一、簡介
1. 什么是時序數據庫?
時序數據庫是專門用于存儲和處理時間序列數據的數據庫系統。
時間序列數據是指按時間順序索引的一系列數據點。每個數據點都包含:
一個時間戳:記錄數據產生的時間。
一個或多個指標值:例如溫度、濕度、CPU使用率、股價、銷售額等。
一組標簽:用于標識數據的來源和屬性,例如設備ID、傳感器類型、地理位置、股票代碼等。
核心思想:數據是按時間流入的,查詢也總是圍繞時間區間展開。
2. 時序數據的特點
時序數據有其獨特的模式,這與傳統的關系型數據(如訂單、用戶信息)截然不同:
海量性:數據源源不斷地產生,數據量巨大。一個傳感器每秒鐘上報一次數據,一年就能產生3150萬條記錄。
時效性:新數據按時間順序追加,幾乎不會有舊數據的更新或刪除操作。
冷熱分明:越新的數據被查詢和使用的頻率越高(熱數據),越老的數據被訪問的頻率越低(冷數據)。
多寫少讀:95%以上的操作是寫入(插入新的數據點),讀取操作相對較少,但查詢模式復雜。
高并發寫入:通常需要同時接收來自成千上萬個設備或代理的高并發寫入請求。
3. 為什么需要專門的時序數據庫?
傳統關系型數據庫(如 MySQL, PostgreSQL)在處理時序數據時會遇到巨大挑戰:
寫入瓶頸:頻繁的INSERT操作會產生大量寫入負載,關系型數據庫的B+樹索引在大量寫入時維護成本極高,容易成為瓶頸。
存儲成本高:原始數據不經壓縮直接存儲,占用空間巨大。
查詢效率低:基于時間的范圍查詢、聚合查詢(如求1小時內的平均值、最大值)性能很差,尤其是在海量數據中。
數據生命周期管理困難:難以高效地自動刪除過期數據(數據降采樣和保留策略)。
時序數據庫正是為了解決這些痛點而設計的。
4. 時序數據庫的核心技術與優勢
列式存儲
傳統數據庫是行式存儲,一行數據(所有列)存儲在一起,適合OLTP事務。
時序數據庫采用列式存儲,將同一列的數據存儲在一起。這對于聚合查詢(如求所有設備在某個時間段的平均溫度)極其高效,因為只需要讀取特定的列,I/O效率極高。
高效壓縮
由于指標值在時間上通常緩慢變化或具有重復性(如
true/false狀態),列式存儲非常適合壓縮。常用的壓縮算法如 Gorilla、Delta-of-delta、Simple-8b 等,可以將數據壓縮到原始大小的十分之一甚至二十分之一,極大地降低了存儲成本。
專為時間優化的索引
時序數據庫通常對時間戳建立主索引,使其能快速定位到某個時間范圍內的數據。
對標簽建立倒排索引或其他高效索引,使得能快速過濾出某個特定設備或某類設備的數據。
這種“時間戳 + 標簽”的索引組合,完美契合了“查詢某設備在某時間段內的數據”這類典型場景。
數據降采樣與保留策略
保留策略:可以自動刪除超過指定時間的老數據,釋放存儲空間。
降采樣:可以自動將高精度的原始數據(如每秒一次)聚合計算成低精度的數據(如每小時的平均值),并存儲下來。這樣在查詢歷史趨勢時,可以使用降采樣后的數據,極大地提升查詢速度并節省存儲空間。
強大的聚合函數和連續查詢
內置了大量針對時序數據的聚合函數(
MEAN,?SUM,?MAX,?MIN,?MEDIAN,?DERIVATIVE(求導)等)。支持連續查詢,可以定期自動執行聚合查詢并將結果存入另一張表,用于實現實時儀表盤或告警。
5. 常見的時序數據庫
InfluxDB:Go語言編寫,是目前最流行、生態最完善的時序數據庫之一。開源版和商業版功能有差異。
Prometheus:CNCF畢業項目,起源于監控系統,其存儲引擎是專為監控場景設計的時序數據庫。是 Kubernetes 生態中的監控事實標準。
