引言
????????關于chatGPT的Prompt Engineer,大家肯定耳朵都聽起繭了。但是它的來由?,怎么能用好?很多人可能并不覺得并不是一個問題,或者說認定是一個很快會過時的概念。但其實也不能說得非常清楚(因為覺得沒必要深究)。但我覺得,它畢竟存在過,火過,我們還是必須對它有更深入的理解,所以,我花時間認真了解了一下。
????????對于提示詞的理解,我也是經歷過好幾個階段。
? ? ? ? 最初,我第一次聽說什么提示詞工程,認為是chatGPT的缺陷所致,也就是GPT不夠聰明,提示詞是為了讓我們遷就它,繞開它的一些不足。但仔細一看,發現不對,大多數提示詞的技巧,實際上就是對人與人進行良好溝通的要求,并不過分,不能認為是GPT的缺陷。
? ? ? ? 于是,我開始關注提示詞的細節和原理,但始終是記不住,感覺無非就是要學會說人話,要和人好好溝通,要能理解你想問領域的基礎知識,似乎并沒啥可學的,也就沒關注了。
? ? ? ? 后來,Agent開始火熱,開始了解Agent,才發現,原來提示詞在這里有用,因為基于GPT編程,實際上很多時候是在使用提示詞。那就不能象在chat里那么隨意了,需要固化下來,抽象出模板,而且要關注這里提示詞在不同版本的準確度。可以理解,提示詞就是在編程序,只是在使用自然語言編程。
? ? ? ? 講到這里,容我打一下岔。我們一定要來說說人與計算機如何交互的問題:
? ? ? ? 人與計算機交互的方式,也就是人給計算機派任務。經歷了幾個階段,因為計算機本質是在處理0/1數據,處理計算任務。最早,我們可以認為計算機比較蠢,人自然就要多做一些事情,就像你的鄰家小孩很笨溝通起來很困難,你就得牽就他。所以,人需要寫晦澀的匯編指令(甚至用過打孔紙帶),沒辦法,誰讓它那么笨。但慢慢的,機器變得越來越聰明,人就開始使用C語言,C++語言,然后是 Java語言,到現在,最流行的Python,與計算機的交互變得越來越簡單,我們可以理解為計算機變聰明了,對于人的要求,不斷在后退,計算機理解能力提升,不斷在前進。
? ? ? ? 直到今天,GPT的出現,人可能再退一步,使用自然語言來和計算機交流。這可是人類倒退的一小步,計算機進步的一大步。我們在使用Prompt的時候,發現使用自然語言就可以讓計算機完成任務。所以,你不得不重視提示詞,它不僅僅是用來聊天的輸入,是未來與AI交流的第一語言(當然,也可能會被工程化,變成GPT的內置功能,但至少目前沒有)
? ? ? ? 我不知道有沒有引起大家的好奇。鋪墊就說這么多了。
Prompt 的產生
????????對于大模型的技術,有一種四階的說法,提示詞工程應該屬于最上層的,應用層技術,面向的人群是所有終端用戶,門檻最低,最易于上手。

