一、設計模式
1、創建型
抽象工廠:提供一個接口,創建一系列的相關相互依賴的對象,無需指定具體的類;
eg:系統軟件,支持多種數據庫
生成器:將一個復雜類的表示與構造相分離,使得相同的構建過程能夠得到不同表示;
eg:同樣制作方法,不同種類披薩
工廠方法:定義一個創建對象的接口,但由子類決定需要實例化哪一個類;
eg:產品選擇用哪個子類產品
原型Prototype:用原型實例指定創建對象的類型,并且通過拷貝這個原型來創建新的對象;
eg:自動生成求職簡歷,工作經驗不同(clone)
單例:保證一個類只有一個實例,并且提供一個訪問他的全局訪問點、、、1855
2、結構型設計模式
適配器:將一個類的接口轉換成用戶希望得到的另一種接口。使得原本不兼容的接口得以協同工作;eg:USB,Type-c,語言適配?
橋接:將類的抽象部分和它的實現部分分離,使得可以獨立變化; 繼承樹拆分
eg:不同Linux,win系統顯示不同后綴圖片gif,bmp,jpeg
組合(composite):將對象組合成樹型結構以表示“整體-部分”層次結構,使用戶對單個對象和組合對象的使用具有一致性。
eg:公司,子公司;文件夾,文件,菜單?
裝飾器:動態給一個對象添加一些額外職責,子類擴展功能;
eg:operation,super.print()調用父類方法,super(t)表示父類的,發票頭尾
person lisi = new Decorator(new A(new student("lisi")))
外觀(Facade):定義一個高層接口,為子系統中的一組接口提供一個一致的外觀,簡化該系統的使用;eg:對外統一接口
享元(Flyweight):提供支持大量細粒度對象共享的有效方法;
eg:黑子,白子,位置
代理:為其他對象提供一種代理以控制這個對象的訪問;
3、行為型設計模式
責任鏈:多個處理器依次處理同一個請求。一個請求先經過 A 處理器處理,然后再把請求傳遞給 B 處理器,B 處理器處理完后再傳遞給 C 處理器,以此類推,形成一個鏈條。鏈條上的每個處理器各自承擔各自的處理職責。
命令:將一個請求封裝為一個對象,從而使得可以用不同的請求進行參數化,對請求排隊或者記錄請求日志以及支持可撤銷的操作。
eg:遙控器開關機,開關燈;
解釋器:有一個語言需要解釋執行,并且你可以將該語言中的句子表示為一個抽象語法樹時,可以使用解釋器模式
迭代器:提供一種方法順序訪問一個聚合對象中的各個元素,而又不暴露該對象的內部表示。常用于遍歷一個集合對象
中介者:中介模式定義了一個單獨的(中介)對象,來封裝一組對象之間的交互。將這組對象之間的交互委派給與中介對象交互,來避免對象之間的直接交互。
eg:支付接口
備忘錄:在不破壞封裝性的前提下,捕獲一個對象的內部狀態,并在該對象之外保存這個狀態。這樣以后就可將該對象恢復到原先保存的狀態。多用于數據備份和恢復的場景。
觀察者:對象之間定義一個一對多的依賴,當一個對象狀態改變的時候,所有依賴的對象都會自動收到通知
eg:關注up,關注某個事情
狀態:當一個對象的行為取決于它的狀態,并且它必須在運行時根據狀態改變它的行為時就可以考慮狀態模式
eg:自動販賣機,會員等級調整。
策略:策略模式會定義一系列算法,從概念上來看,所有這些算法完全的都是相同的工作,相互替換,只是實現不同,它可以以相同的方式調用所有的算法,
eg:飛機模擬飛行。購物中心打折,滿減,原價
模板方法:定義一個操作中的算法骨架,而將一些步驟延遲到子類中。模板方法使得子類可以不改變一個算的結構即使重定義該算法的某些特定步驟。
訪問者:表示一個作用于某對象結構中的各元素的操作,它使你可以在不改變各元素的類的前提下定義作用于這些元素的新操作。
eg:統計館藏文獻頁數?
