?
🤵?♂? 個人主頁:@艾派森的個人主頁
?🏻作者簡介:Python學習者
🐋 希望大家多多支持,我們一起進步!😄
如果文章對你有幫助的話,
歡迎評論 💬點贊👍🏻 收藏 📂加關注+
目錄
1.項目背景
2.數據集介紹
3.技術工具
4.實驗過程
4.1導入數據
4.2詞云圖可視化
4.3基于內容的協同過濾
4.4基于投票的過濾:人口統計學過濾
5.總結
6.源代碼
1.項目背景
????????隨著信息技術的迅猛發展和數字化媒體的普及,人們每天面臨著海量的信息選擇。特別是在線電影平臺,如騰訊視頻、愛奇藝、優酷等,擁有數以萬計的電影資源。用戶在如此龐大的電影庫中尋找感興趣的內容變得愈發困難,因此,一個高效、精準的推薦系統顯得尤為重要。
????????傳統的電影推薦方法,如基于流行度或者最新發布進行推薦,往往不能滿足用戶個性化的需求。為了提供更加個性化的電影推薦,推薦系統需要能夠理解和預測用戶的喜好。基于內容的推薦系統和協同過濾推薦系統是兩種主流的方法。基于內容的推薦主要是通過分析用戶過去的行為和電影的內容(如類型、導演、演員等)來推薦類似的電影。而協同過濾則是通過分析用戶的行為和其他相似用戶的行為來進行推薦。
????????然而,單一的推薦方法往往有其局限性。基于內容的推薦可能過于依賴電影的特征描述,而忽略了用戶的個性化需求;而協同過濾則可能受限于數據的稀疏性和冷啟動問題。為了克服這些問題,可以考慮將基于內容的推薦和協同過濾結合起來,形成一種混合推薦方法,即基于內容協同過濾的推薦系統。
????????本研究旨在構建一個基于內容協同過濾算法的電影推薦系統,通過結合電影的內容特征和用戶的行為數據,為用戶提供更加精準和個性化的電影推薦。通過這種方法,我們期望能夠提高用戶對推薦電影的滿意度,并進一步提升在線電影平臺的用戶體驗。
????????在上述背景下,本研究將深入探索內容協同過濾算法在電影推薦系統中的應用,以期為用戶提供更加精準、個性化的電影推薦服務。
2.數據集介紹
本數據集來源于Kaggle,原始數據集共有2個文件,一個是movies.csv,一個是credits.csv。
movies.csv如下:
credits.csv如下:
3.技術工具
Python版本:3.9
代碼編輯器:jupyter notebook
4.實驗過程
4.1導入數據
導入第三方庫并加載數據集