? ? ? ? 我們今天的重點是講提示詞工程,也就是Prompt。
? 簡單來說,Prompt就是我們與大模型之間的溝通話術。
? ? ? ? 我們以前經常會接觸一些職場溝通,銷售話術,和大模型一起工作,就象人與人配合工作一樣,需要有很好的溝通技巧。好了,言歸正傳,我們說說Prompt的來源。
? ? ? ? 那Promtpt是如何產生的呢?我們必須從GPT的歷史說起。
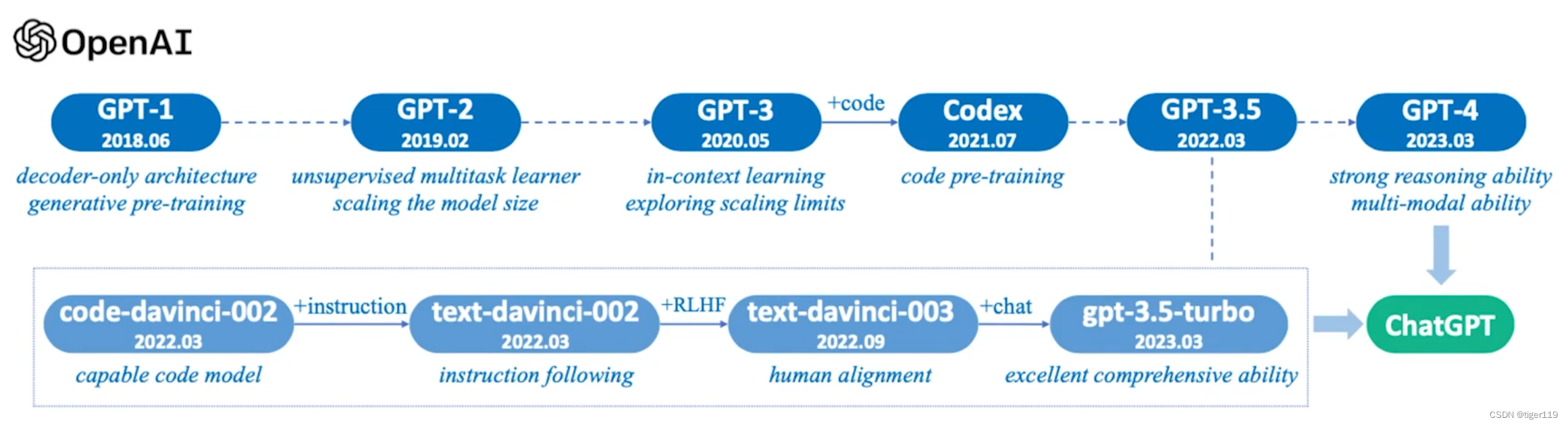
? ? ? ? 我們來看看GPT的歷史:
? ? ? ? 1.0 時代:在Goolge發明Transformer之后,開始大力發展BERT,OpenAI 的同學覺得Transformer挺好的,把Transformer改了改,用了解碼器的生成式架構,改成了可以純并發的架構,并且采用無監督的方法(省了標注),使用了約50G數據(7000本書),通過預訓練 + 專業數據fine-tune的方式,生成一個 1 億參數的模型,效果還行,在特定的測試集上獲得一定的結果。方法嘛 ,那是相當的簡單粗暴。但產生一個重要理論范式:PreTrain + Fine-tune 的模式。這個時候,并沒有什么人關注GPT。那時是BERT的天下。

? ? ? ? 2.0 時代:繼續擴大參數,擴到15億(12倍相對于GPT-1),預訓練使用了更多的數據。將Fine-tune的量減少,爭取一次搞定預訓練和微調,變成一個階段。PreTrain做更多的事情。無監督學習,增加掩碼語言模型(增強自監督)。這仍然是一個暴力美學,但效果確實得到很大增強,相應的范式發生變化,PreTrain做了更多的事情,基礎模型的能力大大增強。
In-context learning的產生
? ? ? ? 到了3.0:增加更多的數據(4100億tokens),模型參數量更大(1700億參數,相對于GPT-2大了100倍),這時就有問題了,如果要傳統的fine-tune,成本會太高。因此,這時候出現了 In-Context learning ,讓模型能夠在上下文中學習,其實就是把問題前移,要求提問的人把問題問得更清楚,并且給出一些解答問題的示例 。這樣,可以讓大模型針對上下文進行推理,做到在不改變預訓練模型的情況下,通過增強輸入,達到最好的結果。
? ??????這和提示詞有啥關系?當然有關系,這實際上就是提示詞一個原理,就是提示詞的前身,這是一個很簡單的道理,一點不深奧,仍然是敵退我進的方法,鄰家傻兒子能力不強,咋辦呢,我把問題講清楚一點。它減少了對fine-tune的依賴,支持對上下文的推理,但要求對方把上下文給清楚,甚至給出示例 ,然后根據模型的常識能力,直接獲得答案。對于in-context learning有三類:
? ? ? ? 1:Zero shot? 不給示例 ,給明確的指示
? ? ? ? 2: One-shot? 給一個示例?
? ? ? ? 3: Few-shot 給小于10個以內的多個案例

