一 用例生成實踐效果
在組內的日常工作安排中,持續優化測試技術、提高測試效率始終是重點任務。近期,我們在探索實踐使用大模型生成測試用例,期望能夠借助其強大的自然語言處理能力,自動化地生成更全面和高質量的測試用例。
當前,公司已經普及使用JoyCoder,我們可以拷貝相關需求及設計文檔的信息給到JoyCoder,讓其生成測試用例,但在使用過程中有以下痛點:
1)仍需要多步人工操作:如復制粘貼文檔,編寫提示詞,拷貝結果,保存用例等
2)響應時間久,結果不穩定:當需求或設計文檔內容較大時,提示詞太長或超出token限制
因此,我探索了基于Langchain與公司的提供的網關接口使測試用例可以自動、快速、穩定生成的方法,效果如下:
| 用例生成效果對比 | 使用JoyCoder(GPT4) | 基于Langchain自研(GPT4) |
|---|---|---|
| 生成時長 (針對項目--文檔內容較多) | ·10~20分鐘左右,需要多次人工操作 (先會有一個提示:根據您提供的需求文檔,下面是一個Markdown格式的測試用例示例。由于文檔內容比較多,我將提供一個概括性的測試用例模板,您可以根據實際需求進一步細化每個步驟。) ·內容太多時,報錯:The maximum default token limit has been reached、UNKNOWN ERROR:Request timed out. This may be due to the server being overloaded,需要人工嘗試輸入多少內容合適 | ·5分鐘左右自動生成 (通過摘要生成全部測試點后,再通過向量搜索的方式生成需要細化的用例) ·內容太多時,可根據token文本切割后再提供給大模型 |
| 生成時長 (針對普通小需求) | 差別不大,1~5分鐘 | |
| 準確度 | 依賴提示詞內容,差別不大,但自研時更方便給優化好的提示詞固化下來 | |
(什么是LangChain? 它是一個開源框架,用于構建基于大型語言模型(LLM)的應用程序。LLM 是基于大量數據預先訓練的大型深度學習模型,可以生成對用戶查詢的響應,例如回答問題或根據基于文本的提示創建圖像。LangChain 提供各種工具和抽象,以提高模型生成的信息的定制性、準確性和相關性。例如,開發人員可以使用 LangChain 組件來構建新的提示鏈或自定義現有模板。LangChain 還包括一些組件,可讓 LLM 無需重新訓練即可訪問新的數據集。)
二 細節介紹
1 基于Langchain的測試用例生成方案
| 方案 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 方案1:將全部產品需求和研發設計文檔給到大模型,自動生成用例 | 用例內容相對準確 | 不支持特大文檔,容易超出token限制 | 普通規模的需求及設計 |
| 方案2:將全部產品需求和研發設計文檔進行摘要后,將摘要信息給到大模型,自動生成用例 | 進行摘要后無需擔心token問題 | 用例內容不準確,大部分都只能是概況性的點 | 特大規模的需求及設計 |
| 方案3:將全部產品需求和研發設計文檔存入向量數據庫,通過搜索相似內容,自動生成某一部分的測試用例 | 用例內容更聚焦 無需擔心token問題 | 不是全面的用例 | 僅對需求及設計中的某一部分進行用例生成 |
因3種方案使用場景不同,優缺點也可互補,故當前我將3種方式都實現了,提供大家按需調用。
2 實現細節
2.1 整體流程

2.2 技術細節說明
?pdf內容解析: :Langchain支持多種文件格式的解析,如csv、json、html、pdf等,而pdf又有很多不同的庫可以使用,本次我選擇PyMuPDF,它以功能全面且處理速度快為優勢
?文件切割處理:為了防止一次傳入內容過多,容易導致大模型響應時間久或超出token限制,利用Langchain的文本切割器,將文件分為各個小文本的列表形式
?Memory的使用:大多數 LLM 模型都有一個會話接口,當我們使用接口調用大模型能力時,每一次的調用都是新的一次會話。如果我們想和大模型進行多輪的對話,而不必每次重復之前的上下文時,就需要一個Memory來記憶我們之前的對話內容。Memory就是這樣的一個模塊,來幫助開發者可以快速的構建自己的應用“記憶”。本次我使用Langchain的ConversationBufferMemory與ConversationSummaryBufferMemory來實現,將需求文檔和設計文檔內容直接存入Memory,可減少與大模型問答的次數(減少大模型網關調用次數),提高整體用例文件生成的速度。ConversationSummaryBufferMemory主要是用在提取“摘要”信息的部分,它可以將將需求文檔和設計文檔內容進行歸納性總結后,再傳給大模型
