資源配額 Resources
在 Kubernetes 中,resources 配置用于設置容器的資源請求和限制,以確保集群中的資源(如 CPU 和內存)得到合理分配和使用。
在之前的pod中,不寫 resources 字段。就意味著 Pod 對運行的資源要求“既沒有下限,也沒有上限”,Kubernetes 不用管 CPU 和內存是否足夠,可以把 Pod 調度到任意的節點上,而且后續 Pod 運行時也可以無限制地使用 CPU 和內存。
Pod 可能會因為資源不足而運行緩慢,或者是占用太多資源而影響其他應用,所以我們應當合理評估 Pod 的資源使用情況,盡量為 Pod 加上限制。
Pod 容器的描述部分添加一個新字段 resources 進行資源限額
ngx-pod-resources.yml
apiVersion: v1
kind: Pod
metadata:name: ngx-pod-resourcesspec:containers:- image: nginx:alpinename: ngxresources:requests:cpu: 10mmemory: 100Milimits:cpu: 20mmemory: 200Mi
containers.resources,它下面有兩個字段:
- “requests”,意思是容器要申請的資源,也就是說要求 Kubernetes 在創建 Pod 的時候必須分配這里列出的資源,否則容器就無法運行。
- “limits”,意思是容器使用資源的上限,不能超過設定值,否則就有可能被強制停止運行。
cpu 和 memory 資源表達方式
- 內存的寫法和磁盤容量一樣,使用 Ki、Mi、Gi 來表示 KB、MB、GB,比如 512Ki、100Mi、0.5Gi 等。
- kubernetes 里 CPU 的最小使用單位是 0.001,為了方便表示用了一個特別的單位 m,也就是“milli”“毫”的意思,比如說 500m 就相當于 0.5。
ngx-pod-resources.yml 向系統申請的是 1% 的 CPU 時間和 100MB 的內存,運行時的資源上限是 2%CPU 時間和 200MB 內存。有了這個申請,Kubernetes 就會在集群中查找最符合這個資源要求的節點去運行 Pod。
Kubernetes 會根據每個 Pod 聲明的需求,像搭積木或者玩俄羅斯方塊一樣,把節點盡量“塞滿”,充分利用每個節點的資源,讓集群的效益最大化。
