 導讀
導讀
目標檢測作為計算機視覺的核心任務之一,其研究已經從基于CNN的架構發展到基于Transformer的架構,如DETR,后者通過簡化流程實現端到端檢測,消除了手工設計的組件。盡管如此,DETR的高計算成本限制了其在實時目標檢測領域的應用。為了解決這一問題,研究人員通過設計高效的編碼器和改進查詢初始化方法,優化了DETR,使其能夠適應實時場景,同時避免了NMS帶來的延遲,推動了目標檢測技術在速度和準確性上的進一步提升。
復雜場景下的檢測能力圖示:

文章目錄
- 摘要
- 一、介紹
- 二、目標檢測器相關工作
- 1.從DETR到實時檢測的創新
- 2.利用多尺度特征提高性能
- 三、端到端速度的優勢
- 1.對NMS的分析
- 2.Anchor-Free檢測其在實時推理中的優勢
- 四、The Real-time DETR
- 1.RT-DETR的結構
- 2.混合編碼器
- 實驗
- 1.與YOLO的比較
- 1.不同模塊的消融研究
摘要
在這項工作中,作者提出了一個名為RT-DETR的實時端到端檢測器,它成功地將DETR擴展到實時檢測場景,并實現了最先進的性能。RT-DETR包括兩個關鍵增強:一個高效的混合編碼器,它可以迅速處理多尺度特征,以及最小化不確定性的查詢選擇,這提高了初始對象查詢的質量。此外,RT-DETR支持靈活的速度調整,無需重新訓練,并消除了由兩個NMS閾值引起的不便,從而促進了其實際應用。RT-DETR及其模型擴展策略拓寬了實時目標檢測的技術方法,為YOLO之外的多樣化實時場景提供了新的可能性。
一、介紹
本文深入分析了現代實時目標檢測器中非極大值抑制(NMS)對推理速度的負面影響,并提出了一種新型的Transformer架構——實時DEtection TRansformer(RT-DETR),它通過簡化目標檢測流程實現了端到端的檢測。盡管如此,DETR的高計算成本問題仍然是其在實際應用中的一個限制。為了克服這一挑戰,文中引入了IoU-Aware查詢選擇器,該方法在訓練階段利用IoU約束來優化解碼器的初始目標查詢,從而提供更高質量的查詢,進一步提升了檢測性能。
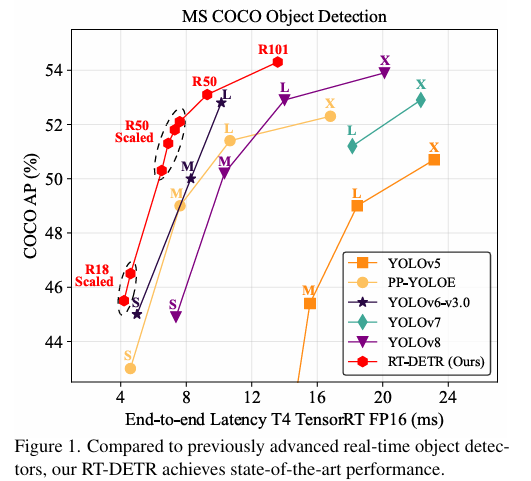
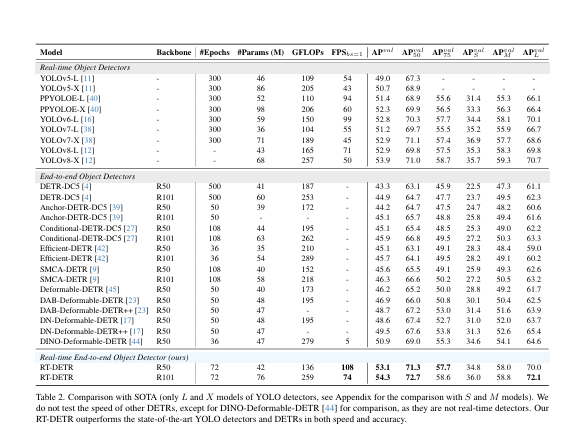
本文提出了一種新型的實時目標檢測框架RT-DETR,旨在解決現有基于Transformer的目標檢測器在計算成本和推理速度上的挑戰。文中展示了RT-DETR-R50和RT-DETR-R101兩種變體的性能:RT-DETR-R50實現了53.1%的平均精度(AP)和108幀每秒(FPS),而更高級的RT-DETR-R101變體則實現了54.3%的AP和74 FPS。特別值得一提的是,RT-DETR-R50在準確度和幀率上均優于DINO-Deformable-DETR-R50,顯示出在實時目標檢測任務中的優勢。這些結果表明,RT-DETR在維持高準確度的同時,還能提供高幀率的檢測,滿足實時處理的需求。
二、目標檢測器相關工作
1.從DETR到實時檢測的創新
端到端目標檢測器DETR(DEtection Transformer)以其簡化的檢測流程而備受關注,它通過二分匹配直接預測對象,避免了傳統檢測的Anchor和NMS組件。但是,DETR仍然存在訓練收斂緩慢和查詢優化難度大的問題。為了解決這些問題,人們提出了很多種DETR變體,比如Deformable DETR和Conditional DERT以及DAB-DETR等等,它們通過不同的方法進行優化效率和查詢。DINO以之前的作品為基礎,不斷完善已經取得了巨大的成果。
2.利用多尺度特征提高性能