查看數據前五行
合并數據集
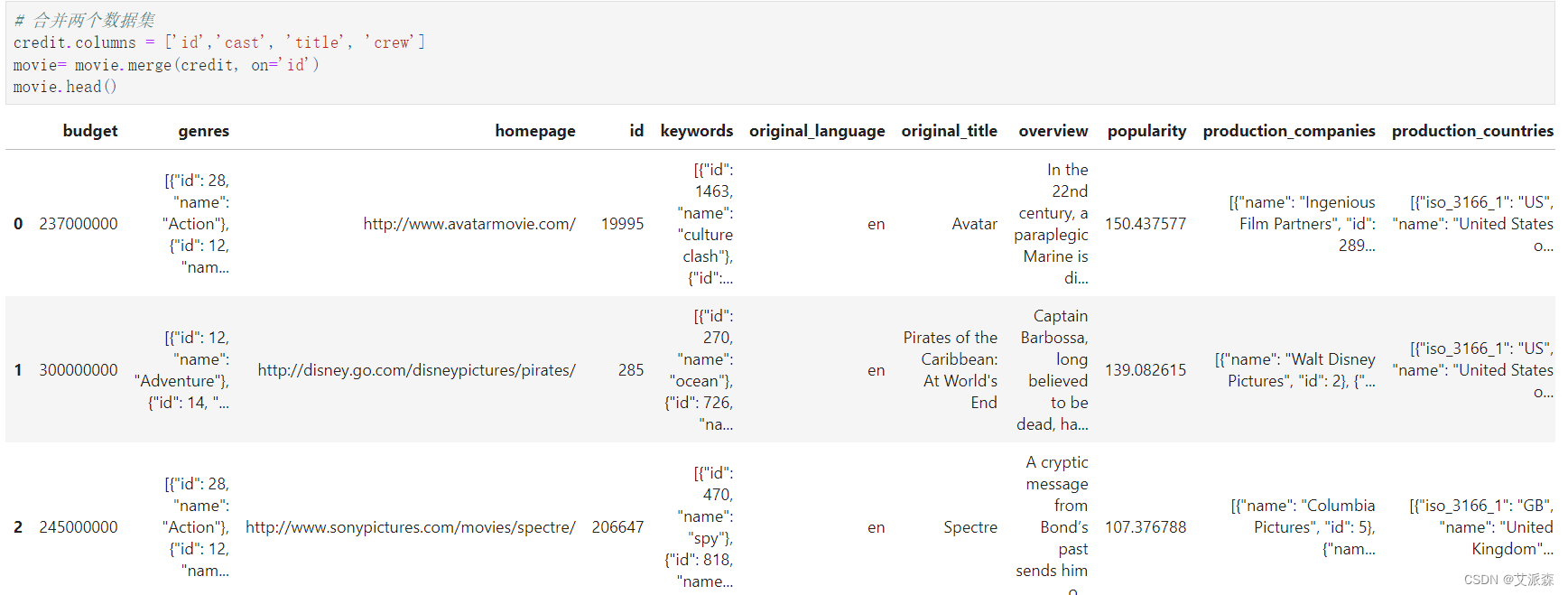
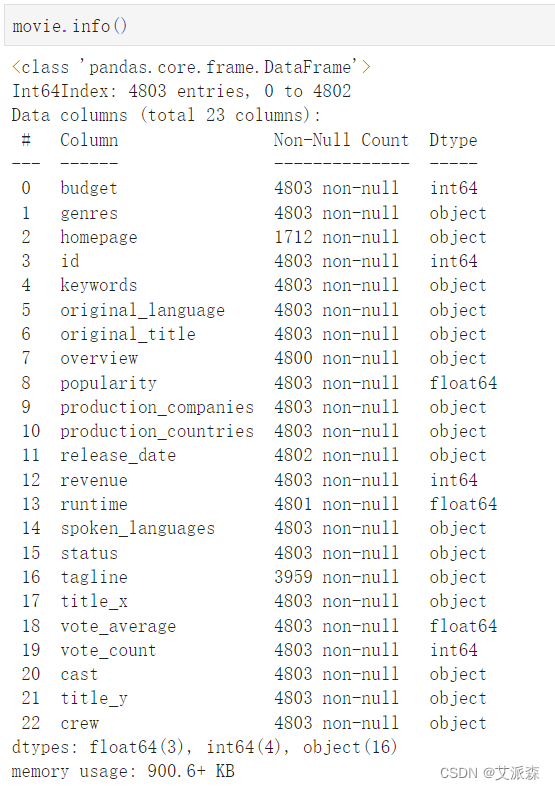
查看數據基本信息
4.2詞云圖可視化
自定義一個畫詞云圖的函數

