1.概述
擴散模型是最近出現的強大的深度生成模型,可用于生成高質量圖像。擴散模型發展迅速,可應用于文本到圖像生成、圖像到圖像生成、視頻生成、語音合成和 3D 合成。
除了算法的改進,骨干網的改進在擴散建模中也發揮著重要作用。一個典型的例子是基于卷積神經網絡(CNN)的 U-Net,它已被用于之前的研究中。 基于 CNN 的 UNet 的特點是一系列下采樣塊、一系列上采樣塊以及這些組之間的長跳接UNet 基于 CNN。它在圖像生成任務的擴散模型中起著主導作用。
另一方面,視覺變換器(ViTs)在各種視覺任務中都取得了可喜的成果:在某些情況下,ViTs 的表現不亞于或優于基于 CNN 的方法。這就自然而然地提出了一個問題:是否有必要在擴散模型中依賴基于 CNN 的 U-Nets?
本評論文章提出了一種基于 ViT 的 UNet(U-ViT)。所提出的方法在 ImageNet 和 MS-COCO 上生成的圖像達到了最高的 FID(衡量圖像質量的標準)。
論文地址:https://arxiv.org/abs/2209.12152
源碼地址:https://github.com/baofff/U-ViT.git
2.U-ViT構架
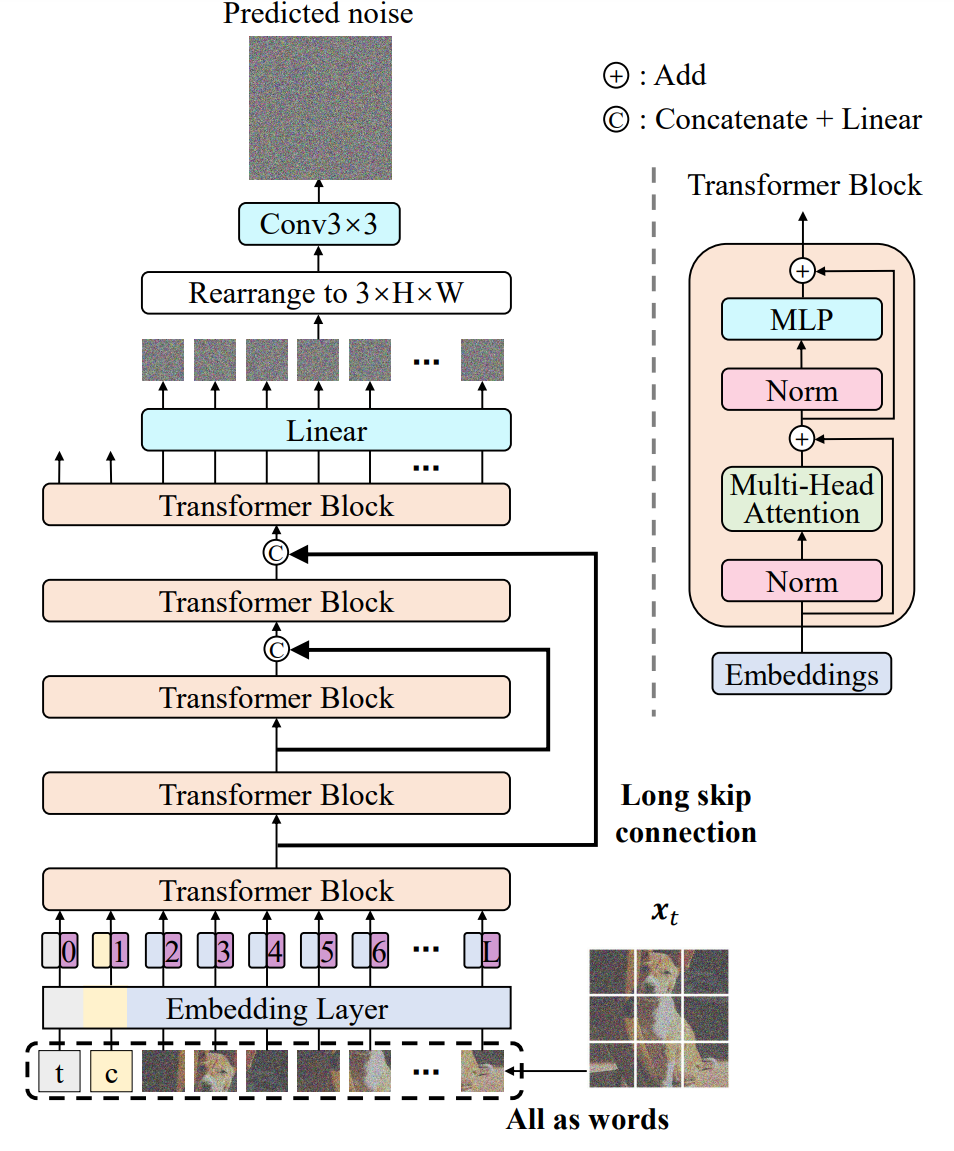
上圖 是 U-ViT 的概覽。該網絡獲取擴散過程的時間(t)、條件(c)和噪聲圖像 ( x t ) (x_t) (xt?),并預測要注入到圖像中的噪聲 ( x t ) (x_t) (xt?)。 按照 ViT 的設計方法,圖像被劃分為多個補丁,U-ViT 處理所有輸入,包括時間、條件和圖像補丁,并將所有輸入視為標記(詞)。并將所有輸入視為標記(詞)。