TimescaleDB:基于 PostgreSQL 的擴展,將其轉變為一個全功能的時序數據庫。優勢是支持完整的SQL,能與現有PostgreSQL生態無縫集成。
TDengine:國產優秀的時序數據庫,以其極高的性能和壓縮比著稱。開源版和商業版并行。
OpenTSDB:基于 Hadoop 和 HBase 構建,歷史悠久,適合大規模集群。
QuestDB:一個高性能、開源的時序數據庫,專注于速度和易用性。
6. 典型應用場景
監控系統:IT基礎設施監控(服務器CPU、內存、磁盤IO)、應用性能監控(APM)、微服務鏈路追蹤。
物聯網:智能家居傳感器數據、工業物聯網設備狀態監控、車聯網車輛軌跡與狀態。
金融科技:實時股價、交易記錄、風險控制指標、欺詐檢測。
** DevOps與SRE**:服務性能指標、日志事件的時間序列化分析。
商業智能:網站實時訪問量、廣告點擊率、銷售額隨時間的變化趨勢。
總結對比
| 特性 | 時序數據庫 | 傳統關系型數據庫 |
|---|---|---|
| 數據模型 | 基于時間戳和標簽 | 基于行和表的關系模型 |
| 寫入模式 | 高并發、追加寫入 | 隨機讀寫、更新、刪除 |
| 存儲效率 | 極高(列式存儲+高效壓縮) | 較低 |
| 典型查詢 | 時間范圍聚合、分組 | 關聯查詢、事務、點查 |
| 擴展性 | 易于水平擴展(分片) | 垂直擴展或復雜的分庫分表 |
總而言之,時序數據庫是應對海量時間序列數據挑戰的專用工具,它在寫入性能、存儲成本和時序查詢效率方面相比傳統數據庫有數量級的提升,是構建現代監控、物聯網和分析系統不可或缺的基礎組件。
二、安裝
1. 拉取鏡像
sudo docker pull apache/iotdb:1.3.2-standalone
2.啟動和運行容器
注意:這個命令啟動的容器不能退出終端,退出后所有表都刪除了,再次登錄需要重新建表。這里僅作演示用。
docker run --rm -p 6667:6667 --name iotdb apache/iotdb:1.3.2-standalone?
當控制臺出現這樣的提示則表明啟動成功:
o.a.i.db.service.DataNode:227 - Congratulations, IoTDB DataNode is set up successfully. Now, enjoy yourself!?
下載好后,可以安裝dbeaver對時序數據進行可視化操作。
3. 安裝dbeaver
下載地址:https://dbeaver.io/files/7.2.5/
4. dbeaver連接iotdb
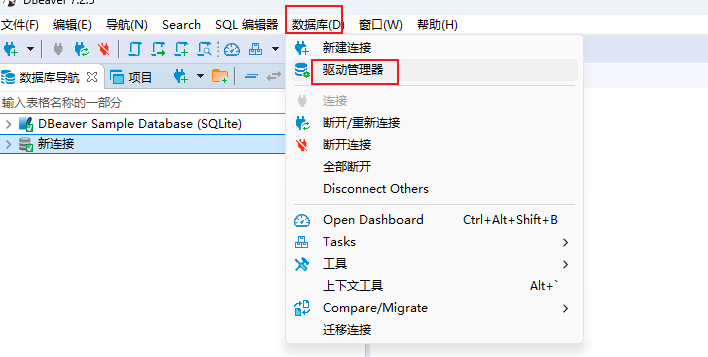
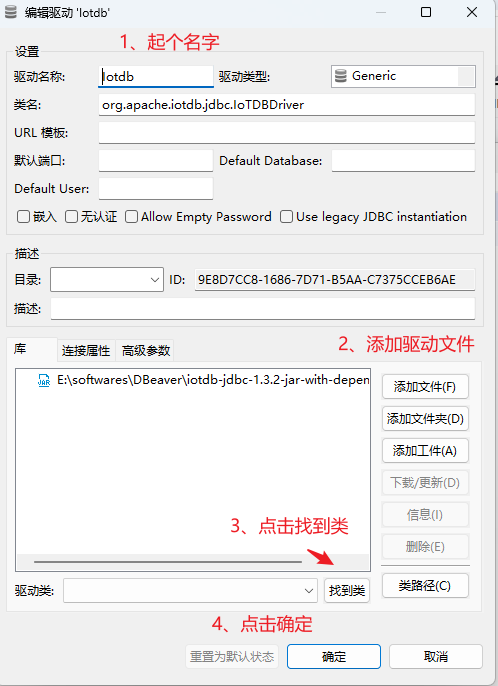
4.1 添加iotdb驅動 (數據庫->驅動管理器)
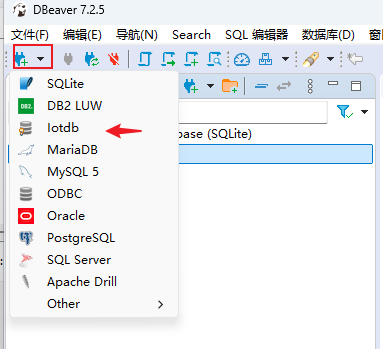
4.2 建立iotdb連接
4.2.1 選中iotdb驅動
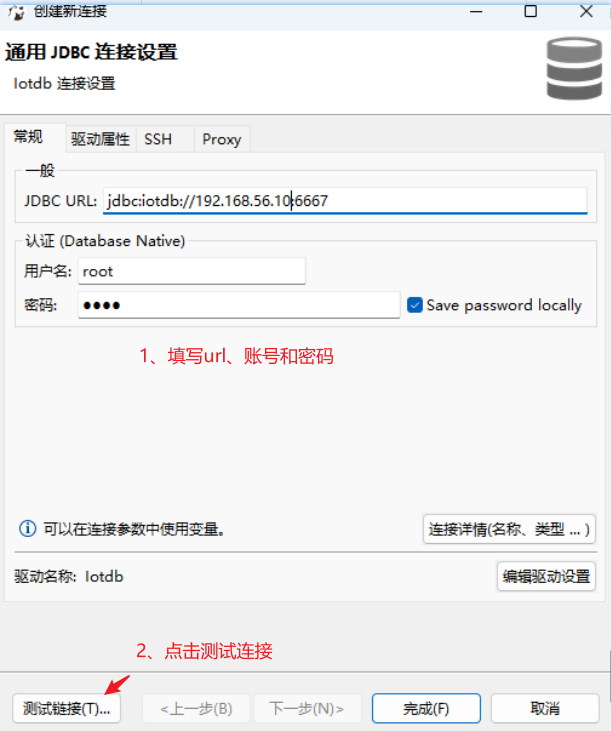
4.2.2 JDBC URL: jdbc:iotdb://ip:6667 #ip替換為數據庫所在服務器的ip
默認賬號?用戶名: root??密碼: root



)




)
:含宮崎駿森系、鴨風人像、國潮等多風格 + 視頻導入教程)
)




使用“BeautifulSoup“按類名獲取內容)



)