畫出標題列的詞云圖?
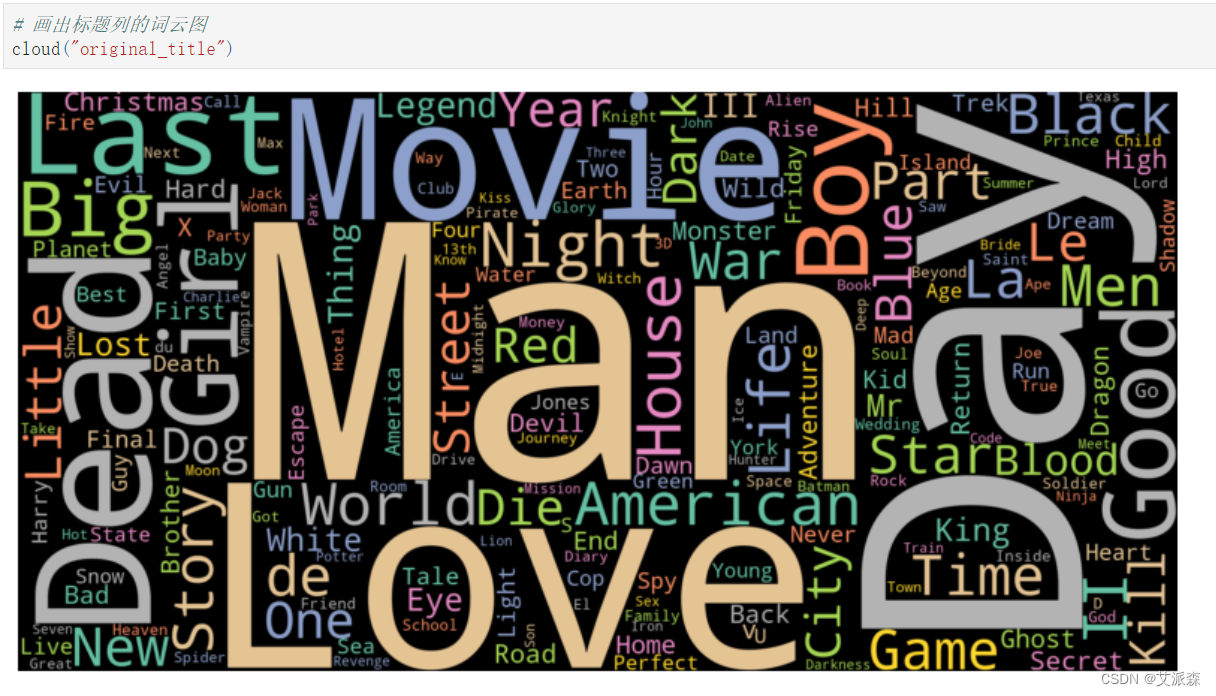
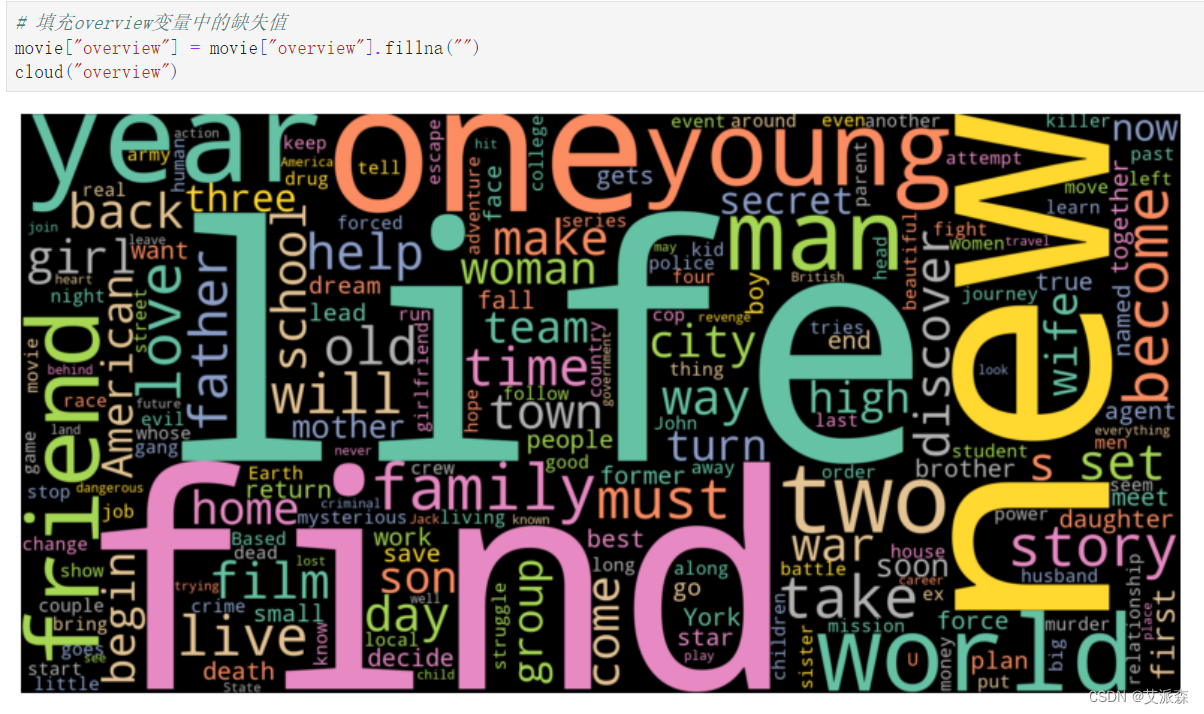
填充overview變量中的缺失值并可視化
4.3基于內容的協同過濾
????????這種類型的過濾器不涉及其他用戶,如果不是我們自己。根據我們的喜好,算法會簡單地挑選內容相似的商品推薦給我們。在這種情況下,推薦的多樣性將會減少,但無論用戶評分與否,這都是有效的。如果我們將其與上面的例子進行比較,也許用戶B可能喜歡黑色喜劇,但他/她永遠不會知道,除非他/她決定自主嘗試,因為這個過濾器只會繼續推薦反烏托邦電影或類似的電影。當然,我們可以計算許多類別的相似性:在電影的情況下,我們可以決定僅基于類型構建我們自己的推薦系統,或者我們想要包括導演,主要演員等。
向量化

