點,監聽讀取MySQL的binlog去更新緩存。此方式不用改業務代碼,無侵入性。
最后,如果不要求實時性和強一致性,如熱點文章數據,可用異步方案同步數據。如果要求數據強一致性,如搶券的庫存,則采用redisson提供的讀寫鎖保證數據同步。
5、面試




)


)


頁面,在菜單中不顯示的頁面)







選擇指南)



