目錄
一、資源限制
1、資源限制定義:
2、資源限制request和limit資源約束
3、Pod和容器的資源請求和限制
4、官方文檔示例
5、CPU資源單位
6、內存資源單位
7、資源限制實例
①編寫yaml資源配置清單
②釋放內存(node節點,以node01為例子)
③注意:
④創建資源
⑤跟蹤查看pod狀態
⑥查看容器日志
⑦刪除pod
⑧修改yaml配置資源清單,提高mysql資源限制
⑨然后再次創建資源
⑩跟蹤查看pod狀態
11查看pod詳細信息
12查看node01節點的詳細信息
二、健康檢查
1、健康檢查的定義
2、探針的三種規則
①livenessProbe存活探針
②readinessProbe就緒探針
③startupProbe啟動探針(1.17版本新增)
④注意:
3、Probe支持三種檢查方法:
①exec:
②tcpSocket:
③httpGet:
4、探測結果
5、exec方式
示例2、
6、httpGet方式
示例2、
7、tcpSocket方式
三、總結
1、探針
2、檢查方式
3、常用的探針可選參數
四、拓展
1、Pod的狀態
2、Container生命周期
一、資源限制
1、資源限制定義:
當定義Pod時可以選擇性的為每個容器設定所需要的資源數量。最常見的可設定資源是CPU和內存大小,以及其他類型的資源。
2、資源限制request和limit資源約束
①當為 Pod 中的容器指定了 request 資源時,調度器就使用該信息來決定將 Pod 調度到哪個節點上。當還為容器指定了 limit 資源時,kubelet 就會確保運行的容器不會使用超出所設的 limit 資源量。kubelet 還會為容器預留所設的 request 資源量, 供該容器使用。
②如果 Pod 運行所在的節點具有足夠的可用資源,容器可以使用超出所設置的 request 資源量。不過,容器不可以使用超出所設置的 limit 資源量。
③如果給容器設置了內存的 limit 值,但未設置內存的 request 值,Kubernetes 會自動為其設置與內存 limit 相匹配的 request 值。 類似的,如果給容器設置了 CPU 的 limit 值但未設置 CPU 的 request 值,則 Kubernetes 自動為其設置 CPU 的 request 值 并使之與 CPU 的 limit 值匹配。
3、Pod和容器的資源請求和限制
官方示例網站:Resource Management for Pods and Containers | Kubernetes
定義創建容器時預分配的CPU資源
spec.containers[].resources.requests.cpu
定義創建容器時預分配的內存資源
spec.containers[].resources.requests.memory
定義創建容器時預分配的巨頁資源
spec.containers[].resources.requests.hugepages-<size>
定義cpu的資源上限
spec.containers[].resources.limits.cpu
定義內存的資源上限
spec.containers[].resources.limits.memory
定義巨頁的資源上限
spec.containers[].resources.limits.hugepages-<size>4、官方文檔示例
apiVersion: v1
kind: Pod
metadata:name: frontend
spec:containers:- name: appimage: images.my-company.example/app:v4env:- name: MYSQL_ROOT_PASSWORDvalue: "password"resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"- name: log-aggregatorimage: images.my-company.example/log-aggregator:v6resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"Pod有兩個Container。每個Container 的請求為 0.25 cpu 和 64MiB(226 字節)內存, 每個容器的資源約束為 0.5 cpu 和 128MiB 內存。 你可以認為該 Pod 的資源請求為 0.5 cpu 和 128 MiB 內存,資源限制為 1 cpu 和 256MiB 內存。
5、CPU資源單位
CPU 資源的 request 和 limit 以 cpu 為單位。Kubernetes 中的一個 cpu 相當于1個 vCPU(1個超線程)。
Kubernetes 也支持帶小數 CPU 的請求。spec.containers[].resources.requests.cpu 為 0.5 的容器能夠獲得一個 cpu 的 ?、一半 CPU 資源(類似于Cgroup對CPU資源的時間分片)。表達式 0.1 等價于表達式 100m(毫核),表示每 1000 毫秒內容器可以使用的 CPU 時間總量為 0.1*1000 毫秒。
Kubernetes 不允許設置精度小于 1m 的 CPU 資源。?
6、內存資源單位
內存的 request 和 limit 以字節為單位。可以以整數表示,或者以10為底數的指數的單位(E、P、T、G、M、K)來表示, 或者以2為底數的指數的單位(Ei、Pi、Ti、Gi、Mi、Ki)來表示。
如:1KB=10^3=1000,1MB=10^6=1000000=1000KB,1GB=10^9=1000000000=1000MB
1KiB=2^10=1024,1MiB=2^20=1048576=1024KiB
注意:在買硬盤的時候,操作系統報的數量要比產品標出或商家號稱的小一些,主要原因是標出的是以 MB、GB為單位的,1GB 就是1,000,000,000Byte,而操作系統是以2進制為處理單位的,因此檢查硬盤容量時是以MiB、GiB為單位,1GiB=2^30=1,073,741,824,相比較而言,1GiB要比1GB多出1,073,741,824-1,000,000,000=73,741,824Byte,所以檢測實際結果要比標出的少一些。
7、資源限制實例
①編寫yaml資源配置清單
[root@master ~]# mkdir /opt/test
[root@master ~]# cd /opt/test
[root@master test]# vim test1.yamlapiVersion: v1
kind: Pod
metadata:name: test1
spec:containers:- name: webimage: nginxenv:- name: WEB_ROOT_PASSWORDvalue: "password"resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"- name: dbimage: mysqlenv:- name: MYSQL_ROOT_PASSWORDvalue: "password"resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"
②釋放內存(node節點,以node01為例子)
由于mysql對于內存的使用要求較高,因此需要先檢查內存的可用空間是否能夠滿足mysql的正常運行,若剩余內存不夠,可以對其進行操作釋放。
查看內存
free -mh
內存總量為3.7G,實際使用1.1G,因此可有內存應該為2.6G左右。但是由于有1.4G的內存被用于緩存,free為1.2G。所以不需要釋放內存。
這里可以手動釋放緩存
echo [1\2\3] > /proc/sys/vm/drop_caches0:0是系統默認值,默認情況下表示不釋放內存,由操作系統自動管理
1:釋放頁緩存
2:釋放dentries和inodes
3:釋放所有緩存
③注意:
如果因為是應用有像內存泄露、溢出的問題,從swap的使用情況是可以比較快速可以判斷的,但free上面反而比較難查看。相反,如果在這個時候,我們告訴用戶,修改系統的一個值,“可以”釋放內存,free就大了。用戶會怎么想?不會覺得操作系統“有問題”嗎?所以說,既然核心是可以快速清空buffer或cache,也不難做到(這從上面的操作中可以明顯看到),但核心并沒有這樣做(默認值是0),我們就不應該隨便去改變它。
一般情況下,應用在系統上穩定運行了,free值也會保持在一個穩定值的,雖然看上去可能比較小。當發生內存不足、應用獲取不到可用內存、OOM錯誤等問題時,還是更應該去分析應用方面的原因,如用戶量太大導致內存不足、發生應用內存溢出等情況,否則,清空buffer,強制騰出free的大小,可能只是把問題給暫時屏蔽了。
④創建資源
kubectl apply -f tets1.yaml
⑤跟蹤查看pod狀態
kubectl get pod -o wide -w