我們將使用sklearn的linear_kernel()而不是cosine_similarity(),因為它更快。?

自定義一個推薦函數?

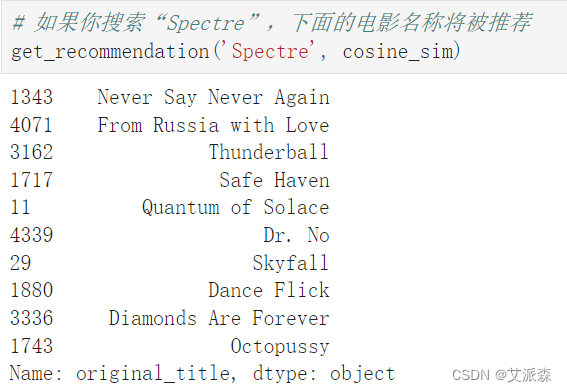
如果你搜索“Spectre”,下面的電影名稱將被推薦?
如果你搜索“John Carter”,下面的電影名稱將被推薦?

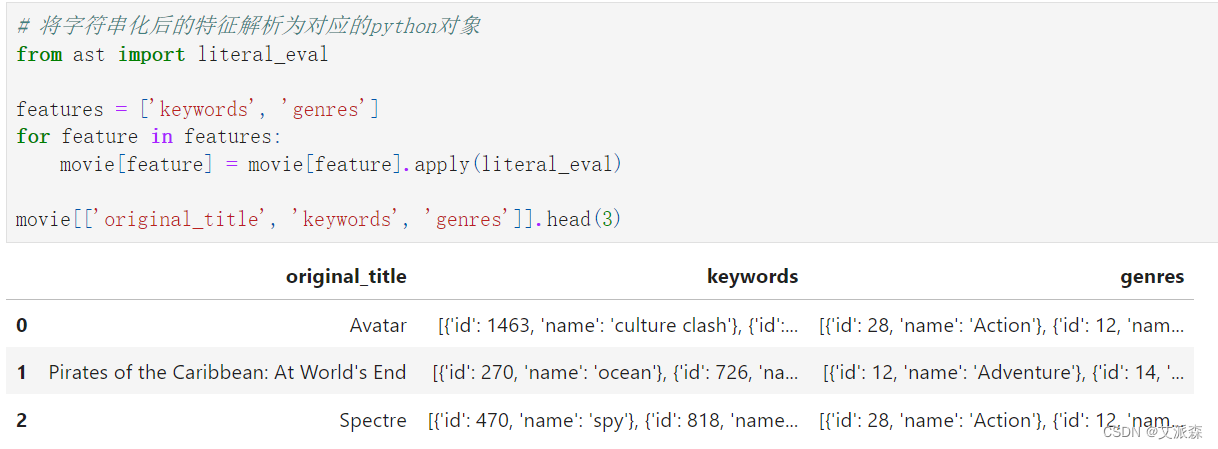
?將字符串化后的特征解析為對應的python對象
提取類型和關鍵詞列表?