與基于 CNN 的 U-Net 一樣,U-ViT 在淺層和深層之間使用長跳轉連接。訓練擴散模型是一項像素級的預測任務,對低層特征非常敏感。長跳轉連接為低層特征提供了捷徑,便于噪聲預測網絡的訓練。
此外,U-ViT 還可選擇在輸出前添加一個 3x3 卷積塊。這是為了防止變換器生成的圖像中出現潛在的偽影。
以下各小節將提供有關 U-ViT 各部分的更多詳細信息。
3.1 實施細節
本節將通過 CIFAR10 中生成圖像的圖像質量(FID)來優化 U-ViT 的結構。整體結果概覽見下圖 。
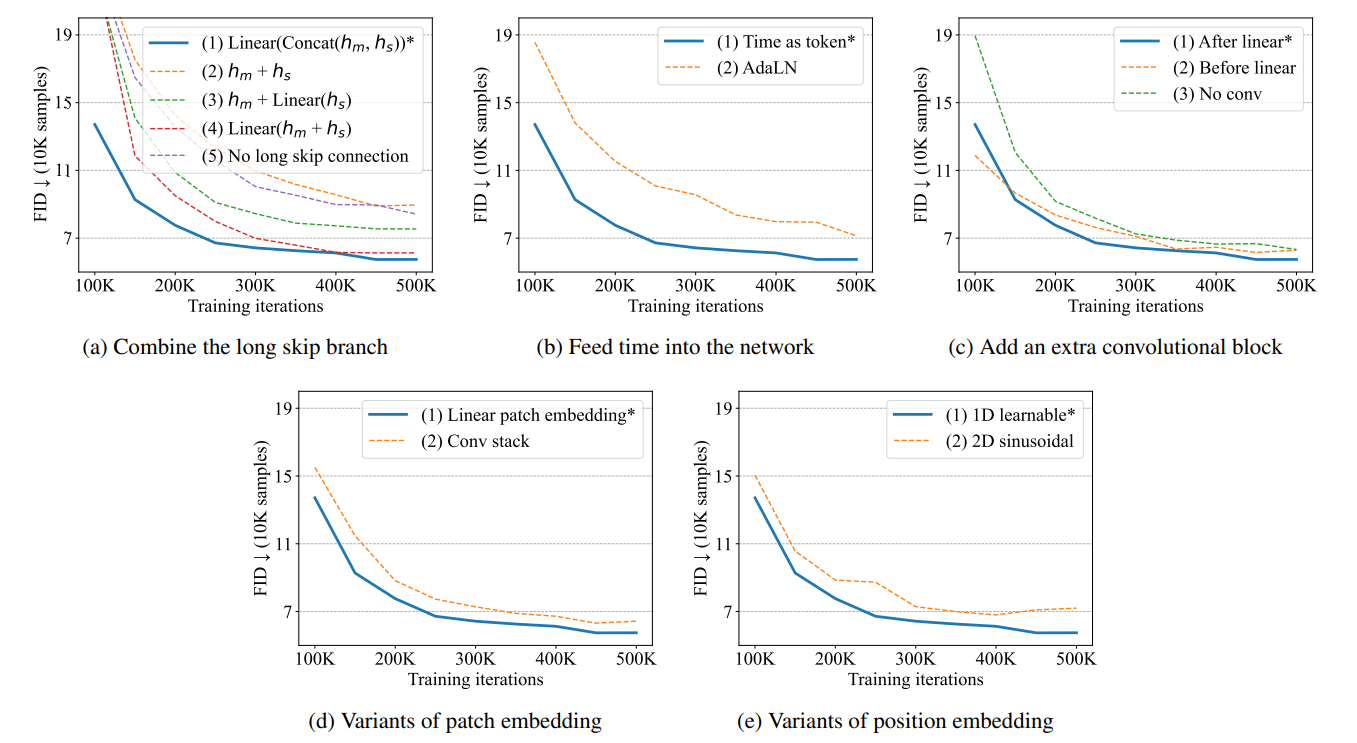
如何結合長跳轉連接起來
首先讓 h m , h s R L × D h_m,h_sR^{L×D} hm?,hs?RL×D成為主分支和長跳分支的嵌入。在將它們送入下一個變換塊之前,考慮一些將它們組合起來的方法:
-
將 h m , h s h_m,h_s hm?,hs?連接起來,然后執行線性投影: L i n e a r ( C o n c a t ( h m , h s ) ) Linear(Concat(h_m,h_s)) Linear(Concat(hm?,hs?))。
-
直接添加 h m 、 h s : h m + h s h_m、h_s:h_m+h_s hm?、hs?:hm?+hs?。
-
在 h s h_s hs?上進行線性投影,并將其添加到 h m : h m + h s h_m:h_m+h_s hm?:hm?+hs?。
-
添加 h m 、 h s h_m、h_s hm?、hs?,然后進行線性投影: L i n e a r ( h m + h s ) Linear(h_m+h_s) Linear(hm?+hs?)。
-
刪除長跳線連接