?向量數據庫:利用公司已有的向量數據庫測試環境Vearch,將文件存入。 在創建數據表時,需要了解向量數據庫的檢索模型及其對應的參數,目前支持六種類型,IVFPQ,HNSW,GPU,IVFFLAT,BINARYIVF,FLAT(詳細區別和參數可點此鏈接),目前我選擇了較為基礎的IVFFLAT--基于量化的索引,后續如果數據量太大或者需要處理圖數據時再優化。另外Langchain也有很方便的vearch存儲和查詢的方法可以使用
2.3 代碼框架及部分代碼展示
代碼框架:
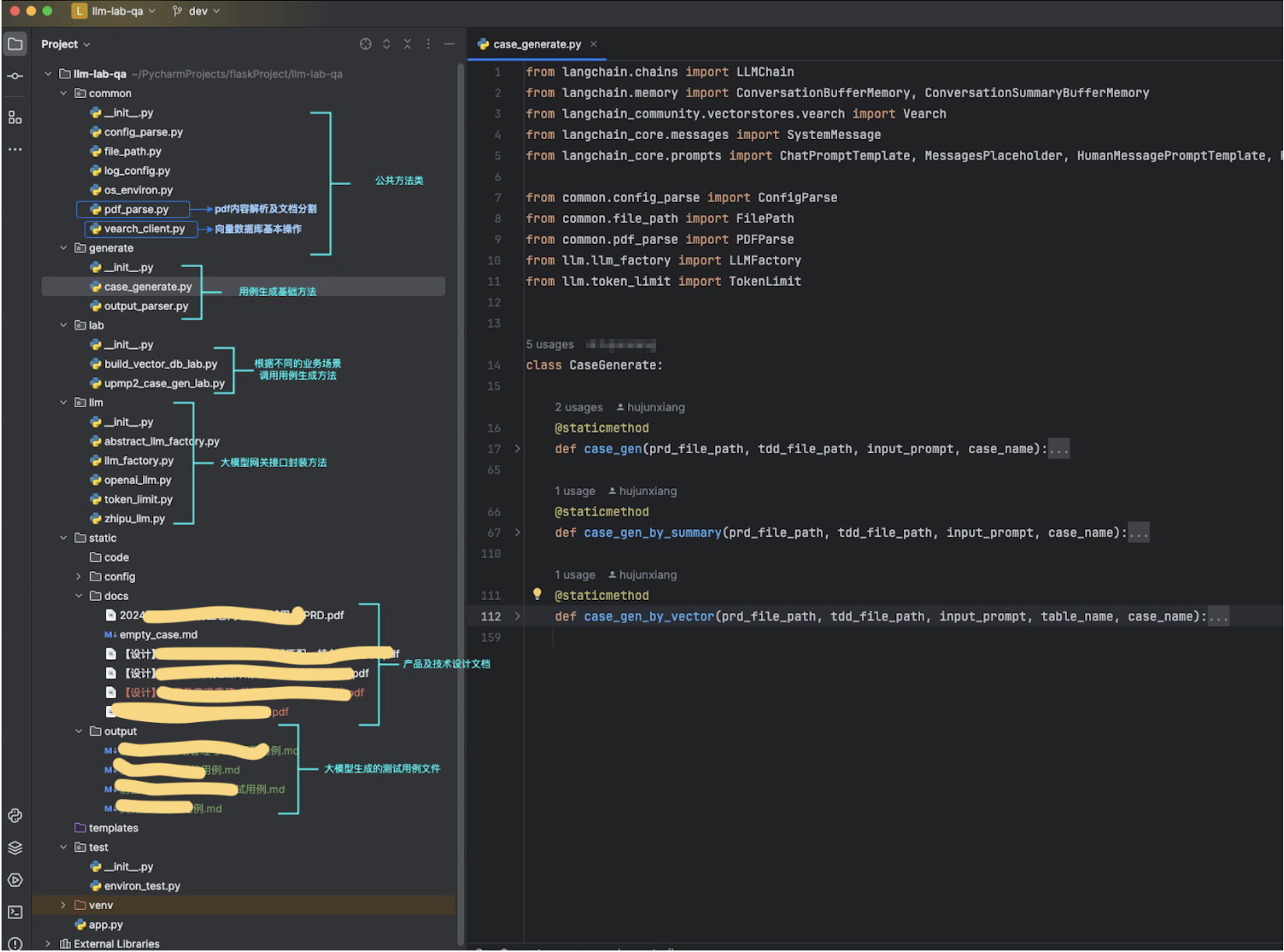
代碼示例:
def case_gen(prd_file_path, tdd_file_path, input_prompt, case_name):"""用例生成的方法參數:prd_file_path - prd文檔路徑tdd_file_path - 技術設計文檔路徑case_name - 待生成的測試用例名稱"""# 解析需求、設計相關文檔, 輸出的是document列表prd_file = PDFParse(prd_file_path).load_pymupdf_split()tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()empty_case = FilePath.read_file(FilePath.empty_case)# 將需求、設計相關文檔設置給memory作為llm的記憶信息prompt = ChatPromptTemplate.from_messages([SystemMessage(content="You are a chatbot having a conversation with a human."), # The persistent system promptMessagesPlaceholder(variable_name="chat_history"), # Where the memory will be stored.HumanMessagePromptTemplate.from_template("{human_input}"), # Where the human input will injected])memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)for prd in prd_file:memory.save_context({"input": prd.page_content}, {"output": "這是一段需求文檔,后續輸出測試用例需要"})for tdd in tdd_file:memory.save_context({"input": tdd.page_content}, {"output": "這是一段技術設計文檔,后續輸出測試用例需要"})# 調大模型生成測試用例llm = LLMFactory.get_openai_factory().get_chat_llm()human_input = "作為軟件測試開發專家,請根據以上的產品需求及技術設計信息," + input_prompt + ",以markdown格式輸出測試用例,用例模版是" + empty_casechain = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory,)output_raw = chain.invoke({'human_input': human_input})# 保存輸出的用例內容,markdown格式file_path = FilePath.out_file + case_name + ".md"with open(file_path, 'w') as file:file.write(output_raw.get('text')) def case_gen_by_vector(prd_file_path, tdd_file_path, input_prompt, table_name, case_name):"""!!!當文本超級大時,防止token不夠,通過向量數據庫,搜出某一部分的內容,生成局部的測試用例,細節更準確一些!!!