運行命令
vim ngx-pod-resources.ymlkubectl apply -f ngx-pod-resources.ymlkubectl get pod
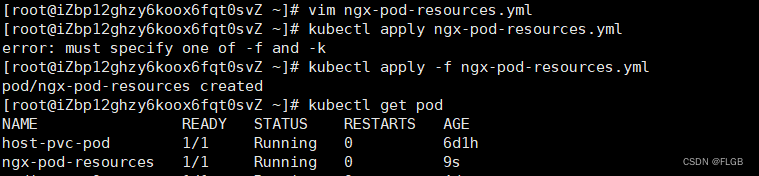
如果pod資源配額不夠,會是什么情況
修改 ngx-pod-resources.yml cpu為10個cpu
apiVersion: v1
kind: Pod
metadata:name: ngx-pod-resourcesspec:containers:- image: nginx:alpinename: ngxresources:requests:cpu: 10memory: 100Milimits:cpu: 20memory: 200Mi
執行命令
kubectl delete -f ngx-pod-resources.yml
kubectl get pod
vim ngx-pod-resources.yml
kubectl apply -f ngx-pod-resources.yml
kubectl get pod
# 獲取pod詳情
kubectl describe pod ngx-pod-resources
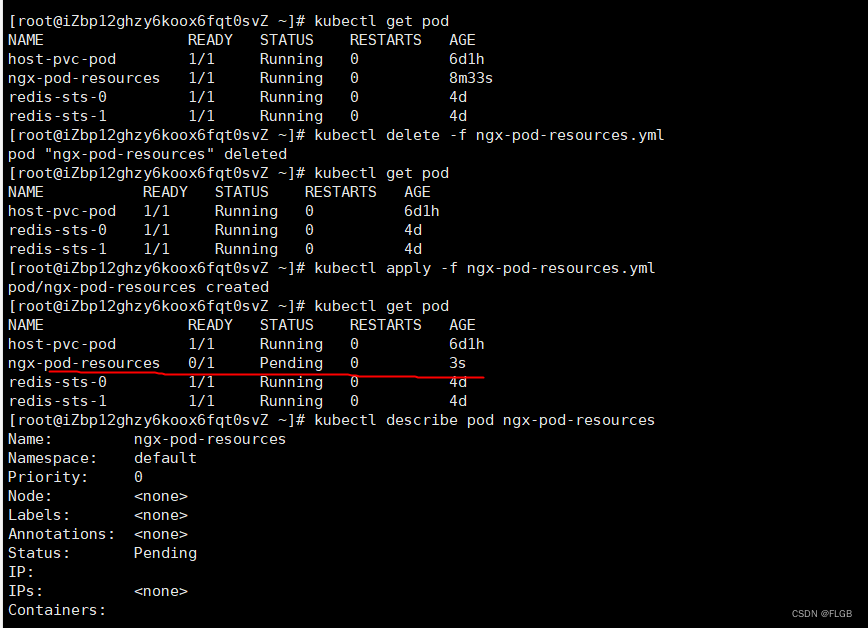
使用 kubectl apply 創建這個 Pod,你可能會驚奇地發現,雖然我們的 Kubernetes 集群里沒有足夠的 CPU,但 Pod 也能創建成功。不過我們再用 kubectl get pod 去查看的話,就會發現它處于“Pending”狀態,實際上并沒有真正被調度運行:

kubectl describe 來查看具體原因,會發現有這么一句提示:
集群中沒有足夠的可用 CPU 資源來調度新的 Pod,同時有一個節點(master 節點)存在污點 (taint),導致 Pod 無法被調度到該節點上。
檢查探針 Probe
探針 Probe
Kubernetes 為了能更細致地監控 Pod 的狀態,除了保證崩潰重啟,還必須要能夠探查到 Pod 的內部運行狀態,定時給應用做“體檢”,讓應用時刻保持“健康”,能夠滿負荷穩定工作。
Kubernetes 在應用的“檢查口”里提取點數據,就可以從這些信息來判斷應用是否“健康”了,這項功能被稱為“探針”(Probe),也可以叫“探測器”。
