1. 背景
最近本qiang~關注了一個開源項目Scrapegraph-ai,是關于網頁爬蟲結合LLM的項目,所以想一探究竟,畢竟當下及未來,LLM終將替代以往的方方面面。
這篇文章主要介紹下該項目,并基于此項目實現一個demo頁面,頁面功能是輸入一個待爬取的網頁地址以及想要從網頁中抽取的內容,最后點擊按鈕實現網頁抓取及解析。
2. 模塊簡介
2.1 Scrapegraph-ai

該項目是一個網頁爬蟲的python包,使用LLM和直接圖邏輯(direct graph logic)來為網頁和本地文檔(XML, HTML, JSON)創建爬取管道(pipeline)。
2.2 GPT-3.5免費申請,且國內可訪問
GPT3.5-Turbo免費申請可以在開源項目GPT_API_free進行訪問,其中該項目有免費申請的地址,以及網頁插件、桌面應用安裝等教程,在日志工作學習中,使用起來非常絲滑~
其次,國內訪問gpt3.5可以基于該項目提供的代理: https://api.chatanywhere.tech/v1來實現訪問。
3. 實戰
3.1 安裝第三方包
# 網頁開發包,和Gradio類似
pip install streamlit
# 爬蟲相關包
pip install playwright
playwright install
playwright install-deps # 安裝依賴
3.2 設置gpt3.5代理環境變量
import os
os.environ['OPENAI_API_BASE'] = 'https://api.chatanywhere.tech/v1'
OPEN_API_KEY = 'sk-xxxxx'
3.3 創建網頁元素
import streamlit as stst.title('網頁爬蟲AI agent')
st.caption('該app基于gpt3.5抓取網頁信息')url = st.text_input('屬于你想抓取的網頁地址URL')
user_prompt = st.text_input('輸入你想要從該網頁獲取知識的prompt')
3.4 基于scrapegraph-ai包構建圖配置以及創建圖邏輯
from scrapegraphai.graphs import SmartScraperGraph# 圖配置信息,默認調用gpt3.5,其次embedding模型未設置,但閱讀源碼后,可以發現默認走的是openai的embedding模型
graph_config = {'llm': {'api_key': OPEN_API_KEY,'model': 'gpt-3.5-turbo','temperature': 0.1}
}# 創建直接圖邏輯
smart_scraper_graph = SmartScraperGraph(prompt=user_prompt, # 用戶輸入的promptsource=url, # 用戶輸入的urlconfig=graph_config
)# 增加一個按鈕進行爬取、解析及頁面渲染
if st.button('爬取'):result = smart_scraper_graph.run()st.write(result)
3.5 運行啟動
streamlit run scrape_web_openai.py3.6 底層原理
通過研讀SmartScraperGraph源碼,底層直接圖邏輯的原理如下圖所示。分為抓取、解析、RAG、答案生成,并默認以json格式輸出
4. 效果
4.1 新聞類
網址:ps://news.sina.com.cn/w/2024-05-20/doc-inavwrxq4965190.shtml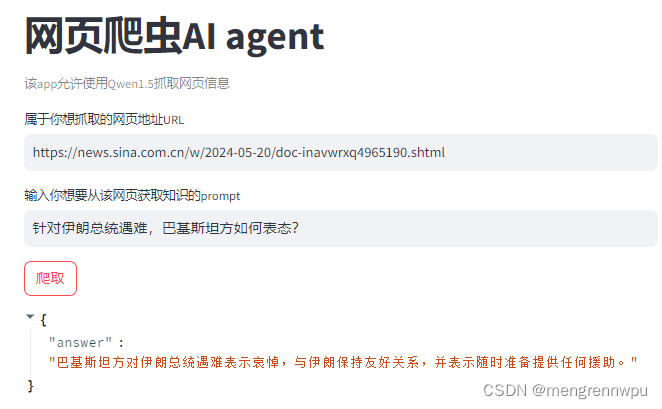
4.2 公眾號
https://mp.weixin.qq.com/s/rFYXKiedqmVo5URDxlbHzA

針對一些簡單的網頁如新聞網頁等,可以正常爬取,但響應時間在10s以上,針對一些復雜的頁面,如包含鑒權、反爬機制等,可能無法正常爬取。
5. 總結
一句話足矣~
本文主要是通過Scrapegraph-ai集成gpt3.5實現一個簡單的網頁爬取并解析的demo應用,其中涉及到gpt3.5免費申請,Scrapegraph-ai底層原理簡介,demo應用源碼等。
之后會寫一篇關于Qwen7B和BGE的相似度模型,與Scrapegraph-ai集成的demo應用,敬請期待 ~
6. 參考
1. Scrapegraph-ai: https://github.com/VinciGit00/Scrapegraph-ai
2. GPT_API_free: https://github.com/chatanywhere/GPT_API_free











)








