論文信息
題目:Zero-Shot 3D Visual Grounding from Vision-Language Models
基于視覺語言模型的零樣本3D視覺定位
作者:Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, Junwei Liang
論文創新點
提出全新框架:論文提出SeeGround這一無需訓練的零樣本3D視覺定位框架,通過渲染視圖和空間文本,將3D場景重新組織成適用于2D視覺語言模型(2D-VLMs)的輸入。
設計動態視角選擇策略:設計了一種查詢引導的視角選擇策略,能動態選擇最優視角,既能捕捉特定對象線索,又能獲取空間上下文,從而提升模型對3D場景的理解和定位能力。
引入視覺提示機制:提出一種視覺提示機制,將2D圖像特征與3D空間描述對齊,減少在復雜場景中定位的模糊性,提高目標定位的準確性。
取得領先實驗結果:該方法在ScanRefer和Nr3D兩個標準基準測試上取得了零樣本設置下的最優結果,展現出強大的泛化能力,且無需針對3D數據進行特定訓練。
摘要
3D視覺定位(3DVG)旨在利用自然語言描述在3D場景中定位目標物體,這使得諸如增強現實和機器人技術等下游應用成為可能。現有的方法通常依賴有標記的3D數據和預定義的類別,限制了其在開放世界場景中的可擴展性。作者提出了SeeGround,這是一個零樣本3DVG框架,它利用2D視覺 - 語言模型(VLM)來避免對特定3D訓練的需求。為了彌合模態差距,作者引入了一種混合輸入格式,將與查詢對齊的渲染視圖與空間豐富的文本描述相結合。該框架包含兩個核心組件:一個視角適應模塊,它根據查詢動態選擇最佳視角;以及一個融合對齊模塊,它整合視覺和空間信號以提高定位精度。在ScanRefer和Nr3D上的大量評估證實,SeeGround相對于現有的零樣本基線有顯著改進,分別超過它們7.7%和7.1%,甚至可以與完全監督的方法相媲美,這表明它在具有挑戰性的條件下具有很強的泛化能力。
