一、方案背景
在公司內部devops平臺的微服務化改造過程中,我們遇到了典型的分布式系統觀測難題:服務間調用鏈路復雜、性能瓶頸難以定位、故障排查效率低下。特別是在生產環境出現問題時,往往需要花費大量時間在各個服務的日志中尋找蛛絲馬跡。
經過前期的技術調研和實際踩坑,我們最終確定了基于 OpenTelemetry Collector + Kubernetes Operator + 阿里云 SLS 的觀測平臺解決方案。這套方案的核心目標是:讓開發團隊能夠快速定位問題,讓運維團隊能夠主動發現問題,讓業務團隊能夠洞察系統性能對用戶體驗的影響。
二、技術選型深度對比
2.1 阿里云鏈路追蹤實戰踩坑記錄
在實際接入阿里云鏈路追蹤的過程中,我們遇到了幾個關鍵問題:
數據閉環問題
-
問題描述:阿里云鏈路追蹤的數據完全封閉在云平臺內部,外部系統無法獲取原始數據
-
影響范圍:無法進行定制化數據分析、無法與現有監控體系集成、難以實現跨平臺數據關聯
-
業務痛點:當我們需要基于鏈路數據做業務分析或告警定制時,完全受限于阿里云提供的功能
功能局限性問題
-
接口篩選限制:無法按照
kind:server進行接口列表篩選,導致客戶端調用和服務端處理混在一起 -
告警配置受限:告警規則無法基于 span 的 kind 屬性進行精確配置
-
環境隔離混亂:通過標簽區分環境導致全局拓撲圖極為混亂,影響問題排查效率
技術架構分析
阿里云鏈路追蹤的本質
-
底層基于 SkyWalking 實現
-
SkyWalking 本身是 OpenTracing 的增強版,包含 Trace 和 Metrics 數據
-
但并非標準的 OpenTelemetry 協議,缺乏標準化支撐
核心問題根源
-
云產品的數據閉環特性,基本斷絕了定制化擴展的可能性
-
非標準協議導致后期 Metrics 定制化擴展時無標準可循
-
強耦合的產品設計限制了技術棧的靈活性
2.2 鏈路追蹤方案對比
基于實際使用經驗,我們對主流鏈路追蹤方案進行了深入對比:
| 方案 | 標準支持 | 運維成本 | 存儲后端 | 數據消費 | 廠商綁定 | 推薦度 |
|---|---|---|---|---|---|---|
| SkyWalking | 自有協議 | 高(需自建ES集群) | Elasticsearch | 受限 | 中等 | ? |
| Jaeger | OpenTracing/OTel | 高(需自建存儲) | Cassandra/ES | 開放 | 低 | ?? |
| 阿里云鏈路追蹤 | 基于SkyWalking | 低 | 托管 | 封閉 | 高 | ? |
| 阿里云SLS | 完整OTel支持 | 低 | 托管 | 開放 | 低 | ? |
2.3 為什么不選擇 SkyWalking?
運維成本過高
存儲后端復雜性:
# SkyWalking 典型部署架構
SkyWalking OAP Server:- 需要 Elasticsearch 集群(至少3節點)- 需要配置索引模板和生命周期策略- 需要監控 ES 集群健康狀態- 數據量大時查詢性能下降明顯Elasticsearch 集群:resources:requests:memory: "4Gi" # 每節點最少4GB內存cpu: "2"limits:memory: "8Gi" # 生產環境建議8GB+cpu: "4"
成本分析對比:
| 組件 | SkyWalking方案 | SLS方案 |
|---|---|---|
| 計算資源 | OAP Server: 2C4G × 2 | 無需自建 |
| 存儲資源 | ES集群: 4C8G × 3 | 按量付費 |
| 運維人力 | 需要ES人員運維 | 無需專門運維 |
| 月成本估算 | ¥3000-5000 | ¥800-1500 |
技術標準化問題
協議兼容性:
// SkyWalking 使用自有協議
type SegmentObject struct {TraceSegmentId string `json:"traceSegmentId"`// 非標準 OpenTelemetry 格式
}// OpenTelemetry 標準格式
type Span struct {TraceId []byte `json:"trace_id"`SpanId []byte `json:"span_id"`// 遵循 OTLP 協議標準
}
-
廠商鎖定風險:SkyWalking 使用自有數據格式,遷移成本高
-
生態兼容性:與 OpenTelemetry 生態集成需要額外適配
-
標準化程度:不符合 CNCF 推薦的 OpenTelemetry 標準
2.4 為什么選擇 OpenTelemetry + 阿里云 SLS?