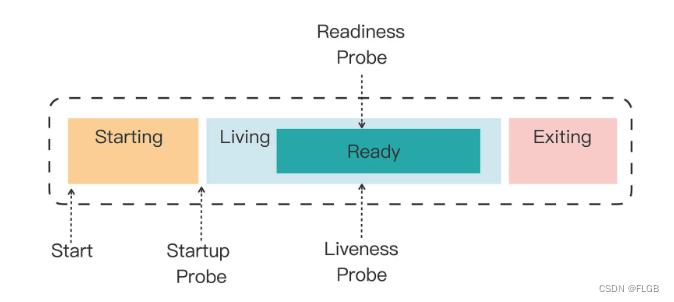
探針類型:
- Startup,啟動探針,用來檢查應用是否已經啟動成功,適合那些有大量初始化工作要做,啟動很慢的應用。
- Liveness,存活探針,用來檢查應用是否正常運行,是否存在死鎖、死循環。
- Readiness,就緒探針,用來檢查應用是否可以接收流量,是否能夠對外提供服務。
三種探針的遞進關系:
- 應用程序先啟動,加載完配置文件等基本的初始化數據就進入了 Startup 狀態
- 之后如果沒有什么異常就是 Liveness 存活狀態,但可能有一些準備工作沒有完成,還不一定能對外提供服務
- 只有到最后的 Readiness 狀態才是一個容器最健康可用的狀態。
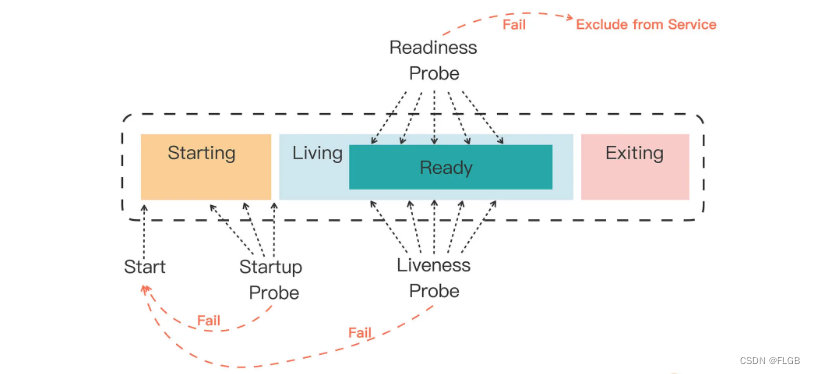
如果一個 Pod 里的容器配置了探針,Kubernetes 在啟動容器后就會不斷地調用探針來檢查容器的狀態:
- 如果 Startup 探針失敗,Kubernetes 會認為容器沒有正常啟動,就會嘗試反復重啟,當然其后面的 Liveness 探針和 Readiness 探針也不會啟動。
- 如果 Liveness 探針失敗,Kubernetes 就會認為容器發生了異常,也會重啟容器。
- 如果 Readiness 探針失敗,Kubernetes 會認為容器雖然在運行,但內部有錯誤,不能正常提供服務,就會把容器從 Service 對象的負載均衡集合中排除,不會給它分配流量。
容器中使用狀態探針
開發應用時預留出“檢查口
nginx-config-cm.yml
apiVersion: v1
kind: ConfigMap
metadata:name: ngx-confdata:default.conf: |server {listen 80;location = /ready {return 200 'I am ready';}}
執行命令
vim nginx-config-cm.yml
kubectl apply -f nginx-config-cm.yml
Pod 定義探針:
ngx-pod-probe.yml
apiVersion: v1
kind: Pod