關鍵詞
3D視覺定位;零樣本學習;視覺 - 語言模型;跨模態對齊
一、引言
3D視覺定位(3DVG)專注于使用自然語言描述在3D場景中定位被提及的物體。這種能力在增強現實[1 - 6]、視覺 - 語言導航[7 - 9]和機器人感知[10 - 22]等應用中至關重要。解決這一任務需要在雜亂多樣的3D環境中同時具備語言理解和空間推理能力。
大多數現有方法依賴于使用有限的、標注繁重的數據集來訓練特定任務的模型[1, 23 - 28],這限制了它們的泛化能力。將這些模型擴展到更廣泛的場景既耗費資源又不切實際[29 - 31]。最近的趨勢[32, 33]試圖通過納入大語言模型(LLM)[34, 35]來解釋重新格式化的文本查詢,以減少對3D監督的依賴。然而,這些策略往往忽略了關鍵的視覺屬性,如顏色、紋理、視角和空間布局,而這些對于精細定位至關重要(見圖1)。

為了克服這些限制,作者引入了SeeGround,這是一個無需訓練的3DVG框架,它利用2D視覺 - 語言模型(VLM)[35 - 37]的開放詞匯能力。這些模型在大規模圖像 - 文本語料庫上進行預訓練,具有很強的泛化能力,使其成為零樣本3DVG的理想選擇[24, 38]。由于VLM并非天生為3D輸入而設計,作者提出了一種跨模態對齊機制,通過查詢驅動的渲染和空間豐富的文本描述,將3D場景重新格式化為兼容的輸入。這種策略使得無需額外的特定3D訓練即可對3D內容進行推理[39]。
作者的表示結合了與查詢對齊的渲染2D圖像和從預先計算的物體檢測中導出的結構化空間文本。與靜態多視圖或鳥瞰投影不同,作者的查詢引導渲染動態地捕捉局部物體細節和全局上下文。空間文本提供了精確的語義和位置線索。為了進一步彌合語言和視覺之間的差距,作者納入了一種視覺提示技術,突出候選區域,引導VLM解決歧義并關注相關的圖像區域。