如上圖所示,在這些方法中,第一種使用連接 LinearConcat ( h m , h s ) \text{Linear} \text{Concat}(h_m,h_s) LinearConcat(hm?,hs?)的方法效果最好。特別是,與不使用長跳轉連接的方法相比,生成圖像的質量明顯提高。
如何輸入時間條件
將時間條件 t 輸入網絡的方法有兩種。方法(1) 是將它們視為標記,如圖 1 所示。 方法(2)是在轉換器模塊中將層歸一化后的時間納入,這與 U-Net 中使用的自適應組歸一化類似;第二種方法稱為自適應層歸一化(AdaLN)。 將時間視為標記的方法(1) 比 AdaLN 性能更好。
如何在變壓器后添加卷積塊
在變換器后添加卷積塊有兩種方法。(1) 在將標記嵌入映射到圖像補丁的線性投影之后添加 3×3 卷積塊。 (2)在線性投影之前添加一個 3×3 卷積塊。此外,還可以將其與去掉附加卷積塊的情況進行比較,在線性投影后添加 3×3 卷積塊的方法(1) 的 性能略優于其他兩種方案。
補丁嵌入法
傳統的補丁嵌入是將補丁映射到標記嵌入的線性投影。除了這種方法,我們還考慮了另一種將圖像映射到標記嵌入的方法,即使用 3 × 3 卷積塊堆疊,然后再使用 1 × 1 卷積塊。但是,如圖 2(d) 所示,傳統的補丁嵌入法效果更好,因此最終模型采用了這種方法。
位置嵌入方法
本文使用的是原 ViT 中提出的一維可學習位置嵌入。 也有一種替代方法,即二維正弦位置嵌入,一維可學習位置嵌入的效果更好。我們也嘗試過不使用位置嵌入,但該模型無法生成清晰的圖像,這表明位置信息對圖像生成非常重要。
3.2 網絡深度、寬度和補丁大小的影響
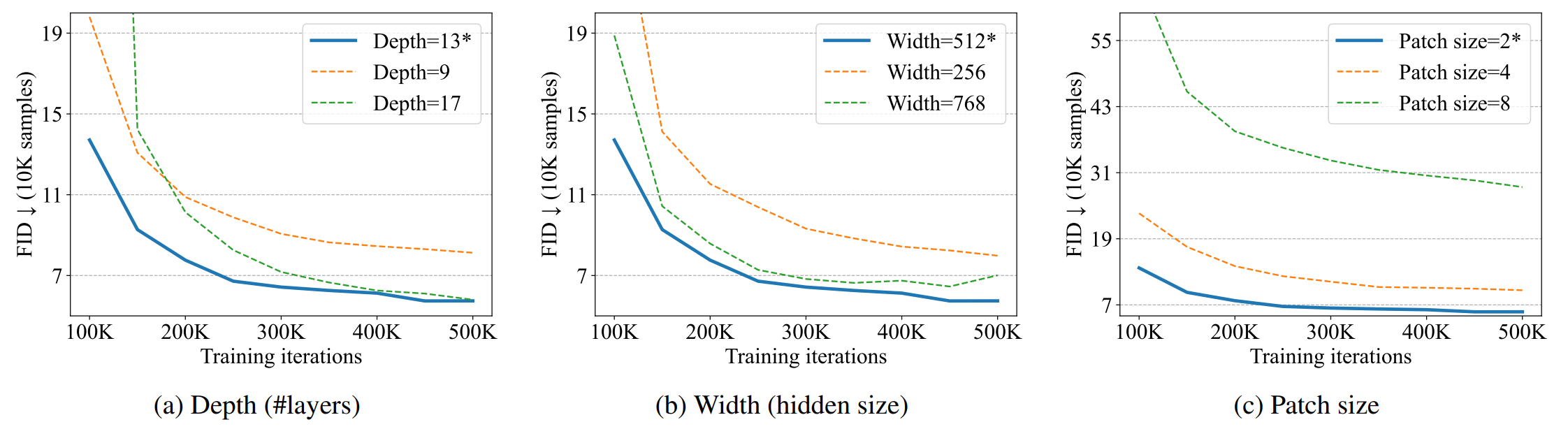
這里,我們在 CIFAR10 中研究了 U-ViT 的縮放特性,以考察層數、寬度和貼片尺寸的影響。如上圖所示,將層數從 9 層增加到 13 層可提高性能,但對于深度超過 17 層的模型則沒有影響。同樣,增加寬度也能提高性能,但超過一定寬度就沒有效果了。