metadata:name: ngx-pod-probespec:volumes:- name: ngx-conf-volconfigMap:name: ngx-confcontainers:- image: nginx:alpinename: ngxports:- containerPort: 80volumeMounts:- mountPath: /etc/nginx/conf.dname: ngx-conf-volstartupProbe:periodSeconds: 1exec:command: ["cat", "/var/run/nginx.pid"]livenessProbe:periodSeconds: 10tcpSocket:port: 80readinessProbe:periodSeconds: 5httpGet:path: /readyport: 80
startupProbe、livenessProbe、readinessProbe 這三種探針的配置方式都是一樣的,關鍵字段:
- periodSeconds,執行探測動作的時間間隔,默認是 10 秒探測一次。
- timeoutSeconds,探測動作的超時時間,如果超時就認為探測失敗,默認是 1 秒。
- successThreshold,連續幾次探測成功才認為是正常,對于 startupProbe 和 livenessProbe 來說它只能是 1。
- failureThreshold,連續探測失敗幾次才認為是真正發生了異常,默認是 3 次。
Kubernetes 支持 3 種探測方式:Shell、TCP Socket、HTTP GET ,它們也需要在探針里配置:
- exec,執行一個 Linux 命令,比如 ps、cat 等等,和 container 的 command 字段很類似。
- tcpSocket,使用 TCP 協議嘗試連接容器的指定端口。
- httpGet,連接端口并發送 HTTP GET 請求。
ngx-pod-probe.yml配置解析
- StartupProbe 使用了 Shell 方式,使用 cat 命令檢查 Nginx 存在磁盤上的進程號文件(/var/run/nginx.pid),如果存在就認為是啟動成功,它的執行頻率是每秒探測一次。
- LivenessProbe 使用了 TCP Socket 方式,嘗試連接 Nginx 的 80 端口,每 10 秒探測一次。
- ReadinessProbe 使用的是 HTTP GET 方式,訪問容器的 /ready 路徑,每 5 秒發一次請求。
執行命令
vim ngx-pod-probe.yml
