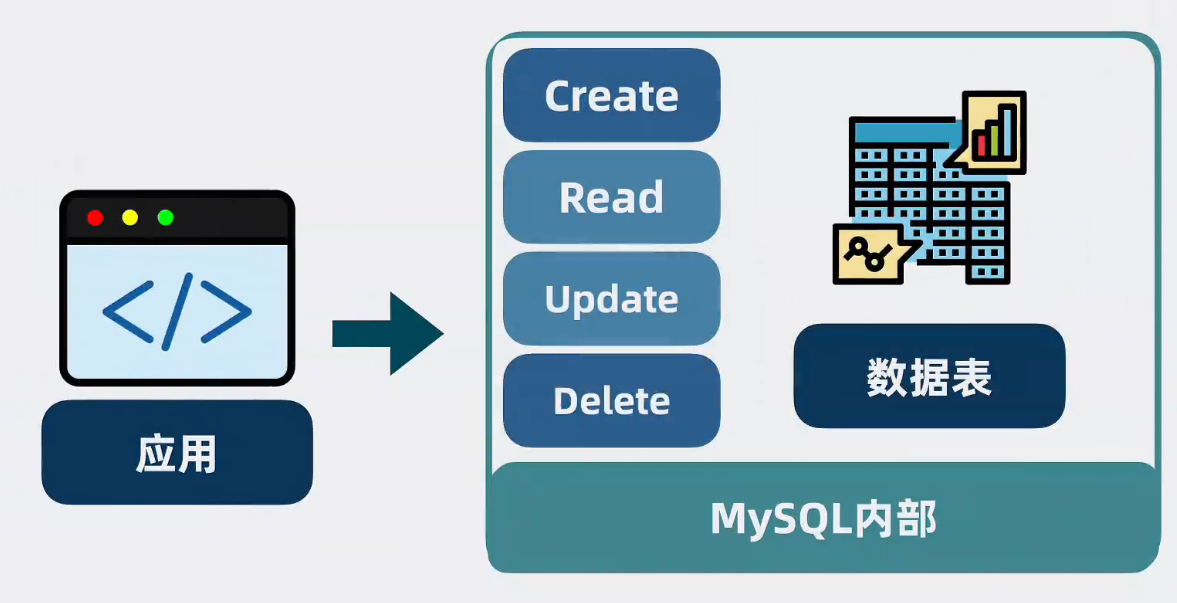
Mysql介于應用和數據之間,通過一些設計 ,將大量數據變成一張張像excel的數據表
數據頁:
mysql將數據拆成一個一個的數據頁
索引:
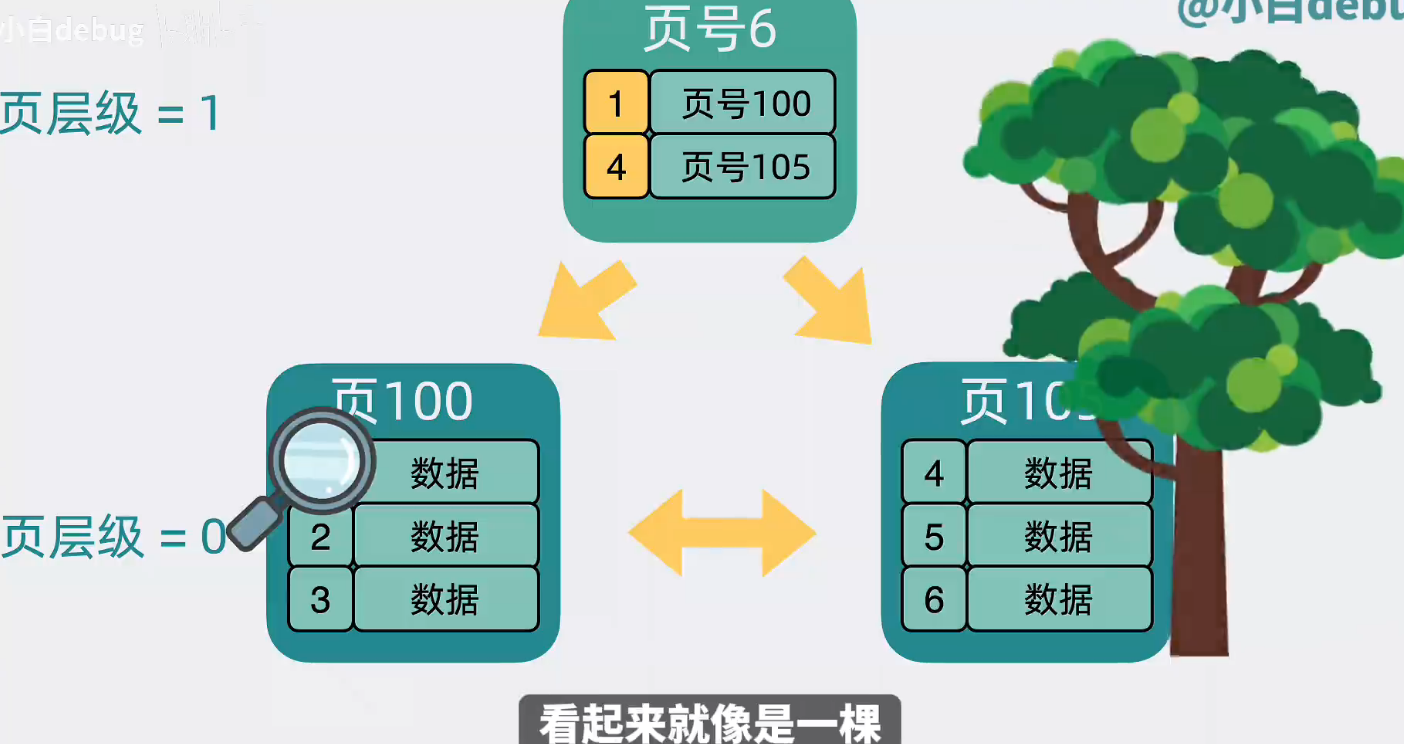
為每個頁加入頁號,再為每行數據加入序號,這個序號就是所謂的主鍵。? 將每個頁的頁號和所在頁最小的主鍵提出來,放入到一個新生成的數據頁中,并且給數據也加入層級的概念,這樣就可以根據上層的數據頁,快速縮小查找范圍,加速查找數據頁的過程。現在頁和頁之間看起來就像是一顆樹,這個可以加速查找數據頁的樹,就是常說的b+樹索引
