
大模型技術論文不斷,每個月總會新增上千篇。本專欄精選論文重點解讀,主題還是圍繞著行業實踐和工程量產。若在某個環節出現卡點,可以回到大模型必備腔調重新閱讀。而最新科技(Mamba,xLSTM,KAN)則提供了大模型領域最新技術跟蹤。若對于構建生產級別架構則可以關注AI架構設計專欄。技術宅麻煩死磕LLM背后的基礎模型。
Anthropic的模型可解釋性團隊,一直想和大模型的靈魂交流,最近在研究Claude 3 Sonnet的內部的參數結構和工作原理時,獲得十分有趣的結論。總所周知,大模型基于人工神經網絡,里面的神經元的激活模式運用十分廣泛。研究人員認為研究這些激活模式以及對應神經元的分布就可以大致的將神經網絡的學習和掌握到的知識概念可視化。

研究思路
大模型理解一行詩詞或者意境主要是基于線性表示假設和疊加假設。從更抽象以及更高維度上,線性表示假設表明神經網絡將具有一定意義的知識概念表示為其激活空間(N維)中的方向。而疊加假設則在線性表示假設的基礎上,并進一步提出了神經網絡是利用高維空間中的各種方向(幾乎正交的向量)的疊加來表示比N維數量更多的特征。這兩種假設的前提下誕生了一種研究標注方法就是字典學習(Dictionary learning)。
有論文表明這種解釋對于Transformer語言模型來說非常有效,例如一種稱為稀疏自動編碼器就非常有效,它近似的等同于字典學習。
稀疏自動編碼器在標準自動編碼器的基礎上增加了稀疏性約束。稀疏性約束通過在隱藏層中引入額外的懲罰項,限制隱藏單元的激活數量,使得大多數隱藏單元的激活值接近零。
假設有一個簡單的稀疏自動編碼器,輸入層有4個單元,隱藏層有3個單元,輸出層有4個單元。目標是學習一個稀疏的3維隱藏層表示,同時稀疏性的約束讓隱藏層的大多數單元的激活值接近零。
具體來說,研究人員使用了一種“字典學習”的技術。該技術主要是訓練一個單獨的神經網絡B,以盡可能緊湊重建被研究模型某些特定層的激活場景。然后,網絡B經過訓練后,權重會形成一個激活模式的“詞典”,稱為特征。每個特征代表模型已學習的一個知識概念。
上面這段話的意思就是看下圖,用一個稀疏的自動編碼器將激活層進行分解,形成特征。分解成的特征比神經元的數量還多。這是因為MLP層可能使用疊加示比神經元更多的特征。事實上在最大的實驗中,可以擴展到比神經元多256倍(131072)的特征。

換句話說,它利用大模型的激活值來訓練一個類似等同的稀疏自動編碼器,因為是稀疏自動編碼器,所以可以比較直觀的觀察激活情況。注意下面的圖表,它采集了mlp的激活值大約8B進行訓練。


Sparse AutoEncoders(SAE)
本次研究人員使用的SAE是“稀疏字典學習”算法系列的一個實例,旨在將數據分解為稀疏的激活組件的加權和。
本次的SAE由兩層組成,第一層(“編碼器”)通過學習的線性變換和ReLU激活函數將輸入映射到更高維度空間。我們將這個高維的層稱為“特征(feature)”。第二層(“解碼器”)嘗試通過激活的“特征”的線性變換來重建模型激活。當然訓練模型的過程是采用最小化重建誤差和鼓勵稀疏的“特征”激活為目標進行迭代訓練。
一旦SAE 訓練完成,它就會提供一個模型激活的近似分解,將其分解為“特征方向”(SAE解碼器權重)的線性組合,其系數等于“特征”激活。稀疏性懲罰確保對于模型的許多給定輸入,只有極小一部分特征具有非零激活。因此,對于任何給定上下文中的任何給定標記,模型激活都由一小部分活動特征(從大量可能特征中)“解釋”。
本次訓練三個不同大小SAE:1,048,576(~1M)、4,194,304(~4M)和 33,554,432(~34M)個特征。對于三個SAE,給定 token 上活躍的特征(即具有非零激活)的平均數量少于 300,并且 SAE 重構至少解釋了模型激活方差的 65%。在訓練結束時,1M SAE 的死特征比例約為 2%,4M SAE 為 35%,34M SAE 為 65%。

