首先我們來看看, 存儲自增主鍵和uuid的數據類型
? ? ? ? 我們知道, mysql中作為主鍵的通常是int類型的數據, 這個 數據從第一條記錄開始, 從1開始主鍵往后遞增, 例如我有100條數據, 那么根據主鍵排序后, 里面的記錄從上往下一次就是1, 2, 3 ... 100, 但是UUID就不一樣了, UUID是根據特殊的算法, 來生成唯一的一個字符串, 他的長度高達128個比特位,?而標準的UUID格式為:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12), 每一個x都是?0-9 或?a-f?范圍內的一個十六進制的數字, 因此他需要使用字符串格式來進行存儲, 標準的uuid的長度是32個字符, 外加兩個短線, 也就是34個字符
? ? ? ? 在mysql中對int類型值的處理速度是比字符串的速度要快的, 因此在速度上, 是肯定比不過自增主鍵的, 我們在比較UUID, 然后對這些UUID進行一個排序的, 是一個字符一個字符的進行比較的, 例如有兩個UUID, 那么就是從第一個字符比較, 如果第一個字符相等, 就比較下一個字符的大小, 以此類推, 直到比較完了, 那么兩個字符串就想等, 如果存在字符的大小區別, 那么就根據不同的這個字符進行排序, 以此類推.
? ? ? ? 所以你是用UUID進行存儲, 那么相比于自增的主鍵, 那么你就要花費額外的空間來存儲這些UUID, 在插入主鍵或者是uuid的時候, 會有一個插入順序的問題, 對于主鍵, 如果你不指定主鍵的值, 然后給這個主鍵設置自增值, 那么在插入的時候, 就會按照最大主鍵值的下一位插入, 這個時候就會性能很高, 為什么這么說呢??
? ? ? ? 因為mysql底層是一個數據頁為一個基本的讀寫單元, 一個數據頁可以存放16kb的數據, 你可以理解為數據頁里面的記錄是一個鏈表, 假如此時你不是按主鍵自增的順序插入, 并且你插入的主鍵對應的數據頁剛好滿了裝不下了, 此時的話, 你就需要將一個頁拆分為兩頁, 這個就造成了不必要的性能消耗. 如果你按照自增的形式插入, 那么他們就會以此在最后一個數據頁里面插入, 如果不夠了, 就創建新的數據頁, 而不是將一個頁差分為兩個, 然后拷貝數據.? ?
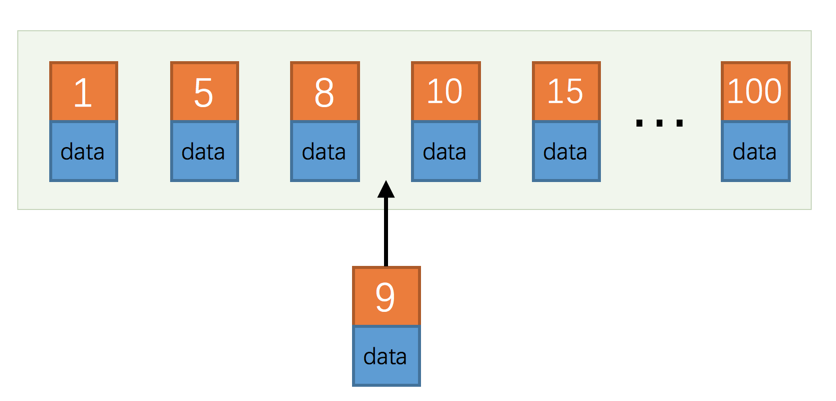
? ? ? ? ?但是如果你是使用的UUID作為主鍵, 那么就沒有這個功能, 你的字符串id是有序的, 但是你不能保證, 你下一個生成的uuid, 就一定是最大的, 因此被分頁的可能性就會很高. 同時每一個主鍵的占用的空間大了, 那么一個數據頁裝的數據記錄也會變少, 頁面增多, 所以在對這些記錄進行操作, 將數據頁讀取到內存中的時候, 讀取的頁數頁隨之增多. io成本隨之增多.
? ? ? ? 在存儲和性能方面, 還是自增主鍵更勝一籌.
說了這么多仿佛都是UUID的缺點, 那UUID做主鍵就么沒有有點嗎?
? ? ? ? 有點肯定是有的?, 例如UUID的長度很長, 并且是隨機生成的, 他的主鍵的復雜性很高, 并且沒有規律, 你不能夠通過數據分析來預測下一個主鍵id是多少,這種不可預測性對于需要保密性的應用場景較為適用。