除了主鍵索引,也可以為其他數據表的列(字段)去建立索引,這就是輔助索引
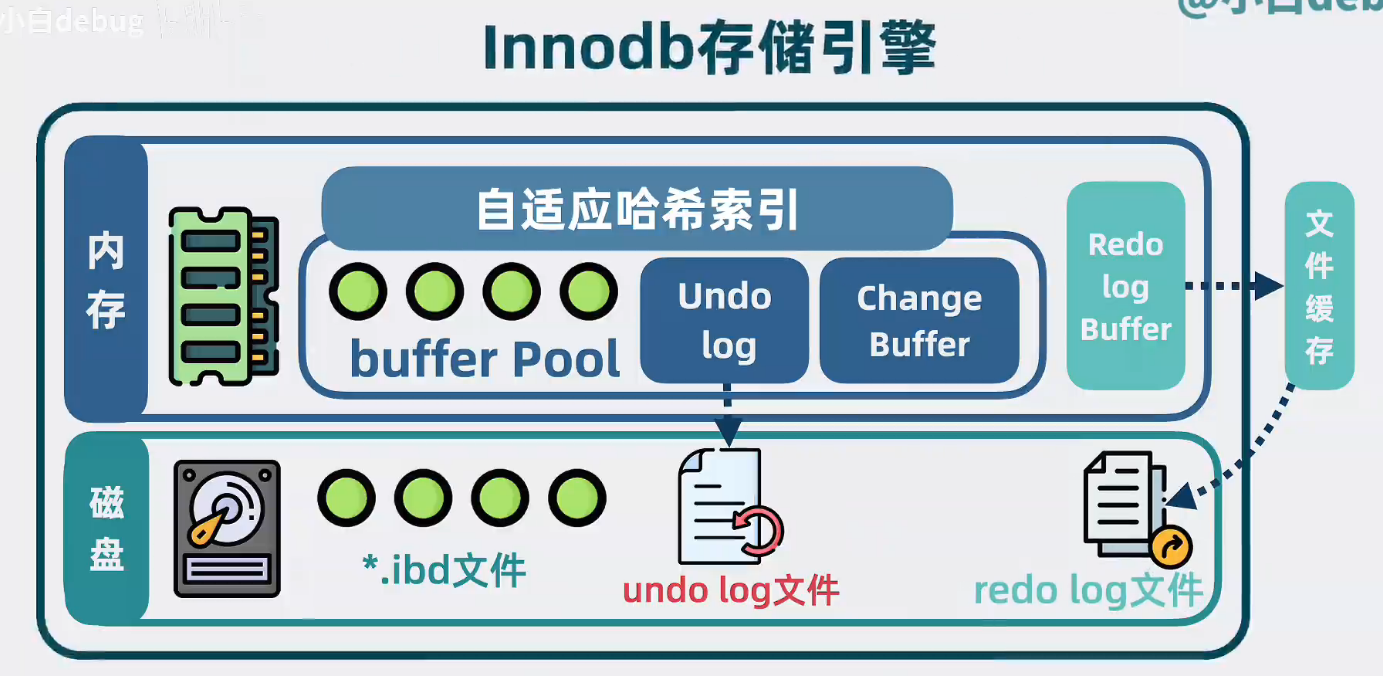
Buffer Pool
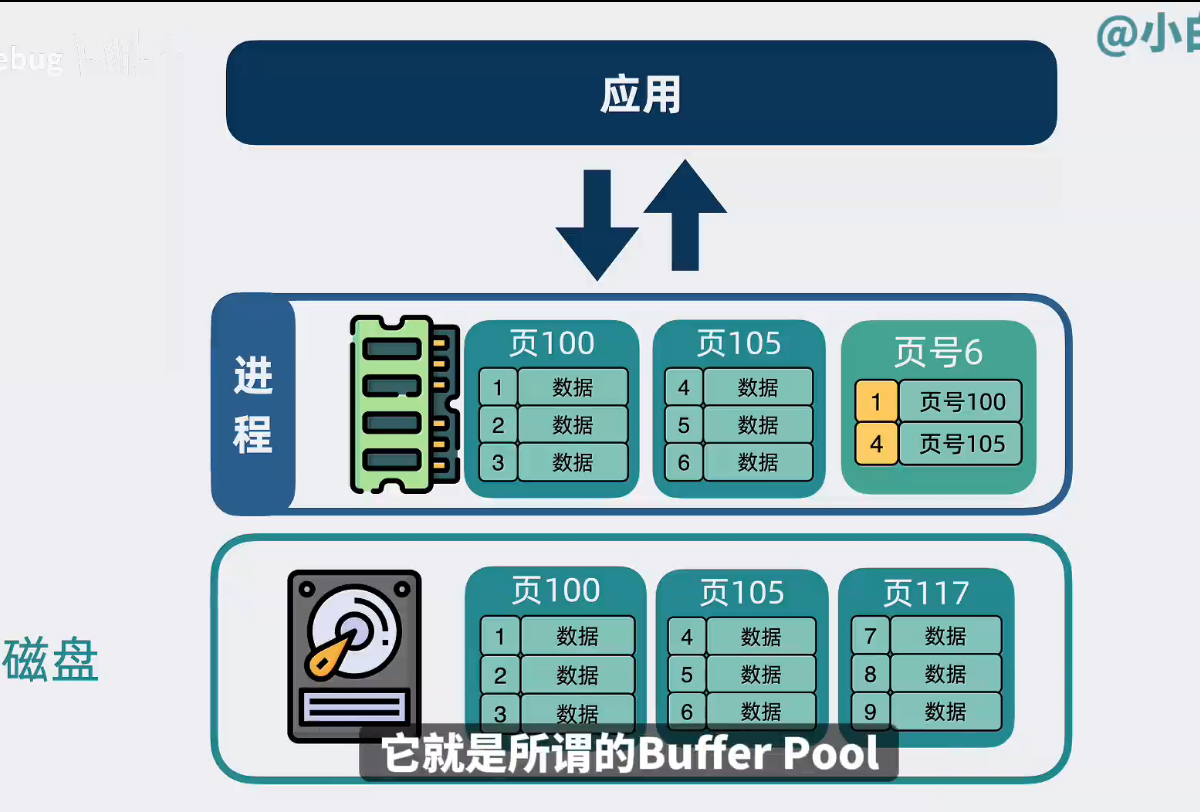
應用和磁盤間,加一層緩存,緩存里裝的就是索引頁和部分數據(先讀buffer pool,有對應數據就返回,沒數據就去磁盤找)
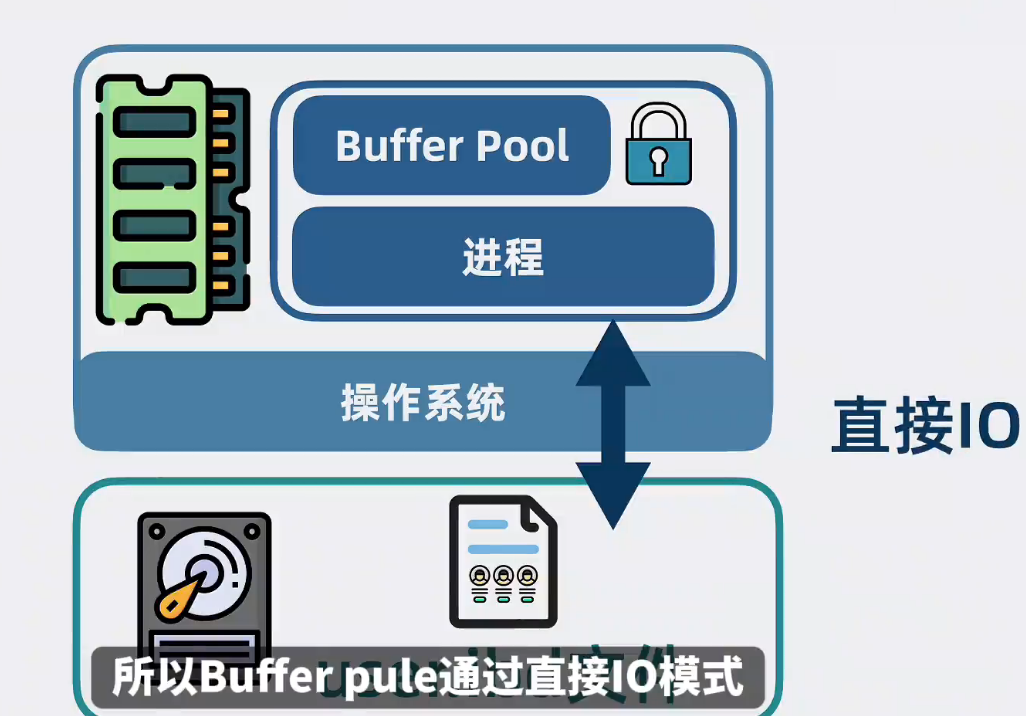
進程自己維護的Buffer Pool可以定制更多緩存策略,還能實現加鎖等各種數據表高級特性,所以有了Buffer Poll,就沒必要使用操作系統的文件緩存了。Buffer Pool通過直接IO模式,繞過操作系統的緩存機制,直接從磁盤讀取數據