? ? ? ? 上圖可以看出,參考示例越多,效果越好。模型越大,效果越好。
? ? ? ?再回顧一下,GPT的發展過程如下:
即然 In-Context learning的效果這么好,那我們提問者是不是可以更進一步呢?
Prompt 實際上是在In-context learning的基礎上更進一步
?In-Context Learing:提供參考示例的學習方式。
?Prompt-Learning 是在 in-context learning的基礎上更進一步,利用好上下文來影響模型的輸出。
????????兩者的區別是:Prompt Learning 是設計好的提示來引導更好的輸出。而 in-context learning則關注的是如何利用輸入序列的上下文信息來影響模型輸出。其實,我覺得大概都是一回事。
Prompt的理論
在學習如何寫好提示詞之前,我們先看看理論,雖然理論實際上我覺得有點扯。
其實就是三篇論文
1:Chain-of-Throught (思維鏈)
論文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
原理:作為用戶,把需求描述更清楚(更適合對方的理解),具體的方法如下
* 大問題分解成小問題。職場OKR的做法。逐步思考,按問題解決的步驟。讓LLM多步驟思考。會消耗額外資源,但會多次思考。
* 多步驟輸出如何解決。讓LLM給出中間結果。就象高中生數學考試,不給過程,要扣分滴。這樣更容易發現錯誤(可以從錯誤的步聚重新開始)
* 對于數學應用題,一定要用步驟,逐步解決問題。
* 只能在大模型上,用少量樣本包含思路。才有用。小模型沒啥效果。原因是什么?越是復雜的問題,越有效。類似 Few-Shot?
舉例 :