結合類型和關鍵詞

?向量化

余弦相似度
余弦相似度度量了內積空間中兩個向量之間的相似度。它是由兩個向量之間夾角的余弦來測量的,并確定兩個向量是否大致指向相同的方向。在文本分析中,它常用于度量文檔的相似度。文檔可以由數千個屬性表示,每個屬性記錄文檔中特定單詞(如關鍵字)或短語的頻率。因此,每個文檔都是由術語頻率向量表示的對象。
我們都熟悉向量:它們可以是2D, 3D或任何d。讓我們用2D來思考一下,因為它更容易在我們的腦海中描繪出來,讓我們先復習一下點積的概念。兩個向量的點積等于其中一個向量在另一個向量上的投影。因此,兩個相同向量(即具有相同分量)之間的點積等于它們的平方模,而如果兩個向量垂直(即它們不共享任何方向),則點積為零。通常,對于n維向量,點積的計算方法如下所示。
在定義相似度時,點積很重要,因為它與相似度直接相關。兩個向量u和v之間相似度的定義,實際上是它們的點積和它們的大小之積的比值。
通過應用相似性的定義,如果這兩個向量相同,它等于1,如果這兩個向量正交,它等于0。換句話說,相似度是一個介于0到1之間的數字它告訴我們兩個向量有多相似。
使用余弦相似度

如果你搜索“John Carter”,下面的電影名稱將被推薦?
?
如果你搜索“Soldier”,下面的電影名稱將被推薦

4.4基于投票的過濾:人口統計學過濾
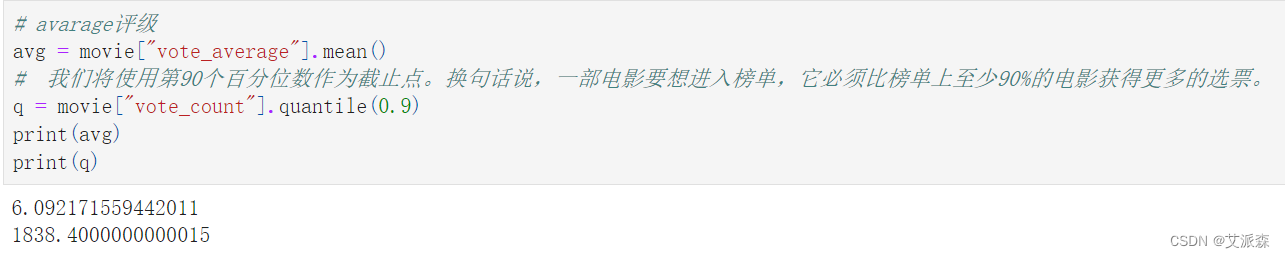
計算avarage評級
篩選符合條件的電影

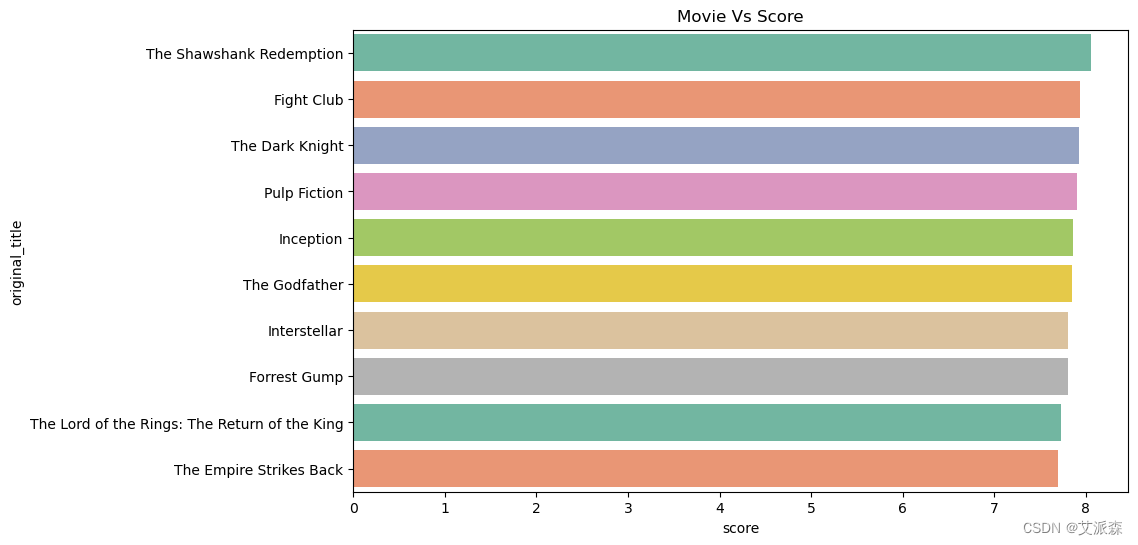
根據上面計算的分數對電影進行排序?

