整體比較分散,可能很多源碼都需要修改,需要有耐心。
一、數據準備
PS
調研后,上手容易代碼比較簡潔的是:https://github.com/Niki173/C3D/tree/main
因為源碼很多參數都寫死到了源碼中,沒有解耦,并且默認只支持ucf101和hmdb51兩個數據集,所以建議最快的方式是將自己的數據集命名為ucf101然后修改對應的參數。以下均以此為前提進行說明。
1、數據組織結構
一般建議是準備原始視頻文件,然后源碼會自動拆幀為圖片,這里以ucf101為例
抽幀前的視頻組織形式,不區分train/val/test, 不同類別的視頻數據放到不同的文件夾中。
Ucf101
—class_name_1
——video_1
——…
—...
PS:這里要注意視頻長度不要過長,因為源碼是一次性將一個視頻所有幀讀到內存然后進行crop指定幀數(16幀)和大小(112),所以也要看你的特征不被crop掉(源碼是先縮放到128*171然后隨機crop 112*112)
源碼處理完后的路徑如下,要注意默認源碼會按照4幀間隔,6:2:2(近似)分割train/val/test集合。
Ucf101
—train
——class_name_1
———video_frames_dir_1
———…
——...
—val
——class_name_1
———video_frames_dir_1
———…
——…
—test
——class_name_1
———video_frames_dir_1
———…
——...
2、修改數據源和類別數(必選)
https://github.com/Niki173/C3D/blob/main/train.py#L28
建議復用ucf101,只修改對應的num_classes變量的值。

3、修改label信息(必選)
https://github.com/Niki173/C3D/blob/main/dataloaders/dataset.py#L58
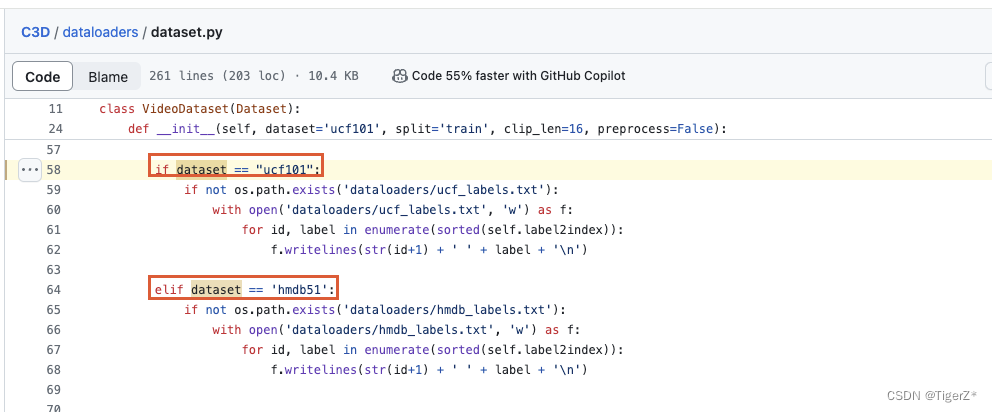
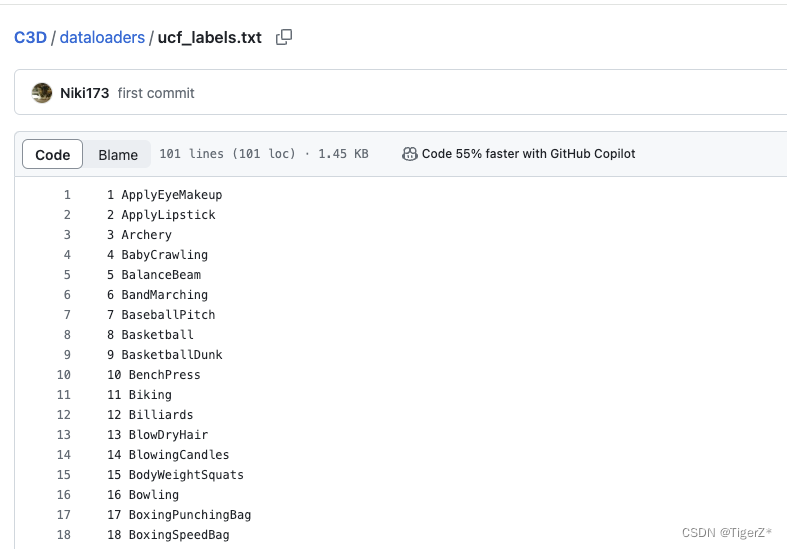
源碼僅僅實現了ucf101、hmdb51,這里有兩種方式,最簡單的就是復用ucf101的名字,只不過是自己的數據,然后刪除掉源碼的“dataloaders/ucf_labels.txt ”文件,讓源碼自己根據數據重新生成,也可以自己修改這個文件,文件的格式如下:
4、修改視頻文件路徑(必須)
這里源碼的處理邏輯是自動一級一級檢查圖片幀目錄,是否存在,并且會檢查第一個類別的第一個視頻的圖片幀的分辨率是否符合要求。
https://github.com/Niki173/C3D/blob/main/mypath.py