基于前面踩坑經驗的總結,我們最終選擇了 OpenTelemetry + 阿里云 SLS 的技術方案:
OpenTelemetry 的標準化價值
在經歷了阿里云鏈路追蹤的數據閉環問題后,我們深刻認識到標準化的重要性:
# OpenTelemetry 配置(標準化)
receivers:otlp:protocols:grpc:endpoint: "0.0.0.0:55680"http:endpoint: "0.0.0.0:55681"exporters:# 可以輕松切換到任何支持 OTLP 的后端otlp/sls:endpoint: "https://sls-endpoint"# 或者切換到其他廠商otlp/jaeger:endpoint: "http://jaeger:14250"
實際項目中的遷移便利性:
-
從阿里云鏈路追蹤遷移時,應用代碼完全不需要修改
-
我們可以同時導出到多個后端,在遷移過程中進行數據對比驗證
-
基于 CNCF 標準,避免了再次踩坑的風險
成本效益分析
在實際項目預算評估中,我們發現成本差異非常明顯:
真實成本對比(基于我們的實際使用量):
# 月處理約100GB Trace數據的成本對比
SkyWalking 自建方案:
- ECS費用: ¥2400 (OAP Server + ES集群)
- 存儲費用: ¥800 (高性能SSD)
- 運維成本: ¥2000 (需要專門的ES運維)
- 監控告警: ¥200 (額外的監控組件)
總計: ¥5400/月阿里云 SLS 方案:
- 存儲費用: ¥600 (100GB數據)
- 查詢費用: ¥300 (日常查詢)
- 運維成本: ¥0 (托管服務)
總計: ¥900/月實際節省: 83% (¥4500/月)
這個成本差異在項目立項時起到了決定性作用,特別是考慮到我們團隊缺乏 Elasticsearch 專業運維經驗的情況下。
數據開放性解決核心痛點
這是我們選擇 SLS 而不是阿里云鏈路追蹤的關鍵原因:
實時數據消費能力:
# SLS 支持實時數據消費,這是我們實際在用的代碼
from aliyun.log import LogClient# 實時消費 Trace 數據進行業務分析
client = LogClient(endpoint, access_key_id, access_key_secret)
response = client.pull_logs(project, logstore, shard_id, cursor)# 我們基于這個能力實現了自定義的性能告警
for log in response.get_logs():# 檢測慢查詢if log.get('duration') > 2000 and 'mysql' in log.get('operation_name', ''):send_slow_query_alert(log)# 檢測錯誤率異常if log.get('status_code') == 'ERROR':update_error_metrics(log)
解決的實際問題:
-
自定義告警:我們可以基于業務邏輯設置精確的告警規則,而不是被限制在云產品的固定功能中
-
數據關聯分析:能夠將鏈路數據與業務指標進行關聯,實現更深層次的業務洞察
-
多維度消費:同一份數據可以同時供給 Grafana、自建告警系統、數據分析平臺使用
2.5 最終技術架構確認
基于以上分析,我們確定的技術架構為:
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ 應用服務 │ │ OpenTelemetry │ │ 數據存儲 │
│ │ │ Collector │ │ │
│ ┌─────────────┐ │ │ (DaemonSet) │ │ ┌─────────────┐ │
│ │ Metrics │─┼────┼──────────────────┼────┼→│ Prometheus │ │
│ └─────────────┘ │ │ │ │ └─────────────┘ │
│ ┌─────────────┐ │ │ │ │ ┌─────────────┐ │
│ │ Traces │─┼────┼──────────────────┼────┼→│ 阿里云 SLS │ │
│ └─────────────┘ │ │ │ │ └─────────────┘ │
│ ┌─────────────┐ │ │ │ │ ┌─────────────┐ │
│ │ Logs │─┼────┼──────────────────┼────┼→│業務LogStore │ │
│ └─────────────┘ │ │ │ │ └─────────────┘ │
└─────────────────┘ └──────────────────┘ └─────────────────┘↓┌──────────────────┐│ Grafana ││ (統一展示) ││ ││ ? Prometheus數據 ││ ? SLS Trace數據 ││ ? 日志關聯查詢 │└──────────────────┘
架構特點:
-
Metrics:通過 Prometheus 直接采集和存儲,利用其成熟的生態
-
Traces:通過 OpenTelemetry Collector 上報到阿里云 SLS,享受托管服務優勢
-
Logs:保持現有業務 LogStore 不變,避免業務改造
-
展示:統一在 Grafana 中展示所有觀測數據,實現一站式監控
核心優勢:
-
成本最優:相比自建 SkyWalking 節省 80%+ 成本
-
標準開放:基于 OpenTelemetry 標準,避免廠商鎖定
-
運維簡單:無需維護復雜的存儲集群
-
擴展性強:支持數據實時消費和自定義分析
-
業務無感:日志系統保持不變,減少業務改造風險
三、核心概念解析
3.1 OpenTelemetry Collector DaemonSet 架構優勢
為什么選擇 DaemonSet 部署模式?
1. 網絡開銷最小化
傳統的集中式 Collector 部署方式存在以下問題:
-
跨節點網絡傳輸:應用數據需要通過 K8s Service 或 Ingress 路由到遠程 Collector,增加網絡跳數
-
網絡延遲累積:數據傳輸路徑:應用 → kube-proxy → Service → 遠程節點 → Collector
-
帶寬競爭:所有節點的觀測數據匯聚到少數幾個 Collector 實例,容易形成網絡瓶頸
DaemonSet 模式的網絡優勢:
傳統模式:App Pod → 遠程 OAP SERVER Pod (跨節點網絡,需要nat網關)DaemonSet:App Pod → DaemonSet:55680 (同集群同節點網絡棧,不走nat網關)
-
本地通信:應用直接通過
DaemonSet:55680與同節點的 Collector 通信,避免跨節點網絡傳輸 -
零延遲:同節點網絡延遲接近 0,大幅降低觀測數據的傳輸延遲
-
帶寬節省:節點內通信不占用集群網絡帶寬,避免對業務流量的影響
-
高可用性:每個節點獨立的 Collector 實例,單點故障不影響其他節點
2. 資源利用優化
# DaemonSet 資源配置示例
resources:requests:memory: "128Mi" # 每節點固定資源消耗cpu: "100m"limits:memory: "256Mi" # 可預測的資源上限cpu: "200m"
-
資源分散:Collector 資源消耗分散到各個節點,避免單節點資源熱點
-
線性擴展:隨著節點數量增加,Collector 處理能力線性擴展
-
故障隔離:單個節點的 Collector 故障不影響其他節點的數據收集
3. 配置管理簡化
# 統一的 ConfigMap 配置
apiVersion: v1
kind: ConfigMap
metadata:name: otel-collector-config
data:config.yaml: |receivers:otlp:protocols:grpc:endpoint: "0.0.0.0:55680" # 所有節點統一配置
-
配置一致性:所有節點使用相同的 Collector 配置,簡化運維管理
-
熱更新支持:通過 ConfigMap 更新可以同時影響所有節點的 Collector
-
版本管理:DaemonSet 確保所有節點運行相同版本的 Collector
3.2 Kubernetes Operator 無侵入式改造原理
為什么選擇 Operator 模式?