即較小SAE中的特征在較大SAE中“分裂”成多個特征的現象,這些特征在幾何上接近且在語義上與原始特征相關,但表示更具體的概念。例如,1M SAE中的“舊金山”特征在4M SAE中分裂成兩個特征,在34M SAE中分裂成11個細粒度特征。
除了特征分裂之外,還看到一些示例,其中較大的SAE包含一些特征,這些特征代表了較小的 SAE中的特征無法捕捉到的概念。例如,4M和34M SAE中有一組地震特征,在 1M SAE中沒有類似的特征,而且最近的 1M SAE的特征似乎也沒有任何關聯。

示例:金門大橋
SAE提取的特征涵蓋范圍廣泛,從知名的公眾人物、地點、到程序代碼中的句法元素,再到同情或諷刺等抽象概念。下面的示例特征展示了來自 SAE 數據集中前 20 個文本輸入的代表性示例,按它們激活該特征的強度進行排序。單擊特征ID 可以找到更大的隨機采樣激活集。突出顯示的顏色表示每個標記的激活強度(白色:無激活,橙色:最強激活)。

聚焦金門大橋特征周圍的一個小街區,會發現其中有與舊金山特定位置相對應的特征,例如惡魔島和要塞。在更遠的地方還看到相關程度降低的特征,例如與太浩湖、優勝美地國家公園和索拉諾縣(靠近舊金山)相關的特征。在更遠的距離,我們還看到以更抽象的方式相關的特征,例如與其他地區的旅游景點相對應的特征(例如“法國梅多克葡萄酒產區”;“蘇格蘭斯凱島”)。總體而言,解碼器空間中的距離似乎粗略地映射到概念空間中的相關性,通常是以有趣和意想不到的方式。

緊接著來看看金門大橋特征34M/31164353。其最大激活基本上是對大橋的所有引用,較弱的激活還包括相關的旅游景點、類似的橋梁和其他紀念碑。接下來,腦科學特征34M/9493533激活了神經科學書籍和課程以及認知科學、心理學和相關哲學的討論。在 1M 訓練運行中,我們還發現一個特征強烈激活了各種交通基礎設施1M/3,包括火車、渡輪、隧道、橋梁甚至蟲洞!最后一個特征1M/887839??響應了熱門旅游景點,包括埃菲爾鐵塔、比薩斜塔、金門大橋和西斯廷教堂。

X軸代表激活值,藍色為不相關,紅色為直接相關。雖然分析方法僅適用于文本數據,但許多特征對相應概念的文本提及和圖像都很敏感。
研究人員發現了一個特征,它對提及金門大橋有特定的反應。當這個特征被人為地激活到最大值的十倍時,模型甚至開始將自己與這座大橋聯系起來,并產生諸如“我是金門大橋,我將舊金山與馬林縣連接起來”這樣的陳述。