減小貼片尺寸可以提高性能,但低于一定尺寸時性能就會下降。在擴散模型中,小補丁尺寸被認為適合低水平噪聲預測任務。另一方面,對于高分辨率圖像來說,使用小尺寸貼片的成本較高,因此必須先將圖像轉換為低維潛在表示,然后再用 U-ViT 進行建模。
4.試驗
4.1 數據集和設置
U-ViT 的有效性在三個任務中進行了測試:無條件圖像生成、類條件圖像生成和文本到圖像生成。
無條件圖像生成實驗在 CIFAR10(50,000 幅圖像)和 CelebA 64×64 (162,770 幅圖像)上進行。對于類別條件圖像生成,在64×64 和 256×256ImageNet 數據集(包含來自 1,000 個不同類別的 1,281,167 幅訓練圖像)和 512×512 分辨率數據集上進行了實驗。MS-COCO (82,783 幅訓練圖像和 40,504 幅驗證圖像)用于文本到圖像的訓練。
在生成256 × 256 和 512 × 512分辨率的高分辨率圖像時,使用由潛在擴散模型(Latent diffusion models,LDM)[Rombach et.al, 2022]提供的預訓練圖像自動編碼器,分別將 32 × 32 和 64 × 64 分辨率的潛在表征分別生成 32 x 32 和 64 x 64 分辨率的潛表征。然后使用 U-ViT 對這些潛表征進行建模。
在MS-COCO 中生成文本到圖像時,使用 CLIP 文本編碼器將離散文本轉換為嵌入序列,然后將這些嵌入序列作為標記序列輸入 U-ViT。
4.2 無條件和類條件圖像生成

表 1.無條件圖像生成和類別條件圖像生成的結果