1. 聲明式配置管理
傳統的觀測接入方式存在以下問題:
-
手動配置:需要開發人員手動修改每個應用的 Deployment 配置
-
配置分散:觀測配置散布在各個應用的部署文件中,難以統一管理
-
人為錯誤:手動配置容易出現拼寫錯誤、配置不一致等問題
-
維護成本高:配置變更需要逐個應用修改,工作量大
Operator 的聲明式優勢:
# 應用只需添加標簽,無需修改容器配置
metadata:labels:odyssey-apm-enable: "true" # 聲明:我需要觀測odyssey-apm-language: "java" # 聲明:我是 Java 應用odyssey-apm-sampling-rate: "0.3" # 聲明:30% 采樣率
-
標簽驅動:通過標簽聲明觀測需求,Operator 自動處理具體實現
-
配置集中:所有觀測邏輯集中在 Operator 中,便于統一管理和升級
-
自動化執行:標簽變更自動觸發配置更新,無需人工干預
2. 無侵入式注入機制
Java 應用無侵入原理:
// Operator 自動注入的環境變量
javaToolOptions := fmt.Sprintf("-javaagent:/usr/local/agent/opentelemetry.jar " +"-Dotel.service.name=%s " +"-Dotel.exporter.otlp.traces.endpoint=http://DaemonSet:55680",serviceName)container.Env = append(container.Env, corev1.EnvVar{Name: "JAVA_TOOL_OPTIONS",Value: javaToolOptions,
})
-
JavaAgent 機制:利用 JVM 的
-javaagent參數在類加載時進行字節碼增強 -
零代碼改動:應用代碼完全不需要修改,只需在鏡像中包含 OpenTelemetry JavaAgent
-
自動埋點:JavaAgent 自動識別并埋點常見框架(Spring、MyBatis、Redis 等)
-
運行時注入:通過環境變量在容器啟動時注入配置,不影響鏡像構建
Golang 應用最小侵入原理:
// Operator 注入的環境變量
envVars := map[string]string{"OTEL_EXPORTER_OTLP_TRACES_ENDPOINT": "http://DaemonSet:55680","OTEL_EXPORTER_OTLP_TRACES_PROTOCOL": "grpc","OTEL_SERVICE_NAME": serviceName,"OTEL_TRACES_SAMPLER": "parentbased_traceidratio","OTEL_TRACES_SAMPLER_ARG": samplingRate,
}
-
環境變量配置:通過標準的 OpenTelemetry 環境變量進行配置
-
SDK 自動初始化:OpenTelemetry Go SDK 自動讀取環境變量并初始化
-
最小代碼改動:只需在應用啟動時調用 SDK 初始化函數
-
標準化接入:遵循 OpenTelemetry 標準,便于后續遷移和升級
3. 動態配置管理
實時監聽機制:
// Operator 的 Reconcile 循環
func (r *ObserReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {// 1. 監聽 Deployment 變化事件var deployment appsv1.Deploymentif err := r.Get(ctx, req.NamespacedName, &deployment); err != nil {return ctrl.Result{}, client.IgnoreNotFound(err)}// 2. 檢查觀測標簽if apmEnable, exists := deployment.Labels["odyssey-apm-enable"]; exists && apmEnable == "true" {// 3. 自動注入觀測配置r.injectObservabilityConfig(&deployment)} else {// 4. 自動清理觀測配置r.removeObservabilityConfig(&deployment)}return ctrl.Result{}, nil