二、數據結構----圖
1、鄰接矩陣:n*n
有向圖: 行:出度,列:入度;
無向圖:對稱,第 i 行非0元素個數為頂點 i 的度;
稠密圖:O(n2)
2、鄰接表:
有向圖:空間:n+e,
無向圖:n+2e,
稀疏圖
3、十字鏈表:有向圖,易
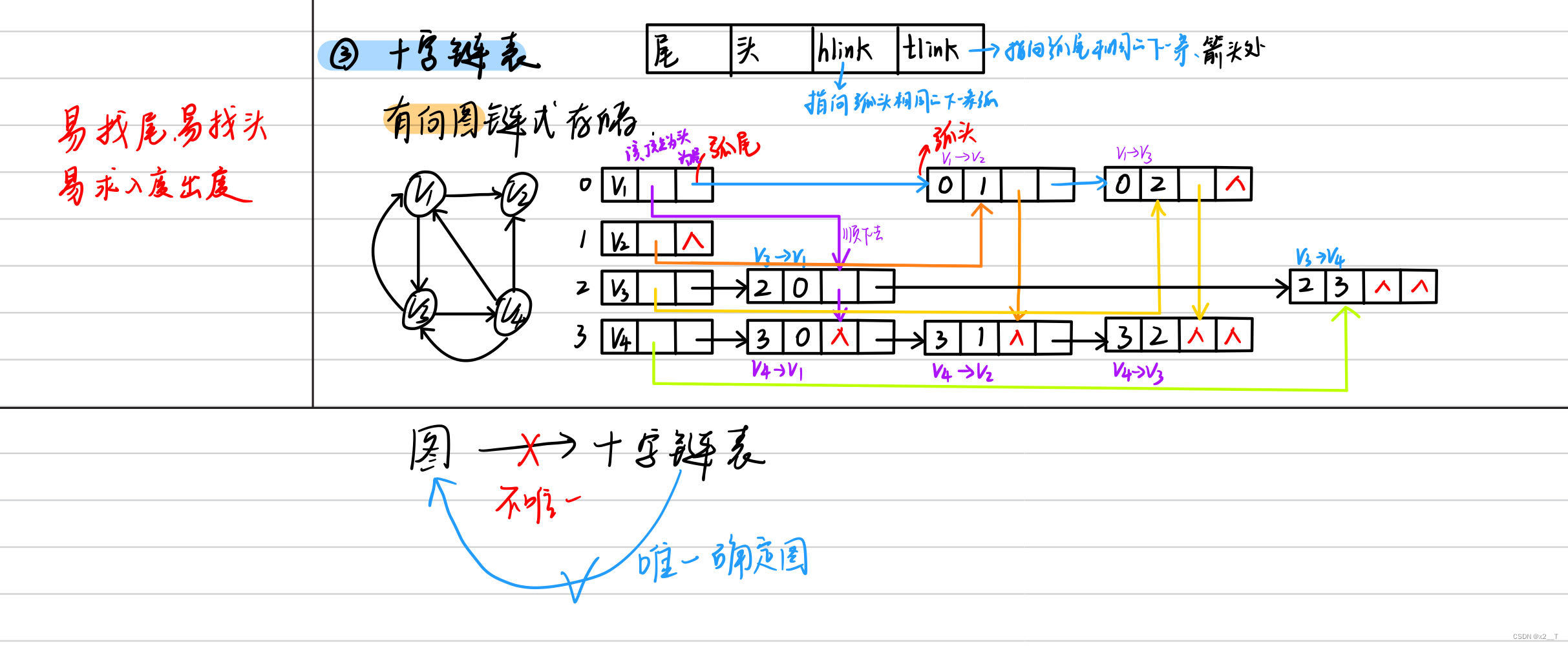
4、廣度優先:
隊列,不唯一,BFS,層序遍歷
空間復雜度:O(n),時間復雜度:O(e);
5、深度優先:
棧,不唯一,BFS,先序遍歷
空間復雜度:O(n),時間復雜度:O(e);
6、最小生成樹
帶權連通無向圖
(1)prim:O(v2)邊稠密;從頂點開始,找集合邊最小;
(2)(貪心算法)kruskal:不斷選擇未被選的最小權值邊,O(eloge),邊稀疏;
7、最短路徑:
(1)(貪心算法)Dijkstra:某一頂點到其他頂點的最短路徑(單源),O(v2);
(2)(動態規劃)Floyed:適用所有頂點間最短路徑和帶權無向圖,
時間復雜度:O(v3)空間復雜度:O(n2)
拓撲排序:AOV網,關鍵路徑--AOE網
二、數據結構----排序
1、查找
順序查找:ASL=(n+1)/2
二分查找:ASL=O(logn)
2、排序

歸并排序:動態規劃
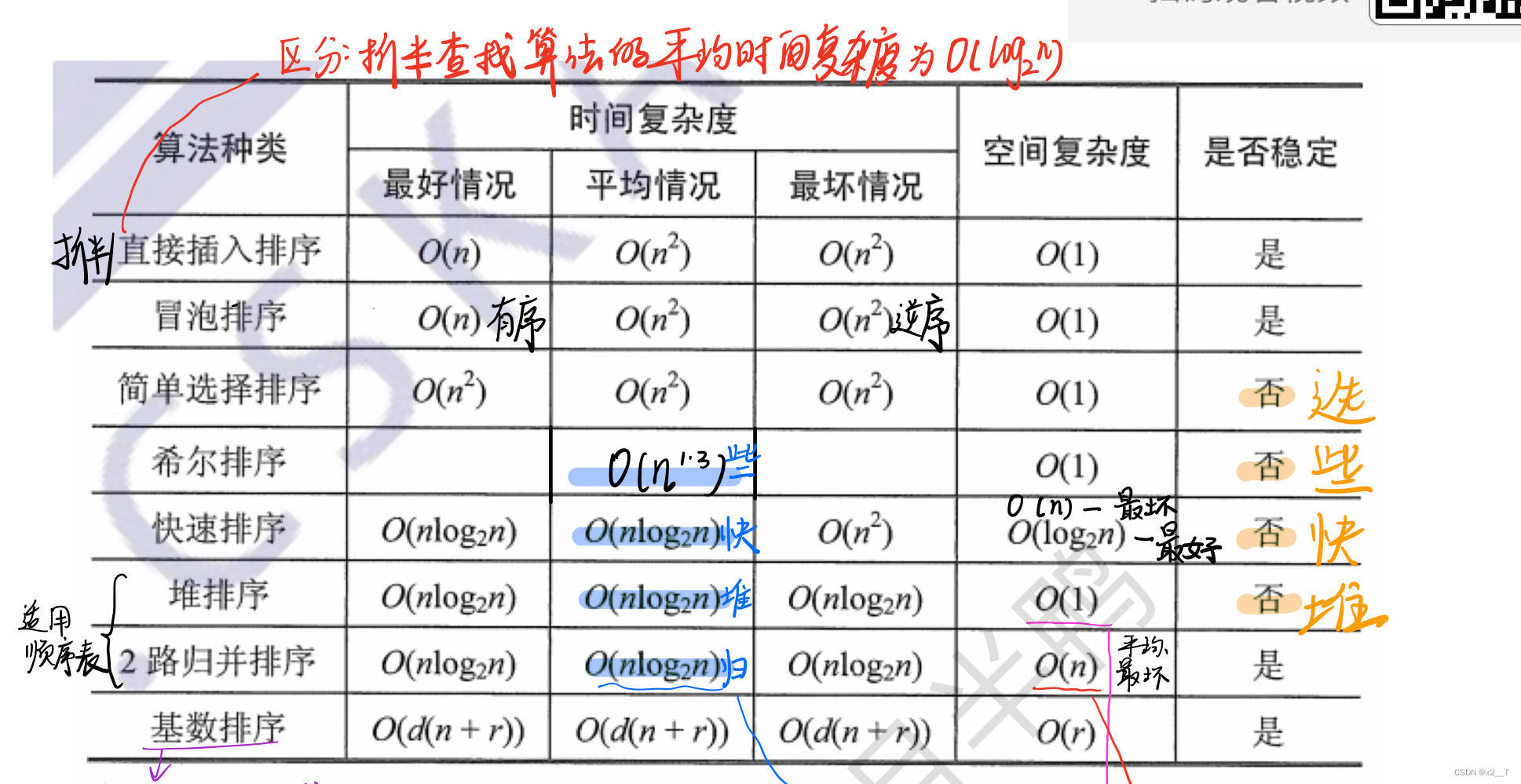
不穩定:快些選堆 朋友來
時間快(nlogn):快些歸隊
一趟確定一個位置:快,選,堆,冒(帽子)

再就是:
正規式:有限自動機的另外一種表達形式