作者在兩個標準基準上驗證了該方法。在ScanRefer[1]上,SeeGround比先前的零樣本方法提高了7.7%,在Nr3D[40]上提高了7.1%,縮小了與完全監督模型的差距。值得注意的是,作者的方法在模糊或部分語言輸入的情況下仍然穩健,通過依賴視覺上下文來完成定位過程。
總之,作者的貢獻如下:
作者提出了SeeGround,這是一種用于零樣本3DVG的無需訓練的方法,它通過渲染視圖和空間文本將3D場景重新格式化為適合2D - VLM的輸入。
作者設計了一種查詢引導的視角選擇策略,以捕捉特定物體線索和空間上下文。
作者提出了一種視覺提示機制,將2D圖像特征與3D空間描述對齊,減少雜亂場景中的定位歧義。
作者的方法在ScanRefer和Nr3D上取得了零樣本的最先進結果,表明在無需特定3D訓練的情況下具有很強的泛化能力。
三、方法
(一)概述
3D視覺定位(3DVG)的目標是根據自然語言查詢在3D場景中定位目標物體,通過預測其對應的3D邊界框:。
作者提出了一種新穎的3DVG框架,該框架結合2D視覺 - 語言模型(2D - VLM)與空間豐富的3D表示。由于傳統的3D數據格式與2D - VLM的輸入模態不兼容,作者提出了一種混合表示,將渲染的2D視圖與結構化的3D空間描述相融合。這使得2D - VLM能夠在無需特定3D重新訓練的情況下,對視覺和空間信息進行聯合推理。
該框架由三個主要組件組成:(1)一個多模態3D表示模塊(3.1節);(2)一個視角適應模塊(3.2節);(3)一個融合對齊模塊(3.3節)。這種架構通過充分利用預訓練的2D - VLM的優勢,能夠在復雜的3D場景中準確地解釋和定位物體。框架概述如圖2所示。
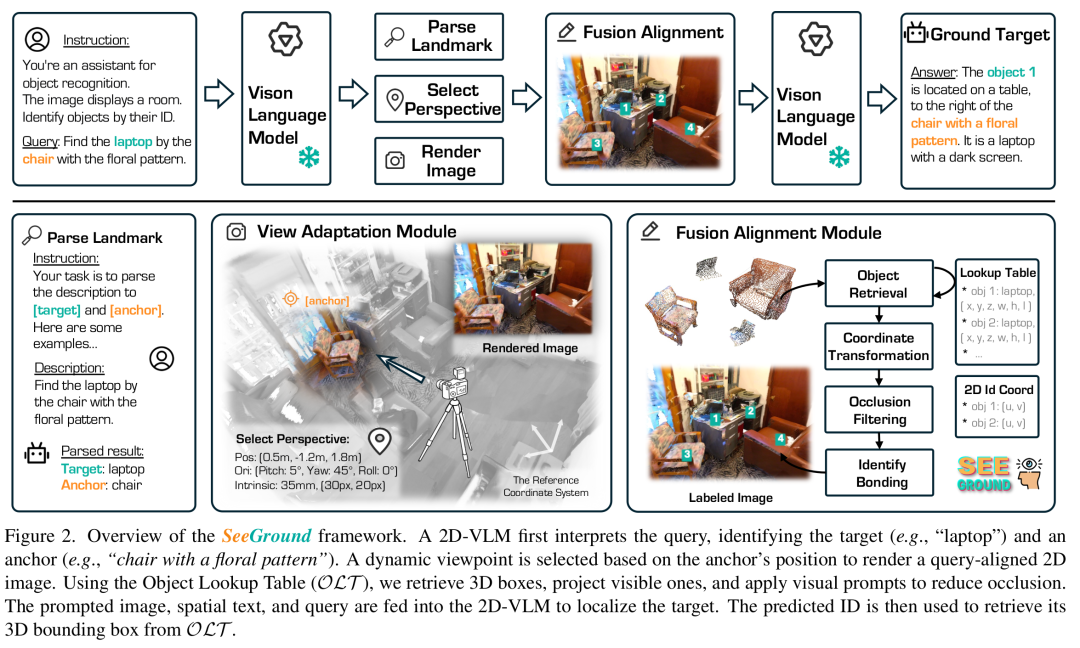
(二)多模態3D表示