}
-
事件驅動:基于 K8s API 的 Watch 機制,實時響應 Deployment 變化
-
自動同步:標簽添加/刪除自動觸發配置注入/清理,保持狀態一致
-
批量管理:支持批量操作,可以同時管理多個應用的觀測配置
-
版本控制:配置變更通過 K8s 的版本控制機制進行管理
4. 運維友好性
統一管理界面:
# 查看所有啟用觀測的應用
kubectl get deployments -l odyssey-apm-enable=true# 批量啟用觀測
kubectl label deployments -l app.type=microservice odyssey-apm-enable=true# 查看 Operator 運行狀態
kubectl logs -f deployment/odyssey-obser-operator
-
可視化管理:通過 kubectl 命令或 K8s Dashboard 可視化管理觀測配置
-
批量操作:支持基于標簽選擇器的批量配置操作
-
審計日志:所有配置變更都有完整的審計日志
-
故障自愈:Operator 持續監控并自動修復配置漂移
3.3 架構優勢總結
| 方面 | 傳統方式 | Operator + DaemonSet 方式 |
|---|---|---|
| 網絡開銷 | 跨節點傳輸,延遲高 | 本地通信,零延遲 |
| 配置管理 | 手動分散配置 | 自動化集中管理 |
| 代碼侵入 | 需要修改應用代碼 | Java 零侵入,Go 最小侵入 |
| 運維復雜度 | 高,需要逐個配置 | 低,標簽驅動自動化 |
| 擴展性 | 集中式瓶頸 | 線性擴展 |
| 故障影響 | 單點故障影響全局 | 故障隔離,影響最小 |
| 資源利用 | 資源熱點 | 資源分散,利用率高 |
核心特性
-
無侵入接入:Java 應用通過 JavaAgent 零代碼改動,Golang 應用通過環境變量配置
-
自動化管理:通過 K8s Operator 自動監聽 Deployment 變化,動態注入觀測配置
-
統一數據出口:所有觀測數據統一上報至阿里云 SLS,支持多維度分析
-
靈活采樣控制:支持通過標簽配置鏈路采樣率,平衡性能與觀測精度
-
多平臺支持:既支持奧德賽 CICD 平臺一鍵開啟,也支持獨立 K8s 環境手動配置
四、架構設計
4.1 整體架構圖
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ 應用服務 │ │ OpenTelemetry │ │ 阿里云 SLS │
│ │ │ Collector │ │ │
│ ┌─────────────┐ │ │ │ │ ┌─────────────┐ │
│ │ Java App │─┼────┼─? gRPC:55680 ─┼────┼─? Trace Store │ │
│ │ (JavaAgent) │ │ │ HTTP:55681 │ │ │ │ │
│ └─────────────┘ │ │ │ │ └─────────────┘ │
│ │ │ │ │ │
│ ┌─────────────┐ │ │ │ │ ┌─────────────┐ │
│ │ Golang App │─┼────┼─? OTLP Protocol ─┼────┼─? Metrics │ │
│ │ (SDK) │ │ │ │ │ │ Store │ │
│ └─────────────┘ │ │ │ │ └─────────────┘ │
└─────────────────┘ └──────────────────┘ └─────────────────┘▲ ▲ ││ │ ▼
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ K8s Operator │ │ DaemonSet │ │ 觀測平臺 │
│ │ │ │ │ │
│ ┌─────────────┐ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │
│ │ Deployment │ │ │ │ OTel │ │ │ │ SLS 控制臺 │ │
