Diffusion Models專欄文章匯總:入門與實戰
SYMPLEX: Controllable Symbolic Music Generation using Simplex Diffusion with Vocabulary Priors
http://arxiv.org/abs/2405.12666v1?

本文介紹了一種新的符號音樂生成方法,名為SYMPLEX,它基于單純形擴散(Simplex Diffusion,SD)模型,通過操作概率分布而非信號空間來生成音樂。該方法利用詞匯表先驗(vocabulary priors)來控制音樂的生成過程,允許在不進行任務特定模型調整或應用外部控制的情況下,對時間和音高進行填充、選擇樂器等。
SYMPLEX模型采用SSD-LM作為基礎,SSD-LM是一種基于窗口的單純形擴散模型,用于生成任意長度的自然語言序列。與SSD-LM處理序列不同,SYMPLEX操作的是一組包含9個屬性的音符事件集合。模型通過訓練神經網絡從噪聲概率中恢復數據樣本,并在生成新樣本時,從隨機初始化的概率開始,逐步迭代細化。此外,通過將詞匯表先驗與當前概率相乘并重新歸一化,可以在不依賴外部模型的情況下控制生成過程。
作者從MetaMIDI數據集中提取了4小節多樂器MIDI循環,并構建了一個包含約25萬個循環的數據集。他們使用了一種無序集合表示法來表示MIDI循環,每個音符事件包含9個屬性。實驗中,SYMPLEX在多個任務上進行了演示,包括無條件生成、有條件生成以及多種編輯任務。作者還討論了未來工作,包括如何避免根據不同生成場景調整參數設置,以簡化工作流程。
ReasonPix2Pix: Instruction Reasoning Dataset for Advanced Image Editing
http://arxiv.org/abs/2405.11190v1

本文介紹了一個名為ReasonPix2Pix的新型圖像編輯數據集,旨在提升生成模型在遵循人類指令進行圖像編輯時的推理能力。現有的圖像編輯模型通常只能理解明確具體的指令,但在處理隱含或定義不明確的指令時表現出推理能力的不足。為了解決這一問題,研究者們創建了ReasonPix2Pix,這是一個包含推理指令、更真實圖像和輸入與編輯圖像之間更大變化的數據集。
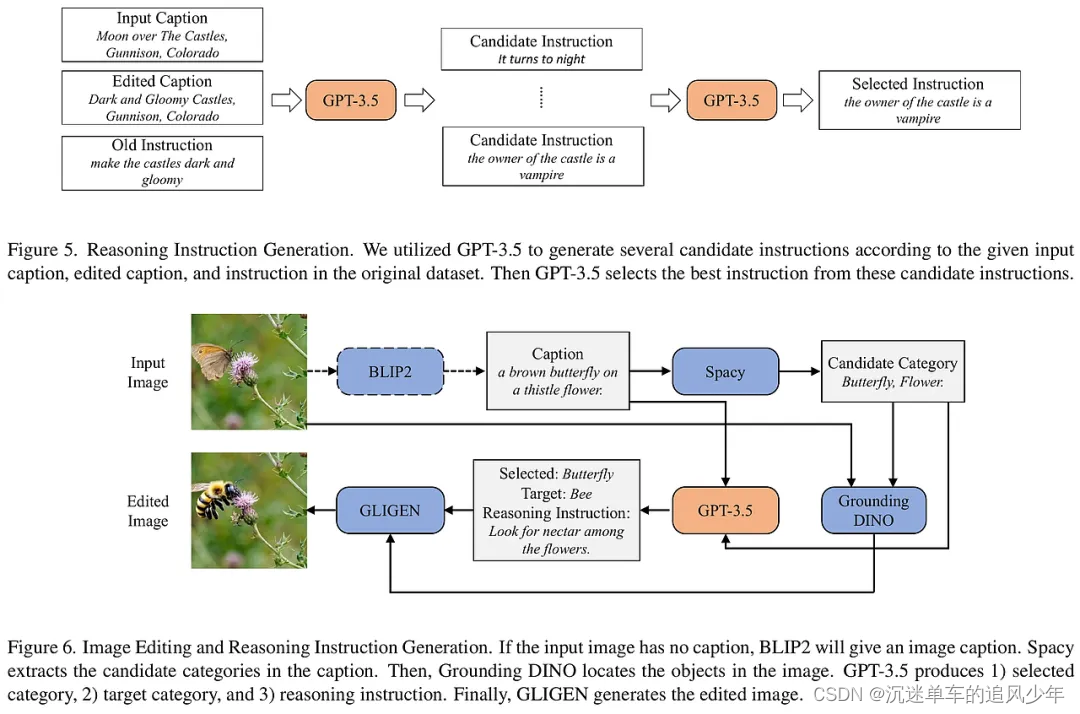
ReasonPix2Pix數據集通過三個部分來增強模型的推理能力:第一部分利用InstructPix2Pix數據集中的圖像對,生成推理指令;第二部分和第三部分則通過生成新的編輯圖像和指令來提升模型對現實圖像的編輯能力。研究者們還結合了多模態大型語言模型(MLLM)和擴散模型來構建一個簡單的框架,該框架能夠理解指令的明確或隱含意圖,并生成符合指令的輸出圖像。