作者利用在大規模圖像 - 文本數據上預訓練的2D視覺 - 語言模型(2D - VLM),以實現對新物體的開放集理解。然而,傳統的3D表示,如點云[53, 70]、體素[71]和隱式場[54],本質上與2D - VLM期望的輸入格式不兼容。為了彌合這一差距,作者提出了一種混合表示,將2D渲染圖像與基于文本的3D空間描述相結合。
基于文本的3D空間描述:作者首先使用一個開放詞匯的3D檢測器檢測場景中的所有物體:其中和分別表示每個物體的3D邊界框和語義標簽。這些輸出被轉換為自然語言并存儲在一個物體查找表(OLT)中以供重用:OLT作為物體級空間信息的結構化存儲庫,支持高效推理,并避免在多個查詢中進行冗余計算。
混合3D場景表示:雖然文本描述編碼了布局和語義,但它們缺乏精細的視覺線索。為了補充這一點,作者渲染與輸入查詢對齊的2D圖像:其中是渲染圖像,是相應的空間描述文本。這種配對使2D - VLM能夠同時訪問視覺外觀線索(如顏色、紋理、形狀)和準確的3D空間語義,有助于全面的場景理解。
(三)視角適應模塊
現有的視圖選擇策略通常無法與查詢所隱含的視角對齊。例如,LAR[43]渲染以物體為中心的多視圖,但缺乏全局場景上下文,而鳥瞰視圖提供了全面的空間覆蓋,但省略了垂直信息,導致遮擋和誤解(見圖3(a))。多視圖或多尺度方法[59]改善了覆蓋范圍(見圖3(b) - (d)),但仍然依賴靜態視角。此外,當渲染的視角不能反映語言查詢時,2D - VLM可能會誤解場景。因此,作者引入了一種查詢驅動的動態渲染策略,使視角與查詢意圖對齊,捕捉更多相關的空間和視覺細節(見圖3(e))。
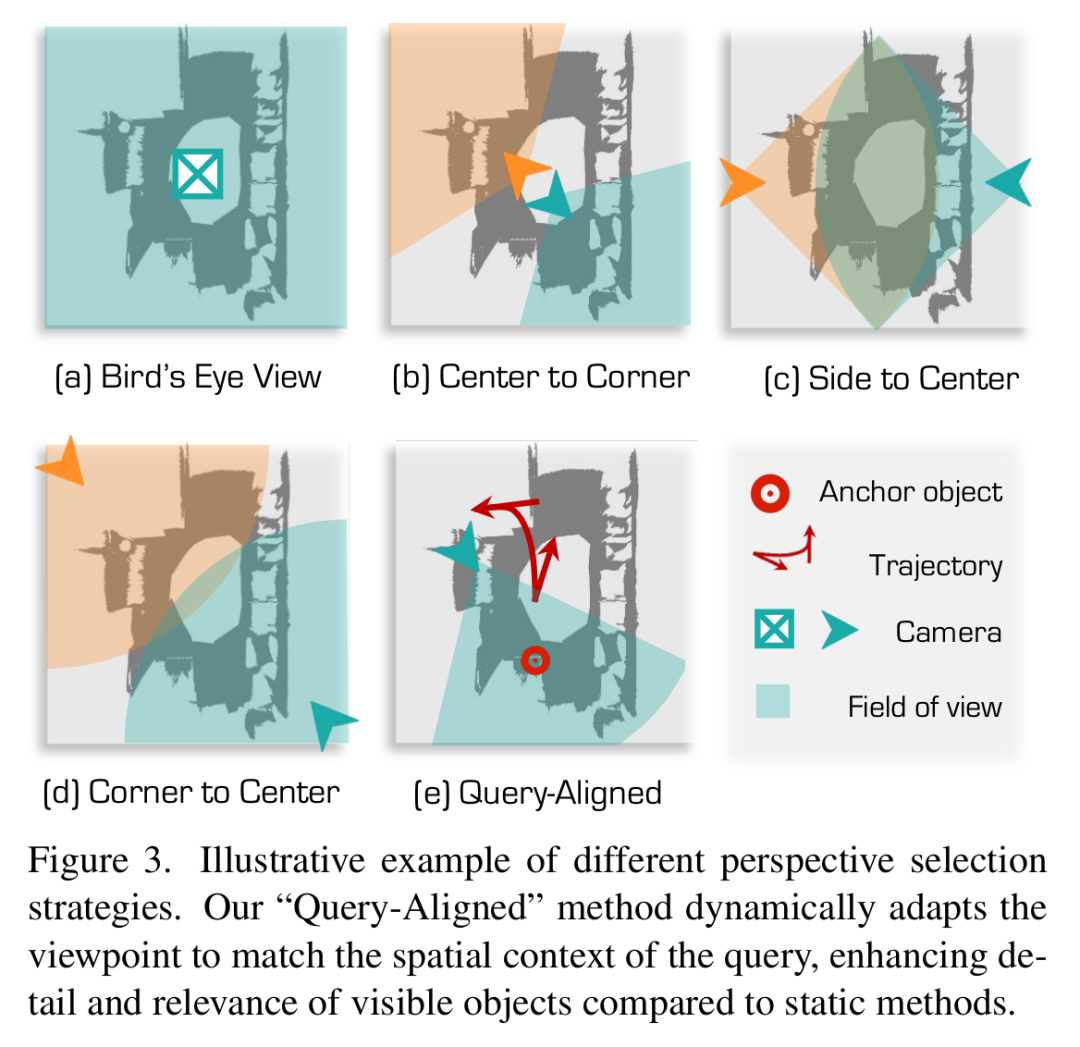
動態視角選擇:給定查詢,2D - VLM使用少樣本提示識別一個錨點物體和一組候選目標:作者將虛擬相機放置在場景中心,面向錨點物體,并將其向后和向上移動以增強可見性和上下文。如果無法自信地提取錨點(例如,在多物體或模糊查詢中),作者默認使用位于質心的偽錨點,并應用相同的相機放置策略。