│ │ Watcher │ │ │ │ Collector │ │ │ │ │ │
│ └─────────────┘ │ │ │ Pod │ │ │ └─────────────┘ │
│ │ │ └─────────────┘ │ │ │
│ ┌─────────────┐ │ │ │ │ ┌─────────────┐ │
│ │ Env Var │ │ │ │ │ │ Grafana + │ │
│ │ Injector │ │ │ │ │ │ Jaeger UI │ │
│ └─────────────┘ │ │ │ │ └─────────────┘ │
└─────────────────┘ └──────────────────┘ └─────────────────┘
4.2 數據流向
應用 Pod → OpenTelemetry Collector (DaemonSet) → 阿里云 SLS↑ ↑
Operator 注入配置 本地 localhost:55680
-
配置注入:Operator 監聽 Deployment 變化,自動注入觀測配置
-
數據生成:應用啟動時自動初始化 OpenTelemetry SDK
-
本地收集:應用通過 localhost:55680 將數據發送到同節點 Collector
-
數據處理:Collector 對數據進行批處理、采樣、格式轉換
-
遠程上報:Collector 將處理后的數據上報到阿里云 SLS
4.3 組件職責
| 組件 | 職責 | 部署方式 |
|---|---|---|
| OpenTelemetry Collector | 接收應用上報的 OTLP 數據,轉發至 SLS | DaemonSet(每個節點一個實例) |
| K8s Operator | 監聽 Deployment 變化,自動注入觀測配置 | Deployment(集群級單實例) |
| 應用服務 | 通過 Agent 或 SDK 上報觀測數據 | 現有 Deployment |
| 阿里云 SLS | 存儲和分析觀測數據 | 云服務 |
五、核心組件實現
5.1 OpenTelemetry Collector
配置說明
基于 otelcol-contrib 構建,配置文件 /tools/obser/config.yaml:
receivers:otlp:protocols:grpc:endpoint: "0.0.0.0:55680" # 接收 gRPC 協議數據http:endpoint: "0.0.0.0:55681" # 接收 HTTP 協議數據exporters:alibabacloud_logservice/sls-trace:endpoint: "sre-observability-monitor.cn-shanghai.log.aliyuncs.com"project: "sre-observability-monitor"logstore: "odyssey-stage-traces"access_key_id: "${SLS_ACCESS_KEY_ID}"access_key_secret: "${SLS_ACCESS_KEY_SECRET}"service:pipelines:traces:receivers: [otlp]exporters: [alibabacloud_logservice/sls-trace]
部署清單
apiVersion: apps/v1
kind: DaemonSet
metadata:name: odyssey-otel-collectornamespace: odyssey-observability
spec:selector:matchLabels:app: odyssey-otel-collectortemplate:metadata:labels:app: odyssey-otel-collectorspec:containers:- name: otel-collectorimage: {otel collector的docker鏡像}ports:- containerPort: 55680name: grpc- containerPort: 55681name: httpenv:- name: SLS_ACCESS_KEY_IDvalueFrom:secretKeyRef:name: sls-credentialskey: access-key-id- name: SLS_ACCESS_KEY_SECRETvalueFrom:secretKeyRef:name: sls-credentialskey: access-key-secretresources:requests:memory: "128Mi"cpu: "100m"limits:memory: "256Mi"cpu: "200m"hostNetwork: true # 使用主機網絡,便于應用訪問