OOM(OverOfMemory)表示服務的運行超過了我們所設定的約束值。
Ready:2/2,status:Running說明該pod已成功創建并運行,但運行過程中發生OOM問題被kubelet殺死并重新拉起新的pod。
⑥查看容器日志
kubectl logs test1 -c web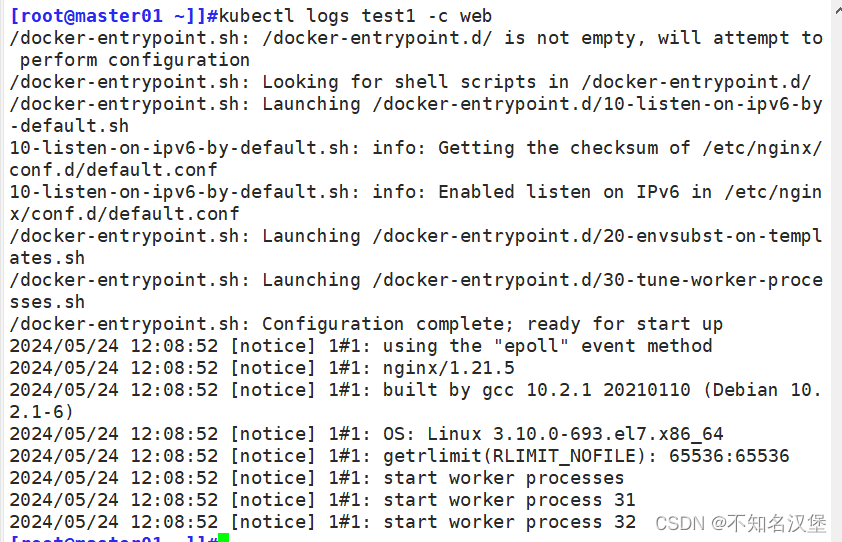
nginx啟動正常,然后查看mysql日志
kubectl logs test1 -c db