直接IO方式是指繞過操作系統的緩存機制,直接從磁盤中讀取到用戶態空間緩沖區,避免了數據從磁盤拷貝到內核態緩沖區,再從內核態緩存區拷貝到用戶態緩沖區的兩次復制,所以大大提升了性能
自適應哈希索引
就算有了Buffer,Poll,要查到某個數據也,也依然要查找B+樹,查詢復雜度O(lgn).可以使用查詢你速度為O(1)的哈希表進行優化,記錄每個數據頁的查詢頻率,對于熱點數據頁,以查詢的值為key,數據頁地址為value構建哈希表
ChangeBuffer
大部分數據表除了主鍵索引外,還會加一些輔助索引。那對于這類數據表的寫操作,更新完主鍵索引的數據頁之后還需要更新輔助索引頁,這樣,讀取輔助索引頁的磁盤IO必然少不了
可以先將要寫入的數據收集到一塊內存里(這就是ChangeBuffer),等哪天磁盤里的索引頁正好被讀入Buffer Pool的時候,再將寫入數據應用到索引頁中,通過這個方式,減少了大量的磁盤IO提升性能
Undo Log
在數據庫中有一個叫事物的概(就是可以讓多行數據要么同時更新成功,要么同時失敗,就是所謂的原子性)。為了實現這一點,我們就知道寫數據時每行數據原來長啥樣,方便對更新后的數據進行回滾,因此就有了undo log ,更新Buffer Pool數據葉的時候,會用舊數據生成Undo log記錄,會用舊數據生成undo log ,存儲在bufferpool中的特殊undo log 內存頁中,并隨著Buffer Pool的刷盤機制,不定時寫入到磁盤的Undo log 文件中