在這里,U-ViT 與之前基于 U-Net 的擴散模型和 GenViT 進行了比較,GenViT 是一種較小的 ViT,它沒有長跳接,并在歸一化層之前加入了時間。FID 分數用于衡量圖像質量。
如表 1 所示,U-ViT 在無條件的 CIFAR10 和 CelebA 64×64 中表現出與 U-Net 相當的性能,并且比 GenViT 性能更好。對于有類別條件的 ImageNet 64×64,我們首先嘗試了 U-ViT-M 配置,參數為 131M。如表 1 所示,其 FID 為 5.85,優于使用 U-Net 且參數為 100M 的 IDDPM 6.92。為了進一步提高性能,我們采用了 U-ViT-L 配置(287M 個參數),將 FID 從 5.85 提高到 4.26。
在有類別條件的 ImageNet 256×256 中,U-ViT 的最佳 FID 為 2.29,優于之前的擴散模型。表 2 顯示,在使用相同采樣器的不同采樣步驟中,U-ViT 的表現優于 LDM。U-ViT 的表現也優于 VQ-擴散模型,后者是一種以變壓器為骨干的離散擴散模型。同樣,在參數和計算成本相同的情況下,U-ViT 也優于 UNet。
對于帶有類別條件的 ImageNet 512×512,U-ViT 的表現優于直接對圖像像素建模的 ADM-G。圖 4 顯示了 ImageNet 256×256 和 512×512 的部分樣本以及其他數據集的隨機樣本,證實了圖像的高質量和清晰度。
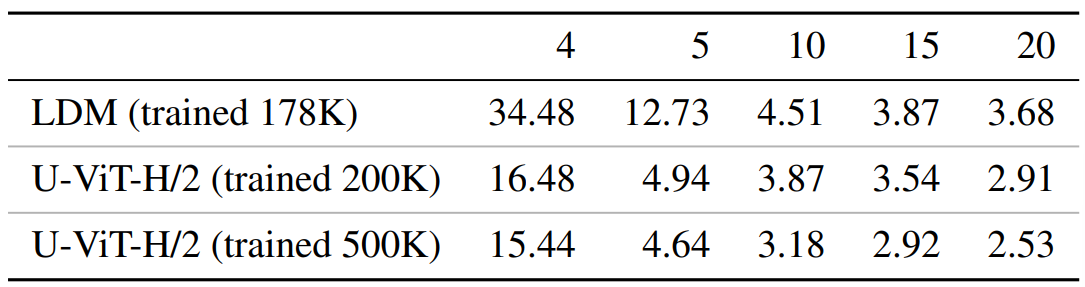
表 2:ImageNet 256×256 不同采樣步數下的 FID 結果。

4.3 使用 MS-COCO 生成文本到圖像
這里,我們使用 MS-COCO 數據集來評估 U-ViT 在文本到圖像生成任務中的表現。我們還使用 U-Net 訓練了另一個潛在擴散模型,模型大小與 U-ViT 相同,并與 U-ViT 進行了比較。