提問中給出推理過程,幫助大模型在上下文中學習知識。然后舉一反三,答對問題:有點相當于老師把飯給你喂到嘴邊,先告訴你大概的解題思路。
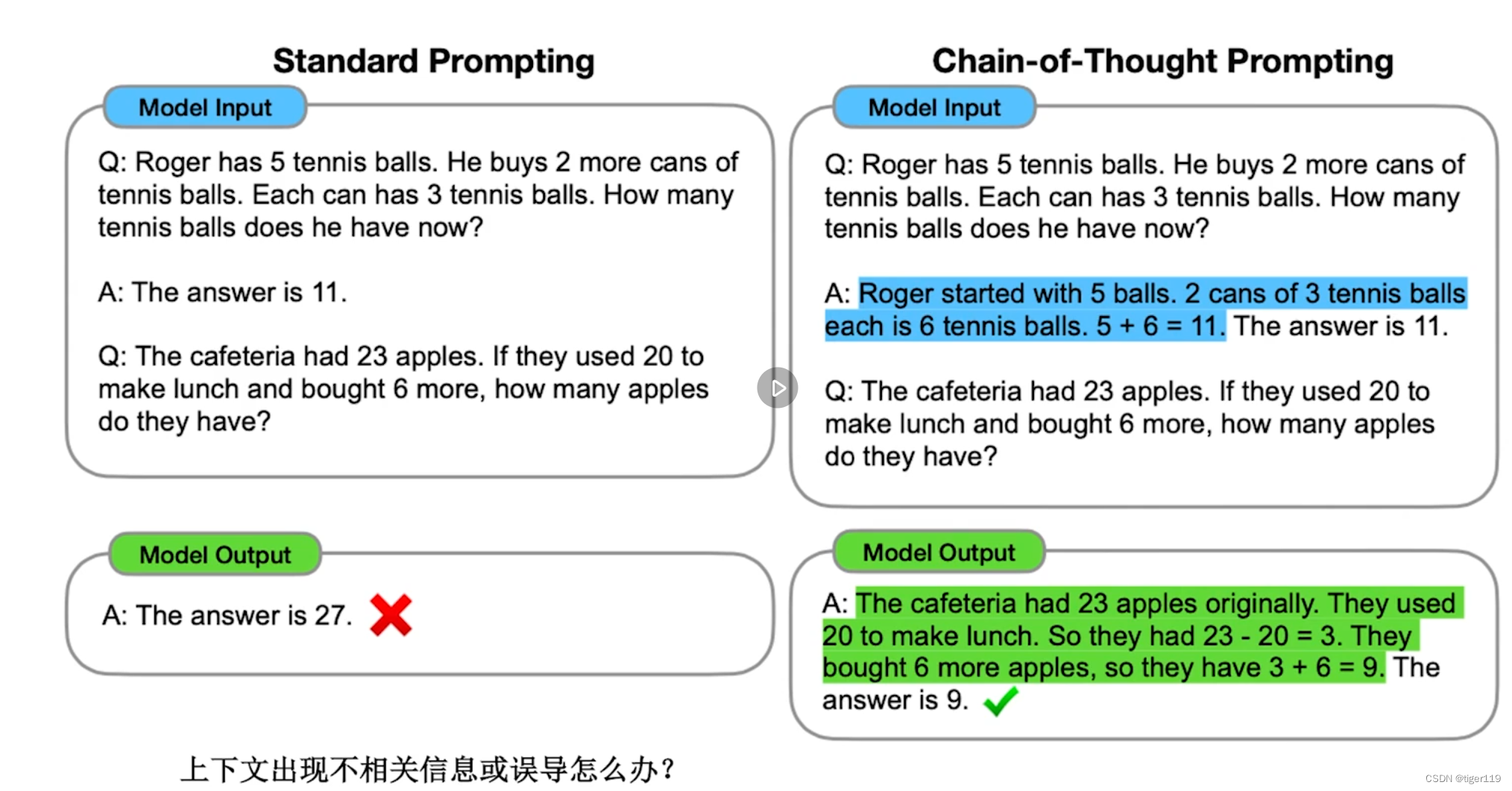
說實話,這個有點扯,一般我們并不會為了問第二個問題,去構造那么復雜的例子一。這實際上是有一定復雜度的。
我的理解就是為了讓大模型具備某一些能力,可以找到解決該類問題的多步驟解決的方法。把它當成上下文給到模型,然后模型可以學會按上下文的解法,來分步驟解決新問題。
對于ChatGPT的高版本,可能已經內置了相應的提示詞模板,會自動帶上模板,提升準確率,當然,因為是分步驟執行,可能會導致消耗更多的算力。對于GPT API,你需要自行按CoT的思想去構造提示詞。
除了添加按步驟示例的方法以外,還有一個小技巧:
在問題的后面追加說明:Think step-by-step? (請按步驟思考和回答這個問題)
在某些情況,會獲得更好的答案。
2:? 自洽性(多路徑推理)
論文:self-consistency improve Chain of Throught Reasoning in Language Models
原理:多路徑推理,如何提升思維鏈的能力。三個臭皮匠頂個諸葛亮,多回答幾次,投票選擇最優解。
初一看到這個,覺得挺好笑,為啥這也是重要的論文之一,這頂維期刊的論文,也太顯而易見了吧?
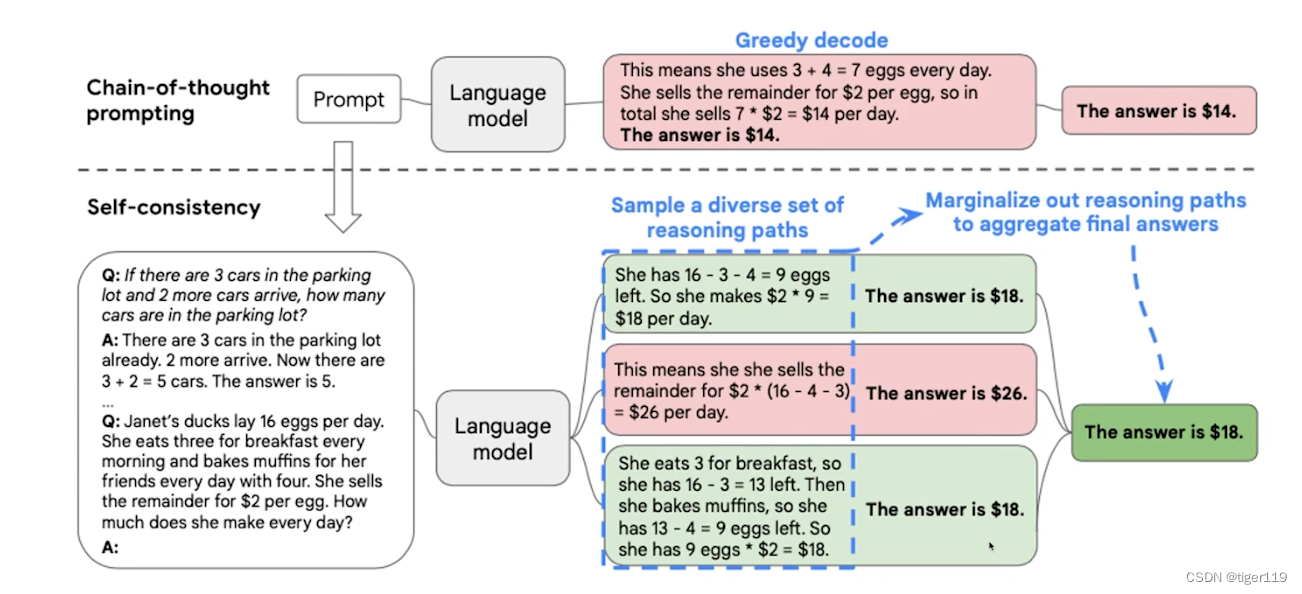
如上圖所示,可以根據多個路徑形成多解,然后投票獲取答案。
非常可惜的是,目前大模型在計算方面的能力不強,另外,對于人腦具德的有意識的行為,大模型基本上是做不到的。我們通過CoT 其實可以看出,大模型并沒有帶來意識,展開來看,它仍然是一種復讀機式的鸚鵡學舌式的智能。