Redo Log
將事務中更新數據行的操作都寫入到Redo Log Buffer內存中,在事務提交的時候進行redo log刷磁盤,將數據固化到redo log文件中,數據庫進程崩潰重啟后,就能通過Redo Log File找到歷史操作記錄重做數據,保證了事務里的多行數據變更,要么都成功,要么都失敗
Redo Log File是由順序寫入的,Buffer Pool的內存數據隨機分散在磁盤內,順序寫磁盤性能是隨機寫的幾十倍
InnoDB
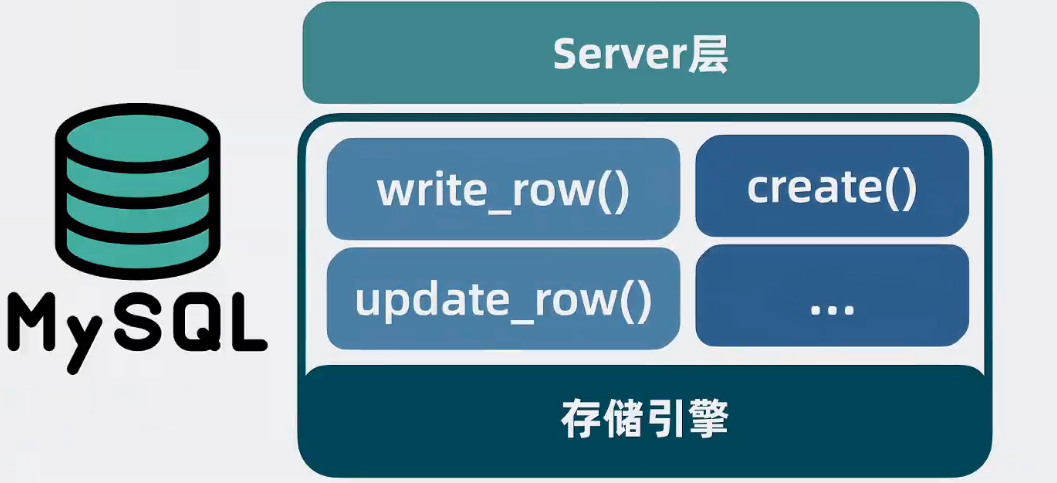
sql語句如何轉成存儲引擎的函數接口呢