參數:prd_file_path - prd文檔路徑tdd_file_path - 技術設計文檔路徑table_name - 向量數據庫的表名,分業務存儲,一般使用業務英文唯一標識的簡稱case_name - 待生成的測試用例名稱"""# 解析需求、設計相關文檔, 輸出的是document列表prd_file = PDFParse(prd_file_path).load_pymupdf_split()tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()empty_case = FilePath.read_file(FilePath.empty_case)# 把文檔存入向量數據庫docs = prd_file + tdd_fileembedding_model = LLMFactory.get_openai_factory().get_embedding()router_url = ConfigParse(FilePath.config_file_path).get_vearch_router_server()vearch_cluster = Vearch.from_documents(docs,embedding_model,path_or_url=router_url,db_name="y_test_qa",table_name=table_name,flag=1,)# 從向量數據庫搜索相關內容docs = vearch_cluster.similarity_search(query=input_prompt, k=1)content = docs[0].page_content# 使用向量查詢的相關信息給大模型生成用例prompt_template = "作為軟件測試開發專家,請根據產品需求技術設計中{input_prompt}的相關信息:{content},以markdown格式輸出測試用例,用例模版是:{empty_case}"prompt = PromptTemplate(input_variables=["input_prompt", "content", "empty_case"],template=prompt_template)llm = LLMFactory.get_openai_factory().get_chat_llm()chain = LLMChain(llm=llm,prompt=prompt,verbose=True)output_raw = chain.invoke({'input_prompt': input_prompt, 'content': content, 'empty_case': empty_case})# 保存輸出的用例內容,markdown格式file_path = FilePath.out_file + case_name + ".md"with open(file_path, 'w') as file:file.write(output_raw.get('text'))
三 效果展示
3.1 實際運用到需求/項目的效果
用例生成后是否真的能幫助我們節省用例設計的時間,是大家重點關注的,因此我隨機在一個小型需求中進行了實驗,此需求的PRD文檔總字數2363,設計文檔總字數158(因大部分是流程圖),結果如下:
| 用例設計環節,測試時間(人日)占用效果分析 | 可自動生成用例之前 | 可自動生成用例之后 |
|---|---|---|
| 分析需求&理解技術設計 | 0.5 | 0.25 |
| 與產研確認細節 | 0.25 | 0.25 |
| 設計及編寫用例 | 1(39例) | 0.5(45例=25例自動生成+20例人工修正/補充) |
| 評審及用例差缺補漏 | 0.5 | 0.25 |
| 總計(效率提升50%) | 2.5人日 | 1.25人日 |
本次利用大模型自動生成用例的優缺點:
優勢:
?全面快速的進行了用例的邏輯點劃分,協助測試分析理解需求及設計
?降低編寫測試用例的時間,人工只需要進行內容確認和細節調整
?用例內容更加全面豐富,在用例評審時,待補充的點變少了,且可以有效防止漏測
?如測試人員僅負責一部分功能的測試,也可通過向量數據庫搜索的形式,聚焦部分功能的生成
劣勢:
?暫時沒實現對流程圖的理解,當文本描述較少時,生成內容有偏差
?對于有豐富經驗的測試人員,自動生成用例的思路可能與自己習慣的思路不一致,需要自己再調整或適應
四 待解決問題及后續計劃
1.對于pdf中的流程圖(圖片形式),實現了文字提取識別(langchain pdf相關的方法支持了ocr識別),后續需要找到更適合解決圖內容的解析、檢索的方式。
2.生成用例只是測試提效的一小部分,后續需要嘗試將大模型應用與日常測試過程,目前的想法有針對diff代碼和服務器日志的分析來自動定位缺陷、基于模型驅動測試結合知識圖譜實現的自動化測試等方向。






:異步編程與錯誤處理)








)


)