FID 分數用于衡量圖像質量:從 MS-COCO 驗證集中隨機選取 30K 個提示,并利用這些提示生成樣本來計算 FID。如表 3 所示,即使在生成模型的訓練過程中不需要訪問大型外部數據集,U-ViT 也能獲得最先進的 FID。通過將層數從 13 層增加到 17 層,U-ViT-S(Deep)可以獲得更好的 FID。
圖 6 顯示了 U-Net 和 U-ViT 使用相同的隨機種子生成的樣本,以進行定性比較;U-ViT 生成的樣本質量更高,圖像內容與文本的匹配度更高。
例如,給定文本 “棒球運動員揮棒擊球”,U-Net 不會生成球棒或球,而 U-ViT 會生成球,U-ViT-S(Deep)會進一步生成球棒。這可能是由于與 U-Net 相比,U-ViT 中文本和圖像之間每一層的交互更為頻繁。
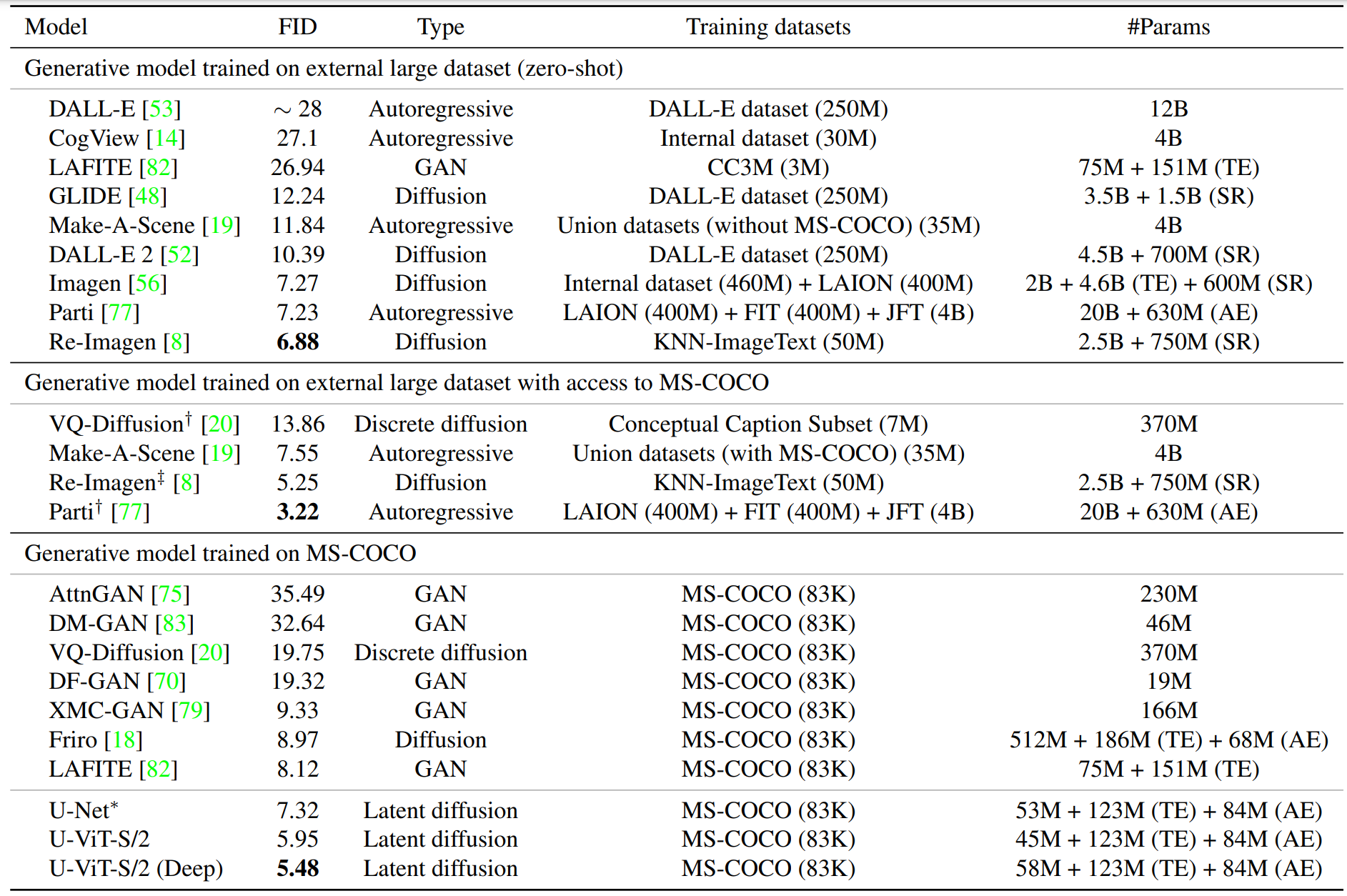
表 3.MS-COCO 的實驗結果

5. 結論
U-ViT 將所有輸入(時間、條件和噪聲圖像片段)視為標記,并在淺層和深層之間采用長跳轉連接。U-ViT 已在無條件和有條件圖像生成以及文本到圖像生成等任務中進行了評估。
U-ViT 的性能與類似規模的基于 CNN 的 U-Nets 不相上下,甚至更好。這些結果表明,長跳接對于基于擴散的圖像建模非常重要,而基于 CNN 的 U-Nets 并不總是需要向下向上采樣運算符。
U-ViT 可以為未來的擴散建模骨干研究提供信息,并有利于在具有不同模式的大型數據集中進行生成建模。



)






![告別 Dart 中的 Future.wait([])](http://pic.xiahunao.cn/告別 Dart 中的 Future.wait([]))