好消息是:通過規模提升,帶來智能擁現。好像有智能了。壞肖息是,看起來還是鸚鵡學?,還是很弱智,并非產生了意識。對于意識:是腦科學范疇,人類自已也沒有弄明白,人到底是怎么回事,人類的本質是復讀機嗎?
? ? ? ? 今天看到騰訊小馬哥提出:人工智能的技術必須是可知的,也就是可以掌握,可以解釋的。其實有一定到底,否則到時可能控制不住,會出大問題。目前深度學習比較黑盒,不知是好事還是壞事。
3: 思維樹(Tree of Throughts)
論文:Tree of thought:Deliberate Problem Solving with Large Language Models
原理:能不能打破從左到右的有局限性的問題解決順序。類似BIRT的做法。
如下圖,類似搜索算法,可以進行遍歷解空間,找到全局最優解。

從理論上,可以看看ToT的思路,正如人是如何解決復雜問題的?
那就是不斷發掘,如何做:
Step 1:利用CoT,把問按多步驟拆解,思維分解。
Step 2:思維生成器——給出K個侯選項,進行抽樣,提供多樣性。
Step 3:選擇,進行價值評估。對每個狀態進行獨立評估。或者進行投票。
? ? ? ? ? ? ? 或者讓大語言模型自已來評估。
注意:在尋找答案時,需要搜索。可以使用廣度或者深度。
說實話,并沒有弄明白,我們如何使用ToT?至少感覺在ChatGPT中簡單利用提示詞很難,如果是編程,在做AutoGPT或者Agent時,好像可以按此思路來解決問題。但這和大模型本身的關系不大,確實又是一個工程方法。
提示詞如何寫?
? ? ? ? 好了,我們終于寫到重點了(以下都是網上截抄的,但我自已實驗過)
原則,把大模型當成你的同事,一個小伙伴。