kubectl apply -f ngx-pod-probe.yml
kubectl get pod
kubectl logs ngx-pod-probe
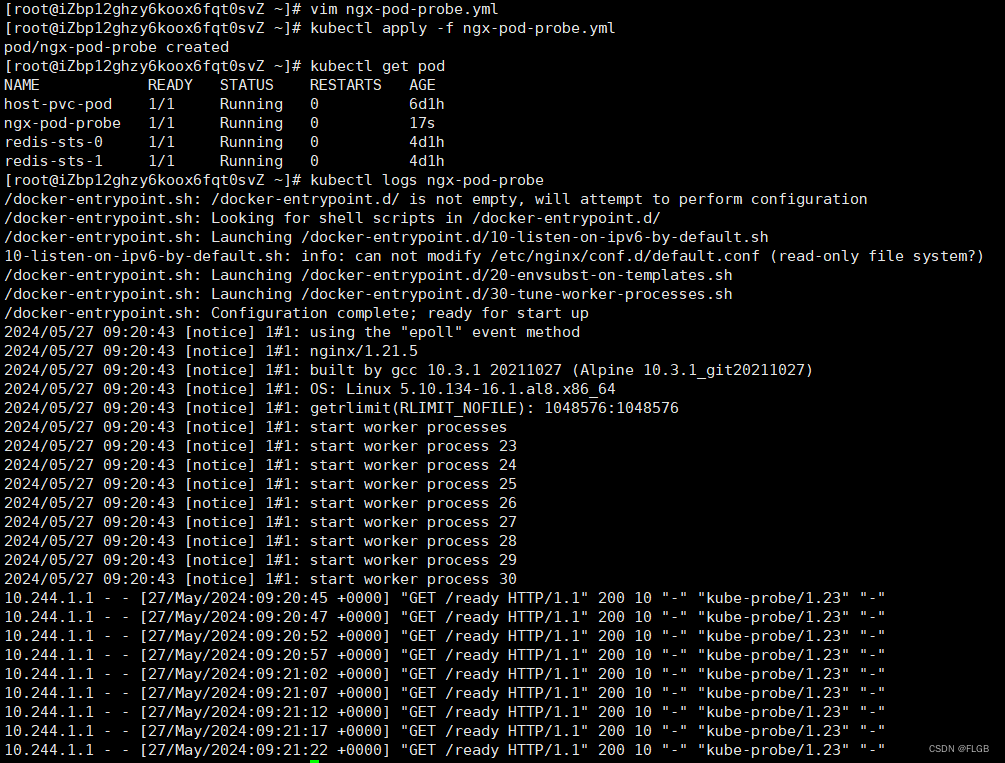
Kubernetes ReadinessProbe 探針以大約 5 秒一次的頻率,向 URI /ready 發送 HTTP 請求,不斷地檢查容器是否處于就緒狀態。
驗證StartupProbe 探針失敗情況
修改ngx-pod-probe.yml的startupProbe
startupProbe:exec:command: ["cat", "nginx.pid"] #錯誤的文件執行命令
kubectl delete -f ngx-pod-probe.yml
kubectl get pod
vim ngx-pod-probe.yml
kubectl apply -f ngx-pod-probe.yml
kubectl get pod
kubectl logs ngx-pod-probe 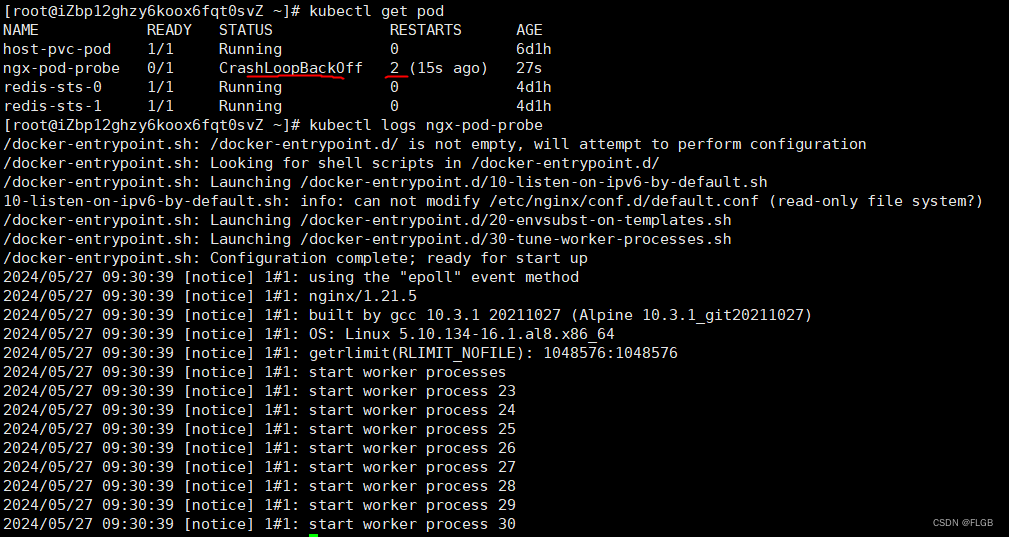
當 StartupProbe 探測失敗的時候,Kubernetes 就會不停地重啟容器,現象就是 RESTARTS 次數不停地增加,而 livenessProbe 和 readinessProbePod 沒有執行,Pod 永遠不會 READY。
修改ngx-pod-probe.yml的livenessProbe(startupProbe內容要還原)
livenessProbe:tcpSocket:port: 8080 #錯誤的端口號
執行命令
kubectl delete -f ngx-pod-probe.yml
kubectl get pod
vim ngx-pod-probe.yml
kubectl apply -f ngx-pod-probe.yml
kubectl get pod
kubectl logs ngx-pod-probe 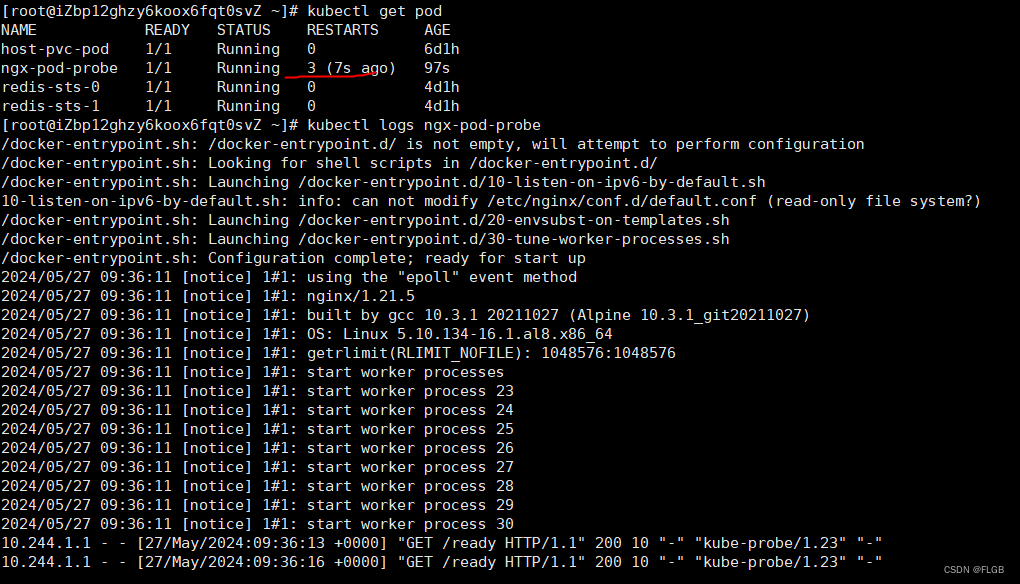
因為 failureThreshold 的次數默認是三次,所以 Kubernetes 會連續執行三次 livenessProbe TCP Socket 探測,每次間隔 10 秒,30 秒之后都失敗才重啟容器。









)






)