5、修改視頻幀尺寸(可選)
邏輯是抽幀的時候resize成這個尺寸,然后訓練的時候中心crop成112。源碼需要修改兩個地方。
1)https://github.com/Niki173/C3D/blob/main/dataloaders/dataset.py#L31

2)https://github.com/Niki173/C3D/blob/main/dataloaders/dataset.py#L105

? ? 6、修改歸一化特征值(可選)
?? ?https://github.com/Niki173/C3D/blob/main/dataloaders/dataset.py#L208
?? ? ?
?
7、修改是否需要test(可選)
一般現實工程數據較少時或者上線有其他測試集,建議關閉test分割,方式就是注銷相關代碼,下面標紅框。
https://github.com/Niki173/C3D/blob/main/dataloaders/dataset.py#L115
?
https://github.com/Niki173/C3D/blob/main/train.py#L23

https://github.com/Niki173/C3D/blob/main/train.py#L100
注銷紅框


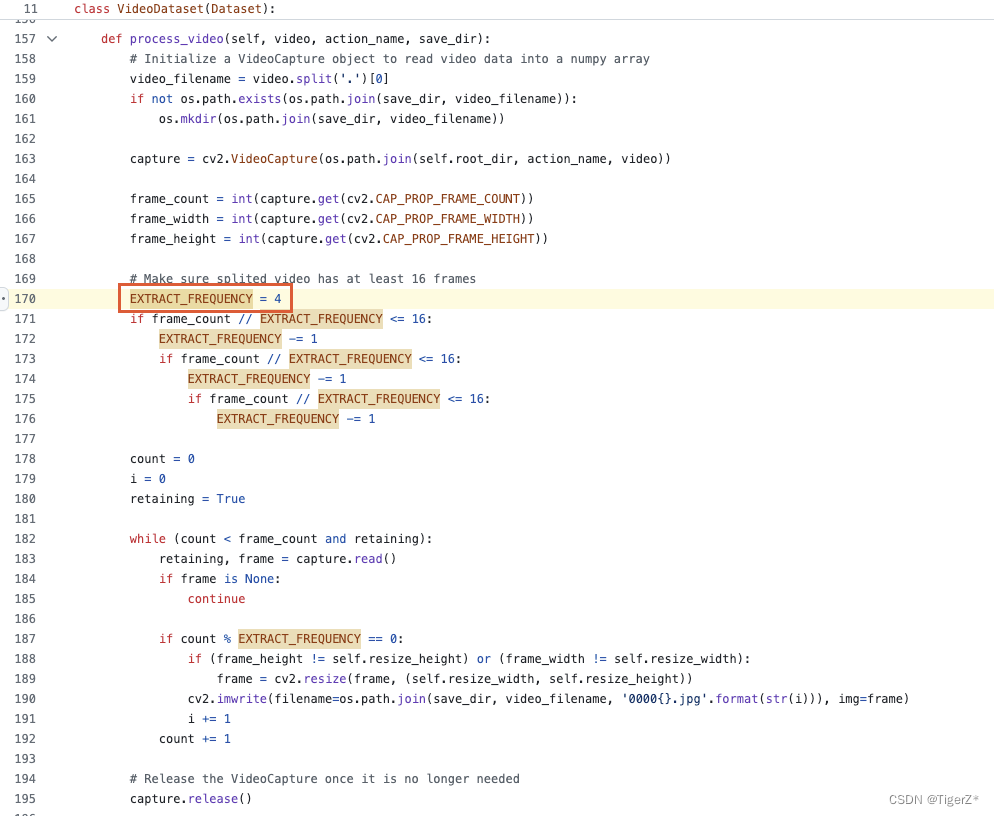
8、修改抽幀間隔(可選)
默認是4秒。
https://github.com/Niki173/C3D/blob/main/dataloaders/dataset.py#L170
?二、訓練超參數
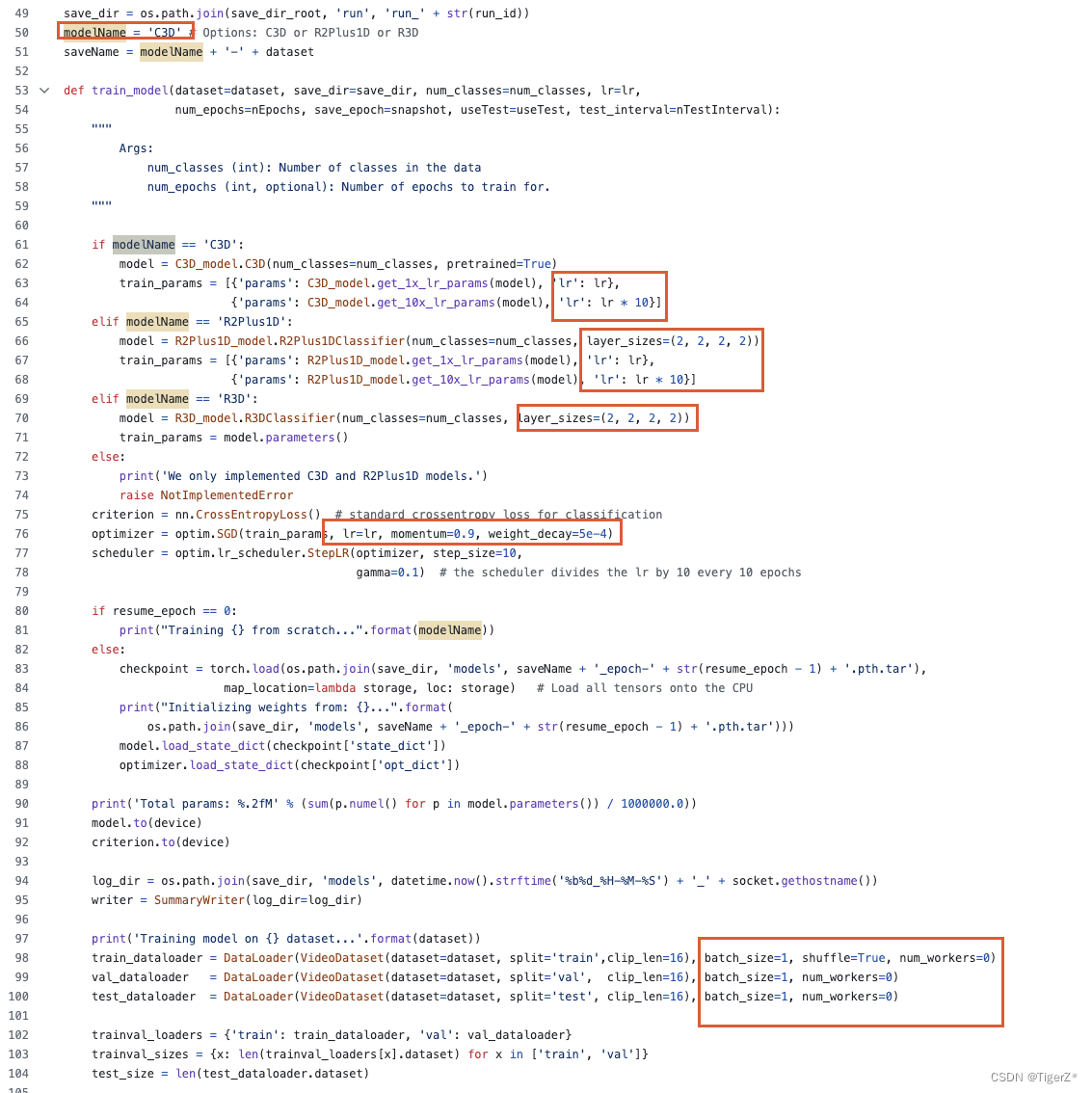
https://github.com/Niki173/C3D/blob/main/train.py#L21