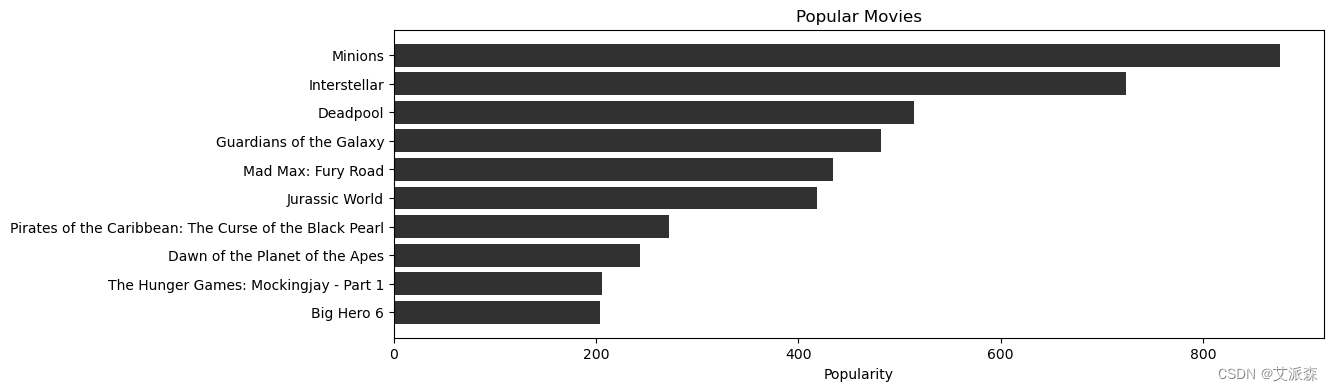
熱門電影?