在實驗部分,研究者們使用了GPT-3.5-turbo生成數據集,并采用了Stable Diffusion v1.5和LLaVA-7Bv1.5進行微調。他們將圖像大小調整為256×256,并在訓練期間使用了基礎學習率。通過定性和定量的實驗結果,證明了ReasonPix2Pix在不需要推理和需要推理的指令編輯任務中均展現出優越的性能。用戶研究也表明,當指令變得更加隱含時,ReasonPix2Pix與先前方法相比具有更大的優勢。最后,研究者們討論了數據集的局限性,并指出了數據集規模因API成本而受限,但提供了清晰的數據生成流程,以便研究人員可以擴展數據集規模。
Evolving Storytelling: Benchmarks and Methods for New Character Customization with Diffusion Models
http://arxiv.org/abs/2405.11852v1
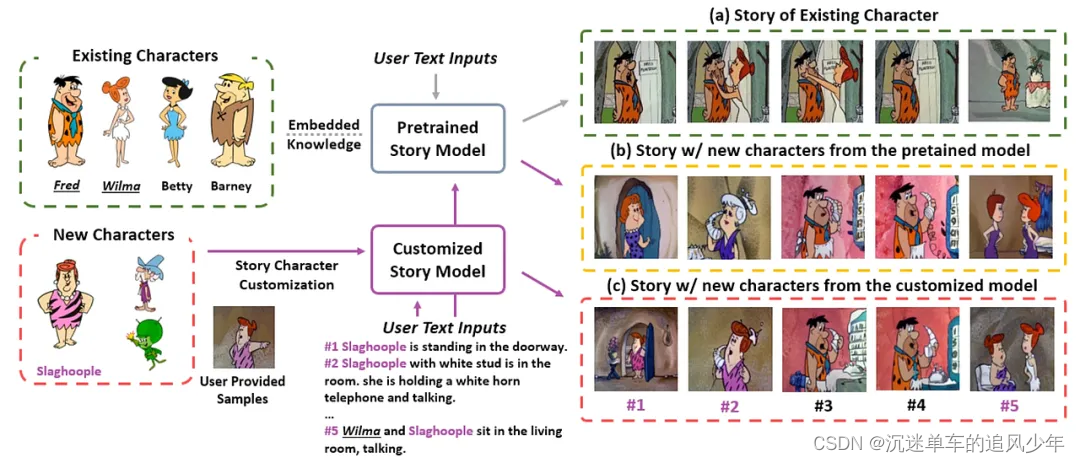
本文探討了如何將新角色有效地融入現有敘事中,并保持角色一致性的問題,特別是在數據有限的情況下。作者指出,現有的故事可視化生成模型在整合新角色時存在兩大限制:缺乏合適的基準測試和新舊角色區分的挑戰。為了解決這些問題,作者提出了"NewEpisode"基準測試,包含經過改進的數據集,用于評估生成模型在僅使用單一示例故事生成新故事的能力。