Server層
本質是sql語句和InnoDB存儲引擎的中間層,在server層內提供一個連接管理模塊,用于管理來自引用的網絡連接,并提供一個分析器用于判斷sql語句有沒有語法錯誤,再提供一個優化器,用于根據一定的規則,選擇改用什么索引生成執行計劃,之后提供一個執行器根據執行計劃去調用InnoDB存儲引擎的接口函數
binlog是什么
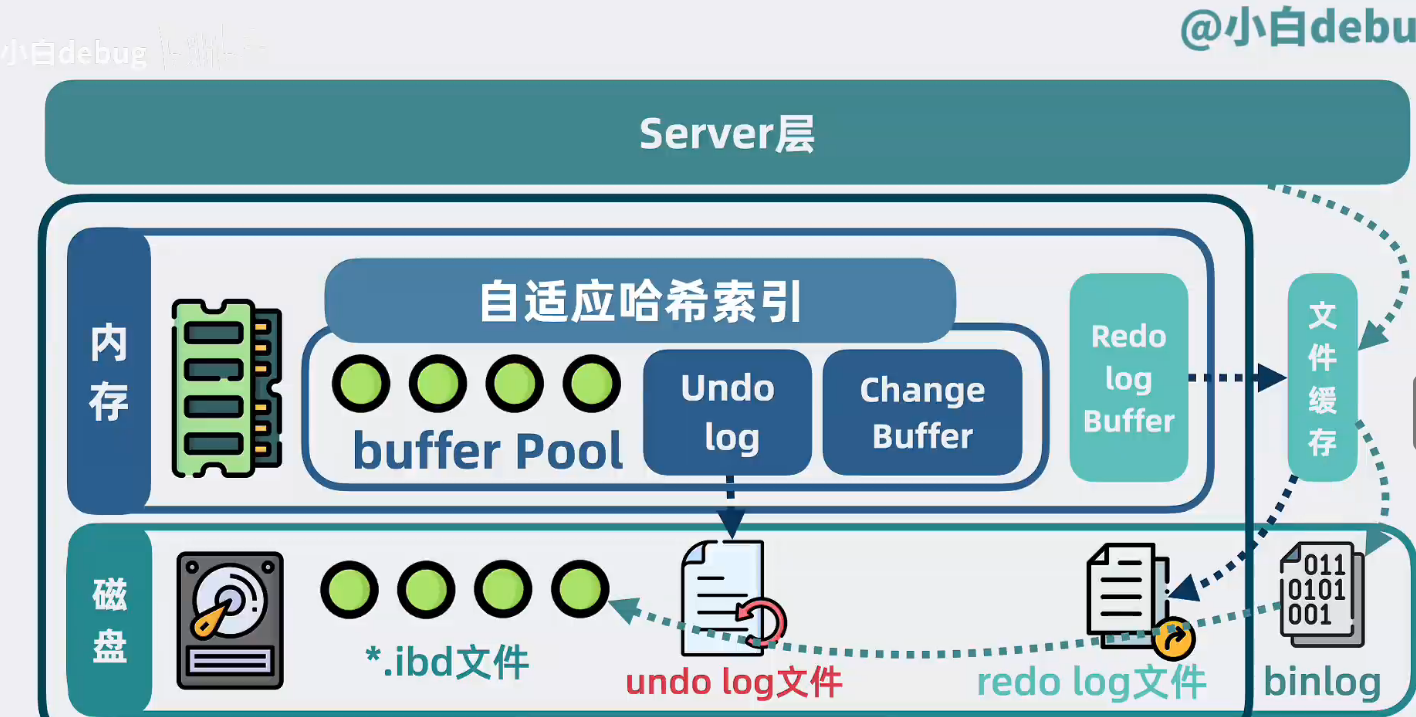
redolog 是環形寫的,寫入數據多的時候會把最開始寫入的刪除掉,所以沒法完全恢復,只能用來恢復部分最近數據(當然,這部分也是比較大的了)


)




)
)


的設計與實現)

)





)