5.總結
????????本研究通過構建并優化基于內容協同過濾算法的電影推薦系統,成功實現了對用戶個性化電影推薦需求的精準滿足。實驗結果表明,該系統能夠結合電影內容特征和用戶行為數據,為用戶提供更加符合其興趣和偏好的電影推薦。相較于單一的推薦方法,該系統展現出了更高的推薦準確性和用戶滿意度,從而驗證了內容協同過濾算法在電影推薦系統中的有效性和優越性。因此,該算法對于提升在線電影平臺的用戶體驗和服務質量具有重要的應用價值。
6.源代碼
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', 25)
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')movie = pd.read_csv('tmdb_5000_movies.csv')
credit = pd.read_csv('tmdb_5000_credits.csv')
movie.head()
credit.head()
# 合并兩個數據集
credit.columns = ['id','cast', 'title', 'crew']
movie= movie.merge(credit, on='id')
movie.head()
movie.info()
# 詞云圖
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
# 自定義一個畫詞云圖的函數
def cloud(col): wcloud = " ".join(f for f in movie[col])wc_ = WordCloud(width = 2000, height = 1000, random_state=1, background_color='black', colormap='Set2', collocations=False, stopwords = STOPWORDS)wc_.generate(wcloud)plt.subplots(figsize=(10,6))plt.imshow(wc_, interpolation="bilinear")plt.axis("off")
# 畫出標題列的詞云圖
cloud("original_title")
# 填充overview變量中的缺失值
movie["overview"] = movie["overview"].fillna("")
cloud("overview")
# Tfidf向量化
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words="english")
tfidf_matrix = tfidf.fit_transform(movie["overview"])
tfidf_matrix
# 我們將使用sklearn的linear_kernel()而不是cosine_similarity(),因為它更快。
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
# 索引和電影original_title的反向映射
indices = pd.Series(movie.index, index=movie['original_title']).drop_duplicates()
# 自定義一個推薦函數
def get_recommendation(title, cosine_sim):idx = indices[title]sim_scores = list(enumerate(cosine_sim[idx]))sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)sim_scores = sim_scores[1:11]movies = [i[0] for i in sim_scores]movies = movie["original_title"].iloc[movies]return movies
# 如果你搜索“Spectre”,下面的電影名稱將被推薦
get_recommendation('Spectre', cosine_sim)
# 如果你搜索“John Carter”,下面的電影名稱將被推薦
get_recommendation("John Carter", cosine_sim)
# 將字符串化后的特征解析為對應的python對象
from ast import literal_evalfeatures = ['keywords', 'genres']
for feature in features:movie[feature] = movie[feature].apply(literal_eval)movie[['original_title', 'keywords', 'genres']].head(3)
# 提取類型列表
def list_genres(x):l = [d['name'] for d in x]return(l)
movie['genres'] = movie['genres'].apply(list_genres)# 提取關鍵字列表
def list_keyword(y):i = [a['name'] for a in y]return(i)
movie['keywords'] = movie['keywords'].apply(list_keyword)
# 結合類型和關鍵詞
def genre(x):return ''.join(' '.join(x['genres']) + ' ' + ' '.join(x['keywords']))movie['mix'] = movie.apply(genre, axis=1)
movie["mix"]
# 向量化
from sklearn.feature_extraction.text import CountVectorizer
countvect = CountVectorizer(stop_words="english")
countvect_mat = tfidf.fit_transform(movie["mix"])
countvect_mat
from sklearn.metrics.pairwise import cosine_similarity
cos_sim = cosine_similarity(countvect_mat, countvect_mat)
# 索引和電影original_title的反向映射
movie = movie.reset_index()
indices = pd.Series(movie.index, index=movie['original_title'])
# 如果你搜索“John Carter”,下面的電影名稱將被推薦
get_recommendation("John Carter", cos_sim)
# 如果你搜索“Soldier”,下面的電影名稱將被推薦
get_recommendation("Soldier", cos_sim)
基于投票的過濾:人口統計學過濾
# avarage評級
avg = movie["vote_average"].mean()
# 我們將使用第90個百分位數作為截止點。換句話說,一部電影要想進入榜單,它必須比榜單上至少90%的電影獲得更多的選票。
q = movie["vote_count"].quantile(0.9)
print(avg)
print(q)
# 符合條件的電影
movies = movie[movie["vote_count"] >= q]
# weighted_rating函數
def weighted_rating(x, q=q, avg=avg):v = x['vote_count']R = x['vote_average']# 根據IMDB公式計算return (v/(v+q) * R) + (q/(q+v) * avg)# 符合條件的影片
movies["score"] = movies.apply(weighted_rating, axis=1)
# 根據上面計算的分數對電影進行排序
movies = movies.sort_values('score', ascending=False)
# 打印前10部電影
listed = movies[['original_title', 'vote_count', 'vote_average', 'score', "popularity"]].head(10)
# 可視化
import seaborn as sns
plt.subplots(figsize=(10,6))
sns.barplot(listed["score"], listed["original_title"], palette="Set2")
plt.title("Movie Vs Score")
plt.show()
# 熱門電影
popular= movies.sort_values('popularity', ascending=False)
plt.figure(figsize=(12,4))plt.barh(popular['original_title'].head(10),popular['popularity'].head(10), align='center',color="#313131")
plt.gca().invert_yaxis()
plt.xlabel("Popularity")
plt.title("Popular Movies")
plt.show()
資料獲取,更多粉絲福利,關注下方公眾號獲取



)


)




)







 系統信息與系統資源)