容器問題為mysql
⑦刪除pod
kubectl delete -f test1.yaml
⑧修改yaml配置資源清單,提高mysql資源限制
[root@master test]# vim test1.yaml apiVersion: v1
kind: Pod
metadata: name: test1
spec: containers: - name: web image: nginx env: - name: WEB_ROOT_PASSWORD value: "password" resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" - name: db image: mysql env: - name: MYSQL_ROOT_PASSWORD value: "password" resources: requests: memory: "512Mi" cpu: "0.5" limits: memory: "1024Mi" cpu: "1"
⑨然后再次創建資源
kubectl apply -f test1.yaml
⑩跟蹤查看pod狀態
kubectl get pod -o wide -w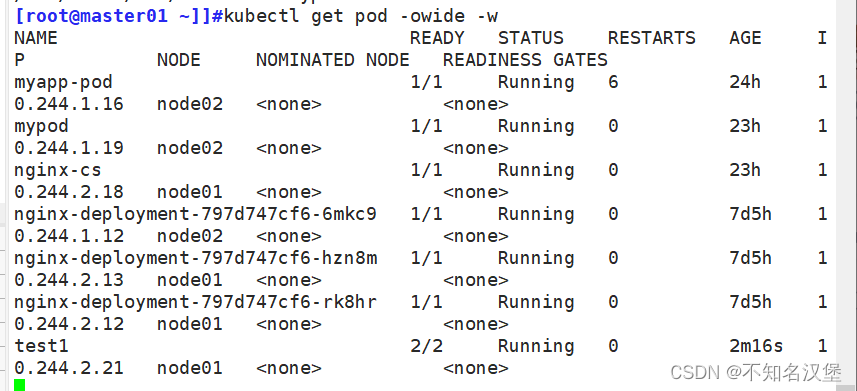
11查看pod詳細信息
[root@k8s test]# kubectl describe pod test1

12查看node01節點的詳細信息
kubectl describe nodes node01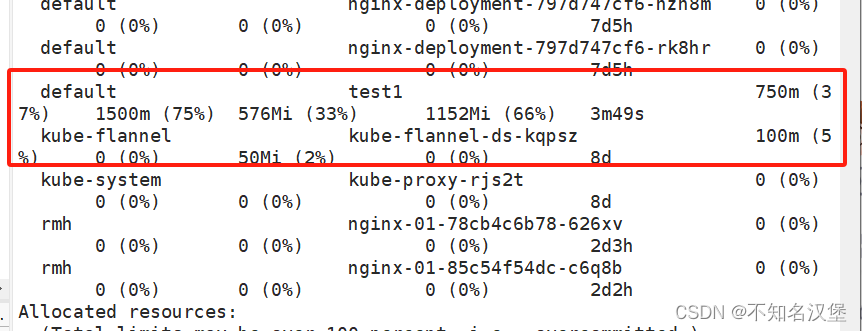
二、健康檢查