現代目標檢測器通過使用多尺度特征,特別是小物體,已經有了顯著的性能提升。FPN(特征金字塔網絡)是實現這一目標的關鍵技術,通過融合不同尺度的特征來構建特征金字塔。而在DERT(DEtection Transformer)中,zhu等人首次引入了多尺度的特征,雖然提高了性能檢測和模型收斂的速度,但是也增加了計算成本。即使后面的Deformable Attention在在一定程度上降低了這一成本,但是高計算成本的問題還是沒有得到解決。
為了應對這些問題。一些研究高效DETR模型的團隊設計了不同的DETR變體,如Efficient DETR通過優化目標查詢的初始化來減少過程中解碼和編碼器的數量,來降低成本。還有Lite DETR通過減少級別特征的更新頻率來提升編碼器效率。
三、端到端速度的優勢
1.對NMS的分析
NMS(非極大值抑制)是一種用于去除重疊預測框的常用后處理技術。它依賴于兩個關鍵的超參數:得分閾值和loU(交并比)閾值。
具體操作中,首先過濾得分低于設定閾值的預測框。然后,對于剩余的預測框,如果倆個框之間的loU超過設定的loU閾值,那么得分低的框會被舍棄。這個過程會一直重復執行直到所有類別的預測框都被執行處理完成。所以NMS執行的時間主要是看,預測框的數量和倆個超參數。
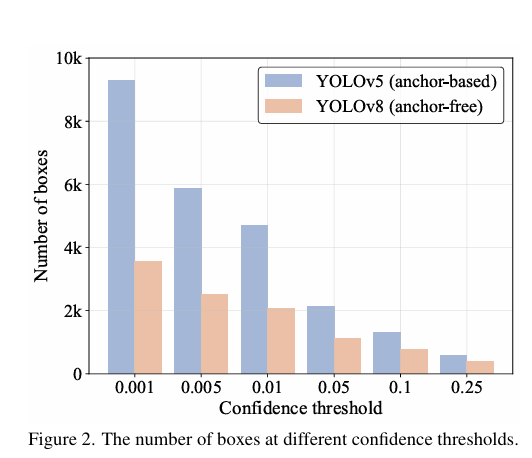
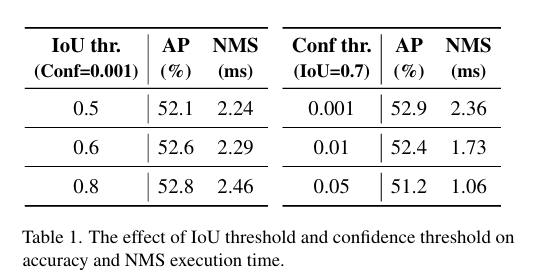
本圖就是通過直方圖的形式展示在相同輸入圖像下不同閾值下剩余的預測框的數量,此外還對YOLOv8進行不同NMS超參數下在COCO val2017的模型的準確性和時間,下圖所示:
2.Anchor-Free檢測其在實時推理中的優勢
作者為了減少外在因素的影響建立了一個端到端的測試基準,并用COCO val2017作為默認數據集,同時也為后處理的實時檢測器添加了TensorRT的NMS后處理插件。
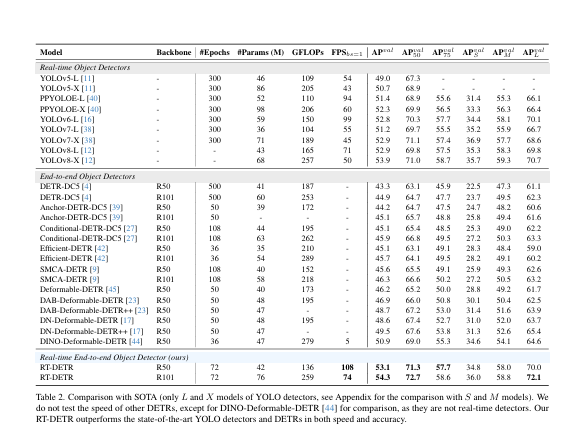
根據數據可以看出來RT-DETR檢測器在精度上要優于YOLO檢測器。而出現這種情況也是因為Anchor-Free檢測器上的預測框比Anchor-Base檢測器多的多。
四、The Real-time DETR
1.RT-DETR的結構
RT-DETR是由混合編碼器和Backbone以及輔助預測頭Transformer解碼器組成。具體如下圖所示:
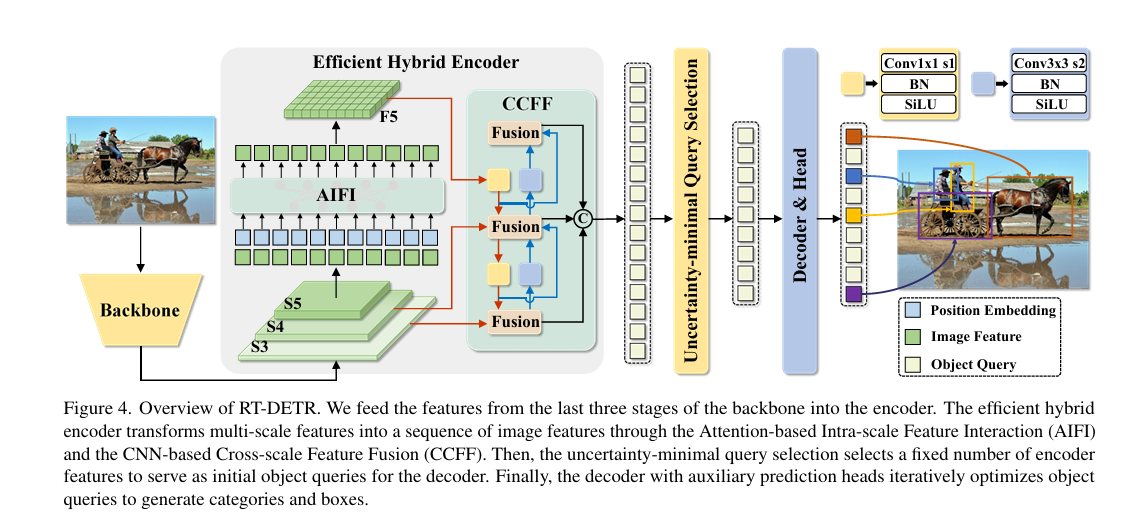
2.混合編碼器
作者等人為了加速訓練收斂并提高性能提出了一種混合高效的混合編碼器,混合編碼器主要是倆個模塊組成,即注意力的尺度內特征交互(AIFI)模塊和神經網絡的尺度特征融合模塊(CCFM)。
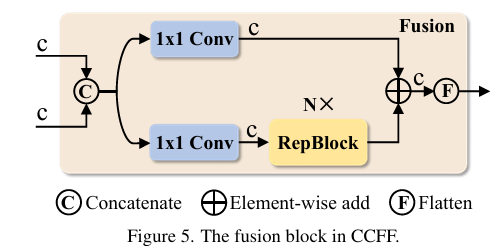
CCFM也基于變體D進行完善,如上圖所示,也可以通過公式表達出來:

然而無論是Effificient detr和Dino以及Deformable detr的查詢方案的哦是以Top-K個特征來初始化查詢,導致探測器的性能削弱。為此作者提出了loU-Aware查詢選擇,它能為不同得分產生不同的分數線,具體的表示如下:

為了證明loU感知查詢的可靠性,進行了如圖所示的實驗:
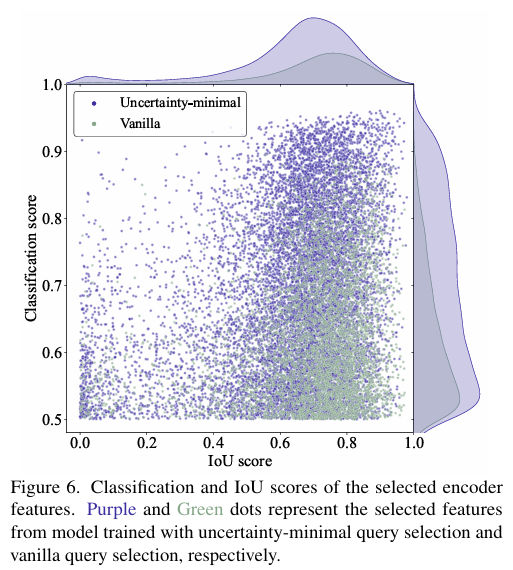
實驗通過可視化和定量分析表明,使用IoU感知查詢選擇訓練的模型(藍色點)在生成高質量編碼器特征方面優于普通查詢選擇訓練的模型(紅色點),這體現在藍色點在散點圖右上角的集中分布,以及在分類得分和IoU得分大于0.5時,藍色點數量顯著多于紅色點,分別高出138%和120%。進而表示loU感知查詢選擇可以為對象查詢提供更多具有準確分類和精確定位的編碼器特征,從而提高檢測器的準確性。