? ? ? ? 還有另外一種場景, 假如現在有這樣一個需求, 我需要將一個自增主鍵的表, 導入另外一個和當前表結構相同的表, 但是這個表已經存了很多數據, 這個時候我將其插入, 就會導入失敗, 因為兩個表前面幾部分的id是重合的, 因此會插入失敗. 同樣的當你去拆分數據庫的時候, 也可以很好的拆分, 并且避免id的重復導致數據的錯亂.
? ? ? ? 此時如果你使用的是UUID, 那么就可以避免這個問題.
總結:?
在MySQL中,使用自增主鍵(AUTO_INCREMENT)和UUID作為主鍵的主要區別體現在以下幾個方面:
- 唯一性:
- 自增主鍵:確保主鍵的唯一性,每次插入新行時,數據庫會自動為主鍵生成一個唯一的、比之前插入的最大主鍵值大1的整數值。
- UUID:具有極高的唯一性,基于一定算法(如隨機數生成器或時間戳)生成,幾乎不可能重復。UUID由32位16進制數表示,共128位(標準的UUID格式為:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)。
- 數據類型和存儲:
- 自增主鍵:只適用于整數類型的主鍵列(如INT、BIGINT等),存儲空間相對較小。
- UUID:雖然也是字符串類型,但由于其長度較長(32個字符),存儲空間相對較大。
- 插入性能:
- 自增主鍵:在插入新行時,數據庫可以很容易地將新行插入到索引的末尾,減少了頁分裂或移動數據的頻率,從而提高了插入性能。
- UUID:由于UUID是隨機生成的,插入時位置具有不確定性,可能導致無序插入和內存碎片,插入性能相對較差。
- 索引和查詢性能:
- 自增主鍵:由于其遞增的特性,非常適合用作聚集索引(Clustered Index),能夠優化查詢性能。同時,較小的索引大小也可以減少內存消耗,更好地適應于內存緩存。
- UUID:由于UUID的無序性,可能導致索引碎片化,影響查詢性能。同時,較大的索引大小也可能增加內存消耗。
- 可預測性:
- 自增主鍵:主鍵值是可預測的,因為它們是按順序生成的。
- UUID:主鍵值是不可預測的,因為它們是隨機生成的。這種不可預測性對于需要保密性的應用場景較為適用。
- 刪除和重新插入:
- 自增主鍵:在刪除并重新插入數據后,可能會出現主鍵值“跳躍”的現象,即新插入的主鍵值可能會比之前刪除的主鍵值大很多。
- UUID:UUID在刪除和重新插入數據時,主鍵值不會受到影響,因為它們是隨機生成的。
?????????自增主鍵和UUID在MySQL中各有優缺點,選擇哪種方式作為主鍵取決于具體的應用場景和需求。例如,在需要高性能插入和查詢的場景下,自增主鍵可能更合適;而在需要保證主鍵全局唯一性和不可預測性的場景下,UUID可能更合適。
![打卡信奧刷題(21)用Scratch圖形化工具信奧P7071 [CSP-J2020] 優秀的拆分](http://pic.xiahunao.cn/打卡信奧刷題(21)用Scratch圖形化工具信奧P7071 [CSP-J2020] 優秀的拆分)
)







)





)


)