1、健康檢查的定義
健康檢查:又稱為探針(Probe),探針是由kubelet對容器執行的定期診斷。
2、探針的三種規則
①livenessProbe存活探針
判斷容器是否正在運行。如果探測失敗,則kubelet會殺死容器,并且容器將根據 restartPolicy 來設置 Pod 狀態。 如果容器不提供存活探針,則默認狀態為Success。
②readinessProbe就緒探針
判斷容器是否準備好接受請求。如果探測失敗,端點控制器將從與 Pod 匹配的所有 service 址endpoints 中剔除刪除該Pod的IP地。 初始延遲之前的就緒狀態默認為Failure。如果容器不提供就緒探針,則默認狀態為Success。
③startupProbe啟動探針(1.17版本新增)
判斷容器內的應用程序是否已啟動,主要針對于不能確定具體啟動時間的應用。如果配置了 startupProbe 探測,在則在 startupProbe 狀態為 Success 之前,其他所有探針都處于無效狀態,直到它成功后其他探針才起作用。 如果 startupProbe 失敗,kubelet 將殺死容器,容器將根據 restartPolicy 來重啟。如果容器沒有配置 startupProbe, 則默認狀態為 Success。
④注意:
以上規則可以同時定義。在readinessProbe檢測成功之前,Pod的running狀態是不會變成ready狀態的。
3、Probe支持三種檢查方法:
①exec:
在容器內執行指定命令。如果命令退出時返回碼為0則認為診斷成功。
②tcpSocket:
對指定端口上的容器的IP地址進行TCP檢查(三次握手)。如果端口打開,則診斷被認為是成功的。
③httpGet:
對指定的端口和路徑上的容器的IP地址執行HTTPGet請求。如果響應的狀態碼大于等于200且小于400,則診斷被認為是成功的
4、探測結果
每次探測都將獲得一下三種結果之一:
①成功:容器通過了診斷
②失敗:容器未通過診斷
③未知:診斷失敗,因此不會采取任何行動
5、exec方式
vim exec.yamlapiVersion: v1
kind: Pod
metadata:labels:test: liveness #為了健康檢查定義的標簽name: liveness-exec
spec: #定義了Pod中containers的屬性containers:- name: livenessimage: busyboxargs: #傳入的命令- /bin/sh- -c- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy;sleep 600livenessProbe:exec:command:- cat- /tmp/healthyinitialDelaySeconds: 5 #表示pod中容器啟動成功后,多少秒后進行健康檢查 periodSeconds: 5 #在首次健康檢查后,下一次健康檢查的間隔時間 5s
在配置文件中,可以看到Pod具有單個Container。該perioSeconds字段指定kubelet應該每5秒執行一次活動性探測。該initiaDelaySeconds字段告訴kubelet在執行第一個探測之前應該等待5秒。為了執行探測,kubelet cat /tmp/healthy在容器中執行命令。如果命令成功執行,則返回0,并且kubelet認為Container仍然重要。如果命令返回非0值,則kubelet將殺死Container并重啟它。
①在這個配置文件中,可以看到Pod只有一個容器。
②容器中的command字段表示創建一個/tmp/live文件后休眠30秒,休眠結束后刪除該文件,并休眠10分鐘。
③僅使用livenessProbe存活探針,并使用exec檢查方式,對/tmp/live文件進行存活檢測。
④initialDelaySeconds字段表示kubelet在執行第一次探測前應該等待5秒。
⑤periodSeconds字段表示kubelet每隔5秒執行一次存活探測。



示例2、
vim exec.yaml
apiVersion: v1
kind: Pod
metadata:name: liveness-execnamespace: default
spec:containers:- name: liveness-exec-containerimage: busyboximagePullPolicy: IfNotPresentcommand: ["/bin/sh","-c","touch /tmp/live ; sleep 30; rm -rf /tmp/live; sleep 3600"]livenessProbe:exec:command: ["test","-e","/tmp/live"]initialDelaySeconds: 1periodSeconds: 3kubectl create -f exec.yamlkubectl describe pods liveness-exec


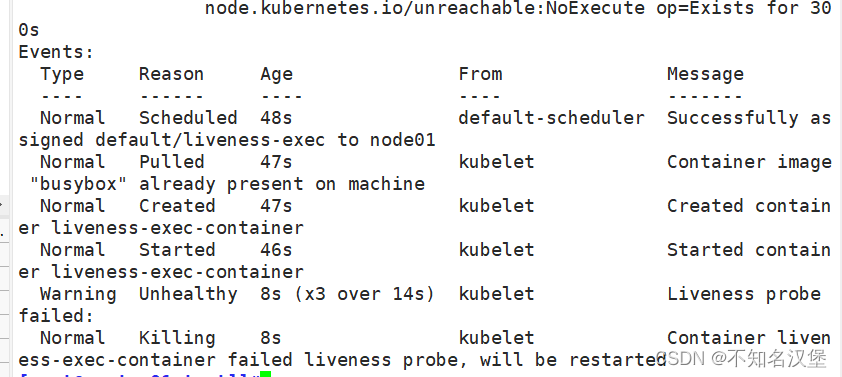

6、httpGet方式
vim httpGet.yaml
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: liveness-http
spec:containers:- name: livenessimage: k8s.gcr.io/livenessargs:- /serverlivenessProbe:httpGet:path: /healthzport: 8080httpHeaders:- name: Custom-Headervalue: AwesomeinitialDelaySeconds: 3periodSeconds: 3
在配置文件中,可以看到Pod具有單個Container。該periodSeconds字段指定kubectl應該每3秒執行一次活動性探測。該initiaDelaySeconds字段告訴kubelet在執行第一個探測之前應等待3秒。為了執行探測,kubectl將HTTP GET請求發送到Container中運行并在端口8080上偵聽的服務器。如果服務器/healthz路徑的處理程序返回成功代碼,則kubectl會認為任何大于或等于400的代碼均表示成功,其他代碼都表示失敗。
示例2、
apiVersion: v1
kind: Pod
metadata:name: liveness-httpgetnamespace: default
spec:containers:- name: liveness-httpget-containerimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80livenessProbe:httpGet:port: httppath: /index.htmlinitialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10
kubectl create -f httpget.yamlkubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.htmlkubectl get pods