查詢對齊圖像渲染:基于選定的視角,作者使用look - at - view - transform函數計算相機姿態,該函數產生相對于的旋轉和平移。然后獲得渲染圖像為。這種查詢對齊的渲染保留了關鍵的視覺特征,同時過濾掉無關的雜亂信息,使2D - VLM能夠更準確地定位被提及的物體(見圖3(e))。
(四)融合對齊模塊
雖然2D圖像和空間描述提供了互補信息,但直接將它們輸入2D - VLM可能無法將視覺線索與相應的3D語義相關聯,特別是在包含相似實例的場景中(例如,多個椅子),這通常會導致定位錯誤。為了解決這個問題,作者引入了一個融合對齊模塊,明確地將2D視覺特征與空間定位的物體描述對齊。
深度感知視覺提示:給定渲染圖像,作者從物體查找表OLT中檢索每個物體的3D點,并使用相機姿態將它們投影到圖像平面上。為了處理遮擋,作者將每個點的深度與渲染的深度圖進行比較,只保留可見點。對于每個物體,作者在其可見投影的中心放置一個視覺提示。生成的提示圖像為:其中是屬于物體的可見像素的指示掩碼。
使用2D - VLM進行物體預測:最后,給定自然語言查詢、提示圖像和結構化空間描述,2D - VLM預測被提及的物體:通過強制視覺和空間模態之間的對齊,該模塊有效地減少了定位歧義,并提高了在雜亂場景中的物體定位能力。
四、實驗
(一)實驗設置
數據集:作者在兩個廣泛使用的3D視覺定位基準上評估方法。ScanRefer[1]包含800個ScanNet場景中的51,500個指代表達。Nr3D[40]包括通過雙人游戲收集的41,503個查詢。ScanRefer專注于稀疏點云定位,而Nr3D提供密集的3D邊界框注釋,能夠進行更精細的評估。