5.2 Kubernetes Operator
功能特性
基于 /operator/obser/main.go 實現的 K8s Operator,具備以下能力:
-
自動發現:監聽集群內所有 Deployment 的創建、更新、刪除事件
-
標簽驅動:根據 Deployment 標簽自動判斷是否需要注入觀測配置
-
多語言支持:支持 Java(JavaAgent)和 Golang(SDK)兩種接入方式
-
采樣率控制:支持通過標簽配置鏈路采樣率
-
服務名映射:優先使用 Pod 的
app標簽作為服務名
標簽配置規范
| 標簽名 | 值 | 說明 |
|---|---|---|
odyssey-apm-enable | "true" | 啟用觀測功能 |
odyssey-apm-language | "java" 或 "golang" | 應用語言類型,默認 java |
odyssey-apm-sampling-rate | "0.1" ~ "1.0" | 鏈路采樣率,默認 1.0(全采樣) |
環境變量注入邏輯
Java 應用:
JAVA_TOOL_OPTIONS="-javaagent:/usr/local/agent/opentelemetry.jar \-Dotel.service.name=${SERVICE_NAME} \-Dotel.exporter.otlp.traces.endpoint=http://localhost:55680 \-Dotel.exporter.otlp.traces.protocol=grpc \-Dotel.exporter.otlp.traces.insecure=true \-Dotel.metrics.exporter=none \-Dotel.logs.exporter=none \-Dotel.traces.sampler=parentbased_traceidratio \-Dotel.traces.sampler.arg=${SAMPLING_RATE}"
Golang 應用:
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT="http://localhost:55680"
OTEL_EXPORTER_OTLP_TRACES_PROTOCOL="grpc"
OTEL_SERVICE_NAME="${SERVICE_NAME}"
OTEL_TRACES_SAMPLER="parentbased_traceidratio"
OTEL_TRACES_SAMPLER_ARG="${SAMPLING_RATE}"
5.3 應用接入方式
Java 應用(無侵入)
-
鏡像準備:在應用鏡像中預置 OpenTelemetry JavaAgent``dockerfile# 在應用 Dockerfile 中添加ADD https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases/latest/download/opentelemetry-javaagent.jar /usr/local/agent/opentelemetry.jar
\ -
標簽配置:在 Deployment 上添加觀測標簽``yamlmetadata:labels:odyssey-apm-enable: "true"odyssey-apm-language: "java"odyssey-apm-sampling-rate: “0.3” # 30% 采樣率
\ -
自動生效:Operator 自動注入
JAVA_TOOL_OPTIONS環境變量,應用重啟后生效
Golang 應用(otel動態插樁)
-