作者引入了"EpicEvo"方法,這是一種定制的擴散模型,用于視覺故事生成。"EpicEvo"通過一個新穎的對抗性角色對齊模塊,在擴散過程中逐步對齊生成圖像與新角色的示例圖像,同時應用知識蒸餾來防止忘記角色和背景細節。這種方法使得模型能夠學習如何生成包含現有角色和/或新角色的故事,并且通過對抗性角色對齊模塊鼓勵模型獨特地生成角色,并通過從預訓練模型中提取知識來保持模型先驗。
為了驗證"EpicEvo"的有效性,作者在"NewEpisode"基準測試上進行了定量和定性的研究。實驗結果表明,"EpicEvo"在基準測試上的定量表現超過了現有的基線,并且通過質量研究確認了其在擴散模型中定制視覺故事生成的優越性。總結來說,"EpicEvo"提供了一種有效的方法,僅使用一個示例故事就能融入新角色,為諸如連載卡通等應用開辟了新的可能性。
TriLoRA: Integrating SVD for Advanced Style Personalization in Text-to-Image Generation
http://arxiv.org/abs/2405.11236v1
本文提出了一種名為TriLoRA的新方法,旨在改進文本到圖像生成模型的微調過程,以實現更高級的風格個性化。現有的深度學習模型,如Stable Diffusion,在視覺藝術創作中應用廣泛,但面臨過擬合、生成結果不穩定和難以精確捕捉創造者所需特征等挑戰。TriLoRA通過將奇異值分解(SVD)整合到低秩適應(LoRA)參數更新策略中,有效降低了過擬合風險,增強了模型輸出的穩定性,并更準確地捕捉到創造者所需的微妙特征調整。
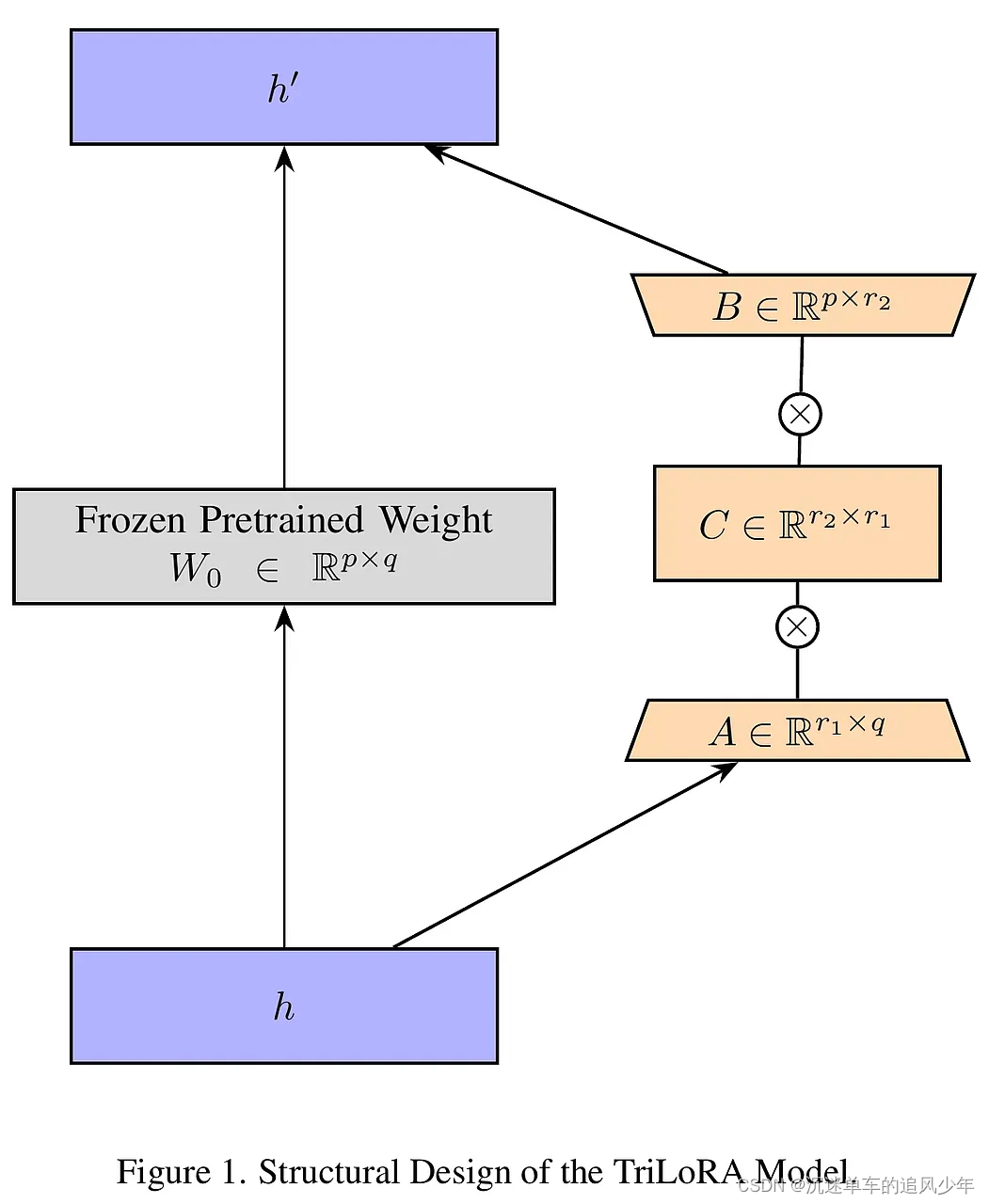
TriLoRA是在LoRA框架內引入SVD的概念,通過訓練兩個適配器:一個標準低秩適配器(LoRA)和一個更小的適配器,這兩個適配器相對于原始預訓練權重并行訓練。該方法的創新之處在于使用緊湊奇異值分解(Compact SVD)來確定創造者關注的特定特征數量,從而提供更精確的選擇空間。在TriLoRA框架中,通過將Compact SVD整合到LoRA中,優化了權重矩陣的更新,使得模型在保持較低參數數量的同時,提高了對新任務的適應性。

為了評估TriLoRA和LoRA在特定風格或主題中的適應性,作者構建了兩個數據集:一個包含多種幻想生物的Pokemon數據集,另一個是專注于特定風格服裝的GAC數據集。實驗采用了標準化Fréchet Inception距離(Normalized FID)和CLIP分數作為主要的定量評估指標,并輔以用戶研究以提供定性見解。實驗結果表明,TriLoRA在多個數據集上的表現優于LoRA,具有更好的模型泛化能力和創造性表達,同時保持了效率和資源限制下的優異性能。用戶研究結果也支持了TriLoRA在文本視覺一致性和視覺吸引力方面的優勢。


,如何檢測?)













 HT-600D)
-序數理論)