三、網絡結構
? ? 1、C3D結構

? ? 2、R(2+1)D結構

? ? 3、區別
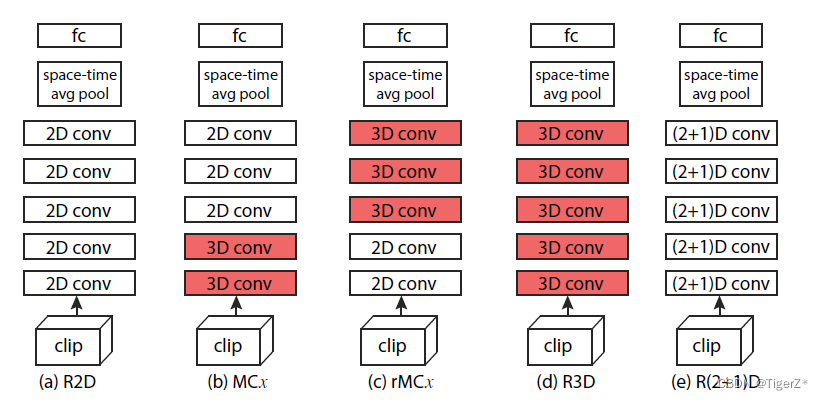
? ??1)R2D模塊就是傳統的2d卷積,將輸入c×l×h×w看作是cl×h×w(把多張當作一整張),只是將2d卷積作用于multi-frames上。
?? ?2)f-R2D,采取R2D相反的方式,分別對每幀做操作,在最后全局池化層在做所有幀的信息融合。
?? ?3)C3D:就是將時間維度單獨成一維。網絡結構如上面的圖。
?? ?4)R3D模塊就是前面講的C3D模塊,只不過是放到ResNet網絡中。
?? ?5)R(2+1)D:作者設計了2d卷積和1d卷積filter個數的匹配公式。相比于R3D,雖然參數沒變,但由于R(2+1)D添加更多Relu激活層,模型的表達能力應該更強,同時也更容易訓練優化。
?? ?6)P3D:R(2+1)D更接近P3D-A,把R(2+1)D都設計為相同的block,但P3D的第一層使用的是2d卷積。

?? ?
開源實現
https://github.com/HHTseng/video-classification
https://github.com/kenshohara/3D-ResNets-PyTorch
幾個不同網絡區別:[論文筆記] C3D | P3D | R2D - 知乎
C3D代碼總結(Pytorch)-CSDN博客



)

的數據回歸預測(多輸入多輸出))

)
(二分法重要例題))







)