|:表示或
()*:表示循環多次,*可以是0到無窮
計算機網絡
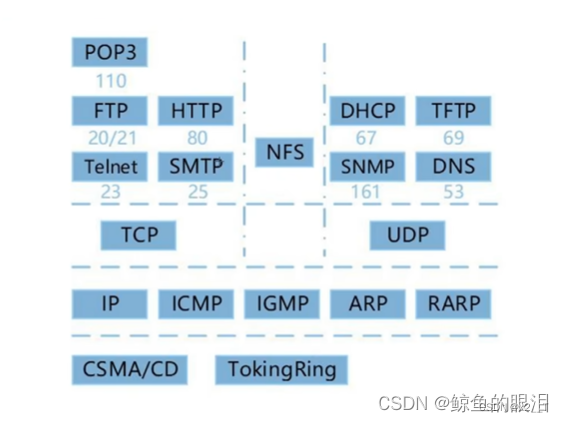
dhcp分到的ip是169和0,說明有問題,是錯誤的
DHCP動態分配ip時候:若沒有獲取到,Windows是169.254.0.0,linux是0.0.0.0
DHCP客戶端可以從DHCP服務端獲得本機IP地址、DNS服務器地址、DHCP服務器地址、默認網關的地址(沒有web服務器地址和郵件服務器地址)
軟件工程:
瀑布模型
每個階段末尾都會有評審,評審上一階段的工作是否達標
缺點:初期分析需求無法把控,開發末期的結果和客戶要求不一致,全盤推翻==(不能適應變化的需求)==
適用場景:需求明確/二次開發/有過經驗,用新技術重構也用瀑布
原型:
定義在需求不明確的情況,初期構建一個簡易系統讓用戶發現問題,探索用戶的需求==(只應用于需求分析階段)==,也可以探索出特殊的軟件解決方案
能夠迅速開發出一個讓用戶看得見的系統框架,可以用來支持用戶界面設計
不能指導代碼優化
原型模型最不適合大規模軟件開發
增量:
先做出核心,好處在核心模塊盡早和用戶接觸了==(逐步理解需求)==,但是這種模式如何進行模塊劃分是難點
演化(迭代)模型:
相比原型,適用于需求清楚,盡早投入使用,要不斷改善的時候
螺旋模型
將開發活動和風險管理結合起來,求將風險降到最小并控制風險
有多個模型的特點:瀑布+快速原型
包含維護周期,所以開發和維護之間沒有本質區別
噴泉模型與RAD
面向對象