編譯代理:使用otel go agent完成編譯改造,只需要加上前綴 otel即可
-
標簽配置:在 Deployment 上添加觀測標簽``yamlmetadata:labels:odyssey-apm-enable: "true"odyssey-apm-language: "golang"odyssey-apm-sampling-rate: “0.5” # 50% 采樣率
\ -
自動生效:Operator 自動注入 OTEL 相關環境變量,應用重啟后生效
六、部署實施方案
6.1 環境準備
命名空間創建
kubectl create namespace odyssey-observability
SLS 憑證配置
kubectl create secret generic sls-credentials \--from-literal=access-key-id="LTAI5t7snKaMwG2RjVAdFv8H" \--from-literal=access-key-secret="4t1E90OJyWhrYfoRtbwsuLQxiJmueN" \-n odyssey-observability
6.2 組件部署順序
-
部署 OpenTelemetry Collector DaemonSet``bashkubectl apply -f otel-collector-daemonset.yaml
\ -
部署 K8s Operator``bashkubectl apply -f odyssey-obser-operator.yaml
\ -
驗證部署狀態``bashkubectl get pods -n odyssey-observabilitykubectl logs -f deployment/odyssey-obser-operator -n odyssey-observability
\
6.3 應用接入流程
devops 平臺CICD 平臺接入
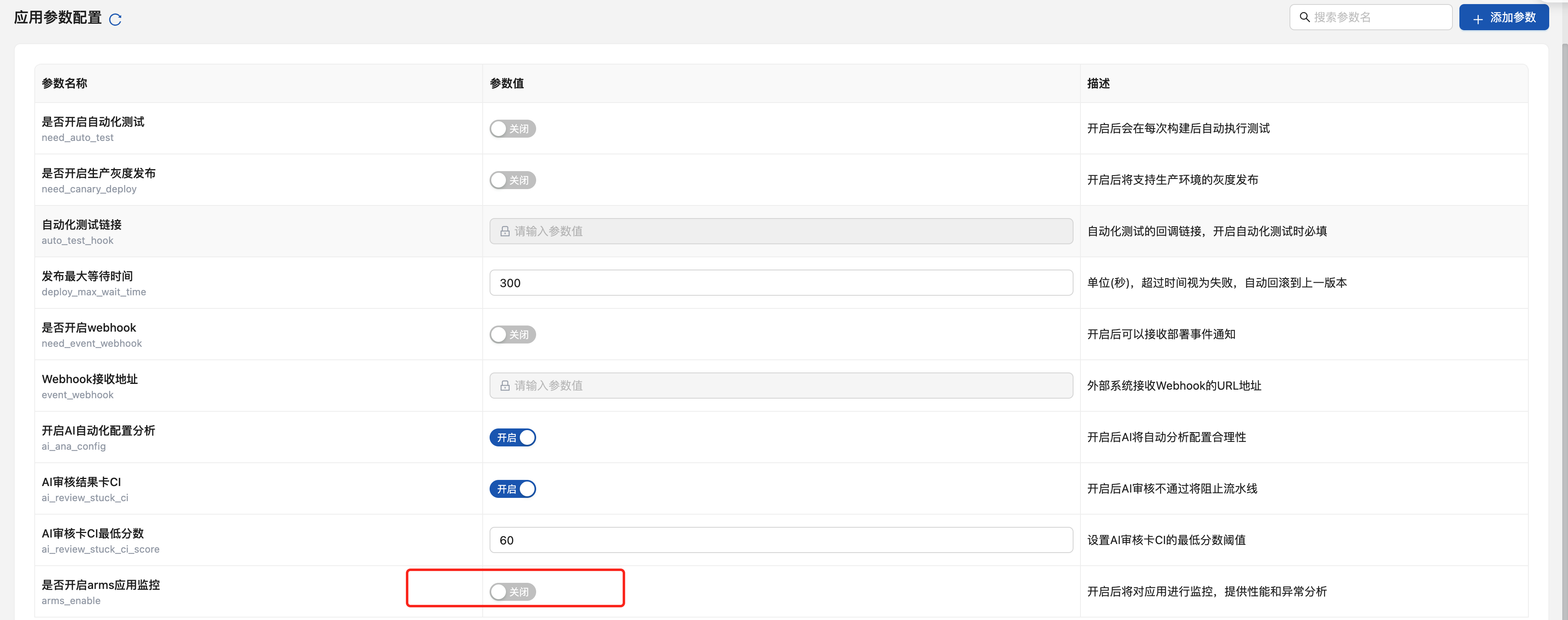
-
平臺配置:在devops CICD 平臺的應用配置頁面
-
一鍵開啟:勾選"開啟觀測"選項
-
參數配置:
-
應用語言:Java / Golang
-
采樣率:0.1 - 1.0
-
-
自動部署:平臺自動在 Deployment 上添加相應標簽并重新部署
獨立 K8s 環境接入

-
手動添加標簽:``bashkubectl label deployment odyssey-apm-enable=truekubectl label deployment odyssey-apm-language=javakubectl label deployment odyssey-apm-sampling-rate=0.3
\ -
觸發更新:``bashkubectl rollout restart deployment
\ -
驗證接入:``bashkubectl describe deployment | grep -A 10 “Environment”
\
七、觀測數據消費
7.1 阿里云 SLS 控制臺
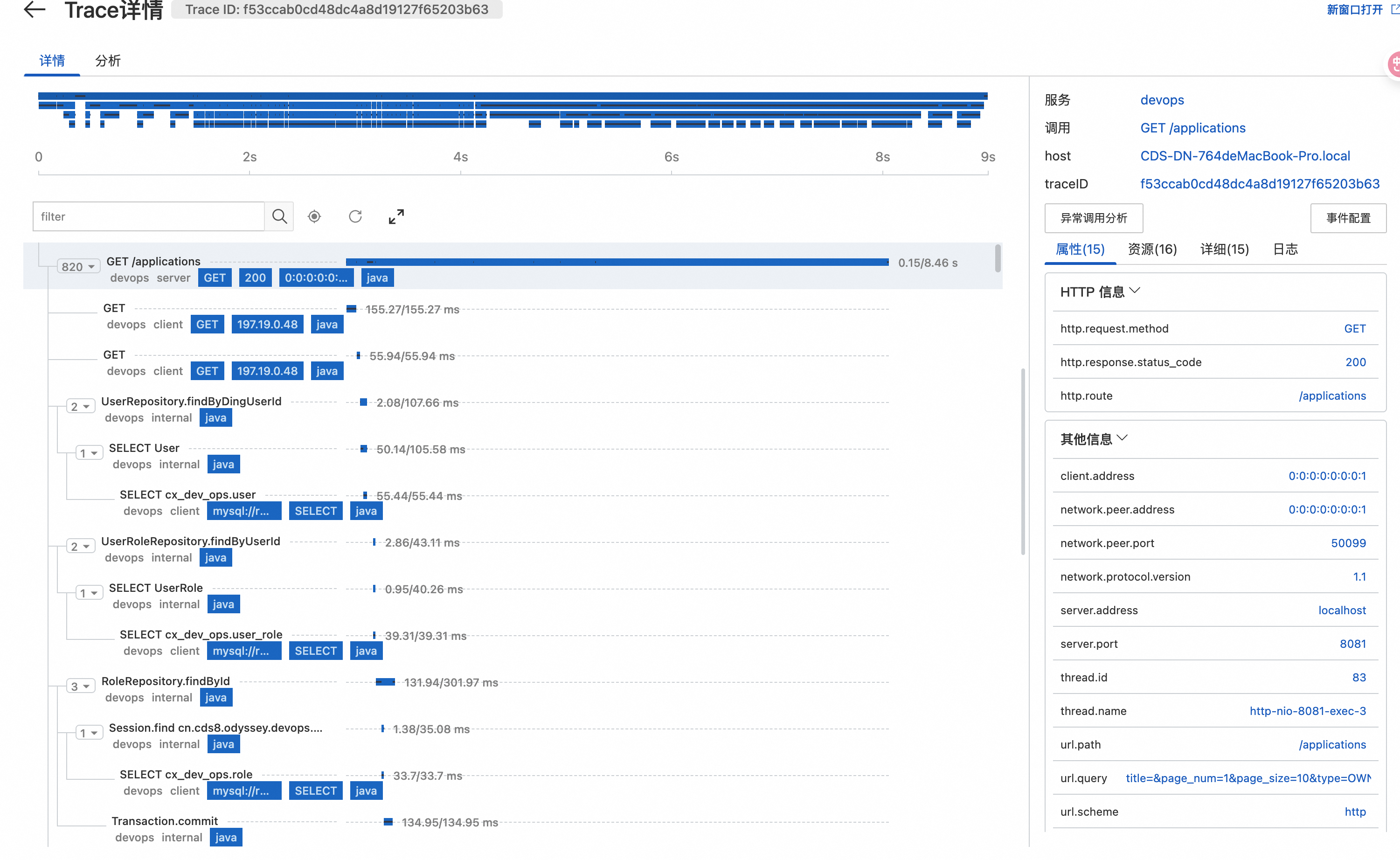
鏈路查詢
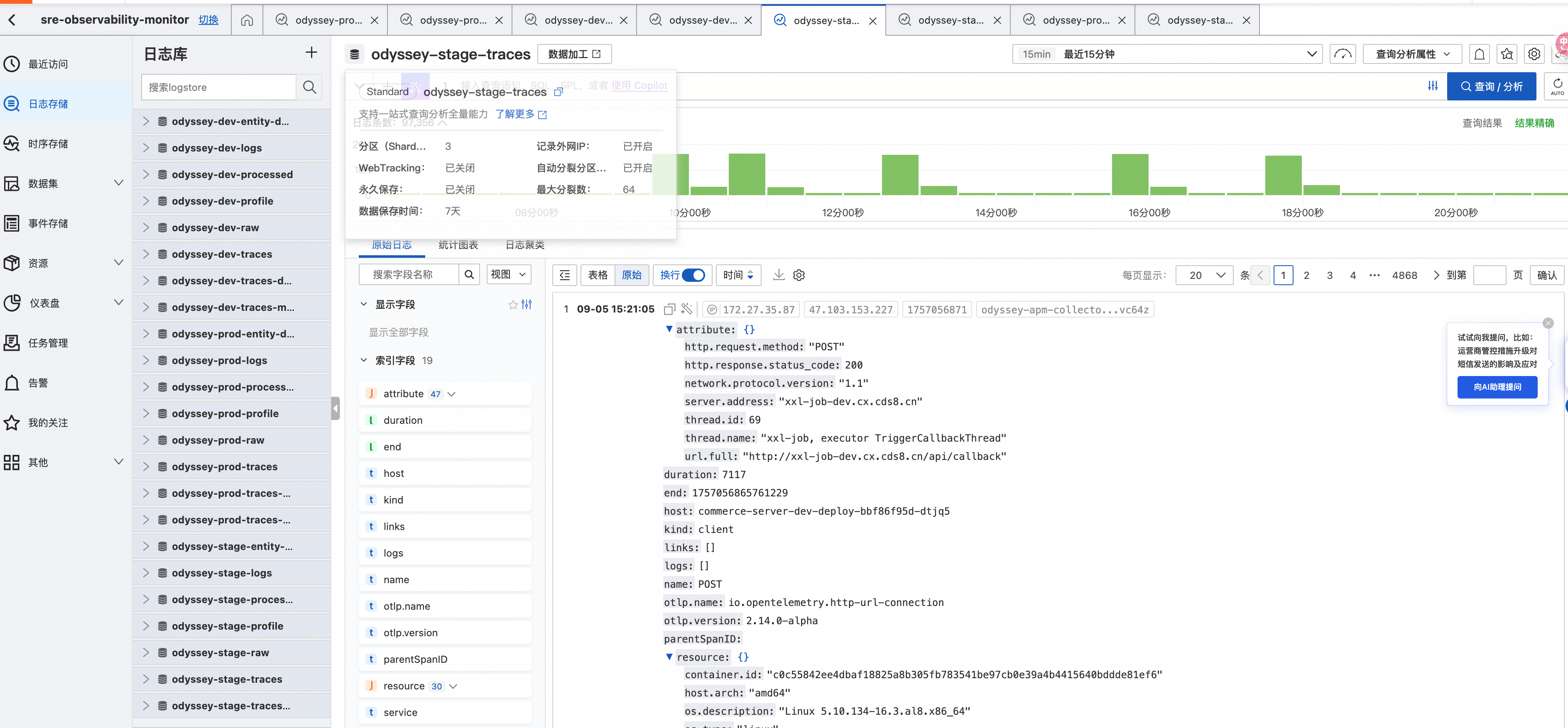
-
入口:SLS 控制臺 → sre-observability-monitor 項目 → odyssey-環境-traces 日志庫
-
查詢語法:```sql
- | SELECT \* FROM log WHERE service\_name = ‘user-service’ AND duration > 1000```
服務拓撲

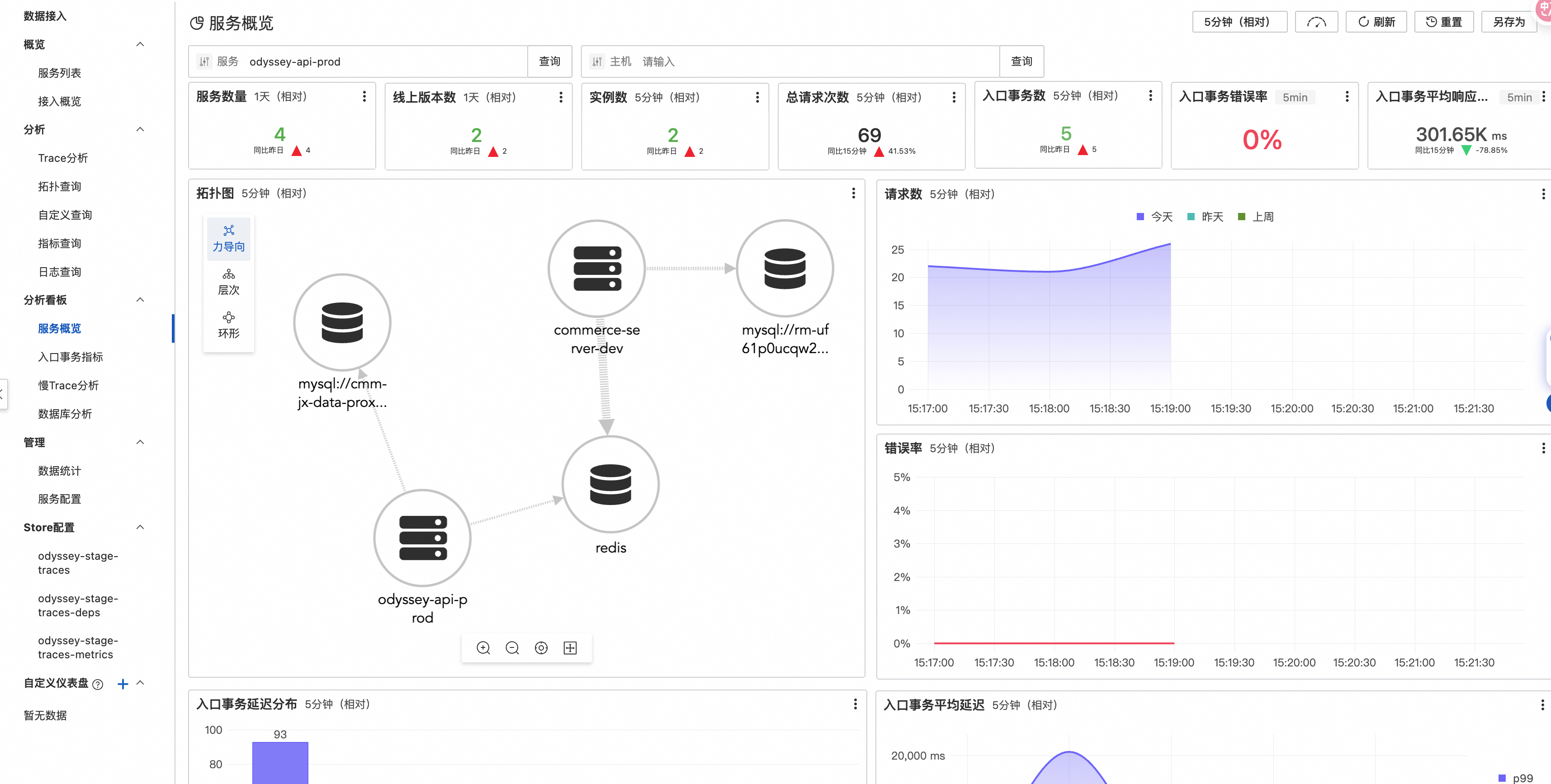
-
自動生成:基于 Trace 數據自動構建服務依賴關系圖
-
-
性能分析:展示服務間調用的延遲、錯誤率、吞吐量
7.2 自建 Grafana + Jaeger
https://apm.cds8.cn
sls自帶監控大盤只是為了方便我們前期使用,最終還是會自己部署grafana去完成數據的在線觀測,由于我們使用otel規范,所以可以很輕松的使用jaeger query插件完成trace的可視化展示,指標利用普羅米修斯去拉取指標數據即可。
Jaeger Query 部署