httpget http://IP:80/index.html ?delay 延遲 =3 ?tomout=10s ? ?period(頻率)=3s ? succes(成功)=1 ?faulure(失敗)=3 機會 ? ? ?殺死容器
7、tcpSocket方式
定義TCP活動度探針
第三種類型的活動性探針使用TCP套接字,使用此配置,kubelet將嘗試在指定端口上打開容器的套接字。如果可以建立連接,則認為該讓其運行狀況良好,如果不能,則認為該容器是故障容器。
apiVersion: v1
kind: Pod
metadata:name: goproxylabels:app: goproxy
spec:containers:- name: goproxyimage: k8s.gcr.io/goproxy:0.1ports:- containerPort: 8080readinessProbe:tcpSocket:port: 8080initialDelaySeconds: 5periodSeconds: 10livenessProbe:tcpSocket:port: 8080initialDelaySeconds: 15periodSeconds: 20
如圖所示,TCP檢查的配置與HTTP檢查非常相似,此示例同時使用就緒和活躍度探針,容器啟動5秒后,kubelet將發送第一個就緒探測器。這些嘗試連接到goproxy端口8080上的容器。如果探測成功,則容器將標記為就緒,kubelet將繼續每10秒運行一次檢查。
除了就緒探針之外,此配置還包括活動探針。容器啟動后15秒鐘,kubelet將運行第一個活動談著,就像就緒探針一樣,這些嘗試goproxy在端口8080上連接到容器。如果活動探針失敗,則容器將重新啟動。
三、總結
1、探針
①livenessProbe(存活探針)∶判斷容器是否正常運行,如果失敗則殺掉容器(不是pod),再根據重啟策略是否重啟容器
②readinessProbe(就緒探針)∶判斷容器是否能夠進入ready狀態,探針失敗則進入noready狀態,并從service的endpoints中剔除此容器
③startupProbe∶判斷容器內的應用是否啟動成功,在success狀態前,其它探針都處于無效狀態
2、檢查方式
①exec∶使用 command 字段設置命令,在容器中執行此命令,如果命令返回狀態碼為0,則認為探測成功
②httpget∶通過訪問指定端口和url路徑執行http get訪問。如果返回的http狀態碼為大于等于200且小于400則認為成功
③tcpsocket∶通過tcp連接pod(IP)和指定端口,如果端口無誤且tcp連接成功,則認為探測成功
3、常用的探針可選參數
①initialDelaySeconds∶?容器啟動多少秒后開始執行探測
②periodSeconds∶探測的周期頻率,每多少秒執行一次探測
③failureThreshold∶探測失敗后,允許再試幾次
④timeoutSeconds?∶?探測等待超時的時間
四、拓展
1、Pod的狀態
①pending:
pod已經被系統認可了,但是內部的container還沒有創建出來。這里包含調度到node上的時間以及下載鏡像的時間,會持續一小段時間。
②Running:
pod已經與node綁定了(調度成功),而且pod中所有的container已經創建出來,至少有一個容器在運行中,或者容器的進程正在啟動或者重啟狀態。--這里需要注意pod雖然已經Running了,但是內部的container不一定完全可用。因此需要進一步檢測container的狀態。
③Succeeded:
這個狀態很少出現,表明pod中的所有container已經成功的terminated了,而且不會再被拉起了。
④Failed:
pod中的所有容器都被terminated,至少一個container是非正常終止的。(退出的時候返回了一個非0的值或者是被系統直接終止)
⑤unknown:
由于某些原因pod的狀態獲取不到,有可能是由于通信問題。 一般情況下pod最常見的就是前兩種狀態。而且當Running的時候,需要進一步關注container的狀態
2、Container生命周期
①Waiting:啟動到運行中間的一個等待狀態。
②Running:運行狀態。
③Terminated:終止狀態。 如果沒有任何異常的情況下,container應該會從Waiting狀態變為Running狀態,這時容器可用。
但如果長時間處于Waiting狀態,container會有一個字段reason表明它所處的狀態和原因,如果這個原因很容易能標識這個容器再也無法啟動起來時,例如ContainerCannotRun,整個服務啟動就會迅速返回。(這里是一個失敗狀態返回的特性,不詳細闡述)


)




低成本與安全保障的完美結合)


![[c++] 小游戲 能量1.0.1 版本 zty出品](http://pic.xiahunao.cn/[c++] 小游戲 能量1.0.1 版本 zty出品)