源碼鏈接:hybrid_encoder
@register
@serializable
class HybridEncoder(nn.Layer):__shared__ = ['depth_mult', 'act', 'trt', 'eval_size']__inject__ = ['encoder_layer']#初始化定義def __init__(self,in_channels=[512, 1024, 2048],feat_strides=[8, 16, 32],hidden_dim=256,use_encoder_idx=[2],num_encoder_layers=1,encoder_layer='TransformerLayer',pe_temperature=10000,expansion=1.0,depth_mult=1.0,act='silu',trt=False,eval_size=None):super(HybridEncoder, self).__init__()self.in_channels = in_channelsself.feat_strides = feat_stridesself.hidden_dim = hidden_dimself.use_encoder_idx = use_encoder_idxself.num_encoder_layers = num_encoder_layersself.pe_temperature = pe_temperatureself.eval_size = eval_size# channel projectionself.input_proj = nn.LayerList()for in_channel in in_channels:self.input_proj.append(nn.Sequential(nn.Conv2D(in_channel, hidden_dim, kernel_size=1, bias_attr=False),nn.BatchNorm2D(hidden_dim,weight_attr=ParamAttr(regularizer=L2Decay(0.0)),bias_attr=ParamAttr(regularizer=L2Decay(0.0)))))# encoder transformerself.encoder = nn.LayerList([TransformerEncoder(encoder_layer, num_encoder_layers)for _ in range(len(use_encoder_idx))])act = get_act_fn(act, trt=trt) if act is None or isinstance(act,(str, dict)) else act# top-down fpnself.lateral_convs = nn.LayerList()self.fpn_blocks = nn.LayerList()for idx in range(len(in_channels) - 1, 0, -1):self.lateral_convs.append(BaseConv(hidden_dim, hidden_dim, 1, 1, act=act))self.fpn_blocks.append(CSPRepLayer(hidden_dim * 2,hidden_dim,round(3 * depth_mult),act=act,expansion=expansion))# bottom-up panself.downsample_convs = nn.LayerList()self.pan_blocks = nn.LayerList()for idx in range(len(in_channels) - 1):self.downsample_convs.append(BaseConv(hidden_dim, hidden_dim, 3, stride=2, act=act))self.pan_blocks.append(CSPRepLayer(hidden_dim * 2,hidden_dim,round(3 * depth_mult),act=act,expansion=expansion))self._reset_parameters()def _reset_parameters(self):if self.eval_size:for idx in self.use_encoder_idx:stride = self.feat_strides[idx]pos_embed = self.build_2d_sincos_position_embedding(self.eval_size[1] // stride, self.eval_size[0] // stride,self.hidden_dim, self.pe_temperature)setattr(self, f'pos_embed{idx}', pos_embed)#添加位置信息;@staticmethoddef build_2d_sincos_position_embedding(w,h,embed_dim=256,temperature=10000.):grid_w = paddle.arange(int(w), dtype=paddle.float32)grid_h = paddle.arange(int(h), dtype=paddle.float32)grid_w, grid_h = paddle.meshgrid(grid_w, grid_h)assert embed_dim % 4 == 0, \'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'pos_dim = embed_dim // 4omega = paddle.arange(pos_dim, dtype=paddle.float32) / pos_dimomega = 1. / (temperature**omega)out_w = grid_w.flatten()[..., None] @omega[None]out_h = grid_h.flatten()[..., None] @omega[None]return paddle.concat([paddle.sin(out_w), paddle.cos(out_w), paddle.sin(out_h),paddle.cos(out_h)],axis=1)[None, :, :]def forward(self, feats, for_mot=False, is_teacher=False):assert len(feats) == len(self.in_channels)# get projection featuresproj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)]# encoderif self.num_encoder_layers > 0:for i, enc_ind in enumerate(self.use_encoder_idx):h, w = proj_feats[enc_ind].shape[2:]# flatten [B, C, H, W] to [B, HxW, C]src_flatten = proj_feats[enc_ind].flatten(2).transpose([0, 2, 1])if self.training or self.eval_size is None or is_teacher:pos_embed = self.build_2d_sincos_position_embedding(w, h, self.hidden_dim, self.pe_temperature)else:pos_embed = getattr(self, f'pos_embed{enc_ind}', None)memory = self.encoder[i](src_flatten, pos_embed=pos_embed)proj_feats[enc_ind] = memory.transpose([0, 2, 1]).reshape([-1, self.hidden_dim, h, w])# top-down fpninner_outs = [proj_feats[-1]]for idx in range(len(self.in_channels) - 1, 0, -1):feat_heigh = inner_outs[0]feat_low = proj_feats[idx - 1]feat_heigh = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_heigh)inner_outs[0] = feat_heighupsample_feat = F.interpolate(feat_heigh, scale_factor=2., mode="nearest")inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](paddle.concat([upsample_feat, feat_low], axis=1))inner_outs.insert(0, inner_out)# bottom-up panouts = [inner_outs[0]]for idx in range(len(self.in_channels) - 1):feat_low = outs[-1]feat_height = inner_outs[idx + 1]downsample_feat = self.downsample_convs[idx](feat_low)out = self.pan_blocks[idx](paddle.concat([downsample_feat, feat_height], axis=1))outs.append(out)return outs@classmethoddef from_config(cls, cfg, input_shape):return {'in_channels': [i.channels for i in input_shape],'feat_strides': [i.stride for i in input_shape]}@propertydef out_shape(self):return [ShapeSpec(channels=self.hidden_dim, stride=self.feat_strides[idx])for idx in range(len(self.in_channels))]
實驗
1.與YOLO的比較
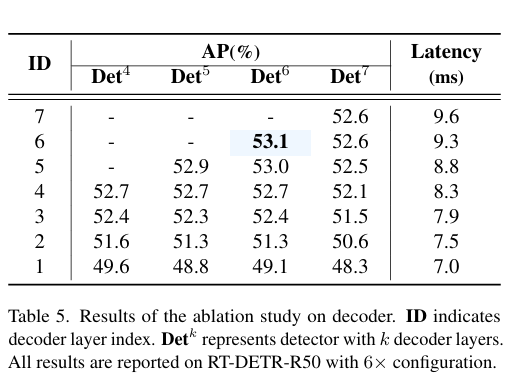
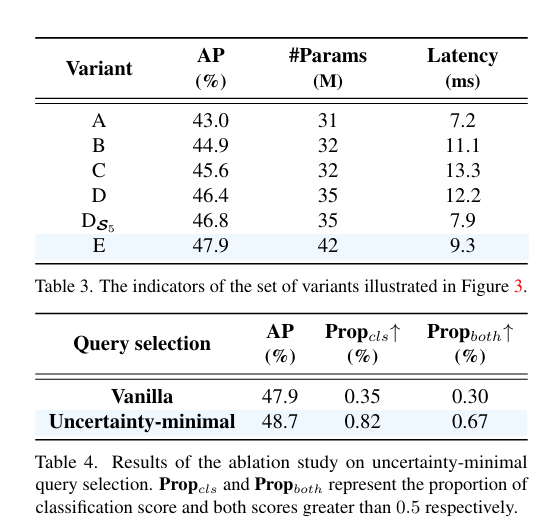
1.不同模塊的消融研究


)









)


)



)