apiVersion: apps/v1
kind: Deployment
metadata:name: jaeger-query
spec:replicas: 1selector:matchLabels:app: jaeger-querytemplate:metadata:labels:app: jaeger-queryspec:containers:- name: jaeger-queryimage: jaegertracing/jaeger-query:latestenv:- name: SPAN_STORAGE_TYPEvalue: "elasticsearch"- name: ES_SERVER_URLSvalue: "http://elasticsearch:9200"ports:- containerPort: 16686
Grafana 數據源配置
-
添加 Jaeger 數據源:URL 指向 Jaeger Query 服務
-
添加 SLS 數據源:通過 SLS API 接入指標數據
-
創建綜合大盤:整合鏈路、指標、日志的統一視圖
八、監控告警策略
8.1 基礎設施監控
| 指標 | 閾值 | 告警級別 |
|---|---|---|
| OTel Collector CPU 使用率 | > 80% | Warning |
| OTel Collector 內存使用率 | > 85% | Warning |
| Operator Pod 狀態 | NotReady > 5min | Critical |
| SLS 上報失敗率 | > 5% | Warning |
8.2 應用觀測告警
| 指標 | 閾值 | 告警級別 |
|---|---|---|
| 服務響應時間 P99 | > 2s | Warning |
| 服務錯誤率 | > 1% | Warning |
| 服務錯誤率 | > 5% | Critical |
| 鏈路斷點 | 檢測到 | Warning |
九、性能優化與最佳實踐
9.1 采樣策略
分層采樣
-
生產環境:默認 10% 采樣率,關鍵服務 30%
-
測試環境:50% 采樣率
-
開發環境:100% 采樣率
動態采樣
# 高 QPS 服務降低采樣率
metadata:labels:odyssey-apm-sampling-rate: "0.1" # 10% 采樣# 關鍵業務服務提高采樣率
metadata:labels:odyssey-apm-sampling-rate: "0.5" # 50% 采樣
9.2 資源配置建議
OpenTelemetry Collector
-
CPU:每 1000 spans/s 需要約 100m CPU
-
內存:每 1000 spans/s 需要約 128Mi 內存
-
網絡:確保與 SLS 的網絡連通性穩定
K8s Operator
-
CPU:100m(輕量級,主要處理 K8s API 調用)
-
內存:128Mi
-
權限:需要 Deployment 的 get、list、watch、update 權限
9.3 故障排查指南
常見問題
-
應用無鏈路數據
-
檢查 Deployment 標簽是否正確
-
驗證 OTel Collector 是否正常運行
-
確認應用是否成功注入環境變量
-
-
鏈路數據不完整
-
檢查采樣率配置
-
驗證服務間網絡連通性
-
確認 SDK 版本兼容性
-
-
性能影響
-
調整采樣率
-
優化 Collector 資源配置
-
檢查 SLS 上報延遲
-
調試命令
# 查看 Operator 日志
kubectl logs -f deployment/odyssey-obser-operator -n odyssey-observability# 查看 Collector 狀態
kubectl get pods -l app=odyssey-otel-collector -n odyssey-observability# 測試 OTLP 端點連通性
kubectl exec -it <app-pod> -- telnet localhost 55680# 查看應用環境變量
kubectl exec -it <app-pod> -- env | grep OTEL
本文章為本人在公司內部的技術分享,已隱去關鍵信息,歡迎大家討論。
)








)


)