實現細節:在Nr3D驗證集上進行消融實驗。圖像以1000×1000分辨率渲染,排除頂部0.3 m以匹配封閉房間設置。作者遵循ZSVG3D[32]并使用Mask3D[58]進行一致的物體檢測。
(二)對比研究
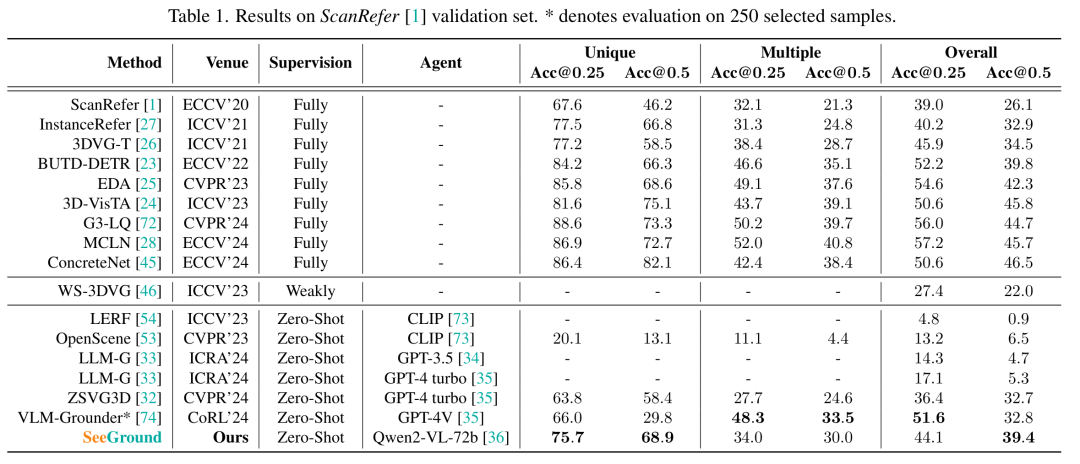
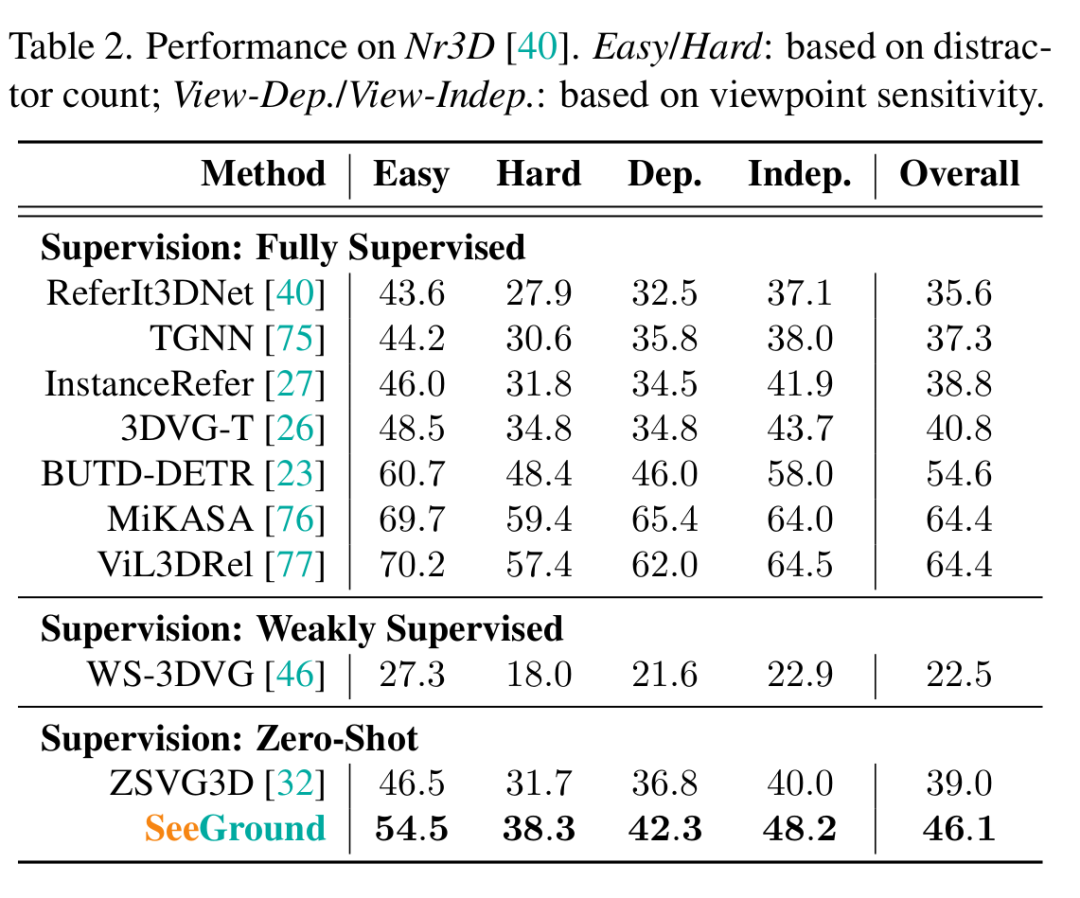
在ScanRefer上,作者的方法在“Unique”分割上的Acc@0.25 / Acc@0.5達到75.7% / 68.9%,在“Multiple”分割上達到34.0% / 30.0%,超過了所有現有的零樣本和弱監督基線[32, 33, 46],并接近完全監督方法的性能[28, 45]。在Nr3D上,作者的模型總體準確率達到46.1%,比之前零樣本的最先進方法高出7.1%[32]。它在不同子集上保持穩健,在“Easy” / “Hard”分割上達到54.5% / 38.3%,在“View - Dependent” / “View - Independent”分割上達到42.3% / 48.2%,有效地縮小了與完全監督方法的差距[23]。
(三)消融研究
架構設計的影響:作者首先評估所提出架構中每個組件的貢獻。結果總結在表3中。

場景布局:僅使用3D坐標(37.7%,表3(a))提供了粗略的物體位置,但準確率較低。通過3D邊界框的2D渲染(無紋理或顏色)納入場景布局(39.7%,表3(b)),引入了空間上下文,幫助模型推理物體的大小和位置。視覺線索:整合物體顏色/紋理(39.5%,表3(c))使模型能夠區分視覺上相似的物體,例如“白色”與“黑色”(圖4(a))。

融合對齊模塊:如表3(d)所示,添加作者提出的融合對齊模塊通過將渲染圖像與空間文本對齊,將準確率提高到43.3%,使模型能夠在雜亂場景中定位目標。
視角適應模塊:納入視角適應模塊(45.0%,表3(e))通過使視角與查詢所隱含的空間上下文對齊,提高了定位準確率(圖4(b))。這有助于解決歧義并增強空間推理。