? ? 這里提供的思路,并不是實際的例子,對于不同應用的例子,可以在網上搜索,或者選擇提示詞工具和插件。
角色設定:減少范圍,有點相當于直接選了MoE
? ? ? ?下面的示例中,System就是系統級的設定,如果在ChatGPT中,可以先單獨開一條消息,提前做一下說明,后續就不用再重復了。
指令注入:強調本次上下文一直要注意的信息

問題拆解:幫計算機拆解一下問題,不要太為難它

這個例子不太好,大概的意思就是把問題的步驟幫助做一下拆解。
分層設計:這個知道答案是分層的,那就按層來提問


編程思維:注意,大模型是可以支持自然語言編程的

問題實際上就是一段程序,可以有邏輯判斷,可以有輸出定義。
Few-Shot:給例子,給例子,給例子。
對于打樣,給例子,上面已經給出例子。
另外,網上提供的一個比較好的例子:生成標注數據,挺好用。

這個例子也很有用,在分析BUG時可以參考。

提示詞工程是啥?
? ? ? ? 隨著ChatGPT的工程能力越來越強,可能寫好提示詞的價值會越來越小。你可能在使用chatGPT過程中會發現,之前的一些提示詞黑魔法,在高版ChatGPT會變得沒必要了。因為相應的提示詞會在ChatGPT中自動引用。但目前而言,GPT API是沒有開放相應的能力的,還需要我們通過程序來進行封裝。
? ? ? ? 我們需要將手工變成自動,把手工的Prompt變成程序自動生成(實際上是抽象變量)。這樣變成一個固定的做法。變成一個工程問題。可以通過抽象模板來完成。
? ? ? ? 比如:我要將{文字}翻譯成{中文}? ?這實際上就是一個翻譯工具
? ? ? ? 比如:我要創作一個{}的文案。
? ? ? ? 定義模板,抽取參數,它就變成一個自動化的工具。
? ? ? ? 將Prompt當作編程語言,把多個prompt串在一起,就可以完成復雜的任務。
? ? ? ? 作為提示詞工程師,會按照一定的規則去寫提示詞。
使用LangChane時,可以很好的使用Prompt,因為它有一個Promt Templates:
1:PromtTemplate.from_template(""),可以添加變量,使用時傳入。輸出格式也可以規范。
可以檢查傳參。無變量也是可以的。
2:使用構造函數生成PromptTemplate。和1沒啥區別。只是更嚴格,確定參數
這個有點怪,但你可以認為實際上就是將自然語言封裝了變量。
ChatPromptTemplate 與之類似。
可以在System中添加變量。要以在user_input中定義變量。
使用fromatf進行參數傳入
FewShotPromptTemplate——給參考示例。
給示例集,解包,定義字典,模板還可以嵌套。
注意:SematicSimilarityExampleSelector 可以查找相近的語義詞。這個很有用噢。
如下是一個簡單的示例圖,只要學過一點點編程,很容易理解這個。

對于復雜的情況,我們還可以生成思維鏈,完成復雜的流程,也就是類似上面講到的ToT了。我覺得ToT的落地,就在這里了。
比如:我需要提供一個工具,有大模型來生成戲劇,另外,針對生成的戲劇在理解后進行評論,使用另一個大模型。對于此類的問題,就需要比較復雜的對待了。
(如下使用的框架是開源的LangChain框架)

好了,大概寫這么多,提示詞大家確實沒必要太關注,我也覺得它是一個過渡的技術。
它的起因是為了給基礎大模型減壓(模型能力問題)
它的發展是因為低版本的ChatGPT的工程能力弱(沒有對提示詞封裝),API沒有提供相應的模板支持,但是,很可能后續很快會被補上。
當然,了解一下原理,并沒有什么壞處。
但沒有必要滿世界去學習提示詞模板,在需要的時候,去搜一下就好了。
但是要注意,提示詞模板并不是通用的,要看具體的大模型和大模型的版本。








)








![P3128 [USACO15DEC] Max Flow P題解(樹上差分,最近公共祖先,圖論)](http://pic.xiahunao.cn/P3128 [USACO15DEC] Max Flow P題解(樹上差分,最近公共祖先,圖論))

