python-pytorch 下批量seq2seq+Bahdanau Attention實現簡單問答1.0.000
- 前言
- 原理看圖
- 數據準備
- 分詞、index2word、word2index、vocab_size
- 輸入模型的數據構造
- 注意力模型
- decoder的編寫
- 關于損失函數和優化器
- 在預測時
- 完整代碼
- 參考
前言
前面實現了 luong的dot 、general、concat注意力實現簡單問答,這里參考官方文檔,實現了python-pytorch 下批量seq2seq+Bahdanau Attention實現問答
原理看圖
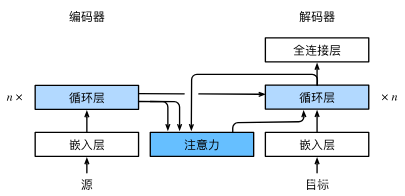
這里模型選擇和官方不一樣,官方選擇的是GRU,我更喜歡使用LSTM,解碼器和編碼器都是如此。
意思大致思路是:
- 計算encoder的encoder_outputs、encoder_hn、encoder_cn
- 使用encoder_outputs、encoder_hn計算新的向量和注意力
- 在deconder中,以SOS單字開始,循環句子最大長度,在循環中,使用新的向量和單字SOS做cat計算得到decoder的LSTM輸入數據,將該LSTM存起來,最后做cat計算得到decoder的輸出
數據準備
結果類似還是采用前面的結構和數據
seq_example = [“你認識我嗎”, “你住在哪里”, “你知道我的名字嗎”, “你是誰”, “你會唱歌嗎”, “誰是張學友”]
seq_answer = [“當然認識”, “我住在成都”, “我不知道”, “我是機器人”, “我不會”, “她旁邊那個就是”]
分詞、index2word、word2index、vocab_size
分詞然后做基礎準備,包括數據:index2word、word2index、vocab_size、最長的句子長度seq_length,和一些超參數的設置
輸入模型的數據構造
- 長度要統一
- 問答的句子以EOS結尾,不足補0,如
tensor([[ 3, 4, 5, 6, 2, 0, 0],
[ 3, 7, 8, 9, 2, 0, 0],
[ 3, 10, 5, 11, 12, 6, 2],
[ 3, 13, 14, 2, 0, 0, 0],
[ 3, 15, 16, 6, 2, 0, 0],
[14, 13, 17, 2, 0, 0, 0]])
注意力模型
可以復用,用官方的即可
# Bahdanau
# query=hidden [layer_num,batch_size,hidden_size] keys=encoder_outputs [seq_len,batch_size,hidden_size]
class Attention(nn.Module):def __init__(self):super(Attention, self).__init__()self.Wa = nn.Linear(hidden_size, hidden_size)self.Ua = nn.Linear(hidden_size, hidden_size)self.Va = nn.Linear(hidden_size, 1)def forward(self, query, keys):scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys))) #[seq_len,batch_size,1]scores = scores.permute(1,0,2).squeeze(2).unsqueeze(1)#[batch_size,1,seq_len]weights = nn.functional.softmax(scores, dim=-1)#[batch_size,1,seq_len]context = torch.bmm(weights, keys.permute(1,0,2))#[batch_size,1,hidden_size]return context, weights
decoder的編寫
思路是,獲得encoder的輸出和hn后,計算得到向量,然后使用向量和目標的每一個字做cat計算,輸入decoder的模型中,然后得出一個字的預測,循環完了以后,就會得到最大句子長度,最后做cat和softmax計算得到輸出。另外,這里要區分訓練和測試,訓練的時候有target,測試的沒有target數據。
關于損失函數和優化器
NLLLoss+Adam的組合優于CrossEntropyLoss+SGD的組合
在預測時
獲取到模型輸出,size是[batch_size,seq_len,vocab_size]后,對結果做topk計算,會得到每一字在vocab_size的概率,連接起來就是一句話
完整代碼
# def getAQ():
# ask=[]
# answer=[]
# with open("./data/flink.txt","r",encoding="utf-8") as f:
# lines=f.readlines()
# for line in lines:
# ask.append(line.split("----")[0])
# answer.append(line.split("----")[1].replace("\n",""))
# return answer,ask# seq_answer,seq_example=getAQ()import torch
import torch.nn as nn
import torch.optim as optim
import jieba
import os
from tqdm import tqdmseq_example = ["你認識我嗎", "你住在哪里", "你知道我的名字嗎", "你是誰", "你會唱歌嗎", "誰是張學友"]
seq_answer = ["當然認識", "我住在成都", "我不知道", "我是機器人", "我不會", "她旁



)
】簡單用接口查詢【等級/昵稱/頭像/Q齡/當天在線時長/下一個等級升級需多少天】)




)




監控與告警)