完整配置:完整配置(表3(f))實現了最高準確率(46.1%),驗證了SEEGROUND的有效性以及所有組件結合的協同效益。 2.?作者方法與現有方法對比:ZSVG3D[32]通過投影物體中心并應用預定義的啟發式方法來推斷空間關系,但缺乏靈活性,省略了視覺上下文,并且在檢測不完善時會失敗(圖6)。如圖5a所示,其基于VLM的變體僅渲染目標和錨點中心而無背景。相比之下,作者的方法生成全場景渲染,能夠利用周圍的視覺線索對未檢測到或模糊的物體進行推理。
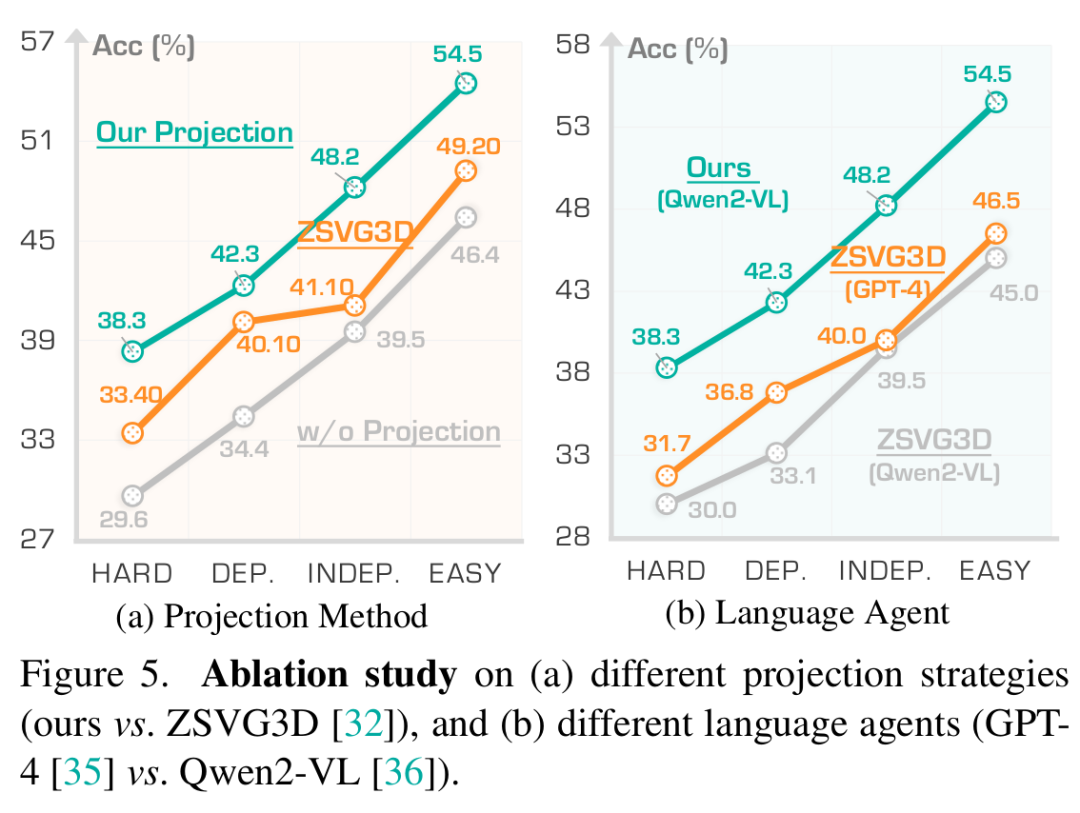
Qwen2 - VL與GPT - 4對比:為了提高可及性和可重復性,作者采用開源的Qwen2 - VL[36]作為智能體。為了進行公平比較,作者使用Qwen2 - VL代替GPT - 4[35]重新評估ZSVG3D(圖5b)。在相同的VLM下,作者的方法始終優于ZSVG3D,證實了作者策略的有效性,與底層語言模型無關。
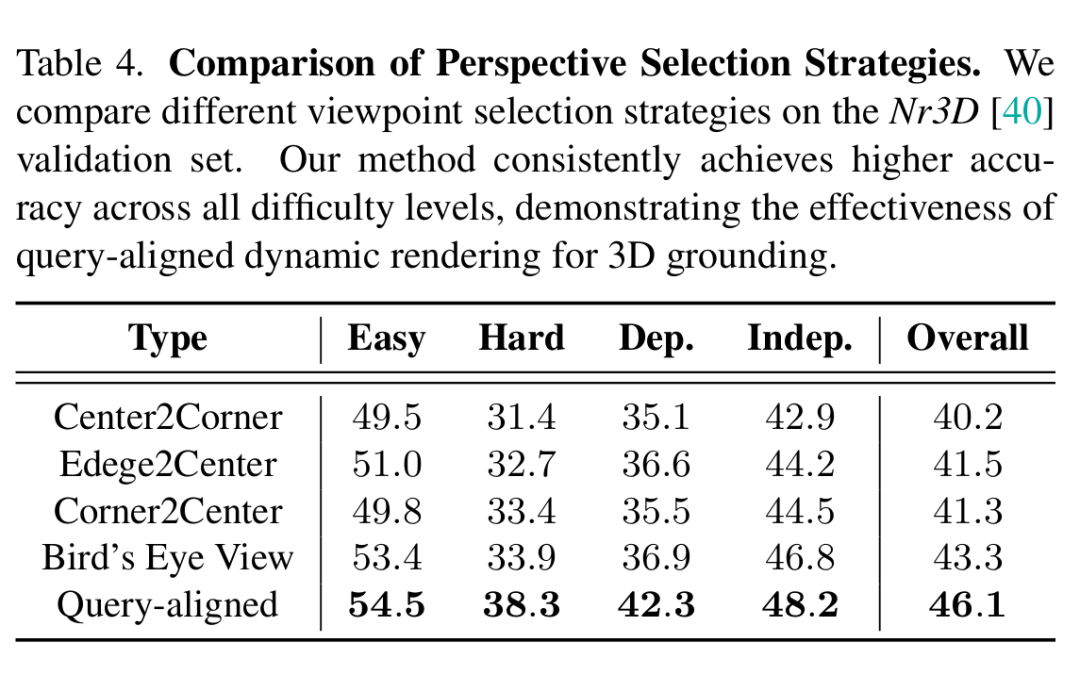
視圖選擇策略的影響:表4顯示了不同視角策略的影響。作者的查詢驅動方法優于靜態基線。固定方法(Center2Corner、Edge2Center、Corner2Center)缺乏適應性,而鳥瞰視圖(BEV)雖然具有全局性,但錯過了關鍵的空間線索,如方向和高度。相比之下,作者的動態策略實現了持續的提升,特別是在Hard(+4.4%)和View - Dependent(+5.7%)查詢上。
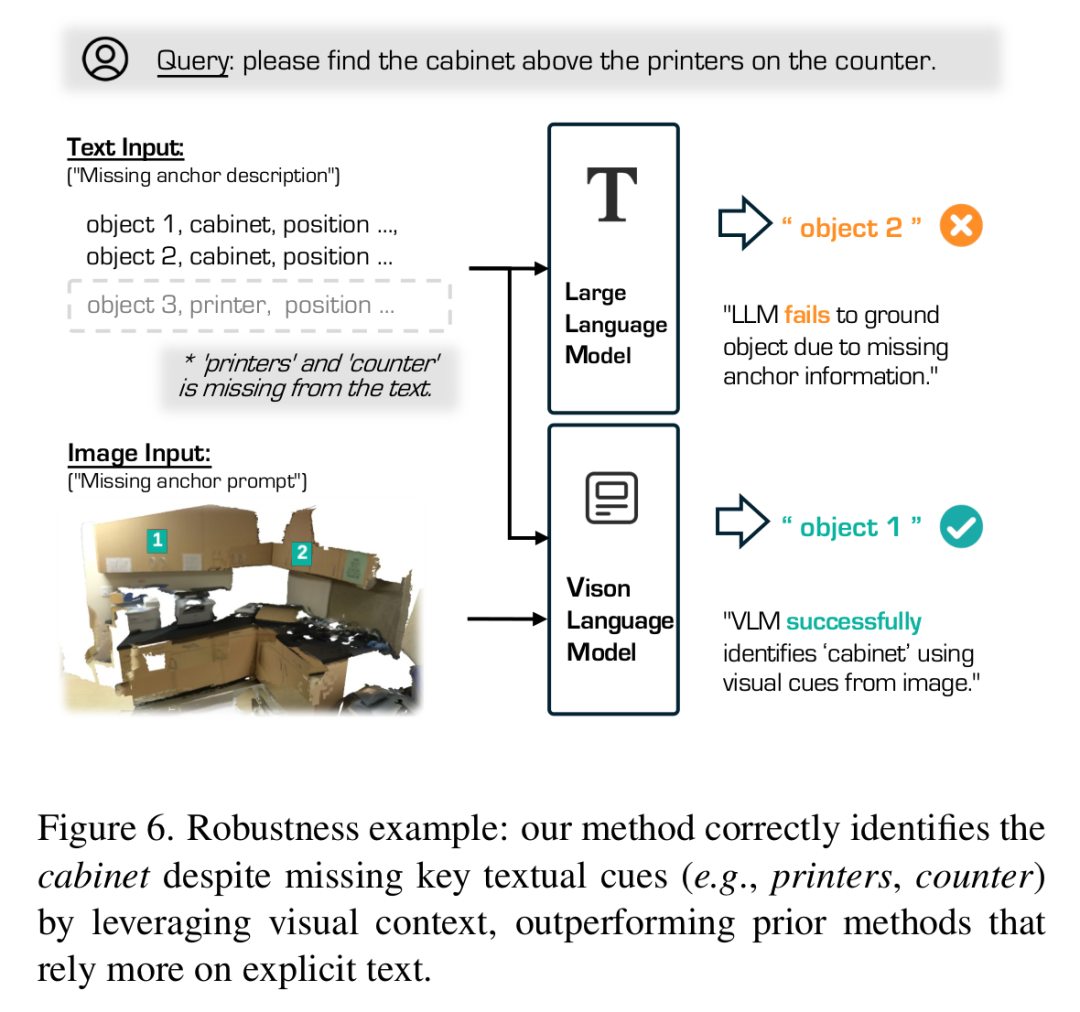
不完整文本描述下的魯棒性評估:圖6顯示了作者模型在不完整查詢下的魯棒性,其中省略錨點物體以模擬檢測失敗。雖然基于LLM的方法在沒有錨點線索時顯著下降,但作者的方法成功利用視覺上下文保持準確的定位。這些結果強調了整合視覺和文本信號對于穩健3D理解的重要性。