免疫學特色1M/533737為中心,可以看到這個鄰域內有幾個不同的聚類。在圖的頂部,可以看到一個聚類專注于免疫功能低下的人、免疫抑制、導致免疫功能受損的疾病等等。向下向左移動時,它轉變為一個專注于特定疾病(感冒、流感、一般呼吸道疾病)的特征聚類,然后是與免疫反應相關的特征,然后是代表與免疫有關的器官系統的特征。相反,當從免疫功能低下的聚類向右向下移動時,可以看到更多與免疫系統的微觀方面(例如免疫球蛋白)相對應的特征,然后是免疫學技術(例如疫苗)等等。
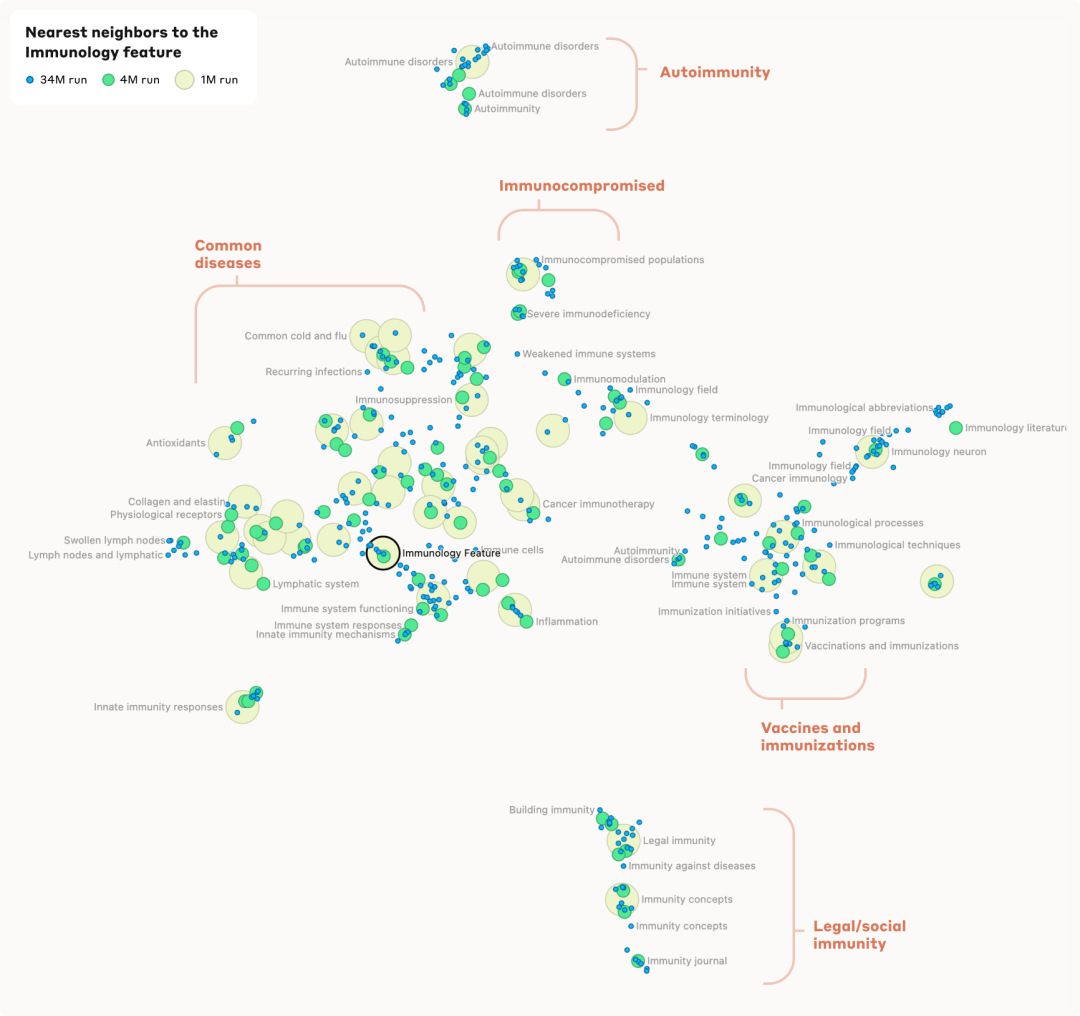
在最底部與其他部分截然不同,看到了一組與非醫學背景(例如法律/社會)中的免疫相關的特征。
研究人員還發現了特征層次結構證據。例如在更詳細分析時,一般特征“舊金山”會分解為針對單個地標和街區的幾個更具體的特征。同樣,國家特征(例如“加拿大”或“冰島”)會分解為“地理”、“文化”和“政治”等子特征。
研究人員表示:“我們發現的特征僅代表模型在訓練期間學習到的所有概念的一小部分,而使用我們當前的技術找到一整套特征的成本將非常高昂(我們當前方法所需的計算量將大大超過用于訓練模型的計算量)。”
研究人員還發現了該模型的潛在問題特征。例如,有些特征對生物武器的開發、欺騙或操縱很敏感,可能會影響模型的行為。
論文指出,僅僅存在這些特征并不一定意味著模型(更)危險。然而,這表明需要更深入地了解這些特征何時以及如何被激活,然而打開大模型的黑匣子將可以幫助未來更好地理解語言模型。

![[算法][前綴和] [leetcode]724. 尋找數組的中心下標](http://pic.xiahunao.cn/[算法][前綴和] [leetcode]724. 尋找數組的中心下標)






)
)