用戶需求為動力,對象作為驅動,客服了瀑布模型不支持軟件重用和多項開發活動集成的局限性
迭代、無間隙(開發活動之間不存在明顯邊界)
RAD:快速開發模型,SDLC(瀑布模型)+CBSD(構件化開發模型);可以快速構建應用系統
統一過程UP
也稱RUP,用例和風險為驅動,以架構為中心,迭代并增量開發
用于大型項目
五個階段:起始、精化、構建、移交、產生
敏捷開發方法
給開發減輕負擔、適合小型項目、隨時對接客戶
自適應方法ASD==(6個基本原則)、水晶方法Crystal(每個項目用不同方法)、特征驅動開發、并列爭球法SCRUM(30天一迭代的沖刺,按需求優先級實現)、極限編程XP(激發創造性、管理負擔小,測試先行)
內聚是一個模塊內部各個元素彼此結合的緊密程度
巧合內聚(偶然內聚):兩個程序塊放在一起,但是沒有任何關系
邏輯內聚:兩個放在一起的程序塊有邏輯上的關系(比如根據參數選擇調用哪個程序塊)
時間內聚:需要同時執行的幾個任務放在一起
過程內聚:放在一起的程序塊處理的元素是相關的,并且按一定次序
通信內聚(信息內聚):模塊內處理的對象都是同一個數據結構
順序內聚:放在一起的程序塊處理的元素是相關的,并且順序執行
功能內聚:模塊內所有元素完成單一功能(不可再分,缺一不可)
耦合是模塊之間相互獨立性的度量,連接越緊密,耦合性越高,獨立性越弱
數據耦合:兩個模塊之間通過簡單數據交換信息
標記耦合:兩個模塊通過數據結構傳遞
公共耦合:訪問同一個公共的數據環境


)


-效益如何評估)