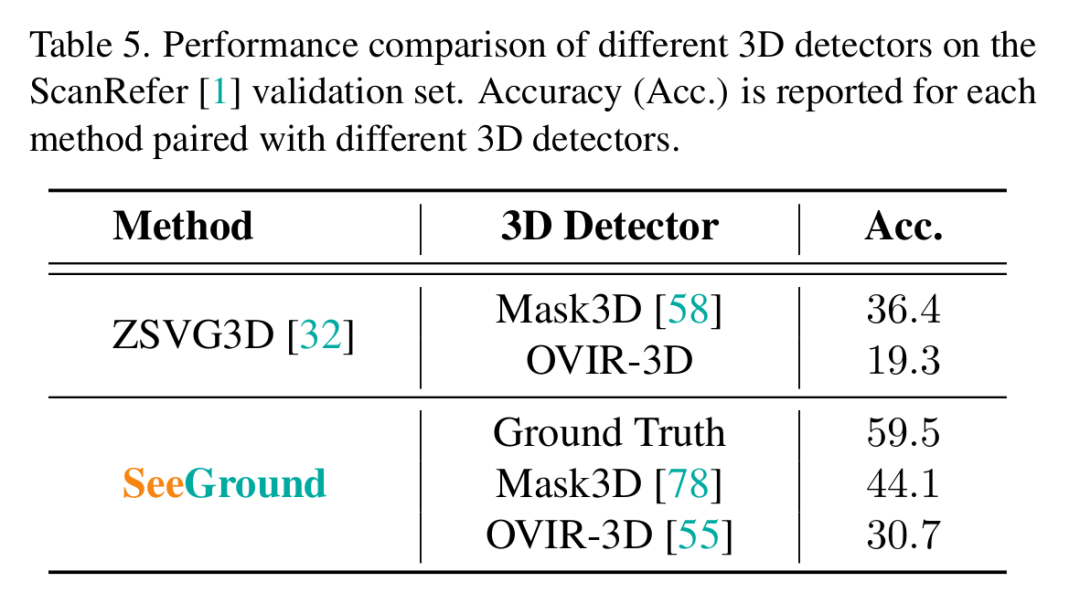
不同檢測器上的結果:表5比較了不同3D檢測器的性能。使用Mask3D時,作者的方法達到44.1%,顯著超過ZSVG3D(36.4%)。使用OVIR - 3D時,作者的性能仍然更高(30.7%對19.3%)。當提供真實(GT)框時,作者的方法達到59.5%,揭示了明顯的性能上限。
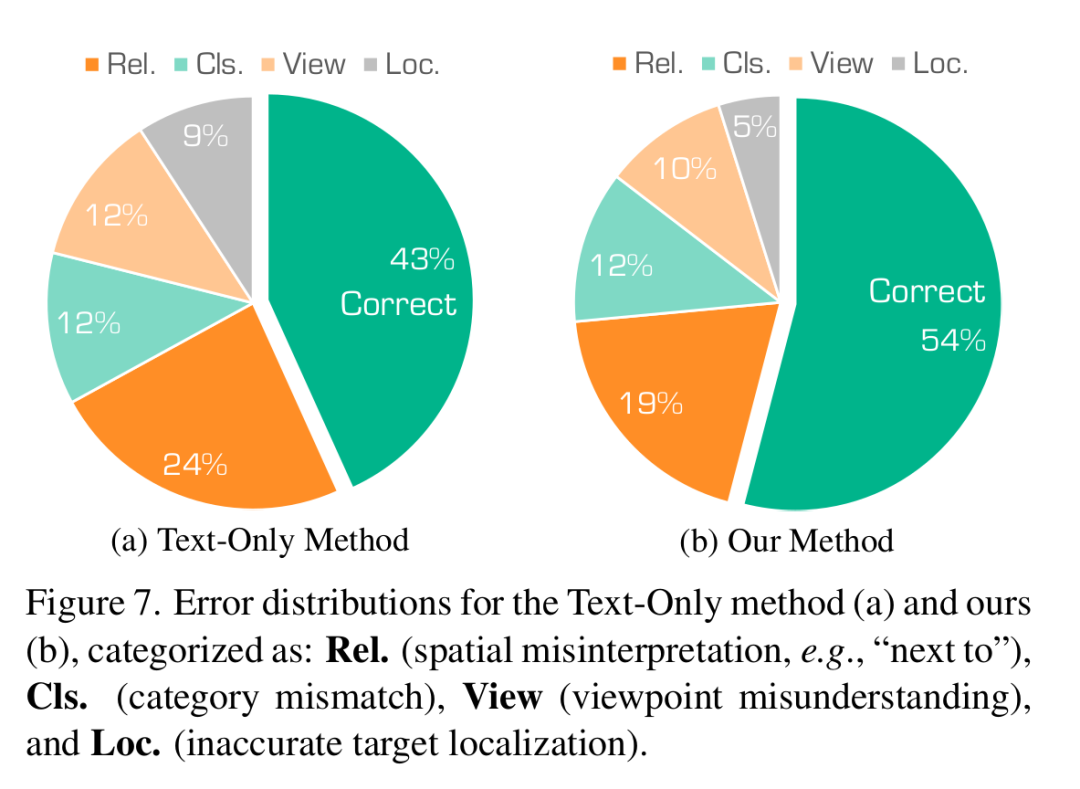
類型錯誤分析:作者從10個場景中隨機采樣185個案例,以識別常見的失敗模式(圖7)。定位和分類錯誤的減少表明視覺輸入對空間理解的益處。然而,空間關系錯誤仍然頻繁(19%),這表明在精細推理方面的局限性,可以通過專門的空間模塊來解決。作者當前的視角選擇在復雜的以自我為中心的引用(例如,“當窗戶在左邊時”,“從門進入時”)方面也存在困難。此外,由于使用原始數據集點云,渲染質量有限,阻礙了物體的區分。未來的工作可以納入高保真渲染,以增強雜亂場景中的視覺清晰度。
五、結論
在本文中,作者提出了SeeGround,這是一個零樣本3D視覺定位框架,通過查詢對齊的渲染和空間描述彌合了3D數據與2D視覺 - 語言模型之間的差距。作者的視角適應模塊動態選擇視角,而融合對齊模塊對齊視覺和空間線索以實現穩健的定位。在兩個基準上的實驗表明,作者的方法優于零樣本基線。
聲明
本文內容為論文學習收獲分享,受限于知識能力,本文對原文的理解可能存在偏差,最終內容以原論文為準。本文信息旨在傳播和學術交流,其內容由作者負責,不代表本號觀點。文中作品文字、圖片等如涉及內容、版權和其他問題,請及時與我們聯系,我們將在第一時間回復并處理。
)













》)




